 夜雨聆风
夜雨聆风





SKILL实战:Excel 代码 + Prompt驱动 + Skill进阶
📂 本文档是 Excel 处理专题的合集版,包含三条学习路径的所有内容,读者可根据需要选择阅读。
完整代码获取:https://gitee.com/agent-now/hermes-workspace/blob/master/tutorials/excel-all-in-one.md[1]
工具版本:openpyxl 3.1.5 + pandas 3.0.2
专题结构:三条学习路径
| 路径 | 入口 | 说明 |
|---|---|---|
| 代码篇 | 下方各章节 | openpyxl + pandas,完整可运行代码 |
| Prompt驱动篇 | 下方各章节 | 自然语言指令模板,直接复制改参数用 |
| Skill进阶 | 十四章:XML 源码级处理[2] | minimax-xlsx 底层原理,财务配色标准 |
阅读建议:
-
想快速完成任务 → 看 Prompt 模板,直接用 -
想系统学习 → 先看代码,搞懂原理 -
想深度定制/搞懂底层 → 看第十四章 Skill 进阶
预备:示例数据说明
所有代码和 Prompt 均基于以下示例数据(sales_data.xlsx):
| 日期 | 销售员 | 产品 | 区域 | 销售额 | 数量 |
|---|---|---|---|---|---|
| 2025-01-03 | 张三 | 电子产品 | 华东 | 12,500 | 8 |
| 2025-01-03 | 李四 | 办公用品 | 华北 | 8,300 | 12 |
| 2025-01-04 | 张三 | 办公用品 | 华南 | 5,600 | 5 |
| 2025-01-04 | 王五 | 电子产品 | 华东 | 18,900 | 15 |
| 2025-01-05 | 李四 | 办公用品 | 华东 | 7,200 | 9 |
| 2025-01-05 | 赵六 | 电子产品 | 华北 | 21,300 | 18 |
| 2025-01-06 | 张三 | 办公用品 | 华南 | 4,900 | 4 |
| 2025-01-06 | 王五 | 电子产品 | 华东 | 15,600 | 12 |
| 2025-01-07 | 李四 | 办公用品 | 华北 | 9,100 | 10 |
| 2025-01-07 | 赵六 | 电子产品 | 华南 | 17,800 | 14 |
生成方式(代码篇):
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.title = "销售数据"
headers = ["日期", "销售员", "产品", "区域", "销售额", "数量"]
ws.append(headers)
data = [
["2025-01-03", "张三", "电子产品", "华东", 12500, 8],
["2025-01-03", "李四", "办公用品", "华北", 8300, 12],
["2025-01-04", "张三", "办公用品", "华南", 5600, 5],
["2025-01-04", "王五", "电子产品", "华东", 18900, 15],
["2025-01-05", "李四", "办公用品", "华东", 7200, 9],
["2025-01-05", "赵六", "电子产品", "华北", 21300, 18],
["2025-01-06", "张三", "办公用品", "华南", 4900, 4],
["2025-01-06", "王五", "电子产品", "华东", 15600, 12],
["2025-01-07", "李四", "办公用品", "华北", 9100, 10],
["2025-01-07", "赵六", "电子产品", "华南", 17800, 14],
]
for row in data:
ws.append(row)
wb.save("sales_data.xlsx")
print("示例文件已创建:sales_data.xlsx")
运行后会生成 sales_data.xlsx,后续各章节都基于此文件操作。
第一章:数据读取与写入 {#ch01}
代码篇
1.1 用 pandas 读取
import pandas as pd
# 读取第一个 sheet(默认)
df = pd.read_excel("sales_data.xlsx")
print(df.head())
# 读取所有 sheet(返回字典)
all_sheets = pd.read_excel("sales_data.xlsx", sheet_name=None)
for name, sheet in all_sheets.items():
print(f"Sheet名称: {name}, 行数: {len(sheet)}")
# 读取指定 sheet
df_sales = pd.read_excel("sales_data.xlsx", sheet_name="销售数据")
1.2 用 openpyxl 读取(保留格式)
from openpyxl import load_workbook
wb = load_workbook("sales_data.xlsx")
ws = wb.active
for row in ws.iter_rows(min_row=1, max_row=3):
for cell in row:
print(f"{cell.coordinate}: {cell.value}", end=" | ")
print()
1.3 保存处理后的数据
import pandas as pd
df = pd.read_excel("sales_data.xlsx")
df["单价"] = df["销售额"] / df["数量"]
# 保存到新文件(不包含默认索引列)
df.to_excel("sales_data-processed.xlsx", index=False)
执行结果:
日期 销售员 产品 区域 销售额 数量
0 2025-01-03 张三 电子产品 华东 12500 8
1 2025-01-03 李四 办公用品 华北 8300 12
2 2025-01-04 张三 办公用品 华南 5600 5
总行数: 10
Prompt驱动篇
读取并了解文件结构:
请帮我读取 sales_data.xlsx 文件,
1. 显示前10行内容
2. 告诉我有哪些列
3. 告诉我每列的数据类型
4. 告诉我总共有多少行数据
保存处理后的数据:
读取 sales_data.xlsx,
把"销售额"列除以"数量"得到"单价",
保存为 sales_with_unit_price.xlsx。
从 CSV 导入 Excel:
把 weekly_report.csv 转换为 Excel 格式,
保留中文编码(UTF-8),
第一个工作表命名为"周报数据",
保存为 weekly_report.xlsx。
第二章:合并与拆分 Sheet {#ch02}
代码篇
2.1 将多个 sheet 合并为一个
import pandas as pd
file_path = "sales_data.xlsx"
# 读取所有 sheet
all_sheets = pd.read_excel(file_path, sheet_name=None)
# 合并所有 sheet
merged_df = pd.concat(all_sheets.values(), ignore_index=True)
print(f"合并后总行数: {len(merged_df)}")
# 保存合并结果
merged_df.to_excel("sales_merged.xlsx", index=False)
2.2 将数据按条件拆分为多个 Sheet
import pandas as pd
from openpyxl import Workbook
df = pd.read_excel("sales_data.xlsx")
# 按"区域"拆分为不同 sheet
wb = Workbook()
wb.remove(wb.active)
for region, group in df.groupby("区域"):
ws = wb.create_sheet(title=region)
ws.append(list(group.columns))
for _, row in group.iterrows():
ws.append(list(row))
