 夜雨聆风
夜雨聆风





75、AI大模型项目实战之智医助手(下篇)
🏥 AI大模型项目实战之智医助手(下篇):知识图谱构建与Web服务部署
作者:orange来源:开源创富指南
🔥 前言
大家好!在前两篇文章中,我们详细讲解了智医助手的项目架构、知识图谱设计、模型训练和实体抽取。今天,我们将继续深入实战,完成整个智医助手的最后部分:知识图谱构建、实体对齐、对话处理和Web服务部署。
这是系列教程的下篇,主要包含四个核心部分:知识图谱构建、实体对齐、对话处理流程和Web服务部署。内容有点干,但全是干货,建议收藏后慢慢学习!
ai-medical链接:https://pan.baidu.com/s/1tj0BdthEs9XwBpXlEdB5yQ 提取码: bxxc
🗂️ 第1部分:构建知识图谱
1.1 清空Neo4j
在构建知识图谱之前,我们需要清空Neo4j中的旧数据。
核心代码:
importre
importos
importhtml
importjson
importrandom
importconfig
fromtqdmimporttqdm
fromneo4jimportGraphDatabase
tag= {
"error": "\033[1;31m[ERROR]\033[0m",
"success": "\033[1;32m[SUCCESS]\033[0m",
"processing": "\033[1;34m[PROCESSING]\033[0m",
}
# --------- 清空 Neo4j ---------
defclear_neo4j():
"""清空 Neo4j 中的约束和数据,并创建属性唯一性约束"""
# 连接 Neo4j
withGraphDatabase.driver(config.NEO4J_URI, auth=config.NEO4J_AUTH) asdriver:
# 删除所有约束
records, _, _=driver.execute_query("SHOW CONSTRAINTS")
constraints= [record["name"] forrecordinrecords]
forconstraintinconstraints:
driver.execute_query(f"DROP CONSTRAINT {constraint} IF EXISTS")
print(tag["success"], "清空约束")
# 清空数据
driver.execute_query("MATCH (n) DETACH DELETE n")
print(tag["success"], "清空数据")
# 创建属性唯一性约束
forconstraintin [
"CREATE CONSTRAINT disease_disease_name IF NOT EXISTS FOR (n:Disease) REQUIRE n.name IS UNIQUE",
"CREATE CONSTRAINT department_department_name IF NOT EXISTS FOR (n:Department) REQUIRE n.name IS UNIQUE",
"CREATE CONSTRAINT symptom_symptom_name IF NOT EXISTS FOR (n:Symptom) REQUIRE n.name IS UNIQUE",
"CREATE CONSTRAINT cause_cause_desc IF NOT EXISTS FOR (n:Cause) REQUIRE n.desc IS UNIQUE",
"CREATE CONSTRAINT drug_drug_name IF NOT EXISTS FOR (n:Drug) REQUIRE n.name IS UNIQUE",
"CREATE CONSTRAINT food_food_name IF NOT EXISTS FOR (n:Food) REQUIRE n.name IS UNIQUE",
"CREATE CONSTRAINT way_way_name IF NOT EXISTS FOR (n:Way) REQUIRE n.name IS UNIQUE",
"CREATE CONSTRAINT prevent_prevent_desc IF NOT EXISTS FOR (n:Prevent) REQUIRE n.desc IS UNIQUE",
"CREATE CONSTRAINT check_check_name IF NOT EXISTS FOR (n:Check) REQUIRE n.name IS UNIQUE",
"CREATE CONSTRAINT treat_treat_name IF NOT EXISTS FOR (n:Treat) REQUIRE n.name IS UNIQUE",
"CREATE CONSTRAINT people_people_name IF NOT EXISTS FOR (n:People) REQUIRE n.name IS UNIQUE",
"CREATE CONSTRAINT duration_duration_name IF NOT EXISTS FOR (n:Duration) REQUIRE n.name IS UNIQUE",
]:
driver.execute_query(constraint)
print(tag["success"], "属性唯一性约束创建成功")
1.2 读取数据
核心代码:
# --------- 读取数据 ---------
# name: str
# desc: str
# acompany: list
# department: list
# symptom: list
# cause: str
# drug: list
# eat: list
# not_eat: list
# way: str
# prevent: str
# check: list
# treat: list
# people: str
# duration: str
defread_json_file(path):
"""读取 json 文件中的数据"""
withopen(path, "r", encoding="utf-8") asf:
datas= [json.loads(line) forlineinf]
returndatas
1.3 数据清洗
核心代码:
# --------- 数据清洗 ---------
def_standardize_text(text: str) ->str:
"""清洗一条文本"""
ifnot (textandisinstance(text, str)):
returntext
# 移除 HTML 标签
text=re.sub(r"<[^>]+>", "", text)
text=html.unescape(text)
# 全角转半角
res=""
forucharintext:
u_code=ord(uchar)
# 全角空格
ifu_code==12288:
res+=chr(32)
# 其他全角字符 (除空格外)
elif65281<=u_code<=65374:
res+=chr(u_code-65248)
else:
res+=uchar
# 去除首尾空格,并将内部多个空格合并为一个
res=re.sub(r"\s+", " ", res).strip()
returnres
defdata_cleaning(datas):
"""数据清洗"""
fordataindatas:
fork, vindata.items():
ifisinstance(v, str):
data[k] =_standardize_text(v)
elifisinstance(v, list):
foriinrange(len(v)):
data[k][i] =_standardize_text(v[i])
1.4 导入Neo4j
核心代码:
# --------- 导入 Neo4j ---------
def_batched_import(session, batch_data):
"""批量导入数据"""
query="""
UNWIND $batch AS row
MERGE (disease:Disease {name: row.name})
ON CREATE SET disease.desc = row.desc
ON MATCH SET disease.desc = CASE
WHEN disease.desc IS NULL THEN row.desc
ELSE disease.desc
END
// 并发症
WITH row, disease
CALL (row, disease) {
UNWIND row.acompany AS acomp
WITH DISTINCT acomp WHERE acomp IS NOT NULL AND trim(acomp) <> ""
MERGE (c:Disease {name: acomp})
MERGE (disease)-[:ACOMPANY]->(c)
}
// 科室
WITH row, disease
CALL (row, disease) {
UNWIND row.department AS dept
WITH DISTINCT row, disease, dept WHERE dept IS NOT NULL AND trim(dept) <> ""
MERGE (d:Department {name: dept})
MERGE (disease)-[:BELONG]->(d)
}
// 症状
