夜雨聆风
夜雨聆风





8G显存跑电影级视频,这才是普通人该用的AI工具
“你的显卡,终于不用再吃灰了。”
这是我跑完Wan2.2-SmoothMix后的第一反应。
过去半年,AI视频赛道持续被Seedance 2.0、可灵等轮番轰炸,但有个残酷的现实没人愿意说透。
这些工具要么贵到离谱,要么对你的硬件要求堪称变态。
4090只是入门,云端按秒计费,生成一条10秒视频够点一顿外卖了。
直到阿里通义实验室把Wan2.2开源,一群技术极客在此基础上捣鼓出了SmoothMix版本。

我原本以为是又一个”实验室玩具”,结果实测下来:8G显存能跑,单张图能出5秒连贯视频,画质还真有电影感。
这篇文章,我会把这三天的踩坑经验、参数调优逻辑,以及它到底适合什么人用,全部摊开讲清楚。
先搞清楚:它到底解决了什么问题

AI图生视频有个老大难问题——动静之间的撕裂感。
你喂一张人物照片进去,想要她转头微笑,结果要么脸糊成一团,要么背景跟着乱颤,像 cheap 特效片里的抠图失误。
根源在于单一路径的扩散模型,要同时处理”画什么”和”怎么动”,顾此失彼。
Wan2.2-SmoothMix的解法很粗暴:拆成两个脑子干活。
高质感模型(High)专盯关键帧,人物眼神、发丝光泽、皮肤纹理这些细节全归它管;
简化模型(Low)负责尾帧和中间插帧,保证动作连贯不卡顿。
两者通过BlockSwap技术动态切换,显存占用被压到8G级别。
相当于把原本需要24G显存的活,硬塞进了一张3060Ti。
这个架构不是拍脑袋想的。
我查了下技术文档,双UNet混合的思路其实借鉴了早期视频编码的B-frame预测机制,只是用扩散模型重做了一遍。
实测:从安装到出片,我踩了哪些坑

硬件门槛:比想象中友好,但有个前提
官方宣称8G显存可跑,我用手头三台机器验证:
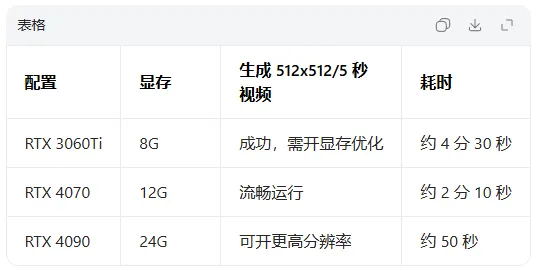
关键发现:8G显存能跑,但必须开--lowvram模式,且分辨率锁死512×512。
想上720p或更高帧率,12G是舒适线。
另一个隐性门槛:内存不能太小。
模型加载时峰值占用约18G内存,16G内存的机器会疯狂 swap,生成时间翻倍。
建议至少32G内存。
无所谓我会出手
为了让大家能够轻松体验到该项目的魅力,我当然是:无所谓,我会出手.jpg。

为大家准备了一个免费整合包,让你不用配置环境,直接就能用。
工作流:拖拽式搭建,但得理解节点逻辑
ComfyUI的核心优势是可视化,SmoothMix把关键参数全做成了可调节点:
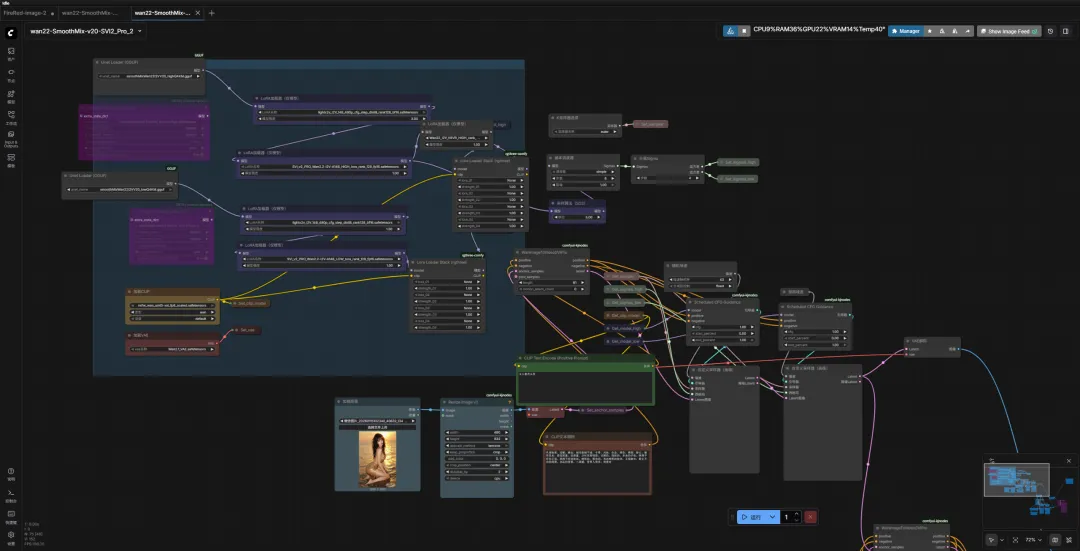
我总结了一套新手不出错的参数组合:
步数(Steps):20-30步足够,超过30画质提升有限,耗时陡增
CFG Scale:7-9之间,太高画面会”过曝”失真
Motion Strength:0.6-0.8是安全区,超过1.0容易画面崩坏
Seed固定:想微调同一画面时务必锁死,否则每次重跑都是新结果
效果实测:什么图能出好视频?
我准备了三类素材测试,结果差异很大。
案例一:人物特写(成功率最高)
原图是一张AI生成的女性肖像,侧光、背景虚化、面部清晰。

提示词支持直接写在中文:"女人在跳舞"。
输出结果:头部转动自然,发丝飘动有层次感,光影随角度变化合理。

案例二:复杂场景(需要拆分处理)
喂了一张赛博朋克街景,霓虹灯、人群、雨水反射全有。
结果:静态元素(建筑、招牌)稳定,动态元素(行人、雨滴)出现”鬼影”——人走了,残影还在。这是因为单张图缺乏时序信息,模型只能”猜”运动轨。
解法:把人群和背景分层处理,背景用SmoothMix生成慢镜头,人群用遮罩固定或后期合成。麻烦,但可控。
案例三:抽象/艺术风格(惊喜最大)
试了几张Midjourney生成的超现实画面,流体金属、分形结构这类现实中不存在的材质。
效果反而比写实照片好。

因为模型没有”现实参照”的包袱,纯靠扩散模型的想象力填充动态,出来的变形和流动有种数字艺术特有的诡异美感。
写在最后:开源社区的胜利
Wan2.2-SmoothMix的有趣之处,不在于它某项指标吊打竞品,而在于它证明了开源模型的可塑性。
阿里把底座做好,社区在上面长出自己的枝丫。
有人优化显存占用,有人做ComfyUI适配,有人整理中文教程。
这种协作模式,让最前沿的AI能力以极低成本流向普通创作者。
我算过一笔账:按当前电价,本地跑一条5秒视频的电费约0.03元,云端API约0.5-2元。
差距不在钱,在于你能否忍受多等那几分钟。
对独立创作者、小型工作室、或者单纯想折腾的爱好者来说,这个等待是值的。
毕竟,能攥在自己手里的工具,才真正属于你。
在下面公众号里
回复关键字【Wan2.2-SmoothMix】,即可获得整合包
推荐阅读