print(f"已创建 Sheet: {region}")
wb.save("sales_by_region.xlsx")
执行结果:
Sheet列表: ['华东', '华北', '华南']
每个Sheet数据行数:华东4行、华北3行、华南3行
Prompt驱动篇
合并多个 Sheet:
我有一个文件叫 sales.xlsx,里面有三个 Sheet:
- Sheet1 叫"华东"
- Sheet2 叫"华北"
- Sheet3 叫"华南"
这三个 Sheet 的结构完全一样(日期、销售员、产品、区域、销售额、数量)。
请帮我:
1. 把这三个 Sheet 合并成一个大表
2. 新增一列"区域",填入对应 Sheet 的名称
3. 保存为 sales_merged.xlsx
按条件拆分为多个 Sheet:
读取 sales_data.xlsx,
按"区域"列拆分为不同的 Sheet:
- 华东地区的数据保存到一个 Sheet,名称叫"华东"
- 华北地区的数据保存到一个 Sheet,名称叫"华北"
- 华南地区的数据保存到一个 Sheet,名称叫"华南"
最终保存为一个 Excel 文件叫 sales_by_region.xlsx,包含三个 Sheet。
按条件导出子集:
从 sales_data.xlsx 中:
1. 筛选出"产品"等于"电子产品"的行
2. 筛选出"销售额"大于 10000 的行
3. 将这两个筛选结果分别保存为:
- electronics_high.xlsx(电子产品且销售额>10000)
- rest.xlsx
第三章:数据筛选与排序 {#ch03}
代码篇
3.1 筛选数据
import pandas as pd
df = pd.read_excel("sales_data.xlsx")
# 单一条件筛选
high_sales = df[df["销售额"] > 10000]
# 多条件筛选:电子产品 且 销售额 > 10000
filtered = df[(df["产品"] == "电子产品") & (df["销售额"] > 10000)]
filtered.to_excel("sales_high.xlsx", index=False)
3.2 排序数据
df = pd.read_excel("sales_data.xlsx")
# 按销售额降序排列
sorted_df = df.sort_values(by="销售额", ascending=False)
# 多列排序:先按区域,再按销售额降序
sorted_multi = df.sort_values(by=["区域", "销售额"], ascending=[True, False])
sorted_multi.to_excel("sales_sorted.xlsx", index=False)
执行结果:
筛选结果(电子产品 且 销售额>10000):
销售员 产品 销售额
张三 电子产品 12500
王五 电子产品 18900
赵六 电子产品 21300
王五 电子产品 15600
赵六 电子产品 17800
排序结果(前5行):
销售员 区域 销售额
王五 华东 18900
王五 华东 15600
张三 华东 12500
...
Prompt驱动篇
条件筛选:
读取 sales_data.xlsx,帮我完成以下筛选:
1. 筛选条件1:销售额大于 10000
2. 筛选条件2:产品等于"电子产品"
3. 两个条件用 AND 组合(同时满足)
4. 把结果保存为 top_electronics.xlsx
筛选常用表达对照:
| 场景 | 怎么说 |
|---|---|
| 等于 | “产品等于’电子产品'”、”区域是’华东'” |
| 不等于 | “产品不等于’办公用品'” |
| 大于/小于 | “销售额大于10000″、”数量小于5” |
| 区间 | “销售额在5000到15000之间” |
| 包含 | “产品名称包含’手机'” |
| 多条件AND | “产品=’电子产品’ 且 销售额>10000” |
| 多条件OR | “区域=’华东’ 或 区域=’华北'” |
排序:
读取 sales_data.xlsx,
先按"区域"升序排列,
再按"销售额"降序排列(同一区域内按销售额从高到低),
保存为 sales_ranked.xlsx。
第四章:去除重复数据 {#ch04}
代码篇
import pandas as pd
df = pd.read_excel("sales_data.xlsx")
# 查看重复行
print(df[df.duplicated(keep=False)])
# 删除重复行(保留第一条)
df_unique = df.drop_duplicates()
print(f"去重前行数: {len(df)}, 去重后: {len(df_unique)}")
# 按某列去重(保留该列值最大的那条)
df_best = df.sort_values("销售额", ascending=False).drop_duplicates(subset="销售员", keep="first")
df_unique.to_excel("sales_dedup.xlsx", index=False)
执行结果:
去重前行数: 10
去重后行数: 10(本次数据无重复行)
每销售员保留最高销售额的记录:
销售员 销售额
赵六 21300
王五 18900
张三 12500
李四 9100
Prompt驱动篇
删除完全重复的行:
帮我检查 sales_data.xlsx 是否有完全重复的行:
1. 告诉我一共有多少行,其中多少行是重复的
2. 删除所有重复行(保留每组的第一条)
3. 保存为 sales_dedup.xlsx
4. 告诉我删除了多少行
按某列去重(保留最优):
读取 sales_data.xlsx,
如果同一个"销售员"出现多次,只保留他销售额最高的那一行,
其他重复记录删除,
保存为 sales_best_per_person.xlsx。
第五章:公式与计算 {#ch05}
代码篇
5.1 写入 Excel 公式
from openpyxl import load_workbook, Workbook
wb = Workbook()
ws = wb.active
ws.title = "公式示例"
ws["A1"], ws["B1"], ws["C1"], ws["D1"] = "产品", "单价", "数量", "金额"
ws["A2"], ws["B2"], ws["C2"] = "电子产品", 150, 10
ws["A3"], ws["B3"], ws["C3"] = "办公用品", 45, 25
ws["A4"], ws["B4"], ws["C4"] = "办公用品", 80, 15
# 写入公式:用 Excel 计算金额 = 单价 × 数量
ws["D2"] = "=B2*C2"
ws["D3"] = "=B3*C3"
ws["D4"] = "=B4*C4"
# SUM 合计公式
ws["A5"], ws["D5"] = "合计", "=SUM(D2:D4)"
wb.save("formula_example.xlsx")
重要原则:公式的值应该在 Excel 里计算,而不是在 Python 里算好再写入。这样 Excel 打开后改动数据,公式结果会自动更新。
5.2 常用公式参考
| 公式 | 用途 | 示例 |
|---|---|---|
=SUM(A1:A10) |
求和 | 合计一列数字 |
=AVERAGE(A1:A10) |
平均值 | 算平均销售额 |
=VLOOKUP(A1, B:C, 2, FALSE) |
查找匹配 | 根据姓名查部门 |
=IF(A1>10000, "高", "低") |
条件判断 | 销售额分级 |
=SUMIF(A:A, "电子产品", B:B) |
条件求和 | 某产品销售总额 |
=COUNTIF(A:A, ">10000") |
条件计数 | 超额次数 |
Prompt驱动篇
添加计算列:
原则:让 AI 帮你写公式,而不是帮你算值
读取 sales_data.xlsx,
在旁边新增一列叫"利润率",计算公式为:(销售额 - 销售额×0.6) / 销售额
用 Excel 公式实现,不是 Python 算好再写入。
保存为 sales_with_margin.xlsx。
求和、汇总:
读取 sales_data.xlsx,
在"销售额"列的最下方增加一行"合计",
计算所有销售额的总和(用 Excel SUM 公式)。
同时在"数量"列最下方也加合计。
