 夜雨聆风
夜雨聆风





做第一个 AI Agent,别急着造万能助手
这篇文章真正有价值的地方,不是告诉你再装一个工具,而是把 Agent 从抽象概念拉回到一个文件夹、一条命令和一次会失败的运行里。
如果你想开始做自己的 AI Agent,最先要想清楚的可能不是选哪个模型,而是:它住在哪里、怎么被你看见、出了错谁来兜底。

文|Hive硅基秩序编辑|Hive硅基秩序来源|Hive硅基秩序封面来源|图片来源网络
原文作者从去年 10 月开始搭建自己的 AI Agent。半年多时间里,他踩过很多第一次做 Agent 时会踩的坑,有些还踩了不止一次。后来他问读者,面向初学者最该写什么,得到的反馈很一致:不要只讲概念,讲真实会出错的地方,讲第一天该怎么开始。
这其实也是今天 Agent 话题里最容易被忽略的一层。外面有太多“自主工作流”“数字员工”“个人助理”的想象,但真正开始动手时,你面对的往往不是宏大叙事,而是一个空文件夹、一个配置文件、一堆权限问题,以及一个第一次运行就报错的小脚本。
Agent 的入门门槛,表面上是模型能力,实际上常常是工程常识。
01 AI Agent 到底和自动化差在哪
原文的起点不是 AI,而是 Zapier。作者过去长期使用 Zapier、n8n、Make.com、脚本和各种连接器做传统自动化,所以他一开始也自然地想:把工具串起来,不就得到一个 Agent 了吗?
这个直觉只对了一半。
AI Agent,可以先理解成一种“围绕目标连续行动的 AI 系统”。它不只是回答一句话,而是可以读取信息、调用工具、观察结果,再决定下一步怎么做。
传统自动化更像一条固定流水线。你提前写好触发条件、执行步骤和分支逻辑,同样的输入,大概率得到同样的输出。它的好处是可预测,所以在生产环境里很可靠。
Agent 的差异在于,它有一点“活动空间”。你给它一个目标和一组工具,它可以自己决定先用哪个工具、怎么拆步骤、遇到错误时是否绕路。这个能力听起来很诱人,也确实是 Agent 的价值来源,但它同时带来另一面:同样的输入,它未必每次都走完全相同的路径。
所以原文里有一个很重要的提醒:自动化和 Agent 不是谁取代谁。很多生产环境里的所谓 Agent,本质上更像是“传统自动化 + 顶层语言模型”。这并不丢人,能稳定工作才是关键。
如果你从零开始,作者甚至建议先做几个简单自动化,比如把日历同步到 Notion、RSS 更新时给自己发 Slack 消息。这样做不是为了绕远路,而是为了先理解三件事:触发、动作、结果。这三件事,是后面所有 Agent 工作流的骨架。
02 先回答三个最朴素的问题
在写代码之前,原文借用了一个很好的提问框架:
Agent 住在哪里?你怎么看见它?你怎么和它说话?
