 夜雨聆风
夜雨聆风





AI的"肉体觉醒":当智能从硅渣里走出来
引言:2026年的春天,AI界发生了两件看似毫无关联的事——一个乒乓球机器人登上了《Nature》杂志的封面;同一个月,全球最大的人形机器人制造商宣布已累计交付一万台。表面看,它们分属娱乐与工业两个赛道,但背后涌动的是同一股浪潮:AI正在长出身体,正在走出数据中心,正在接管物理世界中那些最需要”手感”的工作。 这不是渐进式的改进,而是一场关乎智能本质的结构性跃迁。如果我们把AI的2025年比作”大脑的青春期”,那么2026年就是它”身体成熟”的元年——数字智能第一次以完整的物理形态,与这个由原子构成的世界产生了深度共鸣。
一、一个乒乓球机器人,何以登上《Nature》
2026年4月22日,索尼AI团队在《Nature》正刊发表论文,宣布其自主研发的乒乓球机器人”Ace“在正式比赛中击败了多名人类精英球员。这不是机器人第一次打乒乓球——但这是机器人第一次在完整规则下战胜精英级人类选手,从而在《Nature》这样的基础科学顶刊上占据一席之地。这一事件的影响远超体育本身:它证明AI可以在高度动态、不确定、对抗性的物理环境中实现超人类水平的操作能力。
1.1 20毫秒:人与机器的代差
乒乓球是世界上球速最快的球拍运动之一。顶级球员击球转速可超过450弧度/秒,球离开球拍到对方球台的距离不足两米,留给对手的净反应时间通常只有几百毫秒。更棘手的是,乒乓球的旋转是所有球拍运动中最复杂的——上旋、下旋、侧旋及其组合产生的气流效应让球的飞行轨迹极难预判,这也是为什么业余球员面对专业选手的发球常常”吃旋转”。
人类的平均反应延迟约为230毫秒(包括视觉信号传递、大脑处理、运动指令发出和肌肉执行的总时间),而Ace的端到端系统延迟只有20.2毫秒——快了整整11倍。这意味着Ace有近乎”奢侈”的时间裕度来完成从感知到执行的完整闭环:它看到球飞来的方向和旋转,在大脑(控制模型)中计算最优回球策略,驱动机械臂在精确的时刻以精确的角度挥出。人类选手穷尽一生训练出的”球感”,本质上是在大脑中建立了一个高效的下意识预测-执行模型;而Ace用20毫秒的延迟和强化学习,在虚拟对战中把这个模型训练到了超越人类精英的水平。
1.2 强化学习:从虚拟到物理的”迁移魔咒”
游戏AI(如AlphaGo、Atari游戏、Gran Turismo Sophy)早已证明强化学习(Reinforcement Learning, RL)在封闭规则环境中的强大威力。AlphaGo可以在19×19的棋盘上将所有可能的状态空间穷举搜索,Gran Turismo Sophy可以在赛车游戏中实现超人类圈速。但这些成功大多局限于数字域——环境可精确模拟,物理规律不会因模拟误差而崩溃。
机器人技术在物理世界中应用强化学习,长期受困于”模拟-现实迁移”(Sim-to-Real Transfer)问题。理论上,用精确的物理引擎在虚拟环境中训练机器人是最高效的——可以每秒生成数万次交互数据,比真实机器人快数万倍。但现实是:虚拟环境中的摩擦系数、关节柔性、传感器噪声、地面不平整度永远无法被完美建模。在虚拟中表现完美的策略,一部署到真实硬件上就可能出现性能断崖式下降(”sim-to-real gap”)。
Ace的突破性在于它绕过了这个陷阱。索尼AI团队没有试图构建一个完美的乒乓球物理模拟器,而是让机器人在真实环境中进行大规模自主对打。论文披露,在Nature论文提交前后的多轮评估中,Ace持续与不同水平的人类球员对打,持续用真实交互数据改进策略。最关键的一个细节是:即使球触网后产生不规则弹跳这类”稀有事件”,Ace也能迅速适应,因为它学会了在没有明确物理模型的情况下处理意外。这种从真实失败中快速学习的能力,是”纯模拟训练”路线无法企及的。
1.3 超越体育:一张改变游戏规则的入场券
Ace在赛场上赢得的那三场胜利,意义远远超出了乒乓球本身。它的真正宣言写在论文的结论里:”证明了AI系统能够在动态物理环境中安全可靠地运行,其应用范围从安全关键场景延伸至实时交互领域。 “
翻译成更直白的语言:能打赢乒乓球选手的机械臂,稍加改装就能上手术台协助外科医生精细缝合,能当拆弹专家在复杂地形中处理未爆弹药,能进核电站执行高精度巡检和简单维护任务。乒乓球是一块最经济、最高效的”能力试金石”——它高度压缩了对快速感知、精准控制、对抗性决策、人机协作的全部挑战,且成本可控、规则清晰、失败代价可承受。
更值得关注的是Ace的持续进化能力。索尼AI在论文被接受后继续进行对抗测试,2026年3月的最新结果显示Ace已经可以击败初次交手的职业选手——这说明它的能力还在上升通道中,还没有触到天花板。
二、2026″具身智能元年”:一万台机器人背后的产业信号
