当前时间: 2026-04-22 01:31:29
更新时间: 2026-04-22
分类:软件教程
评论(0)
我们一直在驯AI,却没想到驯的方式错了
去年我在做一个AI陪伴产品,架构用的是LangGraph多Agent,记忆模块接的Pinecone向量数据库,标准的RAG检索增强方案。用户说话,系统检索相关记忆,然后把召回内容塞进上下文,再让模型生成回复。
但有一次我在自测的时候,说了一句很普通的话,结果角色的回复风格突然变了。那个角色设定是温柔细腻的,但那条回复听起来像换了个人,语气疏离,答非所问,和前几轮的对话完全脱节。
我当时的第一反应是:提示词写得不够好,去改系统提示词。
改了一版,好一点,但偶尔还会出问题。又改了一版,新的边界情况被覆盖了,但之前修好的地方又开始出毛病。
这种感觉很奇怪——就像在打地鼠,按下这个,那个又冒出来。
折腾了好几轮之后,我才慢慢意识到,问题根本不在提示词本身。是RAG召回的内容和角色人格设定之间产生了”信息污染”——一段看起来语义相关但场景完全错位的记忆片段被塞进了上下文,模型读完之后就跑偏了。
然后我尝试在系统提示里加”无论召回到什么内容,你始终保持XX性格”这样的锚定指令,加了优先级声明,加了对召回内容使用方式的限制。
因为问题发生在提示词起作用之前——召回层把错误的内容送进来了,模型在推理时已经把那段信息纳入上下文,提示词里写再多”保持角色一致”,也很难让它完全无视已经读进去的东西。
真正要解决,要在召回层动手:加元数据过滤,调相似度阈值,在召回结果进入提示词之前加一层中间处理,格式化或过滤掉风险内容。
但那时候我没有这套认知框架,只知道提示词调优,所以走了很多弯路。
这个经历让我一直有一个困惑:为什么同一个模型、同一套代码,换一个用户输入,行为就不稳定了?明明调好了,但隔几天又出问题,像在跟它打游击。
这个困惑,在2026年2月之后有了一个清晰的答案。
那时候业界突然开始流传一个词:Harness Engineering,中文叫”驾驭工程”。
最早命名这个概念的是HashiCorp联合创始人Mitchell Hashimoto。他在2026年2月5日的一篇博客里写下了这个定义,六天后OpenAI发布了一份百万行代码的实验报告,正式使用了这个术语。随后工程师Martin Fowler写文深度分析,一个月内,Harness Engineering从一篇博客文章变成了AI工程圈的高频词。
但我第一次看到这个词的时候,以为又是在造概念、搞营销。
LangChain在Terminal Bench 2.0基准测试上做了一个对照实验。
同一个模型,什么都没改,没有微调,没有换更强的版本,只是优化了模型运行的”外部环境”——文档结构、验证回路、追踪系统这些东西。
结果:Agent得分从52.8%飙到66.5%,排名从全球第30名之外直接跳进了前5。
还有一个更极端的案例,来自安全研究员Can Boluk。他只改了Agent的代码编辑格式——从传统的patch格式改成一种带哈希锚点的新格式。结果某个模型的基准得分从6.7%跳到68.3%。
两组数据说明同一件事:决定AI Agent表现上限的,不是模型本身,而是模型运行的环境。
这句话听起来很反直觉,因为过去三年我们所有的注意力都放在模型上——哪个更强,哪个更便宜,哪个更快。我们在模型选型上花了大量时间,但对”模型跑在什么样的环境里”几乎没有系统性思考过。
这就是Harness Engineering想解决的问题。
要理解Harness Engineering,得先理解它和提示词工程、上下文工程的关系。这三个概念经常被混用,但它们其实是三个不同层次的东西。
第一阶段:提示词工程(Prompt Engineering)
这个阶段的模型能力还在成长期,输出质量高度依赖你怎么写指令。Few-shot示例、Chain of Thought、角色设定——工程师花大量时间打磨提示词,因为同一个问题措辞不同,输出差距可以很悬殊。
第二阶段:上下文工程(Context Engineering)
随着模型能力提升,单条提示词的影响力下降了,但”上下文窗口里装的是什么”开始变得关键。RAG检索、记忆管理、多轮对话历史的组织方式——这一阶段的焦点从”怎么说”转移到了”给什么”。
第三阶段:驾驭工程(Harness Engineering)
当Agent开始在真实场景中自主运行——多步任务、长时间执行、并发调用——光靠调整说话方式和信息内容已经不够了。真正的挑战变成了:Agent出错怎么兜底?上下文膨胀了怎么处理?工具调用失控了怎么拦截?执行过程出问题了能不能回放追溯?