这三个问题听起来太基础,基础到技术文章经常跳过去。但对初学者来说,它们反而决定了你能不能真的开始。
它住在哪里
作者自己的 Agent 现在跑在客厅电视旁边的一台 Mac Mini 上。在那之前,它先跑在个人 MacBook 上。后来因为电脑必须一直开着,他才把它迁移到一台专用机器。
但这不是第一天的问题。
对第一个 Agent 来说,答案很简单:它就住在你的笔记本上。Agent 说到底还是软件,软件跑在哪里,Agent 就在哪里。它可以在你的 Mac、Windows、Linux 电脑上,也可以以后搬到云服务器、树莓派或者专门的小主机上。
真正的问题不是“我要不要先买一台机器”,而是“我有没有先让它在手边跑起来”。
你怎么看见它
很多人会以为 Agent 应该有一个精致仪表盘,最好有图表、有按钮、有状态灯。现实通常没那么漂亮。
你最开始“看见” Agent 的方式,往往是它产生的输出:它写了什么文件、打印了什么日志、给你发了什么消息、任务成功还是失败。仪表盘可以以后再做,但第一天不需要。
这也是一个很实用的心理预期:Agent 不一定一开始就有“脸”。它先是一段能运行的流程,然后才慢慢长出界面。
你怎么和它说话
作者自己的 Agent 现在接入了邮件、Discord、iMessage,以及一个自建任务应用 WizBoard。这个组合已经超出了初学者需要的范围。
第一天最简单的通道,就是终端。
你输入一句话,它返回结果。看起来朴素,甚至有点不好看,但它是最适合学习的界面。因为后面无论你接入聊天软件、任务面板还是网页应用,本质上都只是给这个输入输出循环套了一层更好看的外壳。
一个新工具最开始不好看,并不妨碍它先变得有用。
03 开始前,你真正需要什么
原文接下来进入“工具箱”部分。这里的重点不是列一堆新名词,而是把入门条件压到足够低:你不需要昂贵硬件,不需要复杂框架,也不需要一上来就懂机器学习。
3.1 一台机器
你的笔记本就够了。Mac、Linux、Windows 都可以。如果它能跑浏览器和文本编辑器,就足以跑你的第一个 Agent。
以后如果你希望 Agent 在你睡觉、出门、合上电脑时仍然工作,再考虑迁移到一台常开设备。原文作者后来迁移到 Mac Mini,但那是“第三个月的问题”,不是第一天的问题。
3.2 一个订阅,或者 API 访问权限
原文这里说得很直接:免费额度通常不够。不是说它完全不能用,而是你很容易在第一个下午就撞上限流,然后把学习时间花在等额度恢复上。
作者给出的入门线是每月 20 美元左右的付费档,比如 Claude Pro、ChatGPT Plus,或者你选择的其他模型服务的同等档位。这个级别通常足够做一个简单 Agent,先跑通流程。
当然,进阶用户可能会同时付多个订阅,还会额外使用 API。那是后面的事情。对初学者来说,这笔钱更像是学习一门新工具的基础成本。
3.3 一个 Harness,也就是你真正坐在里面工作的工具
Harness,原文用它指代“你用来搭建 Agent 的工作环境”。它可以是终端里的 AI 编程工具,也可以是云端 Agent 应用,甚至可以先是一个普通聊天窗口。
