 夜雨聆风
夜雨聆风





AI绘图为什么总拉胯?模型学家终于说了真话
你有过这种经历吗——照着网上的教程写 Prompt,效果却和人家天差地别。”梵高风格”用了没效果,”电影感”写了像废片,调权重 :1.2 还是 :0.8 全凭蒙。
这不是玄学。问题出在你不理解模型是怎么”学会”画图的。
prompt 写得烂,不是因为你不够有创意,而是因为你不知道模型见过什么、是怎么理解的。一旦你知道训练数据长什么样、模型内部怎么工作,你写 prompt 就会有方向得多——不是玄学试错,而是有的放矢。
这篇文章分两部分:第一,模型是怎么训练的(原理);第二,从原理推导出的 Prompt 写法。学完你就知道为什么那些技巧有效,以及什么时候该另辟蹊径。
第一部分:模型是怎么学会画图的
1.1 先搞清楚:AI 不是在”画”,是在”回忆”
AI 生成图片,不是真的在画——它在做模式匹配和重组。
用一个类比来理解:你看过十万张猫的照片,让你闭眼画一只猫,你画出来的是”你记忆里猫的抽象”。你没见过外星猫,你也就画不出外星猫。你记忆里暖色光下的猫多,冷光下的猫少,所以让你画”黄昏的猫”,你大概率会画得比”夜晚的猫”更好。
扩散模型(Diffusion Model)也是这个逻辑。它生成的东西,本质上是它见过的训练数据的”重组”。它不是真的理解”什么是猫”,而是从海量图文对里学到了”在某些文字描述条件下,应该输出什么样的像素分布”。
所以——训练数据决定了这个模型的”记忆库”,决定了它能生成什么、不能生成什么。下一节重点讲训练数据是怎么来的。
1.2 训练数据:从哪来,怎么构造
模型能生成图片,前提是它见过”图片+文字描述”这样的配对样本。这叫图文对(image-text pair)。
1.2.1 数据从哪来
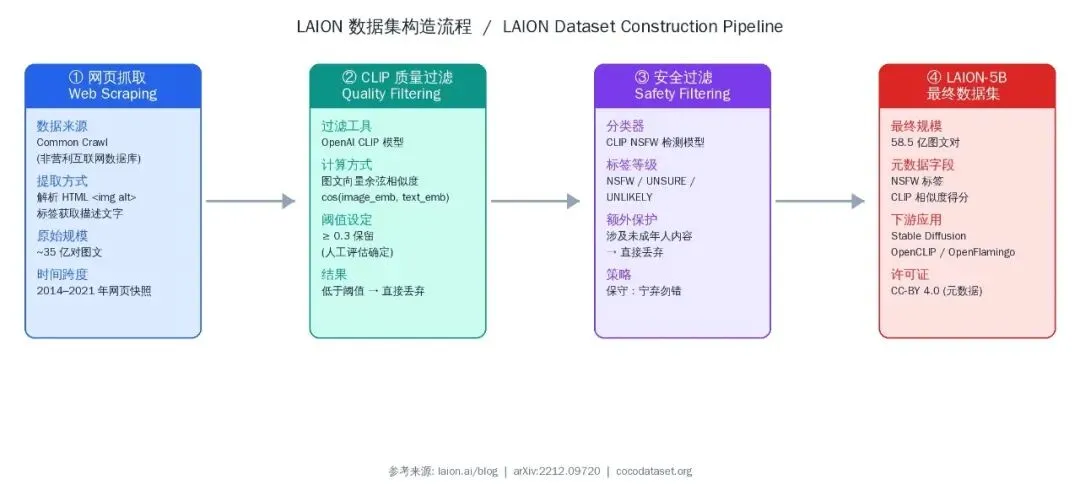
LAION-5B(开源标杆)
这是目前规模最大的开源图文数据集,共 58.5 亿个图文对,Stable Diffusion 用的就是它。
数据来源:Common Crawl——一个非营利组织定期抓取的互联网网页快照。LAION 从中解析 HTML 里的 <img alt="..."> 标签,把 alt 文字当作图片的描述。就这样从 2014 到 2021 年的数据里捞出了几十亿对原始图文。
COCO(人工标注精品)
微软出品,规模小但质量高。COCO 的图片描述不是从网页 alt 文字来的,而是真人在 Amazon Mechanical Turk 众包平台上写的。每张图有 5 个不同的描述,来自 5 个不同的人,所以同一张图可以有多种视角的表达方式——这个设计让它特别适合训练”理解多样描述”的模型。
闭源模型自有数据
Midjourney 和 DALL-E 的训练数据规模和质量不公开,但可以确定是自建的,这是它们的核心护城河。所以它们的 prompt 技巧可以学,但原理你永远无法验证——你不知道它们到底见过什么样的图文配对。
1.2.2 文字描述是怎么来的(标注方式)
这是最关键的问题——图片旁边的文字描述是怎么写上去的?