用Mitchell Hashimoto的原话说:每当Agent犯了一个错误,你要做的不是换一个模型,而是重新设计它运行的环境,让它永远不再犯同样的错误。
Harness,这个词原来是马具的意思——缰绳、马鞍、嚼子。这套装备的目的不是削弱马的能力,而是给强壮但不可预测的动物套上一套引导系统,让它跑得又快又稳。
Harness Engineering的逻辑是一样的:不是让AI变弱,是给它搭一个可控的脚手架。
用一个公式来理解:Agent = Model + Harness
Model是引擎,Harness是围绕引擎建起来的整辆车。没有人能只靠引擎赢得比赛。
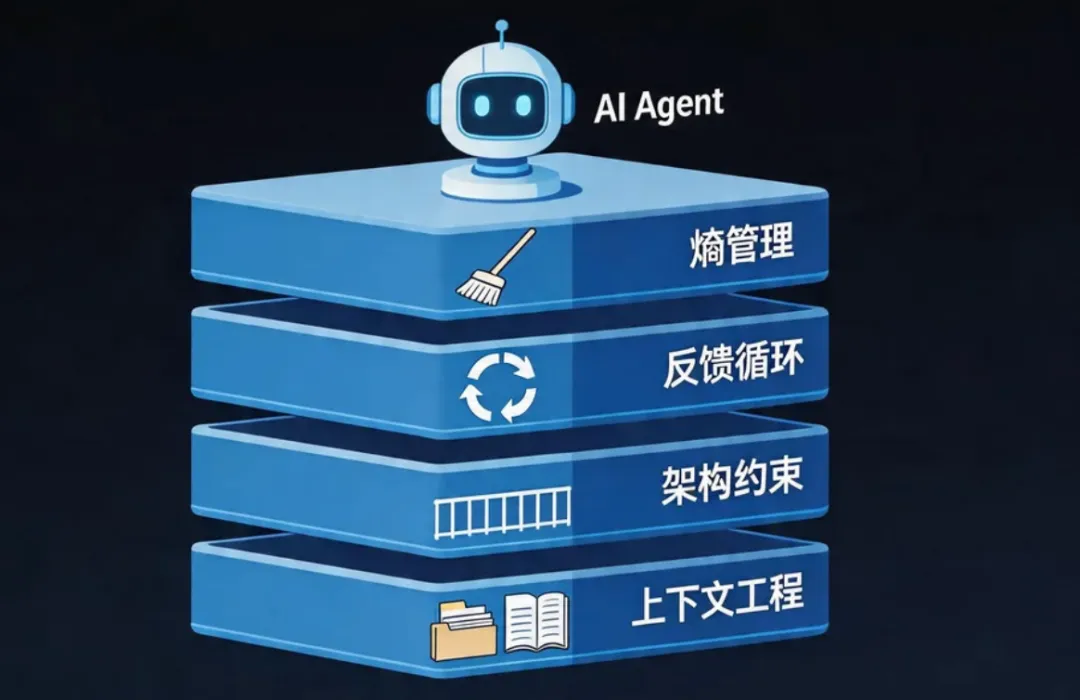
Harness具体包含什么?综合OpenAI、Anthropic、LangChain等团队的实践,大致可以归纳成四个层面。
第一层:上下文工程(Context Engineering)
这是Harness的基础层,也是最多人接触过的部分,但真正做好的人不多。
核心不是”给Agent一份文档”,而是建立一套持续更新的知识管理体系。OpenAI团队在内部用AGENTS.md文件做这件事——它不是一本静态的说明书,而是一个活的反馈循环文档。每次Agent失败,就往里面更新一条规则。Hashimoto的Ghostty项目里,AGENTS.md的每一行都对应一个历史失败案例。
有一个反直觉的发现:这个文件不能写太长。OpenAI发现,把所有指令堆在一起,超过60行之后Agent反而开始失去焦点,那份文档会变成”陈旧规则的坟场”。更好的做法是保持入口精简,然后教Agent根据当前任务按需检索更多上下文。
回到我之前在Dify里踩的那个坑,RAG召回导致人格崩塌的问题,本质上就是上下文工程没做到位——需要加元数据过滤限制召回场景,调整相似度阈值宁缺毋滥,并在召回内容进入提示词之前加一层格式化处理,把信息的”干净程度”管控起来。这些事情在提示词层面是做不了的,必须在更上游的位置动手。
第二层:架构约束(Architecture Constraints)
核心思路是:不要相信Agent的自律,要用机制强制它走正确的路。
OpenAI团队建立了严格的层级依赖模型:Types → Config → Repo → Service → Runtime → UI,Agent不能跨层调用。这不是写在提示词里的”请你不要这么做”,而是从系统架构层面让越界行为根本无法发生。
另一个重要机制是自定义Linter。这里有个关键细节:Linter的错误信息本身也是上下文工程。它不只告诉Agent”你违反了规则X”,而是解释”为什么这个规则存在,正确做法是什么”,这样Agent读到错误之后可以自我理解并修正,不需要人类介入。