原文列了四类选择:
-
Claude Code:Anthropic 的终端工具,适合认真处理文件、代码和项目结构。 -
Claude Cowork:更偏云端应用,让 Claude 在 Agent 循环里工作,少接触终端。 -
Codex 或同类工具:和 Claude Code 属于相近类别,只是风格不同。 -
普通 AI 聊天窗口:比如浏览器里的 Claude.ai 或 ChatGPT,复制粘贴多一些,但也能开始。
关键建议是:先选一个,不要把第一周花在比较工具上。只有真正做过一个东西,你才知道自己需要什么。
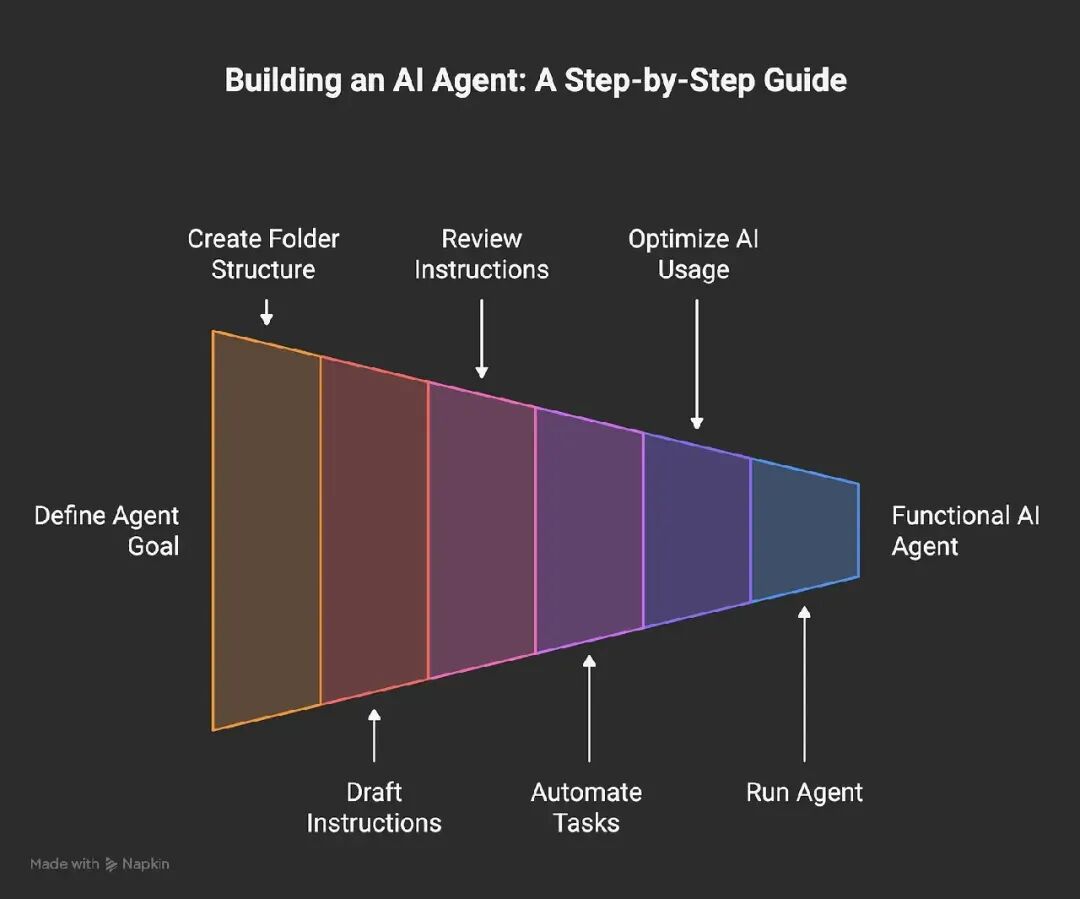
3.4 一个文件夹,这就是你的第一版架构
原文最有启发的一句话是:
Agent 的架构,就是它的文件夹结构。
这句话听起来有点粗糙,但对初学者很有效。因为很多 Agent 概念落到本地,其实都对应一个文件或目录。
有人说 Agent 有工具,通常意味着它有一些可以执行的脚本。有人说 Agent 有记忆,通常意味着它会读取某些 Markdown 文件。有人说 Agent 有角色设定和行为规则,通常意味着项目里有一个 CLAUDE.md、agents.md 或类似文件。
一个入门版目录大概长这样:
my-agent/
├── CLAUDE.md
├── memory/
│ └── notes.md
├── projects/
│ └── morning-email/
│ ├── fetch-email
│ └── prompt.md
├── scripts/
└── secrets/
这棵树可以翻译成很朴素的话:
-
CLAUDE.md放核心指令,告诉 Agent 自己是谁、要遵守什么规则。 -
memory/放记忆,可以先从简单 Markdown 文件开始。 -
projects/放具体项目,比如“早晨邮件摘要”。 -
scripts/放可调用的小工具。 -
secrets/放 API Key、密码等敏感信息,并且要认真保护。
一旦你把 Agent 看成一个文件夹,它就不再像一个神秘存在,而更像一个你可以拆开、阅读、修改和回滚的软件项目。
04 把第一个 Agent 做出来
原文推荐的第一个项目很具体:做一个能读取隔夜邮件,并在早上写出一段摘要的 Agent。
这个选择很聪明。它不大,但足够真实;不复杂到让人半路放弃,又会让你碰到几乎所有 Agent 工程里的核心问题:认证、权限、上下文、提示词、错误处理。
Step 1. 先说清楚你想要什么
先别写代码。打开你选择的聊天工具,用自然语言描述你的早晨:
我每天早上打开邮箱,要扫 40 封邮件,判断哪三封真正重要。我想在咖啡还没喝完前,看到一段关于重点邮件的摘要。
这就是规格说明。越短越好。
如果你不能用一段诚实的话讲清楚自己想要什么,Agent 也不会替你神奇地弄明白。很多项目失败,不是因为模型不够强,而是人一开始就没有定义清楚目标。
Step 2. 创建文件夹