WITH row, disease
CALL (row, disease) {
UNWIND row.symptom AS symp
WITH DISTINCT row, disease, symp WHERE symp IS NOT NULL AND trim(symp) <> ""
MERGE (s:Symptom {name: symp})
MERGE (disease)-[:HAVE]->(s)
}
// 诱因
WITH row, disease
CALL (row, disease) {
WITH row, disease
WHERE row.cause IS NOT NULL AND trim(row.cause) <> ""
MERGE (cs:Cause {desc: row.cause})
MERGE (cs)-[:CAUSE]->(disease)
}
// 药物
WITH row, disease
CALL (row, disease) {
UNWIND row.drug AS drg
WITH DISTINCT row, disease, drg WHERE drg IS NOT NULL AND trim(drg) <> ""
MERGE (dr:Drug {name: drg})
MERGE (disease)-[:COMMON_USE]->(dr)
}
// 宜食用
WITH row, disease
CALL (row, disease) {
UNWIND row.eat AS food
WITH DISTINCT row, disease, food WHERE food IS NOT NULL AND trim(food) <> ""
MERGE (f:Food {name: food})
MERGE (disease)-[:EAT]->(f)
}
// 忌食用
WITH row, disease
CALL (row, disease) {
UNWIND row.not_eat AS bad_food
WITH DISTINCT row, disease, bad_food WHERE bad_food IS NOT NULL AND trim(bad_food) <> ""
MERGE (bf:Food {name: bad_food})
MERGE (disease)-[:NO_EAT]->(bf)
}
// 传播方式
WITH row, disease
CALL (row, disease) {
WITH row, disease
WHERE row.way IS NOT NULL AND trim(row.way) <> ""
MERGE (w:Way {name: row.way})
MERGE (disease)-[:TRANSMIT]->(w)
}
// 预防措施
WITH row, disease
CALL (row, disease) {
WITH row, disease
WHERE row.prevent IS NOT NULL AND trim(row.prevent) <> ""
MERGE (p:Prevent {desc: row.prevent})
MERGE (p)-[:PREVENT]->(disease)
}
// 医学检查
WITH row, disease
CALL (row, disease) {
UNWIND row.check AS test
WITH DISTINCT row, disease, test WHERE test IS NOT NULL AND trim(test) <> ""
MERGE (ch:Check {name: test})
MERGE (ch)-[:CHECK]->(disease)
}
// 治疗方式
WITH row, disease
CALL (row, disease) {
UNWIND row.treat AS treatment
WITH DISTINCT row, disease, treatment WHERE treatment IS NOT NULL AND trim(treatment) <> ""
MERGE (tr:Treat {name: treatment})
MERGE (tr)-[:TREAT]->(disease)
}
// 人群类别
WITH row, disease
CALL (row, disease) {
WITH row, disease
WHERE row.people IS NOT NULL AND trim(row.people) <> ""
MERGE (pl:People {name: row.people})
MERGE (disease)-[:COMMON_ON]->(pl)
}
// 治疗周期
WITH row, disease
CALL (row, disease) {
WITH row, disease
WHERE row.duration IS NOT NULL AND trim(row.duration) <> ""
MERGE (dur:Duration {name: row.duration})
MERGE (disease)-[:TREAT_DURATION]->(dur)
}
"""
session.run(query, parameters={"batch": batch_data})
defimport_data_2_neo4j(datas: list[dict]):
"""导入所有数据到 Neo4j"""
BATCH_SIZE=500
# 连接数据库
withGraphDatabase.driver(config.NEO4J_URI, auth=config.NEO4J_AUTH) asdriver:
withdriver.session() assession:
foriintqdm(range(0, len(datas), BATCH_SIZE), desc="导入数据"):
batch=datas[i : i+BATCH_SIZE]
# 处理字段缺失
batch_prepared= [
{
"name": row["name"],
"desc": row.get("desc", ""),
"acompany": row.get("acompany", []),
"department": row.get("department", []),
"symptom": row.get("symptom", []),
"cause": row.get("cause", ""),
"drug": row.get("drug", []),
"eat": row.get("eat", []),
"not_eat": row.get("not_eat", []),
"way": row.get("way", ""),
"prevent": row.get("prevent", ""),
"check": row.get("check", []),
"treat": row.get("treat", []),
"people": row.get("people", ""),
"duration": row.get("duration", ""),
}
forrowinbatch
]
# 批量导入
_batched_import(session, batch_prepared)
1.5 处理标注数据集
将带标注数据处理为用于微调 UIE 的数据格式,以及方便写入 Neo4j 的数据格式。
核心代码:
# --------- 处理标注数据 ---------
defprocess_annotated_data(tgt_path):
"""将标注数据转换为模型微调数据、和符合知识图谱结构的数据"""
predicate_name_map= {
"预防": "预防措施",
"辅助治疗": "治疗方式",
"化疗": "治疗方式",
"放射治疗": "治疗方式",
"手术治疗": "治疗方式",
"实验室检查": "医学检查",
"影像学检查": "医学检查",
"辅助检查": "医学检查",
"组织学检查": "医学检查",
"内窥镜检查": "医学检查",
"筛查": "医学检查",
"多发群体": "人群类别",
"传播途径": "传播途径",
"并发症": "并发症",
"相关(转化)": "诱因",
"相关(症状)": "症状",
"临床表现": "症状",
"治疗后症状": "症状",
"侵及周围组织转移的症状": "症状",
"病因": "诱因",
"高危因素": "诱因",
"风险评估因素": "诱因",
"病史": "诱因",
"遗传因素": "诱因",
"发病机制": "诱因",
"病理生理": "诱因",
"药物治疗": "药物",
"预后状况": "治疗周期",
}
name_label_map= {
"疾病": "name",
"描述": "desc",
"科室": "department",
"症状": "symptom",
"并发症": "acompany",
"诱因": "cause",
"药物": "drug",
"宜食用": "eat",
"忌食用": "not_eat",
"传播途径": "way",
"预防措施": "prevent",
"医学检查": "check",
"治疗方式": "treat",
"人群类别": "people",
"治疗周期": "duration",
}
deffindall_entity_pos_in_content(content, entity):
"""返回 content 中该实体所有的位置"""
result_list= []
