 夜雨聆风
夜雨聆风





告别PDF解析噩梦:OpenDataLoader让AI轻松处理PDF文件
告别 PDF 解析噩梦:OpenDataLoader PDF —— 为 AI 与合规而生的开源利器
在 AI 浪潮席卷全球的今天,每一个开发者都曾被同一种恐惧支配过:解析 PDF。
无论是为了给大模型(LLM)喂数据构建 RAG(检索增强生成)系统,还是为了满足日益严格的数字化无障碍合规要求,PDF 就像一块“数据黑洞”。那种错乱的阅读顺序、支离破碎的表格、以及无法被索引的扫描件,往往让传统的解析工具束手无策。
今天,我们要深度拆解的这款 GitHub 明星项目——OpenDataLoader PDF(以下简称 OD-PDF),正是一把破冰之斧。它不仅在解析准确率上霸榜,更首次在开源领域实现了端到端的 PDF 无障碍自动化处理。

🚀 项目初衷:为什么我们需要它?
PDF 格式诞生的初衷是为了“显示一致性”,而不是为了“数据提取”。这导致了两个痛点:
- AI 的“消化不良”:大模型需要结构化的 Markdown 或 JSON。如果解析器把双栏论文的左栏第一行接在右栏第一行后面,AI 生成的结果就会变成一派胡言。
- 合规性的“紧箍咒”:全球范围内(如欧盟的 EAA 法案)对 PDF 无障碍性(Accessibility)的要求越来越高。手动为成千上万份 PDF 添加标签(Tagging)的成本高达每份 50-200 美元,企业根本负担不起。
OpenDataLoader PDF 的出现,就是为了解决这两个硬核问题:让 PDF 变成 AI 易读的数据,同时自动化实现 PDF 的无障碍合规。
✨ 项目核心亮点:凭什么它能拿 7k+ Stars?
相比于市面上常见的 PyMuPDF 或 PDFMiner,OD-PDF 的核心优势在于其“混合动力”引擎。
1. 业内顶尖的解析精度
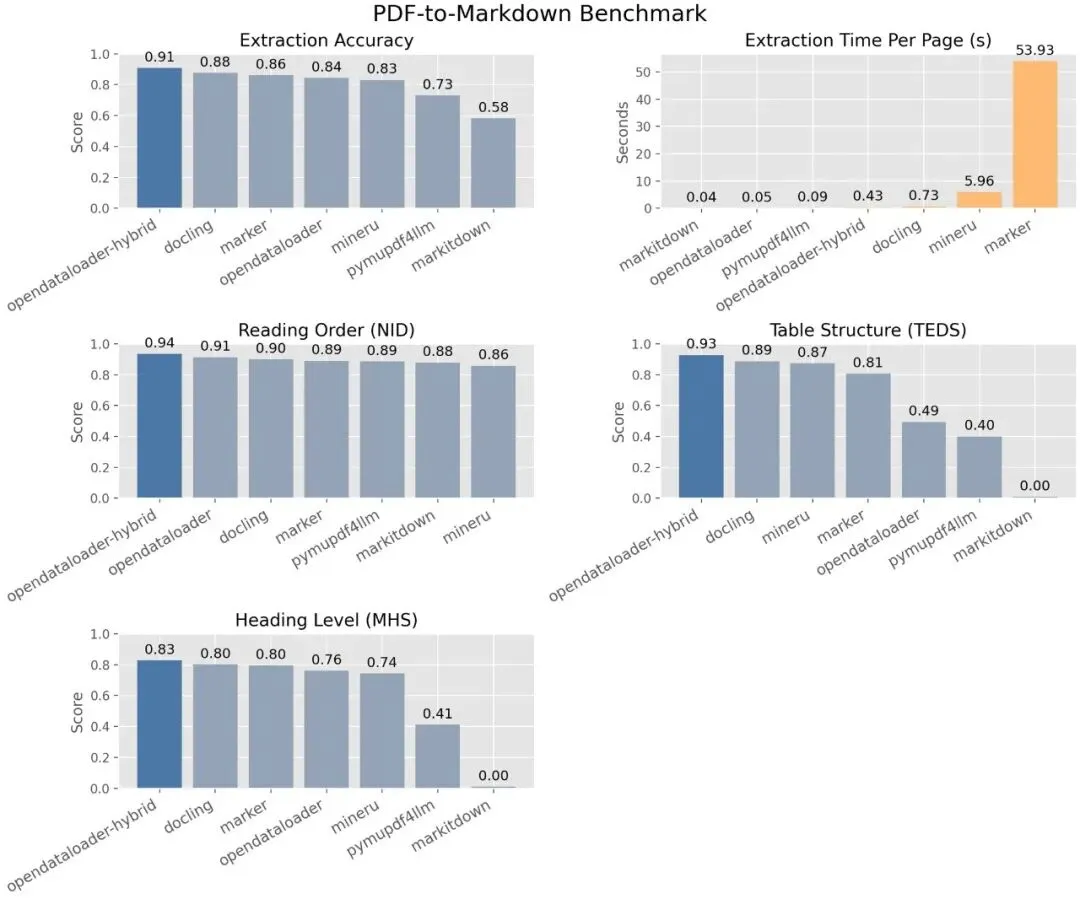
在针对 200 份包含复杂多栏布局、科学论文、财报的真实 PDF 测试中,OD-PDF 拿到了 0.90 的综合准确率评分。特别是在“地狱难度”的表格提取上,其准确率高达 0.93。这得益于它自研的 XY-Cut++ 阅读顺序算法,能够完美还原人类的阅读逻辑。
2. 独创的“混合动力”模式 (Hybrid Mode)
这是 OD-PDF 的杀手锏。它不盲目迷信 AI,也不死守规则:
- 本地模式 (Local Mode):对于标准的电子版 PDF,使用高效的确定性算法,速度快到飞起(单页 0.05 秒)。
- AI 混合模式 (Hybrid Mode):遇到复杂的扫描件、手写体、公式(LaTeX)或复杂的图表,它会自动调用 AI 后端进行 OCR 和语义理解。
3. 首个开源的“无障碍”全栈方案
OD-PDF 与 PDF 协会(PDF Association)以及 veraPDF 的开发团队深度合作,严格遵循 Well-Tagged PDF 规范。它是目前第一个能从“无标签 PDF”直接生成“带标签 PDF(Tagged PDF)”的开源端到端工具,极大地降低了企业的合规成本。
4. 丰富的输出全家桶
它不仅仅给你文字,还给你:
- Markdown:直接喂给 LangChain/LlamaIndex。
- JSON (含 Bounding Boxes):每个元素都有精确的坐标,方便在前端做高亮回溯。
- HTML & Tagged PDF:用于网页发布和无障碍合规。
🛠️ 快速上手指南:30 秒开启解析之旅
OD-PDF 的核心是用 Java 编写的以确保性能,但它提供了 Python、Node.js 和 Java 的多语言 SDK。
环境准备
确保你的系统中安装了 Java 11+(这是高性能引擎的基础)。
Python 快速调用
