 夜雨聆风
夜雨聆风





Skills不是低代码,但也不是App Store
Anthropic 团队成员 Thariq 发了一条推文,分享 Claude Code 内部的 Skills 体系——九大分类、11 条原则、数百个活跃 Skill。2.8M 浏览,26.7K 收藏。整个 AI 开发者圈炸了。
然后争论开始了。
一派人说 Skills 就是 AI 时代的低代码——看起来很美,但模型越来越强,这些 Markdown 指令迟早没用,阶段性产物而已。另一派说 Agent 就像操作系统,Skills 就像 App——ClawHub 上的 Skills 数量两周内从 1 万暴增到近 3 万,这是生态爆发的信号。
一边说会死,一边说会爆。
我跑了 18 个 Skill 的 eval(自动化测试——让 Agent 有 Skill 和没 Skill 分别跑同一批任务,对比得分),得出的结论是:两边都不对。
先搞清楚:LLM、Agent、Skill 到底什么关系
聊 Skill 之前,得先拆清楚三个概念的层叠关系。不然讨论就是空中楼阁。
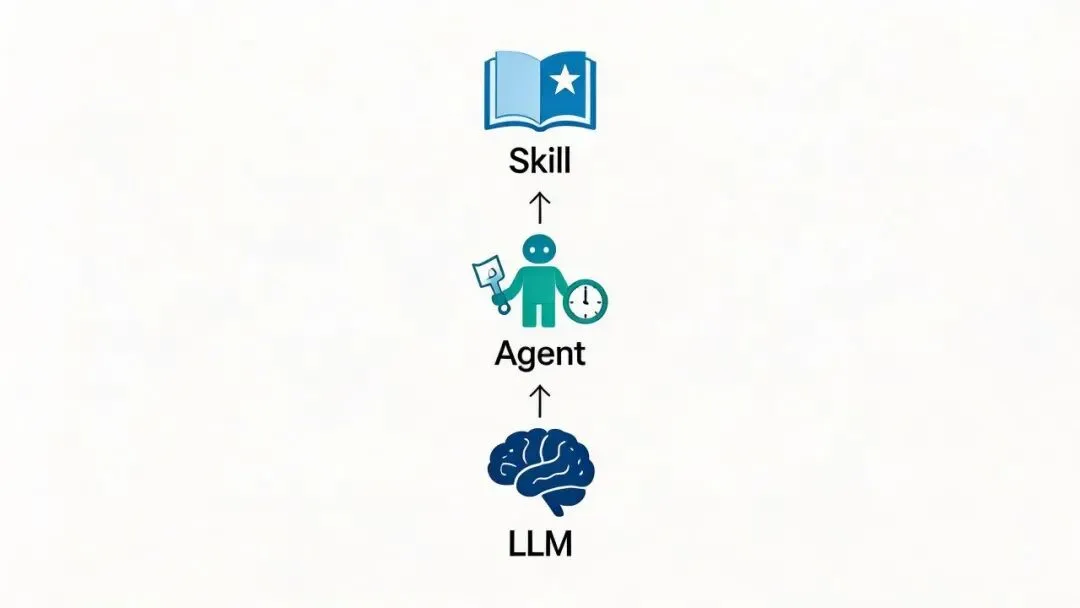
LLM(大语言模型),你可以理解成一个超级大脑。什么都知道一点,推理能力强,但没有记忆、没有手脚、不会主动干活。给它一个问题它回答,然后就忘了你是谁。
Agent 是把这个大脑装进一个”人”里。LLM + 记忆 + 工具调用 + 自主决策循环 = Agent。它能记住上下文,能操作文件,能自己规划任务步骤。
Skill 是这个人学会的一项具体技能。写在 Markdown 文件里的专业知识、工作流程、行为规范——Agent 在执行任务时自动加载,相当于随身携带的经验手册。
打个比方:LLM 是裸考的学霸,什么科目都能扯两句,但你让他填一张报销单他直接懵。Agent 是刚入职的新人,有脑子有手脚,但不知道公司流程。Skill 是同一个人带着经验手册干了三个月之后的状态——他知道报销单要抄送财务王姐,知道周五下午三点前不提交就赶不上本月打款。
三者是层叠关系。Skill 不会替代 Agent,就像”学会做饭”不会替代”人”本身。Agent 不会替代 LLM,就像”人”不会替代”大脑”。它们各管一层。
搞清楚这个,才能判断”低代码派”和”App Store 派”谁说的有道理。
“低代码”类比,错在哪
低代码派的逻辑很清楚:低代码解决了”不会写代码”的问题,但每次底层技术升级,低代码平台就被淘汰一轮。Skills 也一样——模型越来越强,这些 Markdown 指令迟早没用。