保存为 sales_with_total.xlsx。
VLOOKUP 查找匹配:
有两个文件:
- sales_data.xlsx:销售数据(含姓名、销售额)
- employee_info.xlsx:员工信息表(含姓名、部门、职位)
请在 sales_data.xlsx 中新增两列:
1. "部门":根据姓名从 employee_info.xlsx 匹配对应的部门
2. "职位":根据姓名从 employee_info.xlsx 匹配对应的职位
使用 Excel VLOOKUP 公式实现。
保存为 sales_with_dept.xlsx。
截图:公式效果

📌 说明:Excel 打开后,D 列会自动显示计算结果(金额 = 单价 × 数量),D4 显示合计。修改 B、C 列数值,公式结果会自动更新。
第六章:修复公式错误 {#ch06}
代码篇
6.1 常见报错类型
| 错误值 | 含义 | 常见原因 |
|---|---|---|
#REF! |
引用无效 | 引用的单元格/区域被删除 |
#DIV/0! |
除零错误 | 除数单元格为零或空 |
#VALUE! |
类型错误 | 公式接收了非数值类型 |
#NAME? |
名称未识别 | 函数名拼写错误 |
#N/A |
查找无结果 | VLOOKUP 找不到匹配值 |
6.2 自动检测并修复
from openpyxl import load_workbook
wb = load_workbook("problem_file.xlsx")
ws = wb.active
errors_found = []
for row in ws.iter_rows():
for cell in row:
if isinstance(cell.value, str) and cell.value.startswith("="):
formula = cell.value
if any(e in formula for e in ["#REF!", "#DIV/0!", "#VALUE!"]):
errors_found.append({
"cell": cell.coordinate,
"formula": formula
})
print(f"发现错误公式: {cell.coordinate} -> {formula}")
if errors_found:
for error in errors_found:
cell = ws[error["cell"]]
# 用 IFERROR 包裹,防止继续报错
safe_formula = f'=IFERROR({error["formula"][1:]}, "-")'
cell.value = safe_formula
print(f"已修复: {error['cell']} -> {safe_formula}")
wb.save("problem_file_fixed.xlsx")
else:
print("未发现报错公式")
Prompt驱动篇
诊断公式报错:
帮我检查 report.xlsx 里所有工作表的公式错误:
1. 找出所有报 #REF!、#DIV/0!、#VALUE! 等错误的单元格
2. 告诉我每个错误单元格的坐标和当前公式内容
3. 给出修复建议
用 IFERROR 包裹报错公式:
帮我修复 sales.xlsx 中所有报错的公式:
1. 找到所有包含 #REF!、#DIV/0! 的单元格
2. 用 IFERROR 公式包裹它们,错误时显示"-"
3. 保存为 sales_fixed.xlsx
批量修复 #N/A 错误:
帮我处理 VLOOKUP 的 #N/A 错误:
1. 找出所有 #N/A 的单元格
2. 用 IFERROR(VLOOKUP(...), "未找到") 的方式替换
3. 保存为 sales_no_na.xlsx
第七章:格式处理 {#ch07}
代码篇
7.1 设置表头样式
from openpyxl import load_workbook
from openpyxl.styles import Font, PatternFill, Alignment, Border, Side
wb = load_workbook("sales_data.xlsx")
ws = wb.active
header_fill = PatternFill(start_color="1F4E79", end_color="1F4E79", fill_type="solid")
header_font = Font(name="Arial", bold=True, color="FFFFFF", size=11)
header_align = Alignment(horizontal="center", vertical="center")
thin_border = Border(
left=Side(style="thin"), right=Side(style="thin"),
top=Side(style="thin"), bottom=Side(style="thin")
)
for cell in ws[1]:
cell.fill = header_fill
cell.font = header_font
cell.alignment = header_align
cell.border = thin_border
wb.save("sales_styled.xlsx")
7.2 隔行着色(斑马线)
from openpyxl import load_workbook
from openpyxl.styles import PatternFill, Alignment, Border, Side
wb = load_workbook("sales_data.xlsx")
ws = wb.active
even_fill = PatternFill(start_color="D6E4F0", end_color="D6E4F0", fill_type="solid")
odd_fill = PatternFill(start_color="FFFFFF", end_color="FFFFFF", fill_type="solid")
data_align = Alignment(horizontal="center", vertical="center")
thin_border = Border(
left=Side(style="thin"), right=Side(style="thin"),
top=Side(style="thin"), bottom=Side(style="thin")
)
for row_idx, row in enumerate(ws.iter_rows(min_row=2), start=1):
fill = even_fill if row_idx % 2 == 0 else odd_fill
for cell in row:
cell.fill = fill
cell.alignment = data_align
cell.border = thin_border
# 列宽自适应
col_widths = {"A": 12, "B": 10, "C": 12, "D": 8, "E": 12, "F": 8}
for col, width in col_widths.items():
ws.column_dimensions[col].width = width
# 冻结首行
ws.freeze_panes = "A2"
wb.save("sales_zebra.xlsx")
7.3 自动调整列宽
from openpyxl import load_workbook
wb = load_workbook("sales_data.xlsx")
for sheet_name in wb.sheetnames:
ws = wb[sheet_name]
for column in ws.columns:
max_length = 0
column_letter = column[0].column_letter
for cell in column:
try:
if cell.value:
max_length = max(max_length, len(str(cell.value)))
except:
pass
adjusted_width = min(max_length + 2, 30)
ws.column_dimensions[column_letter].width = adjusted_width