创建一个空目录,叫 my-agent,然后放入最小骨架:
my-agent/
├── CLAUDE.md
├── memory/
├── projects/morning-email/
├── scripts/
└── secrets/
这些文件夹一开始可以是空的。它们的意义是给 Agent 一个稳定的工作地点,也给你一个未来排查问题的地图。
Step 3. 让 AI 起草指令文件
如果你用的是 Claude Code,可以在 my-agent 目录里运行 /init,让它生成一个初始 CLAUDE.md。
如果你用的是其他工具或普通聊天窗口,也可以直接这样问:
我想构建一个 AI Agent,第一个任务是每天早上读取我的邮箱,并写出一段真正重要内容的摘要。请帮我起草一个
CLAUDE.md指令文件,控制在 50 行以内,不要假设我的具体环境。
这个文件不会一开始就完美,它只是起点。
Step 4. 认真读完 CLAUDE.md
这是原文反复强调的一步,也是很多人最容易跳过的一步。
你可以让 AI 帮你写指令,但不能不读。打开文件,逐行检查:它是否真的描述了你的需求?有没有奇怪假设?有没有你看不懂却被写进规则里的内容?语气和边界是否符合你的预期?
CLAUDE.md 是 Agent 的行为底座。它如果从第一天就写错,后面很多问题看起来会像“模型抽风”,实际上只是核心指令里埋了一句错误设定。
Step 5. 告诉它要自动化什么
现在才开始真正搭建。你可以直接对 Harness 说:
我希望
projects/morning-email里的第一个任务是读取我的邮箱,抓取过去 12 小时未读邮件,并交给摘要模块处理。最终结果是一段说明真正重要内容的摘要。请根据我的系统环境选择合适方式,并一步步带我完成。
好的工具会继续追问:你用什么邮箱?系统是 Mac、Windows 还是 Linux?有没有 API 凭据?希望定时运行,还是手动触发?
这就是 Agent 工作方式和传统从零写代码的差异:你不必先知道所有库、命令和文件格式。你的责任是讲清目标,并检查它做出来的东西是否符合目标。
Step 6. 把 AI 调用放在流程末端
这是原文里非常实用的一条经验:不要把 AI 塞进每一步。
抓取邮件这件事,普通代码已经解决了很多年。它不需要语言模型。真正需要语言模型的是最后的摘要,因为那一步需要理解内容、判断重点、组织语言。
你可以明确告诉工具:
获取邮件这一步不要使用 AI。用合适的普通工具处理。只在最后摘要环节调用语言模型,而且尽量一次调用完成,不要每封邮件调用一次。
这背后的原则很简单:用 AI 处理语言和判断,用普通代码处理搬运和格式转换。这样更便宜、更快,也更容易排查问题。
Step 7. 运行它
运行方式可以分两种。
如果你不熟悉终端,就直接让 Harness 替你运行,比如说“运行我的 morning-email Agent”。如果你想知道底层发生了什么,就让它告诉你具体命令,再自己复制到终端执行。
看到摘要打印出来的那一刻,你就已经有了一个真实 Agent。它很小,但它属于你,而且解决了一个明天早上就能验证的问题。