如果说Ace代表的是具身智能的技术可行性证明,那么2026年3月发生的一件事则代表了另一层维度的突破——大规模商业可行性。中国机器人公司AGIBOT宣布,其第10000台人形机器人于2026年3月正式下线。同月,AGIBOT在年度合作伙伴大会(APC 2026)上宣布将2026年定位为”部署元年“(Deployment Year One),正式从概念验证全面转向规模交付。
这则消息的重量,需要放在整个具身智能产业的发展脉络中才能看清。
2.1 从”你可以”到”你来做”:跨越最后一步
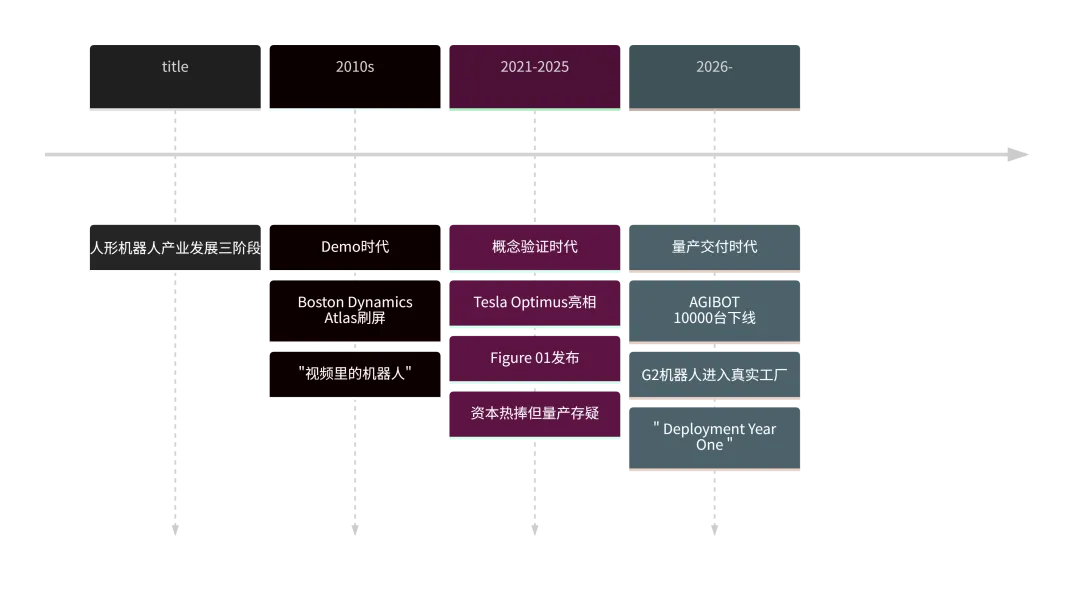
过去十年,人形机器人赛道经历了清晰可辨的三轮叙事迭代:
第一轮(2010年代) :Demo时代。波士顿动力的Atlas翻跟斗、跑酷的视频一次次刷屏全球,但永远是”视频里的机器人”,量产时间表永远停留在”未来几年”。业界逐渐形成了一种”狼来了”的疲惫感——人们开始怀疑人形机器人是否永远只是橱窗里的展品。
第二轮(2021-2025) :概念验证时代。特斯拉Optimus、Figure 01、小鹏PX5等项目相继亮相,资本市场热捧,相关股票估值冲天。但大规模部署始终是”明天的事”——技术成熟度、成本控制、场景适配三大问题悬而未决。
第三轮(2026年起) :量产交付时代。AGIBOT的10000台不是来自融资PPT,而是来自真实的生产线、真实的客户、真实的上岗数据。这是一个本质性的跨越——它意味着具身智能不再是”可以被讨论的技术可能性”,而是一个”正在发生的经济事实”。
2.2 工厂里的”G2″:99.9%成功率的制造业实证
AGIBOT在APC 2026上透露的具体运营数据,才是这则消息最”硬”的部分:其G2人形机器人已在龙旗科技(Longcheer Technology)位于南昌的生产线上岗,负责平板电脑的测试与分拣,每小时可处理310台次,成功率超过99.9% 。
99.9%的成功率对于制造业意味着什么?目前全球顶级代工厂(富士康、比亚迪等)的人工分拣成功率大约在99.5%-99.7%之间,考虑到机器人不需要休息、不会疲劳、不会因情绪波动降低质量,99.9%的自动化分拣实际上已经超越了人类操作工的平均水平。
这个数字的重要性还在于它揭示了具身智能的第一个”正向飞轮”:机器人上岗产生真实数据 → 数据用于训练更好的操控模型 → 更好的模型提升成功率 → 成功率提升吸引更多客户采购 → 更多部署产生更多数据。这个飞轮一旦转动起来,规模效应将使具身智能的成本快速下降,预计在未来3-5年内达到与人工成本交叉的临界点。
2.3 “一机三脑”:AGIBOT的架构哲学
AGIBOT将自身技术框架命名为”一机三脑“(One Robotic Body, Three Intelligences):
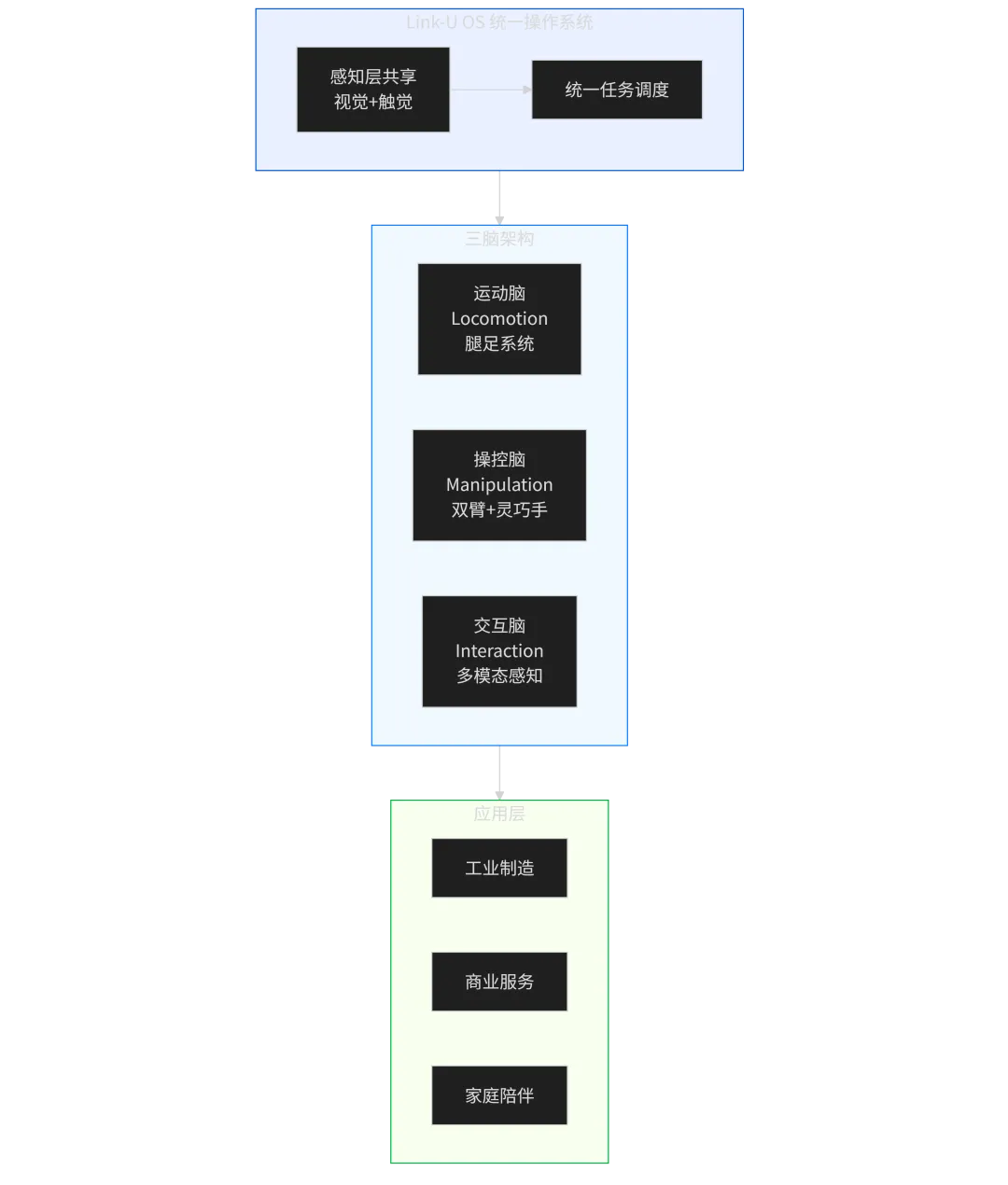
这不是营销概念,而是对具身智能任务逻辑的精确分解:
-
• 运动智能(Locomotion Intelligence):行走、奔跑、上下楼梯、避障导航,对应机器人的腿足系统,是进入物理世界的基础前提 -
• 操控智能(Manipulation Intelligence):抓取、装配、精密操作,对应双臂和灵巧手机器,是替代人类劳动的核心能力 -
• 交互智能(Interaction Intelligence):理解自然语言指令、感知情绪状态、主动学习新任务,对应机器人的”大脑皮层”,是实现通用性的关键
三者在感知层共享视觉和触觉信号,在决策层通过统一的神经网络进行任务调度,在执行层映射到各自的硬件控制器。这套架构的工程意义在于:它把具身智能从”分别攻克单点能力”的垂直攻关模式,转化成了”系统集成和智能调度”的基础设施构建模式——类似于智能手机产业的发展路径:真正的壁垒不是屏幕、芯片或摄像头各自的技术指标,而是整个系统整合后的用户体验。
2.4 AIMA:机器人时代的”安卓生态”
AGIBOT在APC 2026上发布了名为AIMA(AI Machine Architecture)的全栈开放架构,这套系统的设计雄心甚至超出了具身智能本身:
-
• Link-U OS:统一机器人操作系统,负责硬件抽象和实时任务调度 -
• LinkCraft:运动创作平台,提供可视化运动编程工具,降低运动控制开发门槛 -
• LinkSoul:交互设计平台,内置多模态大模型接口,支持自然语言任务配置 -
• Genie Studio:任务开发平台,提供端到端任务编排和调试环境 -
• AGIBOT Embodied Agent Framework:面向商业、工业、家庭场景的可扩展智能体框架