formatchinre.finditer(re.escape(entity), content):
start_idx=match.start()
end_idx=match.end()
result_list.append({"text": entity, "start": start_idx, "end": end_idx})
returnresult_list
with (
open(
config.BASE_DIR/"data/annotated_data/CMeIE-V2.jsonl",
"r",
encoding="utf-8",
) asread_file,
open(tgt_path, "w", encoding="utf-8") aswrite_kg_file,
):
finetuning_data= []
kg_data= []
forlineinread_file:
data=json.loads(line)
content=data["text"]
disease_dict= {}
forspoindata["spo_list"]:
ifspo["predicate"] notinpredicate_name_map:
continue
disease=disease_dict.setdefault(spo["subject"], {})
disease.setdefault(predicate_name_map[spo["predicate"]], []).append(
spo["object"]["@value"]
)
# 处理为模型微调的数据格式
fordisease, relationsindisease_dict.items():
sample= {
"content": content,
"prompt": "疾病",
"result_list": findall_entity_pos_in_content(content, disease),
}
finetuning_data.append(json.dumps(sample, ensure_ascii=False))
forrelation, entitiesinrelations.items():
forentityinentities:
sample= {
"content": content,
"prompt": relation,
"result_list": findall_entity_pos_in_content(
content, entity
),
}
sample_with_relation= {
"content": content,
"prompt": f"{disease}的{relation}",
"result_list": findall_entity_pos_in_content(
content, entity
),
}
finetuning_data.append(json.dumps(sample, ensure_ascii=False))
finetuning_data.append(
json.dumps(sample_with_relation, ensure_ascii=False)
)
# 处理为对应知识图谱结构的数据
fordisease, relationsindisease_dict.items():
tmp_sample= {"疾病": disease}
tmp_sample.update(relations)
sample= {}
fork, vintmp_sample.items():
sample[name_label_map[k]] =v
ifname_label_map[k] in [
"cause",
"way",
"prevent",
"people",
"duration",
]:
sample[name_label_map[k]] ="、".join(v)
kg_data.append(json.dumps(sample, ensure_ascii=False))
# 将模型微调数据写入文件
random.shuffle(finetuning_data)
total=len(finetuning_data)
train_end=int(total*0.8)
valid_end=train_end+int(total*0.1)
train_data=finetuning_data[:train_end]
valid_data=finetuning_data[train_end:valid_end]
test_data=finetuning_data[valid_end:]
uie_processed_dir=config.BASE_DIR/"data/uie/processed"
os.makedirs(uie_processed_dir, exist_ok=True)
withopen(uie_processed_dir/"train.jsonl", "w", encoding="utf-8") asf_train:
f_train.writelines(sample+"\n"forsampleintrain_data)
withopen(uie_processed_dir/"valid.jsonl", "w", encoding="utf-8") asf_valid:
f_valid.writelines(sample+"\n"forsampleinvalid_data)
withopen(uie_processed_dir/"test.jsonl", "w", encoding="utf-8") asf_test:
f_test.writelines(sample+"\n"forsampleintest_data)
# 将知识图谱数据写入文件
write_kg_file.writelines(sample+"\n"forsampleinkg_data)
🔗 第2部分:实体对齐
2.1 构建同义词→标准词映射
核心代码:
importconfig
importpymysql
importhashlib
importchromadb
importsubprocess
fromtqdmimporttqdm
fromsklearn.clusterimportDBSCAN
fromcollectionsimportdefaultdict
fromsentence_transformersimportSentenceTransformer
fromsklearn.metrics.pairwiseimportcosine_similarity
tag= {
"error": "\033[1;31m[ERROR]\033[0m",
"success": "\033[1;32m[SUCCESS]\033[0m",
"processing": "\033[1;34m[PROCESSING]\033[0m",
}
_embedding_model=None
# --------- 创建 MySQL 数据库与建表 ---------
defcreate_mysql_db(host, user, password, database, charset="utf8mb4"):
"""创建数据库"""
# MySQL 命令前缀,包括 host、user、password
mysql_cmd_prefix= [
"mysql",
"-h",
host,
"-u",
user,
f"-p{password}",
f"--default-character-set={charset}",
]
# 创建数据库
print(f"{tag['processing']} 创建 {database}")
cmd=mysql_cmd_prefix+ [
"-e",
f"DROP DATABASE IF EXISTS {database}; CREATE DATABASE {database};",
]
result=subprocess.run(cmd, stderr=subprocess.PIPE, text=True)
ifresult.returncode!=0:
print(f"{tag['error']}{result.stderr.splitlines()[1:][0]}")
return
print(f"{tag['success']}{database} 创建成功")
# collate utf8mb4_bin 设置字段大小写敏感
sql_content="""
create table if not exists
entity_mapping (
id varchar(255) not null comment '实体 ID',
synonym varchar(255) not null collate utf8mb4_bin comment '同义词',
std_name varchar(255) not null comment '标准词',
entity_schema varchar(255) not null comment '实体类型',
is_reviewed int default 0 not null comment '是否已审核',
create_time timestamp default current_timestamp comment '创建时间',
update_time timestamp default null on update current_timestamp comment '更新时间',
primary key (synonym, entity_schema)
) comment '实体映射表';
"""
try:
withpymysql.connect(**config.MYSQL_CONFIG) asmysql_conn:
withmysql_conn.cursor(pymysql.cursors.DictCursor) ascursor:
cursor.execute(sql_content)
exceptpymysql.err.OperationalErrorase:
# 如果目标数据库不存在
ife.args[0] ==1049:
create_mysql_db(**config.MYSQL_CONFIG)
withpymysql.connect(**config.MYSQL_CONFIG) asmysql_conn:
withmysql_conn.cursor(pymysql.cursors.DictCursor) ascursor:
cursor.execute(sql_content)
else:
print(tag["error"], e)
exit(1)
defget_embedding_model():
"""获取嵌入模型"""
global_embedding_model
if_embedding_modelisNone:
_embedding_model=SentenceTransformer(
str(config.PRETRAINED_DIR/"bge-base-zh-v1.5")
)
print(tag["success"], "加载嵌入模型")
return_embedding_model
defentity_alignment(datas, entity_schema, embed_batch_size=128):
"""
实体对齐
如果是初始化:
向量化
聚类
选取高频词作为标准词
所有同义词映射为标准词
如果是增量更新:
新实体向量化
聚类
选出新实体中的高频词作为临时标准词
计算临时标准词和旧标准词的相似度
如果临时标准词和旧标准词相似,使用旧标准词
如果临时标准词没有相似项,将其作为新标准词
所有同义词映射为标准词
"""
field_type_mapping= {
"name": "disease",
"symptom": "symptom",
"cause": "cause",
"drug": "drug",
"eat": "food",
"no_eat": "food",
"people": "people",
"check": "check",
}
embedding_model=get_embedding_model()
# 加载 MySQL 中同义词到标准词的映射
withpymysql.connect(**config.MYSQL_CONFIG) asmysql_conn:
withmysql_conn.cursor(pymysql.cursors.DictCursor) ascursor:
cursor.execute(
"select id, synonym, std_name from entity_mapping where entity_schema=%s and is_reviewed=1",
(field_type_mapping[entity_schema],),
)
old_entity_mapping=cursor.fetchall()
old_entities= []
ifold_entity_mapping:
print(
tag["success"],
f"读取 {len(old_entity_mapping)} 条已对齐的 {field_type_mapping[entity_schema]} 实体",
)
old_ids, old_entities, old_std_entities=zip(
*[(x["id"], x["synonym"], x["std_name"]) forxinold_entity_mapping]
)
# 旧的实体ID
old_ids=list(set(old_ids))
# 旧的实体列表
old_entities=list(set(old_entities))
# 旧的标准词列表
old_std_entities=list(set(old_std_entities))
# 同义词到标准词的映射
old_entity_mapping= {x["synonym"]: x["std_name"] forxinold_entity_mapping}
# 收集所有新增实体,并统计出现频率
new_entity_with_frequency=dict()
foriindatas:
entity=i.get(entity_schema)
ifnotentity:
continue
ifisinstance(entity, str):
entity= [entity]
forentity_iteminentity:
ifnotentity_item:
continue
frequency=new_entity_with_frequency.get(entity_item, 0) +1# 频率+1
new_entity_with_frequency[entity_item] =frequency# 更新频率
# 取补集,筛选出新出现的实体
new_entities=list(set(new_entity_with_frequency) -set(old_entities))
# 如果有新增实体
new_entity_mapping= {} # 同义词 → 标准词
ifnew_entities:
print(
tag["processing"],
f"检测到 {len(new_entities)} 个新增 {field_type_mapping[entity_schema]} 实体",
)
# 初始化与增量更新通用流程:将新实体聚类并根据频次选择标准词
# 获取新实体的向量
new_embeddings=embedding_model.encode(
new_entities, batch_size=embed_batch_size, normalize_embeddings=True
)
# 使用 DBSCAN 聚类,相似的视为同义实体
algorithm=DBSCAN(eps=0.15, min_samples=1, metric="cosine")
# 得到每个实体对应的簇ID
cluster_ids=algorithm.fit_predict(new_embeddings)
# 将实体按簇编号组成列表
cluster_dict=defaultdict(list) # 簇ID → 实体列表
forentity, cluster_idinzip(new_entities, cluster_ids):
ifcluster_id>=0: # 过滤噪声簇,理论上 min_samples=1 没有噪声簇
cluster_dict[cluster_id].append(entity)
# 如果是初始化阶段,聚类,并选择高频词作为标准词
ifnotold_entities:
forcluster_id, entity_listincluster_dict.items():
# 选择每个簇中频率最高的概念作为标准词
std_entity=max(
entity_list, key=lambdax: new_entity_with_frequency[x]
)
forentityinentity_list:
new_entity_mapping[entity] =std_entity
else:
temp_std_to_cluster: dict[str, list[str]] = {} # 临时标准词 → 所有同义词
forcluster_id, entity_listincluster_dict.items():
# 选择每个簇中频率最高的概念作为标准词
std_entity=max(
entity_list, key=lambdax: new_entity_with_frequency[x]
)
temp_std_to_cluster[std_entity] =entity_list
# 获取所有临时标准词的向量
temp_std_list=list(temp_std_to_cluster.keys())
temp_embeddings=embedding_model.encode(
temp_std_list, batch_size=embed_batch_size, normalize_embeddings=True
)
# 获取旧标准词的向量(也可以先计算出id,再从向量数据库中获取,并对Mysql中有但是Chroma中没有的进行嵌入)
old_embeddings=embedding_model.encode(
old_std_entities, batch_size=embed_batch_size, normalize_embeddings=True
)
# 计算临时标准词与旧标准词的相似度
similarity_matrix=cosine_similarity(temp_embeddings, old_embeddings)
# 合并实体
threshold=0.85
fori, temp_stdinenumerate(temp_std_list):
most_similar_idx=similarity_matrix[i].argmax()
max_sim=similarity_matrix[i][most_similar_idx]
# 如果临时标准词匹配到旧的标准词,将所有同义词映射到旧标准词
ifmax_sim>=threshold:
forentityintemp_std_to_cluster[temp_std]:
new_entity_mapping[entity] =old_std_entities[most_similar_idx]
# 如果临时标准词没有找到匹配,使用临时标准词作为新的标准词
else:
forentityintemp_std_to_cluster[temp_std]:
new_entity_mapping[entity] =temp_std
# 将新增实体的映射存储到 MySQL
insert_count=0
withpymysql.connect(**config.MYSQL_CONFIG) asmysql_conn:
withmysql_conn.cursor(pymysql.cursors.DictCursor) ascursor:
forentityinnew_entity_mapping:
result=cursor.execute(
"insert ignore into entity_mapping (id, synonym, std_name, entity_schema, is_reviewed) value(%s, %s, %s, %s, 1)",
(
f"{field_type_mapping[entity_schema]}_{hashlib.md5(new_entity_mapping[entity].encode()).hexdigest()[:16]}",
entity,
new_entity_mapping[entity],
field_type_mapping[entity_schema],
),
)
insert_count+=result
mysql_conn.commit()
print(
tag["success"],
f"添加 {len(insert_count)} 条 {field_type_mapping[entity_schema]} 实体到数据库",
)
# 合并新旧标准词映射
all_entity_mapping=new_entity_mapping
ifold_entity_mapping:
all_entity_mapping.update(old_entity_mapping)
# 替换原始数据
foriindatas:
entity=i.get(entity_schema)
ifnotentity:
continue
ifisinstance(entity, str):
i[entity_schema] =all_entity_mapping.get(entity, entity)
elifisinstance(entity, list):
new_entity= []
forentity_iteminentity:
new_entity.append(all_entity_mapping.get(entity_item, entity_item))
i[entity_schema] =new_entity
2.2 构建向量索引
核心代码:
defvector_indexing(datas, embed_batch_size=128, add_batch_size=256):
"""创建向量索引"""
# 疾病:str,症状:list,诱因:str,药物:list,食物:list,人群类别:str,医学检查:list
field_type_mapping= {
"name": "disease",
"symptom": "symptom",
"cause": "cause",
"drug": "drug",
"eat": "food",
"no_eat": "food",
"people": "people",
"check": "check",
}
vector_items=defaultdict(list)
fordataindatas:
forkey, valueindata.items():
field_type=field_type_mapping.get(key)
ifnotfield_type:
continue
ifisinstance(value, str):
ifnotvalue:
continue
vector_items[field_type].append(
{
"id": f"{field_type}_{hashlib.md5(value.encode()).hexdigest()[:16]}",
"metadata": {"type": field_type},
"document": f"{value}",
}
)
elifisinstance(value, list):
foriinvalue:
ifnoti:
continue
vector_items[field_type].append(
{
"id": f"{field_type}_{hashlib.md5(i.encode()).hexdigest()[:16]}",
"metadata": {"type": field_type},
"document": f"{i}",
}
)
# 合并结果
all_vector_items= (
vector_items["disease"]
+vector_items["symptom"]
+vector_items["cause"]
+vector_items["drug"]
+vector_items["food"]
+vector_items["people"]
+vector_items["check"]
)
ids= [x["id"] forxinall_vector_items]
# 创建或加载向量数据库
client=chromadb.PersistentClient(path=config.VECTOR_STORE_DIR)
collection=client.get_or_create_collection("medical")
# 删数据库中与新增数据 ID 重复的数据,以及过滤新增数据中重复数据
seen=set()
old_ids=collection.get()["ids"]
new_ids=set(ids) -set(old_ids)
new_items= [
(i["id"], i["metadata"], i["document"])
foriinall_vector_items
ifi["id"] innew_ids
andnot (i["id"] inseenorseen.add(i["id"]))
andi["document"]
]
duplicate_data_num=len(set(ids)) -len(new_items)
ifduplicate_data_num:
print(tag["success"], f"{duplicate_data_num} 条数据已存在于向量数据库中")
ifnotnew_items:
return
ids, metadatas, documents=zip(*new_items)
ids=list(ids)
documents=list(documents)
metadatas=list(metadatas)
# 批量嵌入
embedding_model=get_embedding_model()
embeddings=embedding_model.encode(
documents,
batch_size=embed_batch_size,
show_progress_bar=True,
normalize_embeddings=True,
)
# 批量添加到向量数据库
foriintqdm(range(0, len(ids), add_batch_size), desc="writing into chroma"):
collection.add(
ids=ids[i : i+add_batch_size],
documents=documents[i : i+add_batch_size],
metadatas=metadatas[i : i+add_batch_size],
embeddings=embeddings[i : i+add_batch_size],
)
print(tag["success"], f"添加 {len(new_items)} 条数据到向量数据库")
# 存储到 MySQL
insert_count=0
withpymysql.connect(**config.MYSQL_CONFIG) asmysql_conn:
withmysql_conn.cursor(pymysql.cursors.DictCursor) ascursor:
forentityinnew_items:
result=cursor.execute(
"insert ignore into entity_mapping (id, synonym, std_name, entity_schema, is_reviewed) value(%s, %s, %s, %s, 1)",
(
entity[0], # id
entity[2], # document
entity[2], # document
entity[1]["type"], # metadata[type]
),
)
insert_count+=result
mysql_conn.commit()
print(tag["success"], f"添加 {len(insert_count)} 条实体到数据库")
2.3 实体对齐类
核心代码:
classEntityAlignment:
"""实体对齐"""
def__init__(self):
self.embedding_model=get_embedding_model()
