 夜雨聆风
夜雨聆风





效率翻倍,Token减半:让OpenClaw学习后再做测试用例设计

前言
在 AI 赋能研发效能的浪潮中,OpenClaw 凭借出色的自动化执行能力和丰富的 SKILL 生态,成为了许多测试团队手中的提效利器。但令人尴尬的是,当我们试图用它来直接生成测试用例时,往往会遭遇“水土不服”的瓶颈,难以达到预期的效果。

AI编写测试用例的基础模式
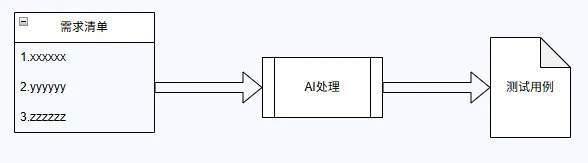
基础模式存在的主要问题


-
脱离架构,浮于表面:AI 缺乏对产品底层架构和系统拓扑的深度感知,生成的用例往往只覆盖基础主流程。
-
机械翻译,缺乏深度:单纯依赖字面需求进行转化,难以深入理解核心业务逻辑与质量策略,测不出深层 Bug。
-
盲目自信,缺乏怀疑:面对模糊指令或复杂场景时,倾向于自信地“脑补”执行甚至编造测试路径,容易产出看似合理但无效的“假大空”用例。
-
领域知识缺失,无视业务与合规红线:AI通常缺乏对垂直领域的深度理解。无法识别复杂的业务规则,无视行业合规要求,生成完全违背业务常理的用例。


给AI赋能-让AI理解软件架构
-
方案一:本地存储知识库


最基础的做法,是直接在 OpenClaw 部署的机器上对资料进行分类存储。每次设计用例前,先让 AI 学习所有资料,再进行生成。但这种方式在实际落地中存在四个明显痛点:
-
学习成本随数据量激增:资料越多,AI 的学习速度越慢,严重拖慢用例生成效率。
-
上下文超长导致内容互串:海量资料极易突破大模型的上下文长度限制,导致不同用例内容相互干扰。
-
缺乏针对性,资源浪费:即使只处理单一需求,AI 仍需全量学习整个资料库,效率低下。
-
职责边界模糊:资料库的维护工作被迫压在系统管理员身上,导致职责划分不明确。


-
方案二:外挂RAG知识库


通过OpenClaw外挂RAG知识库的方式为测试用例设计补充必要的上下文。
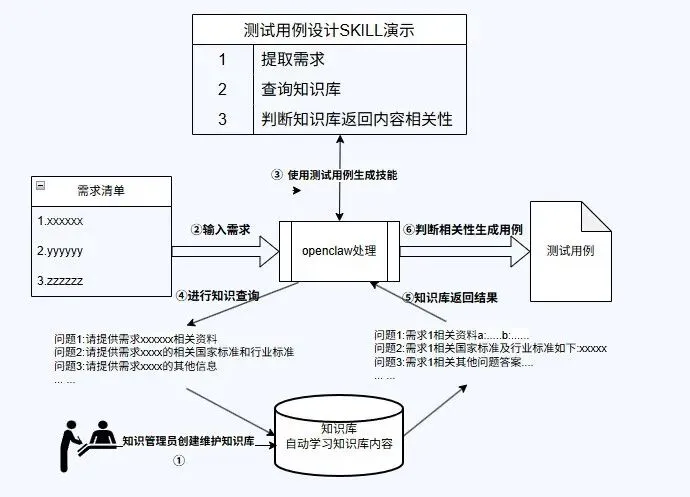
外挂RAG知识库后的AI用例设计流程图
为了突破瓶颈,我们引入了紫鸾知识平台作为独立的知识库,解决了方案一的痛点,并带来以下显著优势:
-
职责分明,召回更准:资料由专人管理,系统管理员无需兼任知识管理员。通过专业的资料分类与结构化处理,知识召回的准确率大幅提升。
-
学答分离,永久记忆:知识平台拥有专属的学习与向量匹配机制,将“学习”与“问答”从 OpenClaw 的大模型中解耦。知识学习完成后即可永久记忆,无需重复学习,不仅大幅缩短了响应时间,还节约了大量 Token 消耗。
-
精简上下文,精准生成:在 OpenClaw 设计用例时,系统会强制其通过知识库检索需求资料及行业/国家标准。知识库返回结果后,再由 OpenClaw 进行二次相关性判断。这大幅降低了上下文的 Token 占用,使 AI 能更精准地针对特定需求生成用例。
-
按需获取,效率跃升:面对单个需求时,AI 无需再全量学习整套资料,只需从知识平台按需获取相关资料与标准即可。这极大缩短了学习成本,实现了用例生成效率的质的飞跃。