这套系统的目标用户不只是AGIBOT自己的工程师——它面向所有希望基于AGIBOT硬件开发机器人应用的第三方开发者。这是AGIBOT从”机器人公司”向”机器人平台公司”转型的战略宣言。类比智能手机产业:AGIBOT的角色类似于苹果(自有硬件+系统整合),而AIMA的开放层则对应安卓的开放生态——吸引全球开发者基于其框架开发各类垂直应用,从而快速扩大整个生态系统的可用场景数量。
AGIBOT计划未来五年投资超过20亿元人民币用于生态建设,目标是扶持数千家合作伙伴、培养大规模的开发者社区。这一投资规模和对标生态的思路,表明AGIBOT的管理层对具身智能的判断是:硬件销售只是第一波收入,真正的长期价值在于开发者生态的平台效应。
三、亚马逊买下”种子”:巨头的具身智能卡位战
就在AGIBOT宣布万台部署的同一月份,大洋彼岸传来另一则收购消息——亚马逊收购了Fauna Robotics的人形机器人产品”Sprout” 。Fauna是一家以色列机器人初创公司,Sprout是其首款商业化的人形双臂机器人,定位为面向家庭和商业场景的通用操作平台。
这笔交易的战略意图不言而喻:亚马逊正在将其在物流仓储领域积累的机器人部署经验,从轮式AGV推向双臂人形操作机器人,从搬运扩展到需要手臂精细操作的全面仓储自动化。
3.1 亚马逊的”最后一公里”执念
亚马逊在仓储自动化上的投入已经是全球最激进的。从2012年以7.75亿美元收购Kiva Systems(现Amazon Robotics)开始,亚马逊的仓库中运行着超过75万台机器人,遍布全球的 fulfillment center。但这些机器人大多数是轮式AGV(自动导引车),能力极其专一且局限:它们只能沿着预设路径在仓库中运输货架,从A点移动到B点,无法处理任何需要手臂操作的任务。
在亚马逊的仓库运营中,真正消耗人力的不是”搬运”环节——那是Kiva机器人最擅长的——而是”分拣”环节:从货架上取下商品(抓取)、检验商品状态(精细操作)、将商品装入包装盒(装配)。这些工作需要手臂、手腕和手指的协调配合,是轮式AGV完全无法涉足的领域。
随着人力成本持续上升和北美劳动力短缺成为结构性挑战(美国仓储行业目前约有30%的岗位空缺率),亚马逊对”能动手的机器人”的需求已经不是远期战略布局,而是当下经营压力。据内部估算,如果人形机器人能在亚马逊的仓库中替代50%的”分拣-包装”岗位,每年可节省超过50亿美元的人力成本——这笔账足以支撑对具身智能技术的激进投资。
3.2 大厂竞速:具身智能的”军备竞赛”图谱
亚马逊收购Fauna只是这场人形机器人军备竞赛的一个缩影。2026年,科技巨头们对具身智能的布局已经形成了清晰的竞速格局:

数据来源:各公司2026年公开披露信息 | 截至2026年4月
中美双雄格局已经基本成型。中国公司(AGIBOT、Unitree、Leju)在量产速度和场景覆盖广度上暂时领先,已进入”交付即上岗”的商业正循环;美国公司(Tesla、Figure、Amazon)在AI能力整合(尤其与大语言模型的深度耦合)和品牌影响力上保持优势;而索尼这样的日本精密制造巨头则选择单点技术突破(Ace代表的是极致性能,而非量产经济性)作为差异化路径。
3.3 从”替代”到”增强”:人机协作的新范式
在这场宏大的叙事中,一个细微但重要的转变正在悄然发生:早期关于”机器人抢工作”的讨论,正在被越来越多的”人机协作增强”(Human-Robot Collaboration)案例所稀释。
在AGIBOT已经部署G2机器人的龙旗科技工厂里,机器人并不是独立工作的——每个机器人操作站旁边都配有一名工人,工人负责监督机器人的操作、在异常情况下介入、以及处理需要灵活判断的边缘案例。这种”人类监督+机器执行”的工作模式,正在成为制造业人机协作的初期主流形态。
它带来的结果是:单个工人的产能放大了——以前一个人做310台/小时的分拣,现在一个人可以监督3-5台机器人同时运行,整体产出达到1550台/小时以上,而工人本身的体力劳动强度大幅降低。这不是”人 vs 机器人”的对决,而是人机混合劳动力对传统纯人力劳动力的系统性竞争优势。
四、DeepSeek V4:百万Token-context打开”记忆封印”
就在具身智能在物理世界开疆拓土的同时,支撑这类复杂AI应用运行的基础模型也在经历一场静悄悄的革命——这次革命的主角是中国AI实验室DeepSeek。
2026年4月24日,DeepSeek发布V4系列,包含两个版本:DeepSeek-V4-Pro(1.6万亿总参数,490亿激活参数)和DeepSeek-V4-Flash(2840亿总参数,130亿激活参数)。最引人注目的特性不是参数量的又一次刷新(这个领域已经过了”唯参数论”的阶段),而是它们共同支持的 100万Token上下文窗口——这相当于约75万汉字,或一整部长篇小说的完整文本容量。