方式一:从网页 alt 属性提取(LAION)
LAION 的原始文字描述来自网页 <img alt="..."> 标签。这些文字本来是给盲人用户看的网页替代文本,写法随意,有的非常详细,有的只有一个词。
举例:alt="photo of a cat"、alt="IMG_1947"、alt="下载"——质量参差不齐,有大量截断的网页文字、截图文件名、表情符号。
这种数据质量偏低,自动标注的描述本质上是”图片说明文”,缺乏艺术性。LAION 后来用 CLIP 做了一次过滤:只有图文相似度 ≥ 0.3 的样本才保留,这个阈值是经过人工评估确定的。
方式二:人工标注(COCO)
每张图找 5 个人类标注者独立看图写描述,要求描述完整句子,至少包含图片的主要物体和场景。结果:同一张图,5 个描述角度不同、详略不同、关注点不同。
举例:一张主人给狗扔球的图:
-
描述1:”A man throwing a ball for a dog to catch” -
描述2:”Golden retriever jumping to catch tennis ball in park” -
描述3:”Outdoor scene with person and dog playing fetch”
这就是 COCO 数据质量高的原因——描述丰富、角度多样、语法正确。缺点是人工成本极高,不可能大规模扩展。
方式三:AI 生成 + 扩写(BLIP + LLM)
2022 年,LAION 团队用 BLIP 模型给 LAION-2B 的 6 亿张图生成了新描述,再用 LLM 扩写成更丰富的句子,效果接近人工标注质量。
过程:
-
BLIP captioner 生成基础描述: BLIP: "A cat on a table" -
LLM 扩写:把短描述扩成长描述: "A fluffy orange tabby cat with green eyes lounging lazily on a weathered wooden table, afternoon sunlight casting soft shadows"
这就是 LAION-COCO(6 亿对),是世界上最大的合成图文对数据集。真正做到了”用 AI 批量化生产接近人工质量的描述”。
三种标注方式总结:
| 标注方式 | 代表数据集 | 描述质量 | 可规模化 | 举例 |
|---|---|---|---|---|
| 网页 alt 提取 | LAION-5B(原始) | 低 | 极高 | “IMG_1947” |
| 人工众包标注 | COCO | 高 | 低(成本高) | “5个人各自写的完整句子” |
| AI 生成 + 扩写 | LAION-COCO(BLIP 生成) | 中高 | 高 | BLIP生成基础句 → LLM扩写成艺术描述 |
为什么这个很重要——你往模型里写 prompt,模型能识别的词汇和描述方式,取决于它训练时见过什么样的图文配对。LAION 的 alt 文字描述质量差,所以在这个数据上训出来的 CLIP 早期版本,对艺术化描述的识别能力很弱;Midjourney 自有数据质量高,所以 Midjourney 对”cinematic lighting””film still”这类描述反应更好。