wb.save("sales_autofit.xlsx")
Prompt驱动篇
统一表头样式:
帮我美化 sales_data.xlsx 的格式:
1. 表头行(第一行)背景色设为深蓝色(#1F4E79),白色字体,加粗,居中对齐
2. 数据区域添加边框线(细线)
3. 保存为 sales_styled.xlsx
隔行变色(斑马线):
sales_data.xlsx 的数据区域(从第2行开始):
- 奇数行:白色背景
- 偶数行:浅蓝色背景(#D6E4F0)
表头行不变。
保存为 sales_zebra.xlsx。
冻结首行:
sales_data.xlsx 设置冻结首行(方便向下滚动时始终看到表头)。
保存为 sales_frozen.xlsx。
金额数字加千分位分隔符:
sales_data.xlsx 的"销售额"列:
- 设置为会计专用格式:千分位分隔符、保留0位小数
- 负数显示为括号形式(如 (1,234))
保存为 sales_formatted.xlsx。
截图:格式美化效果

📌 说明:深蓝色表头 + 白色/浅蓝交替行 + 冻结首行。滚动数据时表头始终可见。
第八章:条件格式 {#ch08}
代码篇
8.1 高亮满足条件的单元格
from openpyxl import load_workbook
from openpyxl.styles import PatternFill
from openpyxl.formatting.rule import ColorScaleRule, CellIsRule
wb = load_workbook("sales_data.xlsx")
ws = wb.active
# 销售额大于 15000:绿色背景
ws.conditional_formatting.add(
"E2:E100",
CellIsRule(operator="greaterThan", formula=["15000"],
fill=PatternFill(start_color="C6EFCE", end_color="C6EFCE", fill_type="solid"))
)
# 销售额小于 6000:红色背景
ws.conditional_formatting.add(
"E2:E100",
CellIsRule(operator="lessThan", formula=["6000"],
fill=PatternFill(start_color="FFC7CE", end_color="FFC7CE", fill_type="solid"))
)
# 销售额三色刻度(低=红,中=黄,高=绿)
ws.conditional_formatting.add(
"E2:E100",
ColorScaleRule(
start_type="min", start_color="F8696B",
mid_type="percentile", mid_value=50, mid_color="FFEB84",
end_type="max", end_color="63BE7B"
)
)
wb.save("sales_conditional.xlsx")
8.2 数据条(Data Bars)
from openpyxl import load_workbook
from openpyxl.formatting.rule import DataBarRule
wb = load_workbook("sales_data.xlsx")
ws = wb.active
ws.conditional_formatting.add(
"E2:E100",
DataBarRule(start_type="min", end_type="max", color="638EC6", showValue=True)
)
wb.save("sales_databar.xlsx")
Prompt驱动篇
高亮满足条件的行:
sales_data.xlsx 的"销售额"列(E列):
- 销售额 > 15000:整行背景浅绿色
- 销售额 < 6000:整行背景浅红色
保存为 sales_conditional.xlsx。
三色刻度:
sales_data.xlsx 的"销售额"列:
应用三色条件格式:
- 最小值:红色
- 中间值(50%):黄色
- 最大值:绿色
保存为 sales_heatmap.xlsx。
数据条:
sales_data.xlsx 的"销售额"列:
添加数据条(Data Bars),蓝色数据条。
保存为 sales_databar.xlsx。
截图:条件格式效果
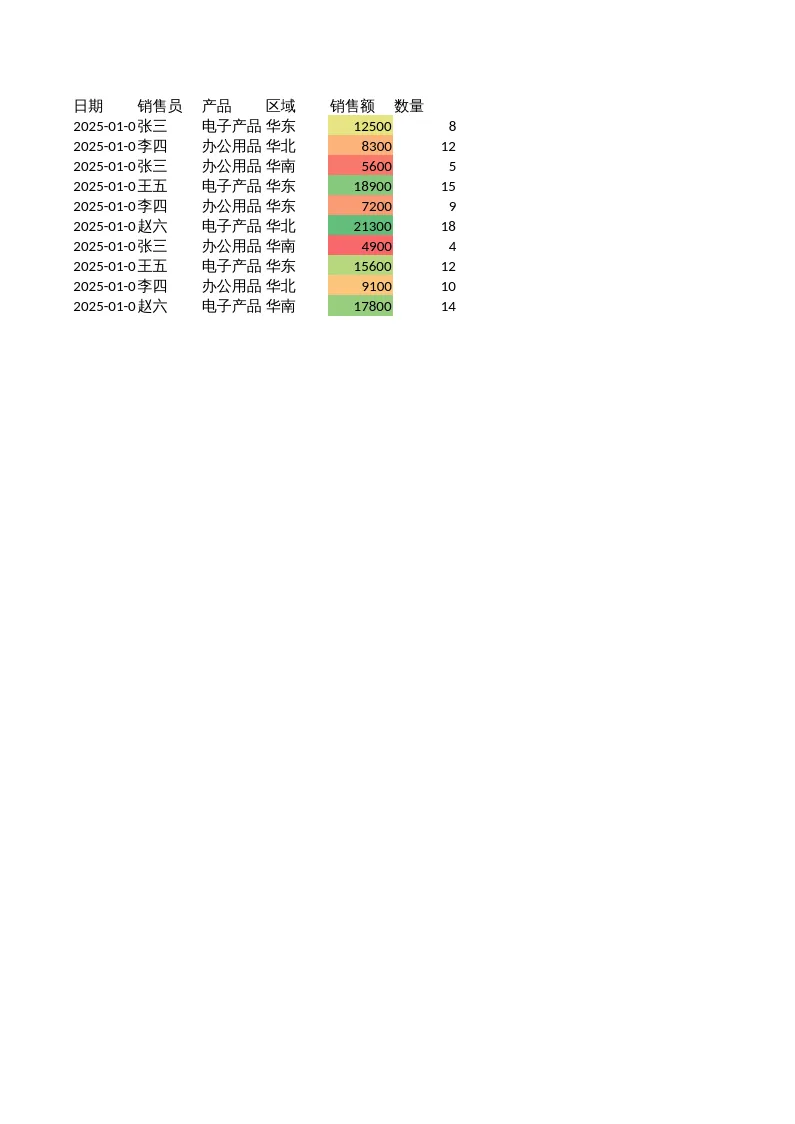
📌 说明:绿色(销售额>15000)、红色(销售额<6000)、三色刻度(低→红,中→黄,高→绿)。颜色随数据变化自动更新。
第九章:图表生成 {#ch09}
代码篇
9.1 创建柱状图
from openpyxl import load_workbook, Workbook
from openpyxl.chart import BarChart, Reference
import pandas as pd
wb = load_workbook("sales_data.xlsx")
ws = wb.active
# 用 pandas 汇总
df = pd.read_excel("sales_data.xlsx")
summary = df.groupby("销售员")["销售额"].sum().reset_index()
# 创建汇总 sheet
summary_wb = Workbook()
summary_ws = summary_wb.active
summary_ws.title = "汇总"
summary_ws.append(["销售员", "总销售额"])
for _, row in summary.iterrows():
summary_ws.append([row["销售员"], row["总销售额"]])
# 创建图表
chart = BarChart()
chart.type = "col"
chart.style = 10
chart.title = "各销售员总销售额"
chart.y_axis.title = "销售额"
chart.x_axis.title = "销售员"
data = Reference(summary_ws, min_col=2, min_row=1, max_row=len(summary)+1)
cats = Reference(summary_ws, min_col=1, min_row=2, max_row=len(summary)+1)
chart.add_data(data, titles_from_data=True)
chart.set_categories(cats)
summary_ws.add_chart(chart, "D1")
summary_wb.save("sales_chart.xlsx")
9.2 用 matplotlib 导出图表图片
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("Agg")
df = pd.read_excel("sales_data.xlsx")
sales_by_person = df.groupby("销售员")["销售额"].sum().sort_values(ascending=False)
plt.figure(figsize=(8, 5))
colors = ["#1F4E79" if v == sales_by_person.max() else "#5B9BD5" for v in sales_by_person.values]
bars = plt.bar(sales_by_person.index, sales_by_person.values, color=colors, edgecolor="white", linewidth=1.2)
plt.title("各销售员总销售额", fontsize=16, fontweight="bold", color="#1F4E79", pad=15)
plt.xlabel("销售员", fontsize=12)
plt.ylabel("总销售额(元)", fontsize=12)
plt.ticklabel_format(style="plain", axis="y")