听起来有道理。但这个类比搞混了一件事:低代码解决的是能力缺失问题,Skill 解决的是上下文缺失问题。
举个我自己的例子。我有一个 Skill 叫 content-collector,用来帮我收藏和整理 AI 领域的信息。它里面写了一套完整的规矩:收藏时自动打标签、按主题归档、关联到我正在跟踪的项目、用我习惯的 frontmatter 格式存储。
这套规矩跟模型能力无关。GPT-5 来了、Claude 5 来了,它们都不可能”自己想到”我的标签体系长什么样、我关注哪些信息源、我的归档目录结构是什么。这不是智商问题,是私有知识问题——模型的训练数据里没有”王某某的知识管理体系”这条信息。
再看另一个例子。我给 Agent 写了一套每日信息摘要的 Skill,里面定义了”五类噪音模式”——钓鱼标题党、恐惧贩卖、信息反刍、伪第一人称、循环叙事。Agent 每天帮我过滤几十条信息流时,会先标记这些模式,然后自动降权。这是我被垃圾信息淹没了两周之后沉淀出来的规矩。
模型会帮你整理信息吗?会。但模型不知道你觉得什么是噪音。
Anthropic 在 skill-creator 博客里把 Skill 分成了两类:Capability Uplift(能力增强)和 Encoded Preference(偏好编码)。能力增强型帮模型做它做不好的事——比如教它怎么用一个冷门 API。偏好编码型把团队的工作流程和规矩写下来——比如”PR 标题必须以 ticket 号开头”。
低代码的命运确实是被淘汰。但那是因为低代码属于能力增强型——模型自己学会写代码了,你的拖拽界面就没用了。
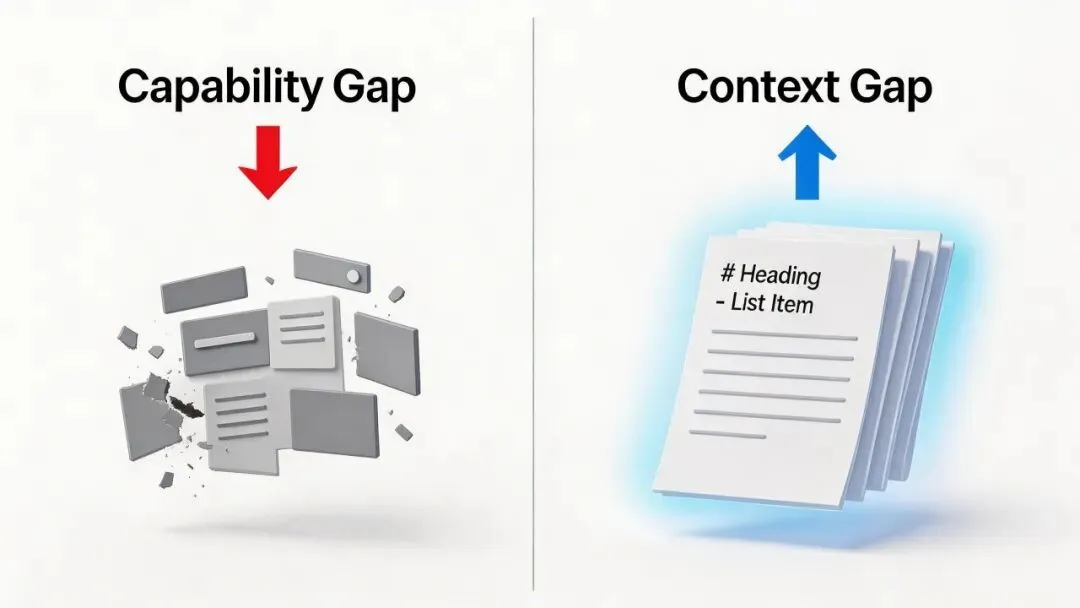
偏好编码型 Skill 不吃这套。 模型再强也不知道你的规矩。这个类比的根基就是歪的。
“App Store”类比,也不全对
乐观派的视角更诱人。Agent 是操作系统,Skill 是 App,ClawHub 是 App Store。两周从 1 万到 3 万个 Skill——看起来确实像生态爆发。
这派人还有一个很有洞察力的观点:”软件正在为 Agent 重写。”命令行工具的 --help 本身就是文档,连 Skill.md 都不需要——Agent 自己读帮助信息就能用。
但 App Store 类比有个致命缺陷:App 是通用的,Skill 天生是私有的。
微信是一个 App。10 亿人用同一个微信。但我的 content-collector Skill——用来收藏和管理我关注的 AI 领域内容——根据我的 eval 测试,它让 Agent 的任务完成质量提升了 2.6 倍。