Step 8. 等它坏掉,然后开始真正学习
它一定会坏。可能是邮箱认证失败,可能是时间窗口取错,可能是摘要口吻不对,也可能是完全没拉到数据。
这不是失败,这是入门课程真正开始的地方。
读报错,把完整错误贴回 Harness,让它解释发生了什么。如果行为不断偏离你的期待,先回到 CLAUDE.md 看核心指令。如果摘要不对,调整摘要提示词。如果完全没有数据,问题通常在更早的抓取步骤。
做 Agent 的能力,不是让它永远不坏,而是坏掉之后你知道从哪里开始看。
05 那些真正会咬人的错误
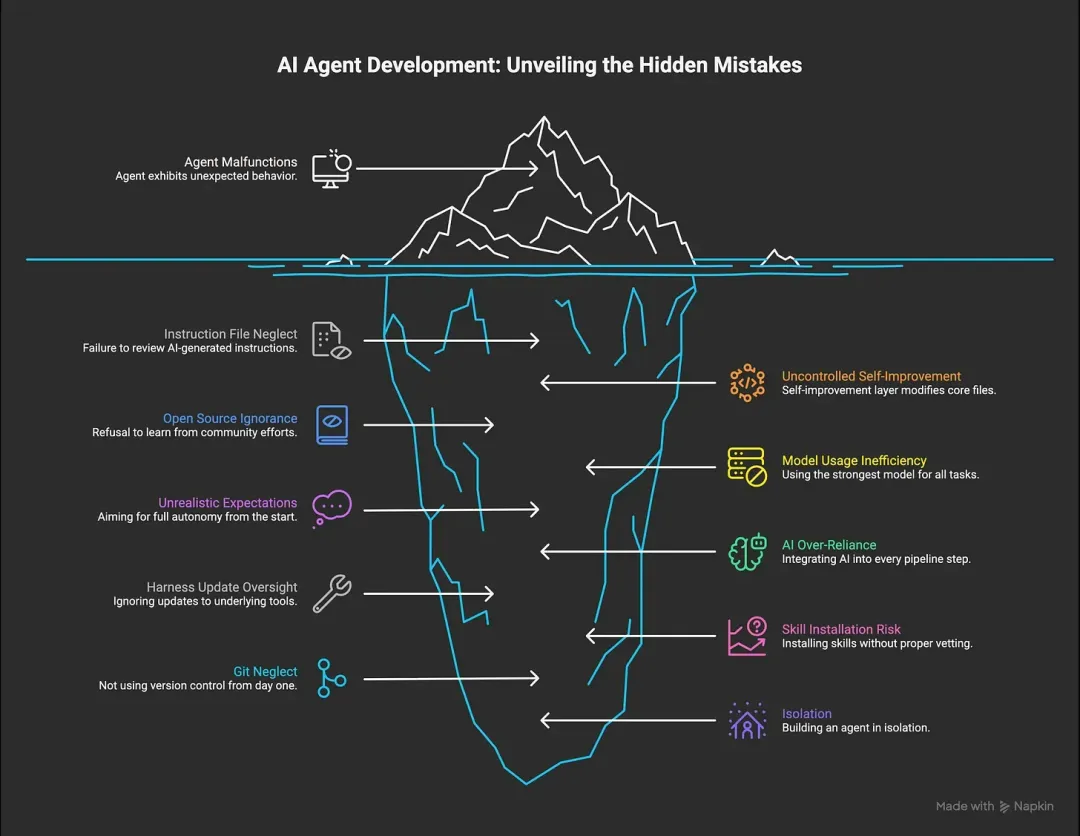
原文第五部分是读者最想看的内容:第一次做 Agent 时,哪些坑最值得提前知道。
错误 1:盲信 AI 写出来的指令文件
作者最早让 AI 生成了 CLAUDE.md,但没有认真读。项目一开始还能跑,后来 Agent 开始做一些奇怪的事。他花了很久调工具、改提示词、换流程,最后发现根因只是指令文件顶部一句误导性规则。
这里的规则很明确:AI 可以帮你起草核心指令,但你必须读。每一行都要读,读到它像你自己写的。
错误 2:让自我改进直接碰核心文件
作者后来做过一个自我改进层:Agent 可以观察自己的行为,发现模式,再修改自己的规则。这听起来很高级,问题在于他一开始没有限制它能改哪些文件。
几天后,Agent 已经重写了大量核心 CLAUDE.md 内容,甚至覆盖了作者明明要求保留的规则。
更稳的做法是分层:每个项目有自己的小指令文件和小记忆文件,自我改进可以修改这些“叶子文件”,但不要直接改核心指令。树干要稳定,树枝可以生长。
错误 3:因为自尊心不看开源项目
作者一开始想全部自己做,不看 GitHub 上别人的 Agent 项目,理由是不想被影响。结果大概浪费了两三个月。
后来他开始阅读开源 Agent 仓库,不是照搬架构,而是借鉴概念。比如他看到有人使用 SOUL.md 来单独管理 Agent 的人格、价值观和表达风格,这让他意识到,不必把所有个性化信息都塞进 CLAUDE.md。
这里的重点不是“找一个框架全盘采用”,而是看别人如何拆问题。Agent 还在早期,很多好经验不是来自文档,而是散落在项目结构、提交记录和社区讨论里。
错误 4:所有任务都用最强模型
原文作者曾经把强模型用在所有事情上:小查询、读文件、简单检查、普通计划。结果很快撞上使用限制。
他后来使用了 模型路由。
模型路由,就是根据任务难度选择不同模型。简单任务用小模型,常规工作用中等模型,关键推理和高风险代码再交给强模型。
原文里的做法是:简单任务交给小模型或本地模型,常规规划和多数编码交给中等模型,困难推理、关键代码和战略判断再交给最强模型。具体模型名字会随着供应商变化,但原则不会变:不要用最贵的能力处理最便宜的问题。
错误 5:第一天就想造 Jarvis
这是很多人对 Agent 的真实幻想:一个助手解决所有问题,管理工作、生活、写作、日程和业务。