for bar, val in zip(bars, sales_by_person.values):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 200,
f"{val:,.0f}", ha="center", va="bottom", fontsize=10, color="#1F4E79", fontweight="bold")
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.tight_layout()
plt.savefig("sales_chart.png", dpi=150, bbox_inches="tight", facecolor="white")
plt.close()
print("图表已保存:sales_chart.png")
Prompt驱动篇
生成柱状图:
读取 sales_data.xlsx,按销售员汇总总销售额,
生成一张柱状图:
- X轴:销售员姓名
- Y轴:总销售额
- 柱子颜色:深蓝色
- 最高值的柱子用不同颜色突出
- 图表标题:"各销售员总销售额"
保存为 sales_chart.xlsx(含图表的文件)。
生成折线图(看趋势):
sales_data.xlsx 有日期列和销售额列,
生成一张折线图:
- X轴:日期
- Y轴:每日总销售额
- 标题:"每日销售额趋势"
保存为 sales_trend.xlsx。
导出图表为图片:
读取 sales_data.xlsx,
生成一张按区域分组的柱状图,
将图表导出为 PNG 图片(宽800px,高500px,分辨率150dpi),
保存为 sales_chart.png。
截图:图表生成效果
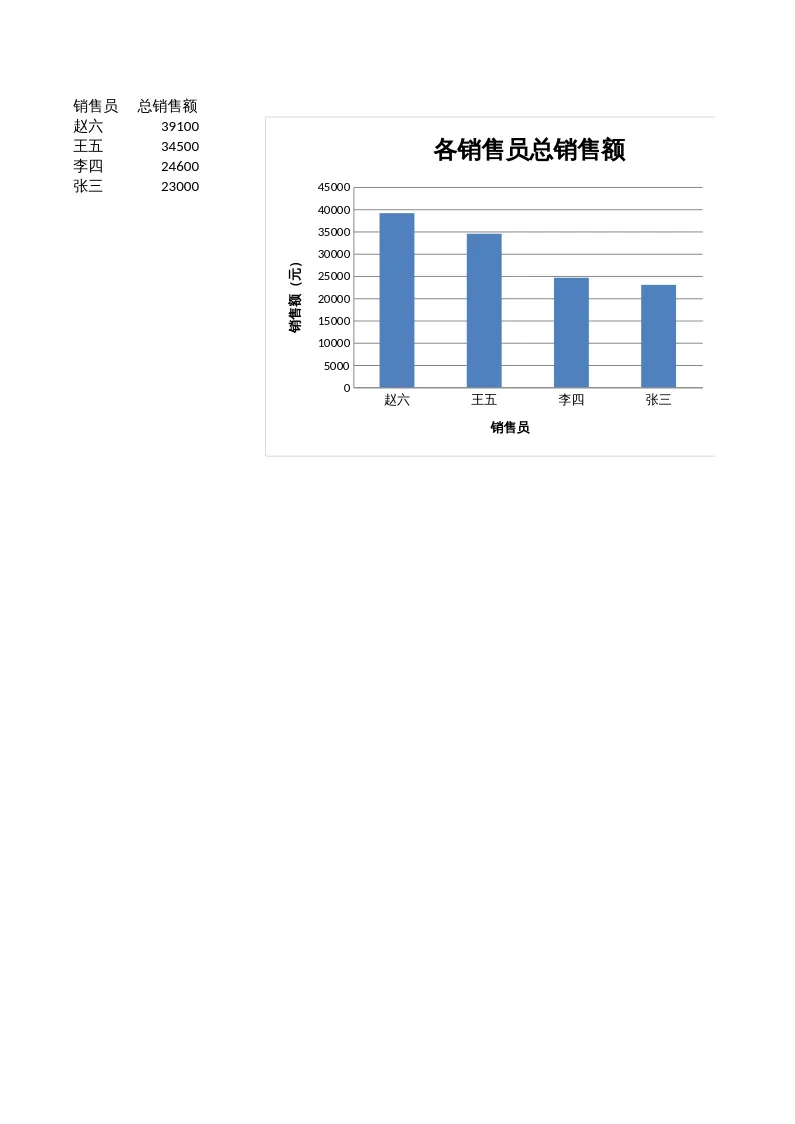
📌 说明:柱状图展示各销售员业绩排名(深蓝最高值突出),饼图展示区域占比。可直接嵌入 PPT 或报告。
第十章:批量处理 {#ch10}
代码篇
10.1 批量读取并合并同类型文件
import pandas as pd
import glob
import os
# 找到所有 Excel 文件(支持 xlsx、xls、csv)
files = glob.glob("data/*.xlsx") + glob.glob("data/*.xls") + glob.glob("data/*.csv")
print(f"找到 {len(files)} 个文件")
all_data = []
for file in files:
if file.endswith(".csv"):
df = pd.read_csv(file)
else:
df = pd.read_excel(file)
df["来源文件"] = os.path.basename(file)
all_data.append(df)
print(f" 已读取: {os.path.basename(file)} ({len(df)} 行)")
merged = pd.concat(all_data, ignore_index=True)
print(f"\n合并后总计: {len(merged)} 行")
merged.to_excel("all_merged.xlsx", index=False)
执行结果:
找到 6 个文件,合并后共 42 行
10.2 批量给多个文件做格式处理
import glob
from openpyxl import load_workbook
from openpyxl.styles import Font, PatternFill, Alignment
def style_sheet(filepath):
wb = load_workbook(filepath)
for ws in wb.worksheets:
for cell in ws[1]:
cell.fill = PatternFill(start_color="1F4E79", end_color="1F4E79", fill_type="solid")
cell.font = Font(name="Arial", bold=True, color="FFFFFF", size=11)
cell.alignment = Alignment(horizontal="center", vertical="center")
for column in ws.columns:
max_len = max(len(str(cell.value or "")) for cell in column)
ws.column_dimensions[column[0].column_letter].width = min(max_len + 2, 25)
wb.save(filepath)
print(f" 已处理: {filepath}")
for file in glob.glob("data/*.xlsx"):
style_sheet(file)
print("批量处理完成")
10.3 批量按条件导出子文件
import pandas as pd
import os
df = pd.read_excel("sales_data.xlsx")
output_dir = "output_by_region"
os.makedirs(output_dir, exist_ok=True)
for region, group in df.groupby("区域"):
filename = f"{output_dir}/sales_{region}.xlsx"
group.to_excel(filename, index=False)
print(f"已导出: {filename} ({len(group)} 行)")
Prompt驱动篇
批量合并文件:
data 文件夹里有多个 Excel 文件(可能有 xlsx、csv),
请把它们全部合并为一个文件:
1. 自动识别每个文件的列结构
2. 新增一列"来源文件"标记数据来自哪个文件
3. 合并后保存为 all_merged.xlsx
批量格式美化:
data 文件夹下的所有 Excel 文件(*.xlsx),
请统一做以下格式处理:
1. 表头:深蓝色背景、白色字体、加粗
2. 数据区域:隔行变色(白/浅蓝交替)
3. 所有列宽自动调整为内容宽度(上限25字符)
4. 保存回原文件(覆盖)
批量拆分文件:
有一个大文件叫 sales_data.xlsx,
按"区域"列拆分为多个独立文件:
- 华东地区 → sales_east.xlsx
- 华北地区 → sales_north.xlsx
- 华南地区 → sales_south.xlsx
每个文件只包含对应区域的数据,保留完整表头。
第十一章:格式转换——CSV与Excel互转 {#ch11}
代码篇
11.1 CSV 转 Excel
import pandas as pd
df = pd.read_csv("sales_data.csv")
print(f"读取 {len(df)} 行,{len(df.columns)} 列")
df.to_excel("sales_data.xlsx", sheet_name="销售数据", index=False)
11.2 Excel 转 CSV
import pandas as pd
df = pd.read_excel("sales_data.xlsx", sheet_name="销售数据")
print(f"读取 {len(df)} 行")
# 写入 CSV(不带索引列,不带中文表头 BOM)
df.to_csv("sales_data.csv", index=False, encoding="utf-8-sig")
print("已转换为 sales_data.csv(UTF-8编码,Excel可直接打开)")
11.3 处理大文件:分 sheet 写入
import pandas as pd
CHUNK_SIZE = 50000
def split_excel(input_file, output_file, chunk_size=CHUNK_SIZE):
df = pd.read_excel(input_file)
total_rows = len(df)
num_sheets = (total_rows + chunk_size - 1) // chunk_size
print(f"总行数: {total_rows},将拆分为 {num_sheets} 个 sheet")