4.1 为什么100万Token是游戏规则改变者
要理解100万Token上下文的重要性,需要先理解当前大模型在实际Agent应用中的”上下文饥饿”问题。
目前主流大模型的上下文窗口通常在3.2万到12.8万Token之间,约合2万到10万汉字。这个长度对于处理单篇文档、生成一段代码已经绑绑够用,但面对真正复杂的AI Agent工作流,上下文空间很快就会被填满。
一个典型的复杂Agent任务链路可能是这样的:

每个工具调用(调用搜索API、代码执行API、数据库查询等)本身会消耗数百到数千Token的输入和输出,而一个复杂任务可能涉及数十次甚至数百次工具调用。当这些中间过程累积起来,现有模型的上下文窗口很快就被填满——更早的历史信息被”挤出”寄存器,模型开始出现”遗忘”问题,导致长程推理链路崩溃。
100万Token的上下文窗口从根本上改变了这个等式:它让Agent可以携带完整的任务历史横跨极长的执行链路而无需遗忘。DeepSeek-V4-Flash在13B激活参数的规模下实现了这一能力,意味着在消费级GPU(如RTX 4090,24GB显存)上运行一个能记住整部《红楼梦》的AI助手已经成为可能。
4.2 注意力机制的结构性创新:90% KV缓存削减
100万Token的上下文不是简单扩大内存就能实现的——Transformer架构中,注意力机制的计算复杂度随序列长度呈二次方增长(O(n²))。在100万Token上运行标准完整注意力,计算量和KV(Key-Value)缓存内存需求都是天文数字:假设每个Token的KV向量为1KB,100万Token的KV缓存就需要约1GB的存储空间,而这只是单次推理的内存需求,实际计算量更是可以达到PetaFLOP级别。
DeepSeek V4的核心技术创新在于其混合注意力架构(Hybrid Attention Architecture) ,包含两项关键设计:
-
• 压缩稀疏注意力(CSA, Compressed Sparse Attention) :利用局部性原理,对长序列中的稀疏高权重注意力区域(少数”关键Token”)进行精确注意力计算,对低权重区域(大量”普通Token”)进行轻量级压缩表示。CSA将单Token推理FLOPs降低到V3.2版本的27% -
• 重度压缩注意力(HCA, Heavily Compressed Attention) :将长尾Token序列(历史对话中已被”处理过”的部分)压缩为极低比特的键值表示,KV缓存内存削减到V3.2版本的10%
两项技术叠加,V4在100万Token上下文上的实际推理成本降到了可接受范围。NVIDIA在Blackwell架构(B200 GPU)上验证了V4的端到端推理流水线,将100万Token的端到端推理延迟控制在了数十秒级别(取决于batch size),这对于非实时应用已经完全可以接受。
4.3 AI Agent的”记忆觉醒”与通用性的曙光
理解这个突破的深层含义,需要把人脑的记忆系统做个类比。人类专家能够处理复杂问题,部分原因在于工作记忆(Working Memory)容量足够大——能够同时保持问题的完整上下文、多个子目标的追踪、以及跨步骤的推理线索。早期AI模型就像”金鱼脑”——记不住超过几段话的事情,只能处理简单的一次性任务。
DeepSeek V4将上下文窗口扩大一个数量级,结合对Agent工具调用能力的专门优化(体现在Terminal Bench 2.0等基准测试的显著提升),正在将AI系统从”单次查询处理器”(Query Processor)推进到 “持续任务执行者”(Continuous Task Executor) 的阶段。
这意味着:同一个AI Agent可以接管一个需要数小时甚至数天才能完成的复杂项目——它记住所有的中间结果、所有的决策上下文、所有的多轮交互历史。它可以像一名资深分析师一样,同时追踪数十个子任务的进展,在每个子任务中调用合适的工具,然后综合所有结果给出最终建议——整个过程中没有任何信息因为”上下文溢出”而被遗忘。
这是通用人工智能(AGI)之路上关键的一步:有限的上下文窗口一直是AI无法真正”持续思考”的结构性障碍,而百万Token上下文正在将这个障碍移除。
五、大脑启发芯片:能耗降低70%的物理极限突破
AI向物理世界的大规模渗透,遇到了一个无法回避的物理学约束:能耗。