原文作者承认,他最初也这样想。结果就是架构被过早推得太大,每次新增五个功能,而不是先让一个功能稳定下来。真正能跑起来的版本,反而是后来逐步长出来的:先做一个小任务,再做下一个,再把它们组合起来。
全自动也不是唯一目标。对邮件摘要、晚间报告、紧急提醒这类“好坏标准清楚”的任务,自动化很合适。但对创意、策略和质量判断,人仍然应该在环路里。
错误 6:每个流程节点都塞 AI
作者早期几乎所有步骤都有语言模型调用:抓数据、搬文件、路由消息、格式化输出。结果后台任务刚启动,就消耗了大量使用额度。
后来他发现,绝大多数管道可以是普通脚本。把数据从 A 移到 B,用代码。清洗格式,用代码。只有最后需要理解、判断和表达时,再调用模型。
AI 不是免费的。即使是本地模型,也消耗时间、电力和机器资源。真正有效的 Agent,不是每一步都显得聪明,而是知道哪里不需要聪明。
错误 7:忘了 Harness 本身一直在更新
Claude Code、Codex 和其他 Agent Harness 都在快速更新。好处是能力持续变强,坏处是你自己写的功能,可能某一天被工具原生支持了。
这时如果你继续保留自定义版本,就可能出现两个系统同时处理同一件事,结果互相影响,输出漂移,还很难排查。
原文作者的做法是每天检查工具更新,如果发现自定义功能和原生功能重叠,就删除自己的版本,改用原生能力。这个建议背后的原则是:建在快速变化平台上的东西,要定期清理旧假设。
错误 8:从技能市场安装扩展却不审查
技能市场和可分享 Agent 扩展正在变多。它们很好用,因为别人可能已经解决了你正在遇到的问题。
但原文提醒得很直接:一个技能本质上是运行在你机器上的代码,而且带着 Agent 的权限。如果你没有理解它能做什么,就等于让一个陌生软件坐进了你的工作区。
安装任何技能前,至少问两个问题:我真的需要它吗?我大致理解它会读取、修改、执行什么吗?如果答不上来,先读源码,或者让 Agent 帮你解释它的行为。
错误 9:从第一天就不用 Git
这一条其实不是作者自己的错误,因为他从一开始就用了 Git。但他见过太多初学者跳过它,然后丢掉几周工作。
Git,可以先理解成项目的时间机器。它让你在文件被改坏、删错、重写之后,回到之前能工作的版本。
Agent 会改文件,人也会误操作。没有 Git,你只能靠记忆还原三天前的状态。有 Git,你至少有机会回到一个稳定版本。
现在这件事对非技术用户也没那么难。你可以让 Harness 帮你初始化仓库、建立私有 GitHub 项目,甚至在每次 Agent 完成重要任务后自动提交和推送。
额外错误:以为必须一个人做
原文最后补了一条:不要孤立地做 Agent。
社区、Newsletter、GitHub 讨论、Substack 评论区,里面有大量一线经验。很多人在踩同样的坑,只是踩坑位置不同。对一个还没有标准答案的领域来说,公开学习本身就是重要工具。
06 上下文窗口,才是隐形成本
原文第六部分谈到一个容易被低估的问题:上下文窗口。
上下文窗口,简单说就是模型一次性能“看见并处理”的信息长度。窗口越大,模型越能同时摊开更多资料;但窗口不是无限仓库,里面放什么仍然需要管理。