实际落地效果演示


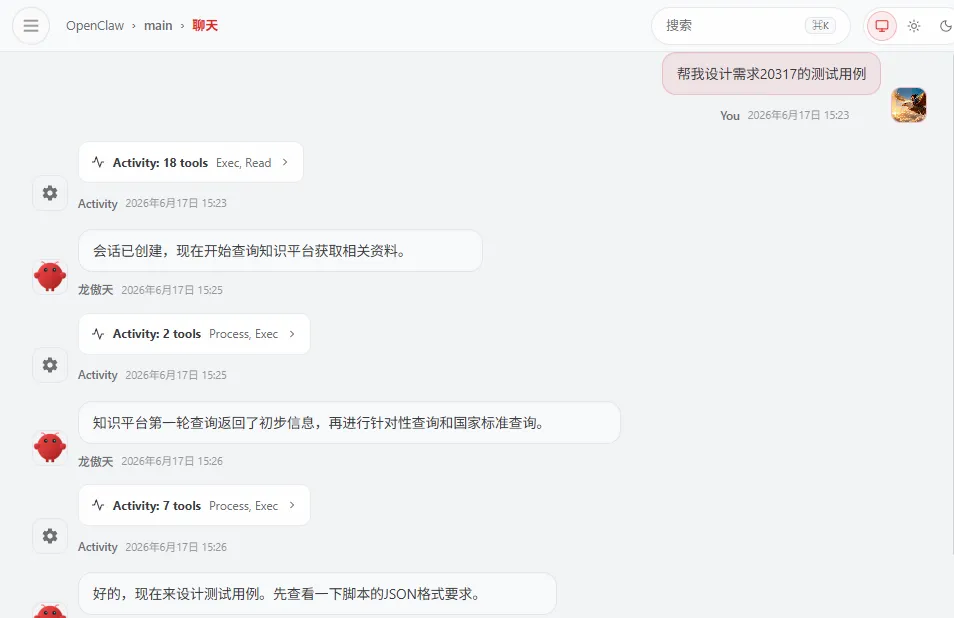
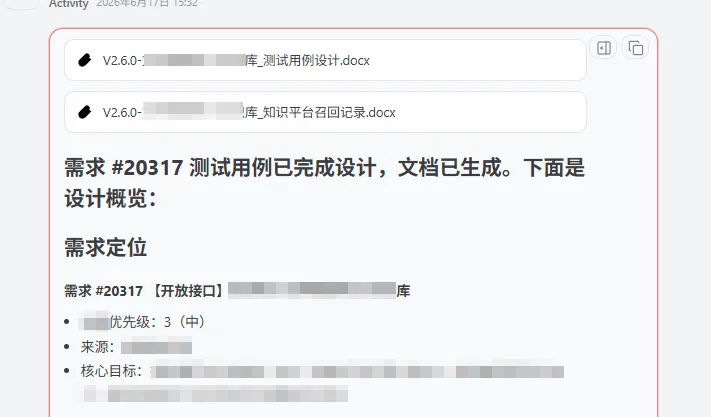
下图直观呈现了OpenClaw如何通过调用SKILL来分析需求并生成测试用例,图中为突出重点,省略了中间的部分工具调用细节:
-
我们打通了需求系统和企业微信,因此我们只需要在 webchat/channel 里给 OpenClaw 发一条指令即可完成用例设计的全过程。
-
用例设计SKILL的步骤设置如下:
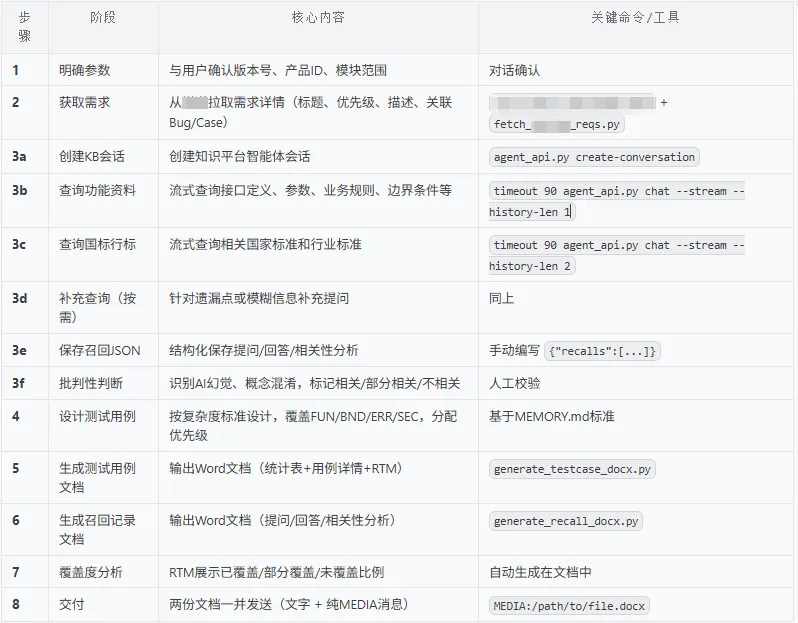
测试用例设计SKILL
-
最后按照我们制定的Skill生成了2份文档,一份为按照我们要求生成的测试用例文档,另一份为知识平台召回记录文档,方便对测试用例设计过程进行回溯,最后直接点击文档链接下载即可。