以GPT-4o为代表的大语言模型,单次完整训练耗电约1吉瓦时(GWh),相当于一个小型城市数天的总用电量。全球数据中心用于AI推理的电力消耗正在以指数级速度增长——据Bernstein Research估算,到2026年底全球数据中心的电力消耗中AI相关负载将超过40%,到2030年这一比例可能攀升至15%以上,届时AI相关用电量可能占全球发电量的10%以上。
解决这个问题,不能只靠更多的GPU堆叠或更先进的制程节点——需要的是对计算范式的根本性重构。
5.1 剑桥大学的”仿生突触”
2026年4月,剑桥大学材料科学与冶金系的研究团队在《Nature》子刊发表研究,宣布开发出一种基于铪氧化物(hafnium oxide)的仿生忆阻器(memristor) ,可将AI硬件能耗降低最高70% 。
忆阻器(Memristor)是一种纳米电子器件,其核心理念是:器件的电阻值可以记住流经它的电荷历史——就像人脑中神经元突触的连接强度可以记住过去的激活模式一样。这一特性让忆阻器天然适合模拟神经网络中的权重存储:传统计算机中,计算(CPU)和存储(内存)是两个独立的物理单元,数据在其间来回搬运消耗了大量能量;而忆阻器中,计算和存储在同一个物理位置同时发生,数据搬运的距离从”CPU到内存”缩短到”同一个纳米器件内部”,这从根本上消除了冯·诺依曼架构中著名的”内存墙”(Memory Wall)问题。
剑桥团队的关键创新在于:他们开发了一种新型的多组分铪基薄膜材料(添加了锶和钛),通过在薄膜内部自组装形成p-n异质结(p-n heterointerface)。这种结构使得器件可以在极低电流(小于10纳安,比一根蚁腿还细一万倍)下实现稳定的多态切换——单个器件可以表达数百个不同的电导等级。相比之下,传统氧化物价键记忆体的开关电流高了约一百万倍。这就好比:在传统芯片中,开关一个晶体管需要的能量相当于举起一个苹果;而在剑桥的忆阻器中,开关一个存储单元需要的能量只相当于抬起一根羽毛——差距是一百万倍。
5.2 从”算法优化”到”架构重构”:范式转移的信号
过往的AI节能研究大多聚焦于算法层面:更高效的注意力机制(FlashAttention系列)、参数量化压缩(INT8/INT4)、稀疏激活(Mixture of Experts)。这些方法确实有效,但都是对同一计算范式(基于SRAM/DRAM和标准CMOS晶体管的冯·诺依曼架构)的”边际优化”——就像在燃烧汽油的内燃机汽车上加空气动力学套件,虽然有效,但无法改变汽油作为能量媒介的根本效率极限。
仿生忆阻器的意义在于它从硬件架构上重新定义了计算的基本单元。当每个忆阻器本身就是一个小型神经网络——既存储权重又执行计算——当”存算一体”(Computing-in-Memory)成为物理现实而非工程幻想,AI硬件的能效曲线将不再是线性改善,而是可能出现阶跃式跃升。
这与1980年代从大型机向个人电脑的范式转移有相似之处:最初的个人电脑CPU算力远不如大型机,但个人电脑的分布式架构后来演化出了整个互联网时代的计算基础设施。今天的忆阻器技术也许正处于”早期个人电脑”的阶段——笨拙、规模小、距离商业化还有距离,但方向是明确的。
5.3 具身智能的最后一块拼图
有趣的是,剑桥芯片的突破与具身智能的商业化进程形成了精确的呼应:具身智能需要在边缘端(机器人本体)部署大量AI算力——环境感知、实时决策、运动控制都需要在毫秒级延迟内完成——但机器人的电池容量、散热条件、机体重量都对芯片能效提出了极致要求。
举一个具体的数字:当前人形机器人内置的AI推理芯片(如NVIDIA Jetson或定制ASIC)在全力运行状态下功耗约为300-500瓦。这意味着即使装配了目前最高能量密度的电池,一台人形机器人满负荷运行的时间也很难超过3-4小时。这就是为什么现在大多数人形机器人的工作场景还是”插着电源的工厂机械臂”——续航问题尚未解决。
70%的能耗降低,意味着在同等电池容量下,机器人的续航时间可以从3小时延长到10小时以上——这将使”全天候工作”成为可能,并大幅降低机器人的电池和散热系统重量,从而改善整体机动性和成本。能效突破与具身智能的商业化进程是相互锁定的:只有芯片能效持续提升,机器人的续航和成本才能达到工业和家用场景的经济性门槛;而机器人大量部署后产生的海量真实场景数据,又会反哺AI模型的训练与优化,形成正向飞轮。
六、AI发现新物理:等离子体里的”非互惠力”
具身智能在”接管物理操作”的同时,另一种反向的渗透也在悄然发生——AI开始发现物理世界中此前未知的规律。
2026年4月23日,埃默里大学物理学家团队在《美国国家科学院院刊》(PNAS)发表论文,宣布他们使用物理启发的定制神经网络,从尘埃等离子体(dusty plasma)粒子的三维运动轨迹中发现了此前未被识别的非互惠力作用定律,模型的预测精度超过99% 。