2.6 倍。不是因为 Skill 写得有多精妙。而是因为它编码了我的工作流:我关注哪些信息源、用什么标签体系、怎么做二次加工。换一个人用同样的 Skill,提升可能只有 1.2 倍,甚至更低。
杀手级 App 是别人写的。但杀手级 Skill 一定是你自己写的那个。
这就是 App Store 类比失灵的地方。ClawHub 上 3 万个 Skill 的增长是真的,社区生态也是真的。但它更像 GitHub 而不是 App Store——你去找灵感、找脚手架,然后回来写自己的版本。下载一个通用 Skill 装上就用?对能力增强型管用。对偏好编码型?你得自己动手。
用 Anthropic 的框架来看:Capability Uplift 型 Skill 确实可以做成”App”——标准化、通用化、别人写好你直接装。但 Encoded Preference 型 Skill 做不成”App”,因为它的全部价值来自你的私有上下文。
乐观派看到了 Skill 的生态价值,但高估了通用化的空间。
我的判断:Skill 是 Agent 的”肌肉记忆”
低代码不对。App Store 也不全对。那 Skill 到底是什么?
我管它叫 Agent 的肌肉记忆。
你学骑自行车,最初需要刻意思考”左脚踩下去、身体右倾、把手反方向修正”。练了两周,你不想这些了——身体自动做。那些固化下来的模式就是肌肉记忆。
Skill 对 Agent 就是这个作用。Agent 不需要每次都从头推理”这条信息该不该收藏、用什么标签、归到哪个项目”。它读一遍 content-collector Skill,就像一个老员工翻开操作手册——几百毫秒,所有规矩加载到位。
用数据说话。我跑了 18 个 OpenClaw Skill 的 eval 测试,发现了一个很清晰的分化:
4 个 P0 级 Skill(用得最频繁、业务最核心的),平均提升 1.83 倍。其中 content-collector 提升最猛,2.6 倍。这些全是偏好编码型——里面写的是我的工作流程、我的质量标准、我的红线。
但也有个反例。nano-banana-pro 是一个能力增强型 Skill,最初写它是因为模型处理某类格式转换任务总出错。后来模型迭代了一版,这个 Skill 的 eval 得分变成了 1.0 倍——有它和没它一样。模型自己学会了。
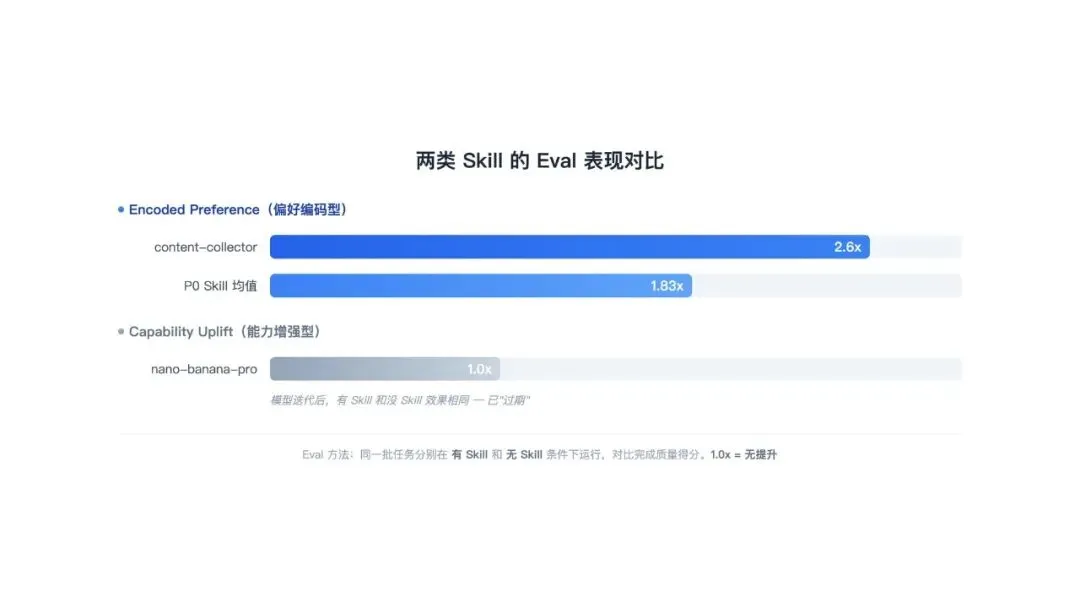
这正好印证了 Anthropic 说的:能力增强型 Skill 寿命有限,模型进步后可能失效。但偏好编码型的价值不受模型升级影响——因为模型再怎么升级,也不会自动知道你的规矩。