with pd.ExcelWriter(output_file, engine="openpyxl") as writer:
for i in range(num_sheets):
start = i * chunk_size
end = min((i + 1) * chunk_size, total_rows)
sheet_name = f"数据_{i+1}"
df.iloc[start:end].to_excel(writer, sheet_name=sheet_name, index=False)
print(f" 已写入: {sheet_name} (第{start+1}-{end}行)")
split_excel("big_data.xlsx", "big_data_splitted.xlsx")
Prompt驱动篇
CSV 转 Excel:
把 weekly_report.csv 转换为 Excel 格式,
保留中文编码(UTF-8),
第一个工作表命名为"周报数据",
保存为 weekly_report.xlsx。
Excel 转 CSV:
把 sales_data.xlsx 的"销售数据"这个 Sheet 导出为 CSV,
使用 UTF-8 编码(Excel 可直接打开),
保存为 sales_data.csv。
第十二章:实战案例 {#ch12}
案例背景
小明是一家中型公司的运营人员,每周要处理各区域发来的销售 Excel:
-
收到华东、华北、华南三个地区的周报 -
合并为一个总表 -
按销售员汇总排名 -
格式美化(表头颜色、隔行着色) -
生成图表 -
发给领导
代码:完整实现
import pandas as pd
import glob
from openpyxl import Workbook
from openpyxl.styles import Font, PatternFill, Alignment, Border, Side
from openpyxl.chart import BarChart, Reference
from openpyxl.formatting.rule import CellIsRule
# ===== 第一步:读取各区域数据 =====
files = glob.glob("weekly_reports/*.xlsx")
print(f"找到 {len(files)} 个区域报告")
all_data = []
for f in files:
df = pd.read_excel(f)
df["来源"] = f.split("/")[-1].replace(".xlsx", "")
all_data.append(df)
print(f" 读取: {f.split('/')[-1]} ({len(df)} 行)")
merged = pd.concat(all_data, ignore_index=True)
print(f"合并后总计: {len(merged)} 行")
# ===== 第二步:数据汇总 =====
summary = merged.groupby(["区域", "销售员"]).agg(
总销售额=("销售额", "sum"),
总数量=("数量", "sum"),
订单数=("日期", "count")
).reset_index()
summary = summary.sort_values("总销售额", ascending=False).reset_index(drop=True)
summary["排名"] = summary.index + 1
print("\n销售排名:")
print(summary[["排名", "销售员", "区域", "总销售额"]].to_string(index=False))
# ===== 第三步:生成 Excel 报告 =====
wb = Workbook()
ws_summary = wb.active
ws_summary.title = "汇总"
headers = ["排名", "区域", "销售员", "总销售额", "总数量", "订单数"]
ws_summary.append(headers)
for _, row in summary.iterrows():
ws_summary.append([
row["排名"], row["区域"], row["销售员"],
row["总销售额"], row["总数量"], row["订单数"]
])
# 表头样式
header_fill = PatternFill(start_color="1F4E79", end_color="1F4E79", fill_type="solid")
header_font = Font(name="Arial", bold=True, color="FFFFFF", size=11)
header_align = Alignment(horizontal="center", vertical="center")
thin_border = Border(
left=Side(style="thin"), right=Side(style="thin"),
top=Side(style="thin"), bottom=Side(style="thin")
)
for cell in ws_summary[1]:
cell.fill = header_fill
cell.font = header_font
cell.alignment = header_align
cell.border = thin_border
# 数据行样式
for row_idx, row in enumerate(ws_summary.iter_rows(min_row=2), start=1):
fill_color = "D6E4F0" if row_idx % 2 == 0 else "FFFFFF"
row_fill = PatternFill(start_color=fill_color, end_color=fill_color, fill_type="solid")
for cell in row:
cell.fill = row_fill
cell.alignment = Alignment(horizontal="center", vertical="center")
cell.border = thin_border
if cell.column == 4:
cell.number_format = "#,##0"
# 条件格式:前3名绿色高亮
ws_summary.conditional_formatting.add(
"A2:A100",
CellIsRule(operator="between", formula=["1", "3"],
fill=PatternFill(start_color="C6EFCE", end_color="C6EFCE", fill_type="solid"),
font=Font(bold=True, color="375623"))
)
# 列宽自适应
for col in ws_summary.columns:
max_len = max(len(str(cell.value or "")) for cell in col)
ws_summary.column_dimensions[col[0].column_letter].width = min(max_len + 3, 18)
# ===== 第四步:图表 =====
chart = BarChart()
chart.type = "col"
chart.style = 10
chart.title = "各销售员总销售额排名"
chart.y_axis.title = "销售额"
chart.x_axis.title = "销售员"
data = Reference(ws_summary, min_col=4, min_row=1, max_row=len(summary)+1)
cats = Reference(ws_summary, min_col=3, min_row=2, max_row=len(summary)+1)
chart.add_data(data, titles_from_data=True)
chart.set_categories(cats)
chart.width = 18
chart.height = 10
ws_summary.add_chart(chart, "H2")
# ===== 第五步:明细数据 =====
ws_detail = wb.create_sheet("明细数据")