这项研究的意义远超等离子体物理本身——它标志着AI从”数据分析工具”进化为”自然规律发现者”,从被动的数据处理者跃升为主动的知识创造者。
6.1 什么是非互惠力
要理解这项研究的意义,首先要理解它研究的对象——尘埃等离子体——及其中的非互惠力现象。
等离子体是物质的第四种状态(仅次于固态、液态、气态),是含有自由电子和离子的电离气体。宇宙中99%以上的可见物质都是等离子体——恒星内部、闪电划过天空时、电弧焊接时产生的电火花,都是等离子体。尘埃等离子体是等离子体中含有固体微粒(尘埃)的变体,广泛存在于行星环(如土星环,NASA卡西尼号已经观测到)、地球电离层、彗星尾部,以及——令人意外的是——野火烟雾中。
在尘埃等离子体这种介质中,粒子之间的相互作用有一个违反直觉的特性:非互惠性。经典物理学中,牛顿第三定律指出”相互作用的两个物体之间的作用力与反作用力大小相等、方向相反、作用于同一直线”——这就是”互惠力”。但在尘埃等离子体中,由于带电粒子会在周围形成复杂的电场屏蔽结构,粒子A对粒子B的力不等于粒子B对粒子A的力,方向也不一定相反。这就是”非互惠力”。
物理学家此前从理论上预言了这种力可能存在,但从未能在实验中精确测量和建模。原因是:非互惠力的效应被淹没在大量随机热运动(统计噪声)中,传统统计学方法难以将其分离出来——就像在喧闹的摇滚音乐会现场,试图听清某人耳语中的某个特定词汇,几乎不可能。
6.2 物理约束神经网络:打破”黑箱”诅咒
埃默里团队的核心创新在于其设计的物理约束神经网络(Physics-Informed Neural Network, PINN) 。
传统深度学习模型是”黑箱”——输入数据,输出预测,中间过程是一个庞大的矩阵乘法网络,工程师能做的只是调整参数让输出更接近目标,但对模型”如何得出这个结果”无法给出物理解释。这种”知其然不知其所以然”的特点在很多应用中是可接受的——我们不需要知道GPT-4是如何决定在某个位置写某个词的——但在发现新物理这个任务上,”黑箱”特性是致命的:人类物理学家无法从黑箱输出中提取出可验证的物理定律。
物理约束神经网络的创新在于:研究团队在训练过程中嵌入了已知的物理对称性和守恒定律作为模型的”强制性约束”——例如能量守恒、动量守恒、物理量纲一致性。如果模型的输出违反了这些约束,训练 loss 就会大幅增加,从而被强制纠正。这就好比告诉AI:”我不在乎你用什么数学函数来描述这件事,但你输出的结果必须满足能量守恒和动量守恒,违反的话我会重重惩罚你。”
在这种约束下,AI的搜索空间被大幅缩小:它不再需要浪费容量去拟合那些违反物理定律的虚假规律,从而能将全部建模能力集中在真实的新规律上。埃默里团队使用高分辨率3D粒子追踪技术(层析成像)在真空腔室中记录了数十个尘埃等离子体粒子的完整三维运动轨迹,然后输入到他们的物理约束神经网络中。模型从噪声中成功提取了非互惠力的模式——预测精度超过99%——更重要的是,它发现的力定律包含了一些让物理学家意外的项:粒子带电量与尺寸的关系远比此前理论预测的复杂,相互作用力的衰减率与粒子大小直接相关。
6.3 AI正在成为科学的”第二作者”
ScienceDaily在报道这则研究时使用了这样的标题:”AI just discovered new laws of nature inside dusty plasma”——AI在物质第四态(等离子体)中发现了自然定律。这不是媒体的语言夸张,而是对AI能力边界的精确描述。
人类历史上每次物理学的重大突破都伴随着”理解范式”的跃迁:

埃默里团队的这项工作暗示了第五种范式的曙光——AI驱动的新认识论。但需要注意的是:AI发现的新规律仍然需要人类物理学家来验证和诠释,将其翻译为人类可理解的数学语言和物理解释。AI在这里扮演的是”超级助手”的角色——它能在人类无法处理的高维数据空间中发现隐藏的结构,但最终的”科学解释权”仍然在人类手中。这让人想起开普勒利用第谷的观测数据发现行星运动定律的故事:开普勒是”AI”,第谷是”数据”,而行星运动定律是最终发现的”自然规律”——只不过这次,”开普勒”是一个神经网络。
七、AI长出手和脚之后:三个无法回避的问题
AI正在从数字世界向物理世界全面渗透——这是2026年正在发生的事情,不是2035年的远景规划。但这场浪潮带来的不只是技术进步和经济增长,还有三个需要整个社会共同面对的深层问题。它们不会因为我们回避而消失。
7.1 就业重构:当”手感”也被算法接管
人类历史上每一次重大自动化浪潮都引发过类似的就业焦虑。蒸汽机取代了纺织工,拖拉机取代了大量农业短工,自动化生产线取代了装配工人——每次技术革命都确实消灭了一些职业,但同时创造了更多新的职业,最终人类整体的劳动内容和收入水平都得到了提升。