self.chroma_client=chromadb.PersistentClient(path=config.VECTOR_STORE_DIR)
defentity_mapping(self, text, entity_schema):
"""标准词映射"""
withpymysql.connect(**config.MYSQL_CONFIG) asmysql_conn:
withmysql_conn.cursor(pymysql.cursors.DictCursor) ascursor:
cursor.execute(
"select std_name from entity_mapping where is_reviewed=1 and synonym=%s and entity_schema=%s",
(text, entity_schema),
)
res=cursor.fetchone()
ifres:
res=res["std_name"]
returnres
defvector_retrieve(self, text, where=None, n_results=1, threshold=1.0):
"""向量检索"""
embedding=self.embedding_model.encode(text, normalize_embeddings=True)
collection=self.chroma_client.get_collection("medical")
res=collection.query(embedding, n_results=n_results, where=where)
# 按阈值过滤,返回 metadata
res= [
res["documents"][0][i]
foriinrange(len(res["ids"][0]))
ifres["distances"][0][i] <threshold
]
res=res[0] ifreselseNone
returnres
def__call__(self, text, entity_schema):
# 先从同义词-标准词中匹配
res=self.entity_mapping(text, entity_schema)
# 如果没有匹配成功,嵌入并检索
ifnotres:
res=self.vector_retrieve(text, where={"type": entity_schema})
ifres:
# 将文本和检索出来的标准词写入 MySQL
withpymysql.connect(**config.MYSQL_CONFIG) asmysql_conn:
withmysql_conn.cursor(pymysql.cursors.DictCursor) ascursor:
cursor.execute(
"insert ignore into entity_mapping (synonym, std_name, entity_schema, is_reviewed) value(%s, %s, %s, 1)",
(text, res, entity_schema),
)
mysql_conn.commit()
returnres
💬 第3部分:对话处理流程
3.1 基于规则的意图识别
核心代码:
import re
class IntentRecognizeRuleBase:
"""意图识别-规则"""
def __init__(self):
# 定义意图关键词库
self.intent_keywords = {
"request": {
"挂号预约": ["挂号", "预约挂号", "挂专家号", "约号", "挂个号", "医生预约", "门诊预约", "看病预约", "预约医生", "号源"],
"检查预约": ["检查预约", "预约检查", "做检查", "约检查", "化验预约", "体检预约", "影像预约", "B超", "CT", "核磁", "胃镜", "肠镜"],
# ... 更多关键词
},
"consult": {
"疾病对应详情": ["什么是", "什么是病", "简介", "概述", "基本情况", "定义", "解释", "详细说明", "详细介绍"],
"疾病对应科室": ["挂什么科", "看什么科", "哪个科室", "什么科室", "就诊科室", "挂号科室", "属于什么科", "找哪个科", "看哪科"],
# ... 更多关键词
},
}
self.intent_patterns = {
"request": {
"挂号预约": [
r"(预约|约|挂)(个)?(专家|普通)?(门诊|号|挂号)",
r"(想|要|需要)(去|在)?(医院)?(挂号|预约挂号|挂个号)",
r"(医生|专家)\s?(预约|挂号)",
],
# ... 更多正则表达式
},
"consult": {
"疾病对应详情": [
r"(什么是|啥叫|解释一下|介绍)(.*?)(病|疾病|症)",
r"(.*?)(的)?(定义|概述|基本情况|详细说明)",
],
# ... 更多正则表达式
},
}
def __call__(self, text):
"""识别意图"""
text = re.sub(r"\s+", " ", text).strip() # 移除多余空格
res = {}
for intent_level1 in ["request", "consult"]:
# 正则表达式匹配
for intent, patterns in self.intent_patterns[intent_level1].items():
for pattern in patterns:
if re.search(pattern, text, re.IGNORECASE):
res.setdefault(intent_level1, []).append(intent)
# 关键词匹配
for intent, keywords in self.intent_keywords[intent_level1].items():
for keyword in keywords:
if keyword in text:
res.setdefault(intent_level1, []).append(intent)
if intent_level1 in res:
res[intent_level1] = list(set(res[intent_level1]))
return res
3.2 基于规则的实体抽取
核心代码:
import jieba
from neo4j import GraphDatabase
from rapidfuzz import fuzz, process
from collections import defaultdict
from config import NEO4J_URI, NEO4J_AUTH
class EntityExtractorRuleBase:
"""实体抽取-基于规则"""
def __init__(self):
# 初始化关键词字典
self.entity_dict = {}
with GraphDatabase.driver(uri=NEO4J_URI, auth=NEO4J_AUTH) as driver:
for entity_type, node_name, label_type, value in [
("疾病", "disease", "Disease", "name"),
("症状", "symptom", "Symptom", "name"),
("诱因", "cause", "Cause", "desc"),
("药物", "drug", "Drug", "name"),
("食物", "food", "Food", "name"),
("人群类别", "people", "People", "name"),
("医学检查", "check", "Check", "name"),
]:
self.entity_dict[entity_type] = [
record[0]
for record in driver.execute_query(
f"MATCH ({node_name}:{label_type}) RETURN {node_name}.{value}"
)[0]
]
# 构造关键词倒排索引
self.inverted_index_dict = {
"疾病": self.build_inverted_index(self.entity_dict["疾病"]),
"症状": self.build_inverted_index(self.entity_dict["症状"]),
"诱因": self.build_inverted_index(self.entity_dict["诱因"]),
"药物": self.build_inverted_index(self.entity_dict["药物"]),
"食物": self.build_inverted_index(self.entity_dict["食物"]),
"人群类别": self.build_inverted_index(self.entity_dict["人群类别"]),
"医学检查": self.build_inverted_index(self.entity_dict["医学检查"]),
}
def __call__(self, text, schema: list):
"""实体抽取,更新实体槽位"""
slots: dict[str, list[str]] = {}
# 使用关键词匹配实体
for entity_type in schema:
for value in self.entity_dict[entity_type]:
if value and value in text:
slots[entity_type] = [value]
break
# 使用倒排索引匹配实体
for entity_type in [
"疾病",
"症状",
"诱因",
"药物",
"食物",
"人群类别",
"医学检查",
]:
if entity_type in schema and slots.get(entity_type) is None:
res = self.query_inverted_index(
text, self.inverted_index_dict[entity_type]
)
if res:
slots[entity_type] = [res]
else:
# 使用模糊匹配提取实体
match = process.extractOne(
text,
self.entity_dict[entity_type],
scorer=fuzz.ratio,
score_cutoff=60,
)
if match:
slots[entity_type] = [match[0]]
return slots
def build_inverted_index(self, entity_list):
"""构建关键词倒排索引"""
stopwords = {"之", "从", "到", "与", "的", "和", "-", "--"}
inverted_index = defaultdict(list) # 关键词->实体列表
for entity_name in entity_list:
# 提取实体名称中的关键词
keywords = jieba.lcut(entity_name)
for keyword in keywords:
keyword = keyword.strip().lower()
if keyword and len(keyword) > 1 and keyword not in stopwords:
inverted_index[keyword].append(entity_name)
return inverted_index
def query_inverted_index(self, text, inverted_index):
"""查询倒排索引"""
best_res = None
candidates = defaultdict(int) # 候选实体->分数
# 提取文本中的关键词
keywords = jieba.lcut(text)
for keyword in keywords:
keyword = keyword.strip().lower()
for entity_name in inverted_index.get(keyword, []):
candidates[entity_name] += 1
if candidates:
# 选择出现次数最多的实体作为匹配结果
if max(candidates.values()) >= 2:
best_res = max(candidates, key=candidates.get)
return best_res
3.3 调用大模型生成回复
核心代码:
import os
import config
from requests import Session
from transformers import AutoTokenizer
class DialogLLM:
"""使用大模型生成回复"""
def __init__(self):
self.session = Session()
self.url = "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions"
self.model_name = "qwen-plus-2025-04-28"
self.max_tokens = 128 * 1024
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.getenv('TONGYI_API_KEY')}", # 从环境变量获取 API-Key
}
self.tokenizer = AutoTokenizer.from_pretrained(config.PRETRAINED_DIR / "qwen")
self.prompt_prefix = (
"你是一个专业医疗助手,必须严格遵守以下规则:\n"
"1. 回答必须严格基于提供的医疗信息,禁止编造任何未提及的细节\n"
"2. 仅使用提供的医疗信息回答\n"
"3. 当医疗信息不存在时,回复:'未查询到相关信息,请提供更多信息或咨询其他内容'\n"
"4. 无论何种情况,不得使用外部知识补充回答\n"
"5. 对于任何无法直接执行的请求(如操作类、主观类、非医疗信息类),不生成任何文字(包括解释、建议或道歉)\n"
"医疗信息:"
)
self.messages: list[dict] = [{"role": "system", "content": ""}]
def _count_tokens(self, message: list[dict]):
"""计算 token 长度"""
return (
len(
self.tokenizer.apply_chat_template(
message, tokenize=True, add_generation_prompt=False
)
)
- 6
)
def _check_token_len(self, prompt: str):
"""检查 tokens 长度是否超出限制,如果超出进行处理"""
max_input_ratio = 0.6
# 如果消息总长度超过限制
while self._count_tokens(self.messages) > max_input_ratio * self.max_tokens:
# 如果 system_prompt 过长
if (
self._count_tokens([self.messages[0]])
> 0.7 * max_input_ratio * self.max_tokens
):
# 截半 prompt
prompt = prompt[: int(len(prompt) / 2)]
self.messages[0]["content"] = self.prompt_prefix + prompt
# 如果当次用户输入过长
elif (
self._count_tokens([self.messages[-1]])
> 0.3 * max_input_ratio * self.max_tokens
):
# 清空历史消息
self.messages = [self.messages[0]] + [self.messages[-1]]
# 截半当次用户输入
self.messages[-1]["content"] = self.messages[-1]["content"][
: int(len(self.messages[-1]["content"]) / 2)
]
# 如果历史消息过长,截半历史消息
else:
self.messages = [self.messages[0]] + self.messages[
int(len(self.messages) / 4) * 2 + 1 :
]
def __call__(self, user_input, prompt: str = ""):
prompt = str(prompt)
# 将 prompt 添加到 system 消息中
self.messages[0]["content"] = self.prompt_prefix + prompt
# 向 messages 中添加 user 消息
self.messages.append({"role": "user", "content": user_input})
# 检查 token 长度是否超过限制
self._check_token_len(prompt)
# 发送请求
data = {"model": self.model_name, "messages": self.messages, "stream": False}
resp = self.session.post(url=self.url, headers=self.headers, json=data).json()
# 获取回复消息
resp_message = resp["choices"][0]["message"]
# 向 messages 中添加 assistant 消息
self.messages.append(resp_message)
return resp_message["content"]
3.4 对话处理整体流程
核心代码:
import config
from neo4j import GraphDatabase
from dialog_llm import DialogLLM
from entity_alignment import EntityAlignment
from intent_recognize_rule_base import IntentRecognizeRuleBase
from entity_extractor_rule_base import EntityExtractorRuleBase
from entity_extractor_model_base import EntityExtractorModelBase