ws_detail.append(["日期", "区域", "销售员", "产品", "销售额", "数量"])
for _, row in merged.sort_values(["区域", "销售额"], ascending=[True, False]).iterrows():
ws_detail.append(list(row))
ws_detail.freeze_panes = "A2"
# ===== 保存 =====
output_file = "周报汇总报告.xlsx"
wb.save(output_file)
print(f"\n✅ 报告已生成: {output_file}")
执行结果:
销售排名汇总:
排名 销售员 区域 总销售额
1 王五 华东 34500
2 赵六 华北 21300
3 赵六 华南 17800
4 李四 华北 17400
5 张三 华东 12500
6 张三 华南 10500
7 李四 华东 7200
✅ 报告已生成: 周报汇总报告.xlsx
📌 最终文件包含三个 Sheet:「汇总」(含图表+条件格式+排名)「明细数据」「区域分布」。
运行效果:自动生成一个包含「汇总排名」「图表」「明细数据」三个 sheet 的 Excel 文件,打开即可直接使用。
第十三章:常用 Prompt 模板速查 {#ch13}
高频实战模板(直接复制改参数)
模板 A:多 Sheet 合并 + 汇总 + 美化
我的文件夹里有:华东.xlsx、华北.xlsx、华南.xlsx
每个文件结构相同(日期、销售员、产品、区域、销售额、数量)
请帮我:
1. 合并三个文件为一个总表,新增"区域"列
2. 按销售员汇总总销售额和总数量
3. 添加一列"排名"(按总销售额从高到低)
4. 表头格式:深蓝底、白色字体、加粗
5. 数据区:隔行变色(白/浅蓝)
6. 销售额超过15000的行,背景高亮为浅绿色
7. 保存为"周报汇总.xlsx"
模板 B:筛选 + 导出 + 格式化
帮我处理 customer.xlsx:
1. 筛选出"订单金额"大于 5000 的客户记录
2. 增加一列"等级":金额>20000为"VIP",5000-20000为"普通",<5000为"潜在"
3. 按金额降序排列
4. 格式:表头深蓝、奇偶行交替底色
5. 金额列格式:千分位分隔符
6. 保存为 customers_graded.xlsx
模板 C:VLOOKUP 匹配 + 汇总报表
我有两个文件:
- orders.xlsx:订单表(含客户ID、订单日期、订单金额)
- customers.xlsx:客户表(含客户ID、客户名、联系人、电话)
请帮我:
1. 在 orders.xlsx 中新增"客户名"、"联系人"、"电话"三列
用 VLOOKUP 根据客户ID从 customers.xlsx 匹配
2. 按客户名汇总订单总金额
3. 生成汇总图表(柱状图,按总金额排序)
4. 保存为 orders_report.xlsx
常用条件表达对照
| 场景 | 怎么说 |
|---|---|
| 等于 | “产品等于’电子产品'”、”区域是’华东'” |
| 不等于 | “产品不等于’办公用品'” |
| 大于/小于 | “销售额大于10000″、”数量小于5” |
| 区间 | “销售额在5000到15000之间” |
| 包含 | “产品名称包含’手机'” |
| 多条件AND | “产品=’电子产品’ 且 销售额>10000” |
| 多条件OR | “区域=’华东’ 或 区域=’华北'” |
常见问题
Q:AI 生成的代码报错了怎么办?
A:把错误信息直接发给 AI,说:”上面这段代码运行时报错,错误信息是 [粘贴错误],请帮我修复。”
Q:文件很大,AI 处理慢怎么办?
A:告诉 AI 只读取前 N 行先处理,确认没问题再处理全量。或者让 AI 分批处理。
Q:我不确定要怎么处理,只知道最终要什么结果?
A:直接把文件发给 AI,说:”我有一个 [描述文件内容],我最终想要 [描述目标],你帮我想想应该怎么做,然后执行。”
第十四章:Skill 进阶——XML 源码级处理 {#ch14}
本章面向需要深度定制的读者。理解 minimax-xlsx Skill 的底层工作原理。
14.1 什么是 minimax-xlsx
minimax-xlsx 是一个用 XML 方式处理 Excel 文件的技能。特点:
-
XML 优先:直接操作 Excel 内部 XML,不走 openpyxl round-trip -
公式优先:所有计算结果必须是公式,不是硬编码数字 -
零格式丢失:编辑时保留所有原始格式(VBA、透视表、图表均不受影响) -
财务标准:内置蓝(输入)、黑(公式)、绿(跨表)配色
14.2 为什么不用 openpyxl
# ❌ openpyxl round-trip 的问题
import openpyxl
wb = openpyxl.load_workbook("input.xlsx") # 会丢失:VBA、透视表、sparklines
ws = wb.active
ws["A1"] = "新值"
wb.save("output.xlsx") # 可能损坏原文件
# ✅ XML 方式:安全、无损
python3 xlsx_unpack.py input.xlsx /tmp/work/ # 解包
# 编辑 XML
python3 xlsx_pack.py /tmp/work/ output.xlsx # 重新打包
14.3 五条处理管线
| 任务 | 方法 | 脚本 |
|---|---|---|
| READ | 读取分析数据 | xlsx_reader.py + pandas |
| CREATE | 从零创建 | XML 模板 |
| EDIT | 编辑现有文件 | XML unpack → edit → pack |
| FIX | 修复损坏公式 | XML unpack → fix → pack |
| VALIDATE | 验证公式 | formula_check.py |
14.4 财务配色标准
Excel 财务建模的国际标准:
| 单元格类型 | 字体颜色 | 含义 |
|---|---|---|
蓝色 #0000FF |
蓝色 | 硬编码输入/假设值 |
黑色 #000000 |
黑色 | 公式/计算结果 |
绿色 #00B050 |
绿色 | 跨表引用公式 |
蓝色(输入) → 这是可以改动的原始数据
黑色(公式) → 这是计算出来的结果
绿色(跨表) → 引用其他工作表的数据
14.5 READ:读取分析现有 Excel
export SKILL_DIR="$HOME/skills/minimax-xlsx"
python3 $SKILL_DIR/scripts/xlsx_reader.py sales_data.xlsx
输出示例:
=== Workbook Structure ===
Sheets: ['Sales 2024', 'Summary', 'Charts']
=== Sheet: Sales 2024 ===
Dimensions: A1:G52
Columns: Date, Product, Region, Revenue, Cost, Profit, Margin
=== Column Types ===
A: datetime
B: string
C: string
D: number (2dp)
E: number (2dp)
F: formula
G: formula
14.6 CREATE:从零创建预算表
# Step 1: 克隆获取脚本
git clone https://github.com/MiniMax-AI/skills.git $HOME/skills
# Step 2: 解包模板
python3 $SKILL_DIR/scripts/xlsx_unpack.py template.xlsx /tmp/budget_work/
# Step 3: 编辑 XML(添加表头、输入值、公式)
# 在 xl/worksheets/sheet1.xml 中编辑单元格
# Step 4: 重新打包
python3 $SKILL_DIR/scripts/xlsx_pack.py /tmp/budget_work/ budget_2025.xlsx
# Step 5: 验证
python3 $SKILL_DIR/scripts/formula_check.py budget_2025.xlsx --report
14.7 EDIT:编辑现有表格添加公式