但”具身AI”带来的冲击有其独特性:它首次威胁到了那些依赖”手感”的体力工作和依赖”经验”的半脑力工作。过去的工业机器人能替代重复性高的流水线操作,但无法应对柔性化生产、异常情况处理、与人协作的场景——因此工厂里总需要大量”人”来填补机器的盲区。
人形机器人的量产和成本下降,正在将这道”人机分界线”向越来越多的职业类别推进:
制造业:分拣、装配、质检、包装——这些需要手眼协调和精细触觉反馈的工作,正在被AGIBOT G1/G2等机器人替代。在龙旗科技的案例中,310台/小时、99.9%成功率的数据说明这个替代已经是实质性的。
物流仓储:搬运、上架、分拣——亚马逊、京东等企业的无人仓已经大量部署AGV,而双臂人形机器人Sprout的收购则标志着从”搬运”向”分拣-包装”的延伸。
商业服务:零售理货、餐饮后厨、酒店客房服务——Unitree G1已经开始在部分餐厅进行试点应用。
医疗辅助:手术助理(不是主刀,是器械递送和辅助操作)、康复陪护、药物配送——这是需要极高精度和可靠性的场景,也是人形机器人商业化的高价值市场。
然而,”替代”不是全貌。 “增强”(Augmentation)同样在并行发生。 索尼Ace的论文中记录了一个意味深长的细节:前奥运选手Kinjirow Nakamura在观看Ace比赛后说:”我从没想过有人能打出这种球——看到机器人做到,让我相信人类也可以。”这揭示了AI的另一种存在价值:作为人类能力的”镜像放大器” 。通过与AI进行对抗性训练,人类选手能够将自身推到此前不可及的极限——就像AlphaGo让围棋选手看到了”上帝视角”的棋理,Ace也在让乒乓球选手理解”超人类的球感”意味着什么。
历史一再证明,技术消灭的是”重复性劳动”,而创造的是”创造性劳动” 。问题在于:技术变革的速度是否正在快于社会消化失业劳动力的速度?这个答案决定了自动化浪潮是成为人类福祉的加速器,还是社会动荡的导火索。
7.2 能源瓶颈:智能越强大,耗电越惊人
DeepSeek V4把百万Token上下文的推理成本降到了可接受范围,DeepSeek-V4-Flash的API定价更是低至每百万Token输入仅0.14美元、输出0.28美元(截至2026年4月)。这种边际成本的持续下降,正在让AI能力的普及门槛趋近于零——但与此同时,AI向物理世界延伸的步伐正在快速推高总能耗。
一个粗略的估算:假设全球有100万台人形机器人在运行(考虑到AGIBOT一家2026年就已经部署了10000台,这个数字并不夸张),每台每天进行8小时AI推理(基于边缘AI芯片,如Jetson Thor或同等性能的定制ASIC),每台耗电约500瓦。仅机器人端每天就消耗400万度电(4000 MWh) ——这相当于一座中型水电站的日发电量。
若再算上全球数据中心的大模型训练和推理需求(2026年AI相关总算力需求约为2024年的10倍以上),AI相关能耗的增速将远超现有电网的承载能力。有研究预测,到2030年全球数据中心的电力消耗可能达到总发电量的3%-4%,其中AI相关负载将占一半以上。
剑桥仿生芯片降低70%能耗的意义在此刻变得格外清晰——能效突破不是锦上添花,而是这场产业革命能否持续的核心约束条件之一。如果芯片能效无法持续提升,AI的物理世界扩张将撞上能源天花板。这让人想起核聚变”永远还有30年”的笑话——但与核聚变不同的是,忆阻器和存算一体技术的技术路线是清晰的,工程障碍是可量化的,商业化路径是真实的。也许在未来5-10年内,我们会看到AI能效的又一次”寒武纪大爆发”。
7.3 智能体的”权利”与”责任”:法律框架的空白
一个人形机器人在工厂里操作时发生意外,碰撞并伤人了——责任由谁承担?制造商?软件提供商?部署企业?购买机器人的工厂主?当前的世界各国法律法规几乎完全没有为这类场景做好准备。
以德国为例——德国是全球工业机器人密度最高的国家之一,也是”工业4.0″战略的发源地——其现行的机器事故责任框架(如ProdHaftG产品责任法、ArbSchG劳动安全法)均基于”人类操作员是行为主体”的前提,机器是”工具”而非”行为者”。当机器本身具有一定的自主决策能力(Ace可以自行决定击球策略,Agent可以自行规划任务执行路径),传统的”工具-行为者”二分法就开始瓦解。
更深层的哲学问题在于:当AI的行为越来越自主,人类是否终将需要承认AI系统具有某种形式的”行为主体性”(agency)? 这不是科幻小说中的幻想——而是一个正在逼近的现实法律问题。当一个AI系统的决策过程足够复杂、足够不可预测,当它的行为对物理世界产生了实质影响(不只是生成文字,而是移动了物体、改变了物理状态),继续把它当作纯粹的”工具”是否还能维持法律体系的内在一致性?