from models_def import IntentClassifyModel, SpellCheckModel, load_params
class DialogProcess:
def __init__(self):
# 意图识别-规则
self.intent_recognize_rule_base = IntentRecognizeRuleBase()
# 意图识别-模型
self.intent_classify_model = IntentClassifyModel(
config.PRETRAINED_DIR / "bert-base-chinese", config.INTENT_INFO
)
load_params(
self.intent_classify_model, config.FINETUNED_DIR / "intent_classify.pt"
)
# 拼写纠错-模型
self.spell_check_model = SpellCheckModel(
config.PRETRAINED_DIR / "bert-base-chinese"
)
load_params(self.spell_check_model, config.FINETUNED_DIR / "spell_check.pt")
# 实体抽取-规则
self.entity_extractor_rule_base = EntityExtractorRuleBase()
# 实体抽取-模型
self.entity_extractor_model_base = EntityExtractorModelBase(
config.FINETUNED_DIR / "uie/model_best", "gpu"
)
# Neo4j 驱动
self.driver = GraphDatabase.driver(config.NEO4J_URI, auth=config.NEO4J_AUTH)
self.ea = EntityAlignment()
self.entity_schema_zh_en_mapping = {
"疾病": "disease",
"症状": "symptom",
"诱因": "cause",
"药物": "drug",
"食物": "food",
"人群类别": "people",
"医学检查": "check",
}
# 使用大模型生成回复
self.llm = DialogLLM()
def entity_extract(self, text, schema):
# 实体抽取-规则
slots = self.entity_extractor_rule_base(text, schema)
slots = {k: v[0] for k, v in slots.items()}
# 取出未填充的槽位
rest_schema = list(set(schema) - set(slots.keys()))
if not rest_schema:
return slots
# 实体抽取-模型
model_extract_res = self.entity_extractor_model_base(text, rest_schema)
model_extract_res = {k: v[0] for k, v in model_extract_res.items()}
# 实体对齐
model_extract_res = {
k: std_name
for k, v in model_extract_res.items()
if (std_name := self.ea(v, self.entity_schema_zh_en_mapping[k]))
}
# 添加到槽位
slots.update(model_extract_res)
rest_schema = list(set(schema) - set(slots.keys()))
if not rest_schema:
return slots
# 如果仍存在未填充的槽位,使用向量检索直接匹配
retrieved_res = {
k: std_name
for k in rest_schema
if (
std_name := self.ea.vector_retrieve(
text, where={"type": self.entity_schema_zh_en_mapping[k]}
)
)
}
# 添加到槽位
slots.update(retrieved_res)
rest_schema = list(set(schema) - set(slots.keys()))
return slots
def __call__(self, text):
response = {}
# 意图识别-规则
intent = self.intent_recognize_rule_base(text)
# 意图识别-模型
if not intent:
intent = self.intent_classify_model.predict(text)
if "request" in intent:
response["request"] = intent["request"]
if "consult" not in intent:
return response
# 拼写纠错
text = self.spell_check_model.predict(text)
# 实体抽取
slots = {}
query_res = []
for consult_intent in intent["consult"]:
slots.update(self.entity_extract(text, config.ENTITY_INFO[consult_intent]))
# 查询Neo4j并生成回复
# ... (省略Cypher查询部分,详见原文)
response["message"] = self.llm(text, query_res)
if "request" not in response and "message" not in response:
response["message"] = "抱歉,我无法理解您的问题,请描述得更清晰一些😥"
return response
🚀 第4部分:Web服务部署
4.1 构建Web服务
核心代码:
import uvicorn
from fastapi import FastAPI, Request
from dialog_process import DialogProcess
from fastapi.staticfiles import StaticFiles
from fastapi.responses import JSONResponse, RedirectResponse
# 初始化组件
dialog_process = DialogProcess()
# 创建 FastAPI 实例
app = FastAPI()
# 挂载静态文件
app.mount("/static", StaticFiles(directory="templates"))
# 首页
@app.get("/")
async def homepage():
return RedirectResponse("/static/index.html")
# 处理用户消息
@app.post("/chat")
async def handle_message(request: Request):
data = await request.json()
user_message = data["message"]
resp = dialog_process(user_message) # {request: ,message: }
return JSONResponse(resp)
if __name__ == "__main__":
uvicorn.run("app:app", host="127.0.0.1", port=8089, reload=True)
4.2 服务界面
启动服务后,您可以通过浏览器访问 http://127.0.0.1:8089 来使用智医助手。
【Web服务界面】
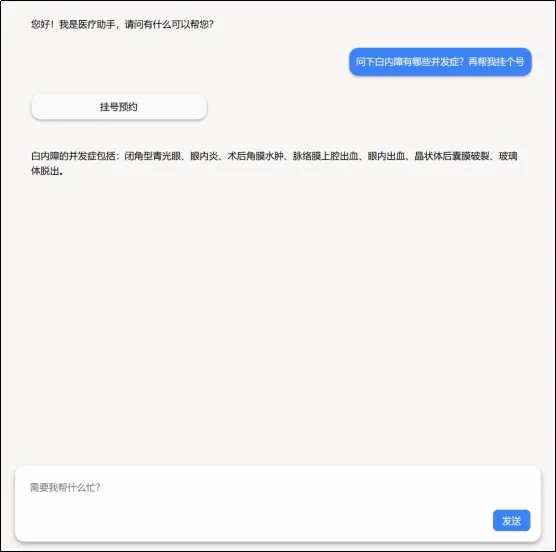
🎯 总结
通过本文的学习,我们完成了整个智医助手的构建:
-
✅ 知识图谱构建:从数据清洗到导入Neo4j
-
✅ 实体对齐:构建同义词映射和向量索引
-
✅ 对话处理流程:意图识别、实体抽取、大模型回复
-
✅ Web服务部署:使用FastAPI构建Web服务
这是一个完整的智能医疗问答系统,它可以:
-
理解用户的自然语言查询
-
从知识图谱中获取相关信息
-
生成准确的回答
-
提供良好的用户体验
💡 互动环节
思考问题:
-
你觉得这个智医助手还可以增加哪些功能?
-
在实际应用中,如何保证医疗信息的准确性和时效性?
欢迎在评论区分享你的想法和经验!
🌟 系列教程回顾
《AI大模型项目实战之智医助手》系列教程:
-
上篇:项目架构与知识图谱设计
-
中篇:模型训练与实体抽取
-
下篇:知识图谱构建与Web服务部署(本文)
通过这三部分的学习,你已经掌握了完整的智能医疗问答系统构建流程。希望这些内容对你有所帮助!
🎁 福利时间
为了方便大家学习,我整理了本文涉及的所有代码和资料,包括:
-
完整的项目代码
-
知识图谱数据
-
预训练模型下载链接
-
部署教程
获取方式:关注公众号,回复”智医助手”获取下载链接
如果本文对你有帮助,记得点赞、在看、分享三连哦!关注公众号开源创富指南,第一时间解锁更多技术实战教程!
创作不易,感谢您的支持,祝您技术进阶,事业有成! 🎉