如果你是 AI 开发者,只需三步:
-
安装
pip install -U opendataloader-pdf -
转换代码
import opendataloader_pdf # 一键将 PDF 转换为 Markdown 和 JSON # 它会自动处理阅读顺序和布局分析 opendataloader_pdf.convert( input_path=["report_2025.pdf", "research_paper.pdf"], output_dir="output_data/", format="markdown,json" ) -
查看结果
在output_data/下,你会惊喜地发现原本复杂的表格已经被精准转化为了 Markdown 表格,且所有的标题层级(H1, H2…)都井然有序。
🎨 应用场景:它适合谁?
1. 法律与金融行业的 RAG 建设
这些行业有海量的扫描合同和多栏研报。使用 OD-PDF 的混合模式,可以确保提取出的文本不再是乱序的“单词汤”,极大提升 RAG 系统召回的准确度。
2. 自动化合规审计
对于需要批量处理政府文件、企业年报以满足无障碍标准的场景,OD-PDF 的 Auto-tagging 功能可以节省 80% 以上的人工操作时间。
3. 学术科研数据清洗
将带有大量复杂公式(LaTeX)和嵌套表格的 PDF 论文转化为结构化数据,用于构建垂直领域的知识库。
📊 优缺点客观分析
优点 ✅
- 精度天花板:目前开源界处理布局识别(Layout Analysis)的首选。
- 极速响应:本地处理逻辑极快,适合大规模批处理。
- 工业级标准:背靠 PDF 协会,生成的 Tagged PDF 符合专业验证(veraPDF)。
- 开发者友好:多语言支持,文档详尽。
缺点 ❌
- 依赖 Java:Python 开发者需要额外配置 Java 环境,这可能会让初学者觉得稍显麻烦。
- 资源消耗:在开启 AI 混合模式处理超大扫描件时,对内存和后端算力有一定要求。
- 进阶功能付费:虽然核心解析完全开源,但 PDF/UA 导出等企业级功能属于商业插件。
⚔️ 同类工具对比:谁更适合你?
| 特性 | OpenDataLoader PDF | PyMuPDF (fitz) | Marker |
|---|---|---|---|
| 解析准确率 | ⭐⭐⭐⭐⭐ (0.90+) | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 表格处理 | 极强 (0.93) | 一般 | 较强 |
| 无障碍合规 | 是 (Auto-tagging) | 否 | 否 |
| 核心技术 | Java + AI Hybrid | C 库 | Python + Deep Learning |
| 主要定位 | AI 数据 + 无障碍合规 | 轻量化文字提取 | Markdown 转换优化 |
💡 使用建议与总结
如果你正在寻找一个工业级的 PDF 解析方案,尤其是需要将 PDF 深度集成进 RAG 流程 或者需要应对 无障碍合规 要求,OpenDataLoader PDF 是目前的无二之选。
我的建议是:
- 对于简单的文本提取,PyMuPDF 依然是轻量之选;
- 对于涉及图表、表格、多栏布局的复杂文档,请务必尝试 OD-PDF。
下一步:
你会考虑在你的下一个 AI 项目中试用 OpenDataLoader PDF 吗?或者你目前在 PDF 解析上遇到了哪些“难啃的硬骨头”?欢迎在评论区分享,我也很乐意为你演示如何针对特定文档进行优化配置!
- GitHub 地址: https://github.com/opendataloader-project/opendataloader-pdf
- Star 数量: 7,416 (持续增长中…)