200,000 tokens 听起来很多,但真正开始做 Agent 后,你会发现它很快被“常驻内容”占掉:核心指令文件、记忆文件、历史对话、当前任务状态,都可能在你还没输入新问题之前就被加载进来。
这也是为什么原文作者强调三个入门规则:
第一,CLAUDE.md 要薄。每多一行,模型每次启动都要读一行。它是黄金地段,不是杂物间。
第二,每个项目先用一个记忆文件。不要第一天就上向量数据库、语义搜索、知识图谱。一个扁平的 Markdown 文件,已经足够支撑很长一段学习期。
第三,先不要担心复杂压缩。等记忆文件真的变大,再考虑定期压缩、重写或归档。
评论区有读者补充得很准确:很多人在优化执行层,比如省 token、调提示词,但上下文加载是另一个问题。决定“模型应该看到什么”的责任不会因为窗口变大而消失。
上下文窗口不是越大越不用管理,而是越大越容易把杂物也一起塞进去。
07 安全,从第一天开始
最后一部分是安全。它不是进阶话题,而是第一天就要进入脑子的基本意识。
Agent 是你电脑上的新攻击面。它可能读文件、跑代码、访问网络、调用 API,还可能被网页、邮件或外部文本里的提示注入影响。即使模型越来越强,我们也还没有把这类系统的所有风险边界摸清楚。
原文作者的做法是逐步放权:
先在个人 MacBook 上以严格权限运行,只开放明确白名单文件夹,不给真实凭据,也不给宽泛网络权限。等他理解 Agent 实际需要什么,再一点点扩大权限。最后,才迁移到一台专用 Mac Mini,用独立账号和独立凭据运行更大范围的任务。
这里最值得记住的一条是:Agent 应该有自己的账号,而不是直接用你的账号。
自己的邮箱、自己的 API Key、自己的登录凭据。这样即使出问题,影响范围也更可控。安全不是为了让你不开始,而是让你开始得更稳。
原文还提到,作者后来做过一个 Claude Code 技能安全扫描工具,起因是他看到自主 Agent 和技能扩展里出现了被利用的案例。这个细节说明了一个现实:当 Agent 生态开始拥有“插件”和“技能市场”,安全问题就不再是遥远的理论,而是每个安装按钮背后的实际成本。
08 从一个小东西开始
回到最初的问题:做第一个 AI Agent,到底需要什么?
不是最强模型,不是昂贵机器,不是复杂框架,也不是机器学习博士学位。你真正需要的是一台已有的电脑、一个可用的模型订阅或 API、一个 Harness、一个清楚的文件夹结构,以及一个你明天真的会用的小任务。
比如早晨邮件摘要。
它会坏,会报错,会拿错数据,会写出你不喜欢的摘要。但这正是它有价值的地方。因为你会在修复它的过程中,真正理解 Agent 不是一个会魔法的盒子,而是一套可以被拆开、约束、观察和改进的工作系统。
AI Agent 的入门,不是从“万能助手”开始,而是从一个能跑、能坏、也能被你修好的小流程开始。
模型会继续变强,但真正决定它能不能进入日常工作的,仍然是目标是否清楚、边界是否可控,以及人是否愿意认真读完那份最初的 CLAUDE.md。