Anthropic 团队的 Thariq 在那条 2.8M 浏览的推文里说过一句话:
“Same model on day 1 and day 40. The difference is a stack of markdown files that get richer every single week.”
第 1 天和第 40 天,同一个模型。区别是磁盘上那堆越来越厚的 Markdown 文件。
Saboo 的实践也在验证这个方向。他用 OpenClaw 跑了 8 个 Agent,40 天没换模型——效果持续变好,靠的不是更强的模型,而是更厚的 Skill 文件。
那堆文件就是 Agent 长出来的肌肉记忆。不是低代码那种”阶段性拐杖”,也不是 App Store 里那种”通用标准品”。它是你和你的 Agent 之间独有的默契。
我给这种积累起了另一个名字:上下文护城河。模型是公共资源,谁都能调用同一个 Claude 4。但你的 Skill 文件里编码的私有知识、工作流偏好、行为红线——这些别人复制不了。
李宏毅在 YouTube 的 Context Engineering 系列里用学术语言说了同一件事:模型能力可以通过训练提升,但上下文管理是一个独立的工程问题——你给模型的信息质量,决定了输出质量的上限。Skill 就是上下文管理最系统化的实践。
Hacker News 上有句话说得更直白:”Intelligence is a commodity. Context is the real AI moat.” 智能已经是大宗商品了,上下文才是真正的护城河。Skill 就是这道护城河的砖。
往前看:Skill 的三个演进方向
搞清楚 Skill 的本质之后,更有意思的问题是:它往哪里走?
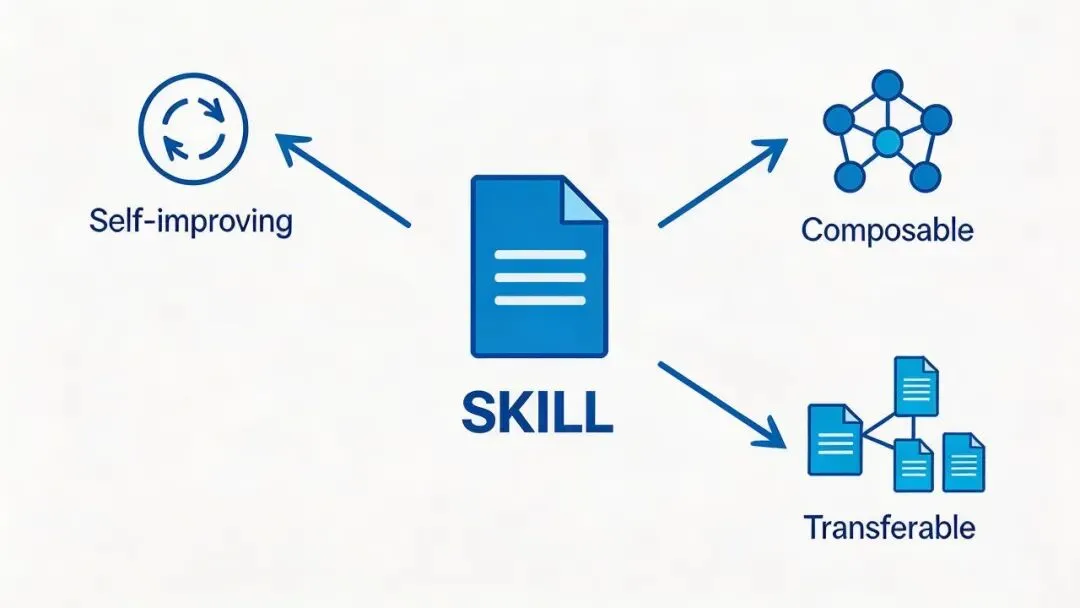
方向一:从人写到自写。
现在 Skill 基本靠人手写 Markdown。但这正在变。Anthropic 的 skill-creator 已经能自动生成 Skill,最近还加了 Evals 框架——自动写测试用例、跑 benchmark、A/B 对比、优化 Description 字段。Saboo 在搭一个基于 Gemini 3 的自改进系统,Agent 自己分析”哪些规则管用、哪些该淘汰”,然后自动迭代 Skill 文件。
终局可能是这样:你不写 Skill,你只给反馈。Agent 把反馈沉淀成规则,自己维护自己的经验手册。Saboo 的 Kelly(他的内容 Agent)已经在这么干了——它自己写了一个”NEVER SUGGEST AGAIN”清单,记录所有被否掉的选题,防止再次推荐。