有趣的是,这个问题可能会先在交通领域爆发:Waymo和Cruise的无人出租车已经在旧金山运营,它们已经发生过多次事故。当前法律框架通常将无人车的责任归于”车辆运营商”或”制造商”,但随着自动驾驶级别从L3向L4/L5推进,人类的干预越来越少,运营商对车辆”具体行为”的解释能力也越来越弱——法律体系将不得不面对一个根本性的问题:当AI做出导致事故的决策时,”责任人”究竟是谁?
这个问题目前没有答案。但它不会永远悬而未决——随着具身智能的规模化部署加速,它将成为一个无法回避的社会议题。
八、结语:硅基文明的”成年礼”
回望2026年的这个春天,几个分散在地球各个角落的团队,做似乎是毫不相干的事:
-
• 索尼的工程师在东京的实验室里调试乒乓球机器人的击球角度,计算如何让八轴机械臂在20毫秒内完成从看到球到击中球的全部决策; -
• 剑桥的科学家在显微镜下观察铪氧化物薄膜的原子结构,试图理解p-n异质结为何能在10纳安的极低电流下实现数百个电导状态; -
• 埃默里的理论物理学家在超级计算机上训练一个嵌入了物理定律约束的神经网络,让它从数十个尘埃粒子的三维运动轨迹中挖掘隐藏在噪声里的自然规律; -
• AGIBOT的工人在深圳的生产线上拧紧每一颗螺丝,检验每一台即将发往工厂的G2机器人的关节精度; -
• 亚马逊的并购团队在完成对Fauna Robotics的收购交割,让Sprout机器人的研发路线与亚马逊的仓储运营需求对接。
但如果把这些碎片拼在一起,一幅清晰的图景浮现出来:AI正在完成从”数字存在”到”物理存在”的成年礼——它不再只是屏幕上可以关闭的对话窗口,而是能够感知重力、承受磨损、在真实空间中移动和操作的实体。
这场成年礼的完成需要三个条件的同步成熟:
-
• 大脑的成熟:大模型、Agent架构、长程推理能力——DeepSeek V4的百万Token上下文、Claude和其他模型的多模态能力正在让AI的认知能力向通用化方向快速推进 -
• 能效的提升:新型芯片、存算一体、仿生架构——剑桥70%能耗削减的研究代表了一条清晰的技术路线 -
• 身体的成型:人形机器人、传感器、末端执行器——AGIBOT万台部署和Ace的Nature封面标志着”身体”已经不再是瓶颈
2026年,这三条线第一次同时出现了实质性突破——不是某一项指标的微小改善,而是整个技术栈的系统性协同跃迁。三种技术革命(AGI+芯片革命+机器人革命)在同一时间段汇流,它们的合力将远超各自单打独斗的影响。
接下来会发生什么?
最保守的预测:人形机器人在未来五年内在工业场景中大规模替代重复性劳动,AI Agent在办公场景中承担起复杂的自动化任务,芯片能效的持续改善为这一切提供能源保障。整体而言,这是一个价值数万亿美元的产业升级过程。
更大胆的预测:当AI能同时进行复杂的物理操作和高级认知推理,当它既能打赢乒乓球又能发现新物理,当它的”身体”越来越灵巧而”大脑”越来越深邃——人类将第一次面对一个真正意义上的物理-认知双轨并行的智能物种。
那将不是一项技术的成熟,而是一个文明节点的到来。
硅基文明的”成年礼”,或许正在2026年的这个春天悄然完成。而我们,正在见证。
附:本文提及的技术突破与事件均来自2026年3月28日至4月27日期间的公开报道与学术出版物。主要信息源包括:《Nature》2026年4月22日论文(Ace机器人)、AGIBOT APC 2026官方发布(万台部署与AIMA架构)、《PNAS》埃默里大学研究论文(等离子体新物理发现)、《Nature》子刊剑桥大学研究论文(仿生忆阻器芯片)、NVIDIA开发者博客(DeepSeek V4技术报告与Blackwell部署验证)、《ScienceDaily》2026年4月专题报道,以及TechCrunch、Ars Technica、The Verge、IEEE Spectrum等科技媒体的同期报道。DeepSeek V4模型技术参数来自DeepSeek官方Hugging Face模型卡及NVIDIA NIM官方页面。