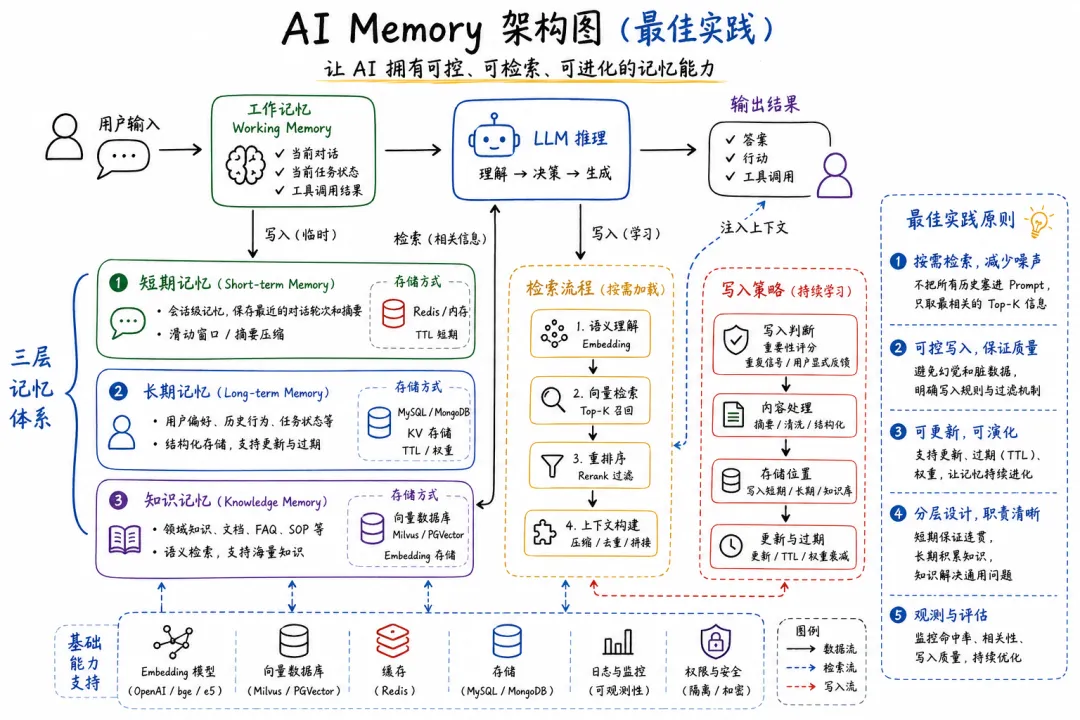
AI Memory,直译就是 AI 记忆。但它不是简单地“把聊天记录保存下来”。更准确地说:AI Memory 是让模型在长期交互中持续积累、提取、更新和利用用户信息、任务信息、环境信息的能力。它让 AI 不再只是基于当前对话回答问题,而是能够结合过去的信息来理解现在的任务。这就是 AI Memory 的价值。
这是 AI Memory 的关键。好的记忆系统必须有筛选机制。它要判断:这个信息是否长期有效?是否会影响未来回答?是否是用户明确要求记住?是否涉及隐私或敏感信息?是否可能过期?是否只是一次性任务?很多低质量 Memory 系统的问题就在这里:什么都记,最后记忆变成噪音。真正好的 Memory,不是记得多,而是记得准。
3. 写入:把信息转成可管理的记忆
写入不是简单存原话,更好的方式是把信息结构化。Memory 写入的本质,是从对话中提炼稳定模式。
4. 存储:把记忆放在哪里
AI Memory 常见的存储方式有几类。第一类是结构化数据库,适合存用户画像、偏好、任务状态。第二类是向量数据库,适合存语义记忆,方便相似检索。第三类是事件日志,适合保存时间线和任务过程。第四类是知识图谱,适合表达实体、关系和长期结构。第五类是摘要记忆,适合压缩长对话和项目历史。实际系统通常会混合使用。比如用户偏好放结构化数据库,历史项目放事件日志,长文档理解放向量库,复杂关系放知识图谱。
5. 检索:在合适时机想起来
记忆真正有价值,不是存起来,而是在需要时被正确唤起。这一步很难。因为 AI 不能每次都把所有记忆塞进上下文,它需要判断当前任务需要哪些记忆。好的 Memory 系统必须具备上下文相关检索能力,该想起来的时候想起来,不该想起来的时候不要干扰。
6. 更新:记忆不是一成不变的
人会改变,项目会变化,偏好也会变化,所以 AI Memory 必须支持更新。你以前关注 RAG,现在重心转向 Agent。这些都需要更新。如果 Memory 不能更新,它就会从资产变成负担。所以,遗忘和修正也是 AI Memory 的核心能力。
 夜雨聆风
夜雨聆风