矛盾的是,约束越清晰,Agent反而跑得越快。当Agent可以生成任何东西时,它会浪费大量token探索死胡同。当Harness定义了清晰边界,它能更快收敛到正确答案。
核心是把”出了问题再去查”变成”设计时就把可观测性当成一等公民”。
传统程序有可重入性:同样的输入加同样的上下文,等于确定的输出。但大模型的不确定性是本质属性,不是bug,是特性。Harness不承诺消除不确定性,它承诺的是:整个执行链路是可见的、可回放的,出了偏差能快速定位。
OpenAI在内部做”Agent对Agent”的代码审查——Codex在本地审核自身更改,在失败时带着错误信息循环回模型,反复迭代直到通过。如果AI写的测试用例”通过”了带有Bug的代码,Harness会判定测试无效,强迫它重新思考测试边界。
第四层:熵管理(EntropyManagement)
AI生成的代码库或内容系统,会随时间积累越来越多的混乱——文档与现实脱节、命名约定分歧、死代码堆积、知识库里有相互矛盾的信息。这是熵增,是自然趋势,阻止不了,但可以管理。
Claude Code有一个机制被形象地称为”晚上做梦”:后台进程在不活跃时自动激活,对历史信息进行整理——去重、丢弃过时的、合并相关的——把短期记忆转化为长期记忆。OpenAI把熵管理称为”垃圾回收”,像处理高息贷款一样持续小额偿还,而不是等债务堆满了再集中处理。
一个让人清醒的结果:3个人,5个月,100万行代码
OpenAI做过一个实验,3名工程师用5个月时间产出了一个百万行规模的代码库,没有一行是手动编写的,平均每人每天合并3.5个PR。
这不是模型有多强的问题——他们用的模型并不是那个时期最强的。是因为他们花了大量时间构建和打磨Harness,让Agent能在有护栏的环境里稳定、高速地自主运行。
这个结果给行业释放了一个信号:AI工程的竞争焦点正在发生转移。
过去大家拼模型能力,拼谁用了更好的底层大模型,拼提示词写得更聪明。但现在越来越清晰——模型能力的提升是共享的,所有人都能用到最新的模型。真正拉开差距的,是你围绕模型建了一个什么样的运行环境。
就像业界开始流传的一句话:”如果说2025年是AI Agent证明它们可以做事的一年,那么2026年就是我们认识到难点不在Agent本身、而在Harness的一年。”
说到这里,我想直接说一些对PM这个角色而言具体的东西,不停在概念层面。
Harness Engineering是从工程圈子里冒出来的概念,最初的受众是开发者。但它对PM的影响其实更深——因为PM是那个决定”这个产品该如何运作”的人,而Harness正是在解决”产品如何稳定运作”的问题。
如果你现在在做AI产品,不管是to C的智能助手、AI陪伴,还是to B的自动化流程,有几件事值得认真想一想。