方向二:从单打到组合。
Thariq 在分享中提到,Claude Code 内部的 Skill 可以”通过名字引用其他技能,构建编排链”。实际上 Skill 还能在自己的目录里存数据(状态、日志、缓存),甚至注册钩子在特定时机自动触发。一个 Skill 调用另一个 Skill,像函数调用一样组合。
这是个大变化。现在大多数人的 Skill 是独立的——content-collector 管收藏、daily-brief 管信息摘要、coding-agent 管写代码。但如果它们能互相调用呢?content-collector 采集到热点素材,自动触发选题评估,再触发 coding-agent 生成数据可视化图表。Skill 不再是一个个孤岛,而是一张可编排的技能网。
方向三:从个人到团队。
Skill 目前主要是个人工具。但 Thariq 提到 Anthropic 内部的做法是”检入代码库”——Skill 跟代码一起做版本管理,团队成员共享、review、迭代。ClawHub 的 3 万 Skill 增长,本质上也是这个趋势的社区版。
想象一下:你写了一个管理代码 review 的 Skill,用了两个月打磨成熟。新人入职,clone 仓库,Agent 自动加载这个 Skill——新人的 Agent 第一天就知道团队的 review 规范。不用开会传达,不用写 wiki 然后没人看。Skill 就是活的文档,而且有人(Agent)真的在读它。
最终形态我觉得是这样的:Agent 通过工作积累自动沉淀 Skill,Skill 之间可以互相调用和编排,成熟的 Skill 可以从个人 Agent 迁移到团队 Agent。人类越来越少直接写 Skill,但”私有知识”的核心价值不变——因为那是你的规矩、你的流程、你的上下文。不是模型训练数据能覆盖的。
写在最后
大多数人还在争论 Skill 会不会被淘汰。这个问题本身就问错了。
被淘汰的只有一种 Skill——弥补模型短板的那种。模型每半年升级一次,你教它的技巧迟早过期。这跟低代码的命运一样,没什么好惋惜的。
但另一种 Skill——编码你的规矩、你的流程、你的判断标准——这种东西不会过期。因为它的价值来源根本不是”模型不够强”,而是”模型不是你”。
Claude 100 再强,也不知道你每周五下午三点前必须提交报销单。GPT-7 再聪明,也猜不到你讨厌标题里出现感叹号。
模型的能力是公共资源。你的上下文是私有资产。
所以别再问”Skill 会不会死”了。问一个更有用的问题:
你现在最重复的那件事,Agent 知道你要怎么做吗?
不知道?那你的第一个 Skill 就在那里。