 夜雨聆风
夜雨聆风





揭秘子词切分(subword)的真相:别再搞混了!Token和字根本不一样
我是老九,一个一直在一线折腾技术和AI的人。我习惯留意一些看着很先进,但放到工作和生活里付出不小代价的事。欢迎关注我!
当前章节:第一章|Token 与分词机制
当前小节:第一节|Token 到底是什么(基础认知层)
本篇知识点:子词切分(subword)
我第一次接触token下意识觉得:“哦,就是一个字对应一个token。”
尤其中文,因为中文就是一个字一个字排列的,看起来特别像。实际上。token和“字”根本不是一回事。
我们拆一下为什么token不等于一个字?
先举个简单例子。一句:“我喜欢人工智能”
在不同tokenizer里可能会被拆成:
[“我”, “喜欢”, “人工智能”]
也可能是:
[“我”, “喜欢”, “人工”, “智能”]
甚至:
[“我”, “喜”, “欢”, “人”, “工”, “智”, “能”]
模型到底怎么拆不是按“字数”,是按“哪些内容更适合一起出现”。这个东西在大模型里有个名字:Subword(子词切分)。
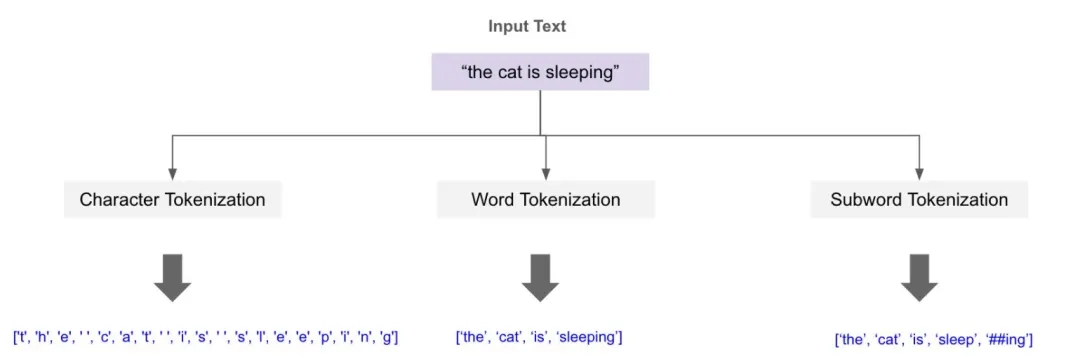
简单说就是tokenizer不会死板地按“字”切,它会尝试找到最合适的语言片段。有些片段很常见那就合并,有些很少见那就拆开。
比如:“人工智能”
在训练数据里出现太多次了,所以tokenizer很可能直接给它一个整体token。因为这样效率更高,语义也更稳定。但如果是“量子香菜火锅修仙器”,模型从来没见过,那tokenizer大概率会疯狂拆碎,因为它不知道哪里该合并。
这就是为什么高频词通常token更少,冷门词通常token更多。
我第一次知道这个的时候就觉得tokenizer有点像“拼积木”,它会尽量把经常一起出现的部分拼成一个整体。这样模型后面计算时语义会更清楚。还有一个特别重要的原因,如果真的严格按“一个字一个 token”,上下文会变得特别长。
比如:“中华人民共和国”
如果拆成:
中 / 华 / 人 / 民 / 共 / 和 / 国
Attention的计算量会暴涨,因为Transformer本质上是token 和token两两建立关系,token 越多计算量越大。
子词切分其实是一种折中,既不能太碎,也不能太大。太碎语义丢失,太大词表会爆炸。tokenizer会不断寻找“最合适的粒度”。
这也是为什么token有时候像字,有时候像词,有时候甚至像半个词。
比如英文里“unbelievable”
可能会被拆成:
[“un”, “believ”, “able”]
因为这些子结构在很多单词里都会重复出现,这样tokenizer 可以用更少的词表覆盖更多语言。
这个设计特别聪明,它解决了一个很大的问题:语言里的组合是无限的,但模型词表不可能无限大。
所以tokenizer只能:
-
尽量复用。
-
尽量拼接。
-
尽量压缩。
最后形成一种介于“字”和“词”之间的东西,这就是subword。
很多AI的奇怪现象也和这个有关。
-
为什么生僻词容易翻车。
-
为什么新梗容易理解错。
-
为什么缩写有时候特别奇怪。
因为tokenizer根本没把它当成一个完整单位,它只是硬拆。所以很多时候以为AI在理解“文字”,它真正处理的只是一块一块的子词碎片。
如果你读着还行,欢迎点赞收藏关注;如果有不同的观点,也欢迎大家留言讨论。