-
在知识平台召回记录里我们可以看到那些资料是被采纳,那些未被采纳:
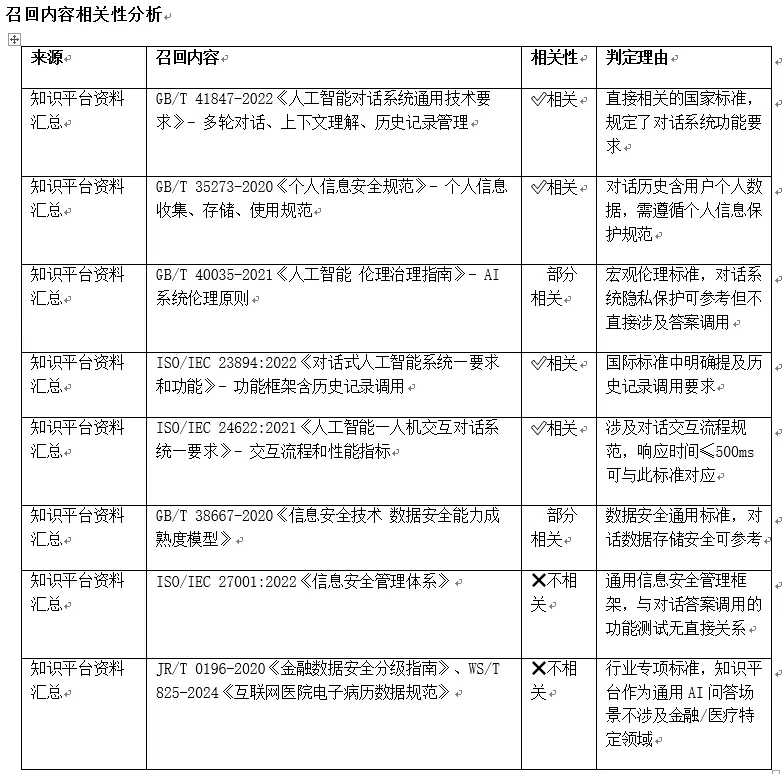
知识平台召回文档示例
-
接入知识库前与接入知识库后生成的用例对比:
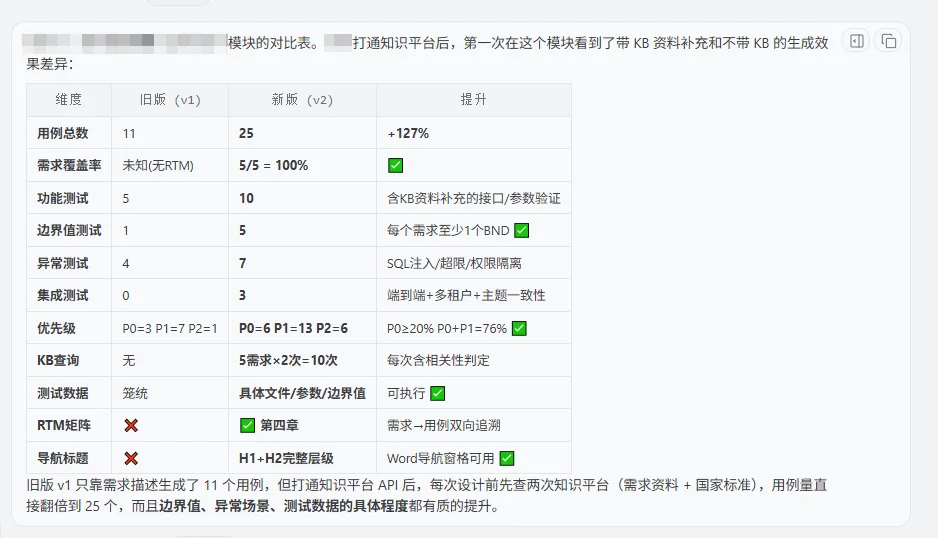
引入知识库前后的效果对比



结语


打通用例设计流程仅仅是起点。未来,我们将聚焦于知识库的动态治理与经验沉淀机制,致力于构建“文档总结-经验提炼-知识反哺”的有效闭环,确保持续赋能,实现从需求到经验的自进化。
从“机械翻译”迈向“架构驱动”,从“本地存储的捉襟见肘”走向“独立知识库的精准赋能”,我们探索的不仅是工具层面的优化方案,更是对测试质量与效率极限的不断突破。


往期推荐