很多AI产品团队有一种习惯:产品出问题了,第一反应是改提示词。改完提了个需求,下个迭代再改一版,再下个迭代又改回来。
这种循环不是没价值,但如果你的团队80%的调优时间都花在提示词上,而几乎没有人在看召回层、工具调用层、上下文组织层,那大概率你们在用第一代方法解决第三代问题。
Harness Engineering给出的思路是:每次Agent出错,先不急着改提示词,先问一个问题——这个错误是”说话方式”的问题,还是”运行环境”的问题?大多数情况下,是后者。
第二件事:把”可观测性”纳入产品设计而不是事后补救
我见过很多AI产品,上线之后才开始想”怎么知道Agent是不是跑对了”。这时候再做监控、做日志、做回放,成本很高,而且很多关键信息已经丢失了。
更好的做法是在产品设计阶段就把可观测性作为一等公民来对待:Agent的每一步推理是否可追踪?工具调用的输入输出是否有记录?出现异常时能否快速定位到是哪个节点出了问题?
Hashimoto的AGENTS.md给了我很大启发。那个文档里每一行规则,背后都是一个真实的Agent失败案例。
对AI产品团队来说,可以做一个类似的东西——不一定叫这个名字,但逻辑是一样的:把每次产品出现的Agent行为异常,以结构化的方式记录下来,分析根因,更新到约束规则里。
这个文档不是一次性写好的,它是随着产品跑起来之后被用户和测试喂出来的。它活着,就意味着你的产品在持续变得更可控。
以前评估一个AI功能好不好,我们习惯看单次输出质量——这个回复好不好,那个生成结果准不准。
但随着Agent开始承担更复杂的任务,单次质量已经不够用了。你需要看的是:在100次调用里,有多少次跑偏了?在长对话之后,角色一致性还稳不稳?跨会话的状态延续是否可靠?
这些是”系统级质量”,是Harness要解决的问题,也应该成为PM评估AI产品成熟度的核心指标。
我在开头说那次自测的经历,说提示词调优治标不治本。
但我想补充一点:那段弯路走得不完全是坏事。正是因为在提示词调优上撞了墙,才开始真正去理解上下文组织和召回层的问题,才会在看到Harness Engineering这个词的时候有一种”原来如此”的感觉,而不是”又来了一个新概念”。
但现在有了这个框架,后来者可以少走一段弯路——不用等到角色人格崩塌了才开始想召回层的问题,不用等到Agent在线上跑偏了才开始想反馈循环的设计。
Harness Engineering的核心哲学是:Agent犯错不可怕,可怕的是让它在同一个地方再犯一次。
这对工程师是一种约束设计的方法论,对产品经理来说,我觉得更像是一种产品成熟度的思维方式——从”让AI跑起来”,到”让AI稳定地跑起来”,再到”让AI在出错之后越跑越好”。
 夜雨聆风
夜雨聆风