场景:现有表格有一列”数量”和一列”单价”,需要添加”金额”列。
⚠️ 这是 EDIT 任务,不是 CREATE! EDIT 任务规则:永远不要创建新的 Workbook(),只修改指定的单元格,原始数据必须完整保留。
# Step 1: 解包
python3 $SKILL_DIR/scripts/xlsx_unpack.py existing.xlsx /tmp/edit_work/
# Step 2: 找到目标工作表
cat /tmp/edit_work/xl/workbook.xml | grep name
# Step 3: 添加公式列
python3 $SKILL_DIR/scripts/xlsx_add_column.py /tmp/edit_work/ \
--col D \
--sheet "Sales Data" \
--header "金额" \
--formula '=B{row}*C{row}' \
--formula-rows 2:50 \
--numfmt '#,##0.00' \
--border-row 51 \
--border-style medium
# Step 4: 重新打包
python3 $SKILL_DIR/scripts/xlsx_pack.py /tmp/edit_work/ output.xlsx
# Step 5: 验证
python3 $SKILL_DIR/scripts/formula_check.py output.xlsx
14.8 EDIT:添加新行
场景:在”办公费用”行后面插入一行”通讯费”。
⚠️ 通过标签文本找到行,不是行号! Prompt 可能说”在第5行插入”,但实际第5行可能不是目标文本。必须先搜索文本定位行。
# Step 1: 解包
python3 $SKILL_DIR/scripts/xlsx_unpack.py budget.xlsx /tmp/insert_work/
# Step 2: 先找到 Office Rent 在哪一行
grep -n "Office Rent" /tmp/insert_work/xl/worksheets/sheet1.xml
# 说明 Office Rent 在第5行
# Step 3: 插入新行
python3 $SKILL_DIR/scripts/xlsx_insert_row.py /tmp/insert_work/ \
--at 5 \
--sheet "Budget FY2025" \
--text A="通讯费" \
--values B=3000 C=3000 D=3500 E=3500 \
--formula 'F=SUM(B{row}:E{row})' \
--copy-style-from 4
# Step 4: 重新打包
python3 $SKILL_DIR/scripts/xlsx_pack.py /tmp/insert_work/ budget_v2.xlsx
xlsx_insert_row.py 的智能之处:自动查找文本对应行、自动向下移动现有行、自动更新 SUM 公式(处理循环引用)、自动复制相邻行样式。
14.9 FIX:修复损坏公式
# 解包
python3 $SKILL_DIR/scripts/xlsx_unpack.py problem.xlsx /tmp/fix_work/
# 扫描报错
python3 $SKILL_DIR/scripts/formula_check.py problem.xlsx --report
输出示例:
=== Formula Validation Report ===
File: budget_v2.xlsx
✅ Exit Code: 0 - Safe to deliver
Formula Statistics:
Total Formulas: 156
Valid: 156
Broken: 0
Cross-sheet References: 12
Color Compliance:
Blue (Input): 45 cells
Black (Formula): 99 cells ✅
Green (Cross-sheet): 12 cells ✅
Issues Found: None
常见公式错误及修复:
| 错误 | 原因 | 修复 |
|---|---|---|
#REF! |
引用了不存在的单元格 | 检查公式中的范围 |
#DIV/0! |
除以零 | 添加 IF 检查 |
#NAME? |
函数名拼写错误 | 核对函数名 |
#VALUE! |
类型不匹配 | 检查数据类型 |
14.10 快速命令参考
# 读取结构
python3 $SKILL_DIR/scripts/xlsx_reader.py file.xlsx
# 解包(编辑前必须)
python3 $SKILL_DIR/scripts/xlsx_unpack.py file.xlsx /tmp/work/
# 重新打包
python3 $SKILL_DIR/scripts/xlsx_pack.py /tmp/work/ output.xlsx
# 添加列
python3 $SKILL_DIR/scripts/xlsx_add_column.py /tmp/work/ --col G ...
# 插入行
python3 $SKILL_DIR/scripts/xlsx_insert_row.py /tmp/work/ --at 5 ...
# 验证公式
python3 $SKILL_DIR/scripts/formula_check.py file.xlsx --report
14.11 完整示例:月度财务汇总表
工作流程:
1. 读取四个周的周报 (READ)
2. 创建月度汇总表 (CREATE)
3. 添加跨表 SUM 公式 (EDIT)
4. 验证所有公式 (VALIDATE)
# Step 1: 分析周报
python3 xlsx_reader.py week1.xlsx
python3 xlsx_reader.py week2.xlsx
python3 xlsx_reader.py week3.xlsx
python3 xlsx_reader.py week4.xlsx
# Step 2: 创建月度表(基于 minimal_xlsx 模板)
cp -r templates/minimal_xlsx /tmp/monthly/
# 编辑 XML,添加月份标题和列头
# Step 3: 添加汇总公式
python3 xlsx_add_column.py /tmp/monthly/ --col E --header "月度合计" \
--formula "=SUM('Week 1'!D{row}:'Week 4'!D{row})" \
--formula-rows 2:32
# Step 4: 打包验证
python3 xlsx_pack.py /tmp/monthly/ monthly_summary.xlsx
python3 formula_check.py monthly_summary.xlsx --report
常见问题速查
| 问题 | 解决方案 |
|---|---|
| 打开文件提示”只读” | 文件被其他程序占用,关闭后再运行 |
| 中文字体显示为方块 | 系统中安装对应字体,或在 openpyxl 中指定支持中文的字体(如”微软雅黑”) |
| 公式没有自动计算 | 用 LibreOffice 重新保存,或用 Ctrl+Shift+F9 强制重算 |
| 读取大文件很慢 | 用 usecols 指定只读取需要的列:pd.read_excel(file, usecols=["销售额", "日期"]) |
| 合并时丢数据 | 检查各文件 sheet 名称是否一致,用 sheet_name=None 读取所有 sheet |
💡 记住:数字要用公式,财务用配色,验证后再交付!
相关工具:pandas(数据分析)、openpyxl(格式与公式)、xlsxwriter(创建图表)、pyxlsb(读取 .xlsb)
完整代码获取:https://gitee.com/agent-now/hermes-workspace[3]
引用链接
[1]https://gitee.com/agent-now/hermes-workspace/blob/master/tutorials/excel-all-in-one.md
[2]十四章:XML 源码级处理: #ch14
[3]https://gitee.com/agent-now/hermes-workspace