原始数据不能直接用,还需要清洗:
分辨率过滤:低于一定像素的图片丢弃。太小的图信息量不足,模型学不到细节。
美学评分:用 CLIP 模型对图片做美学打分,过滤低分图片。LAION 里有很多截图、meme、表情包,这些被过滤掉后,剩下的才是”看起来像正经摄影/绘画”的图。
NSFW 过滤:自动过滤成人内容。
去重:相似图片只保留一张,避免模型对某些样本过拟合。
清洗后,LAION-5B 里真正用于训练 Stable Diffusion 的是筛选后的几亿对数据,质量远高于原始数据集。
1.3 模型在训练时到底学了什么
1.3.1 两阶段训练:以 Diffusion Model 为例
Diffusion 模型(Stable Diffusion、DALL-E 2、Midjourney 底层都是这个)是目前文生图的主流架构。它的训练分两个阶段,用类比来理解:
阶段一:学”破坏”(Forward Process)
给一张真实图片,逐步加噪声,直到变成纯噪声。这个过程模型全程”观察”。
类比:一个人看过无数东西从”有序”变”混乱”的过程,他就渐渐了解了”混乱”长什么样——噪声的统计规律、像素随机分布的模式。
阶段二:学”恢复”(Reverse Process)
模型输入是噪声图,目标是还原出原始图片。但这里有个关键:在去噪的每一步,模型都要参考文字描述,来决定像素应该往哪个方向调整。
这就是”文字条件引导”(Text Conditioning)——没有文字条件,模型只会生成一张”随机但看起来像真实图片”的图;加上文字条件,模型才能生成你想要的内容。
类比:还是那个学过”混乱规律”的人,现在你给他一堆乱码的像素,告诉他”帮我画一只猫”,他就能在混乱中一步步还原出一只猫——因为他在”恢复”的时候,有”猫”这个概念作为方向指引。
1.3.2 文字和图片是怎么”对齐”的
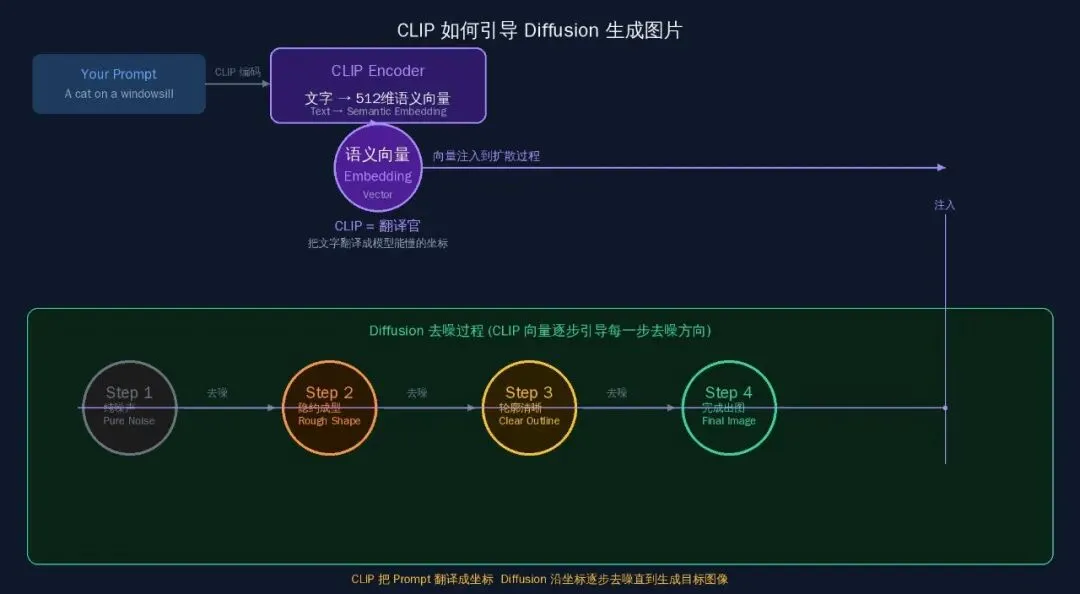
关键角色是 CLIP(Contrastive Language-Image Pre-training)。
CLIP 的训练方式:给它看海量的图文对,让它学会”判断这张图和这段文字是不是一对”。训练完成后,CLIP 学会了:一段文字和一张图片,在”语义空间”里是同一个点。
生图时,用户的 Prompt 先被 CLIP 编码成一个向量(即”语义坐标”),然后这个向量在 Diffusion 的去噪过程中持续注入,引导每一步去噪往对应方向走。
简单理解:CLIP 是翻译官,把你的文字翻译成模型能理解的”视觉坐标”,然后 Diffusion 沿着这个坐标走到目标位置。
1.3.3 模型学到了什么,没学到什么
模型学到的:
-
风格模式:梵高的笔触、赛博朋克的光影、浮世绘的配色——因为训练数据里大量这类图文对 -
对象概念:猫、狗、建筑、自然景观——常见对象,训练充分 -
场景组合:室内、室外、城市、自然——常见场景描述 -
光照氛围:逆光、柔光、戏剧光——视觉特征明显,描述充分
模型学不好的:
-
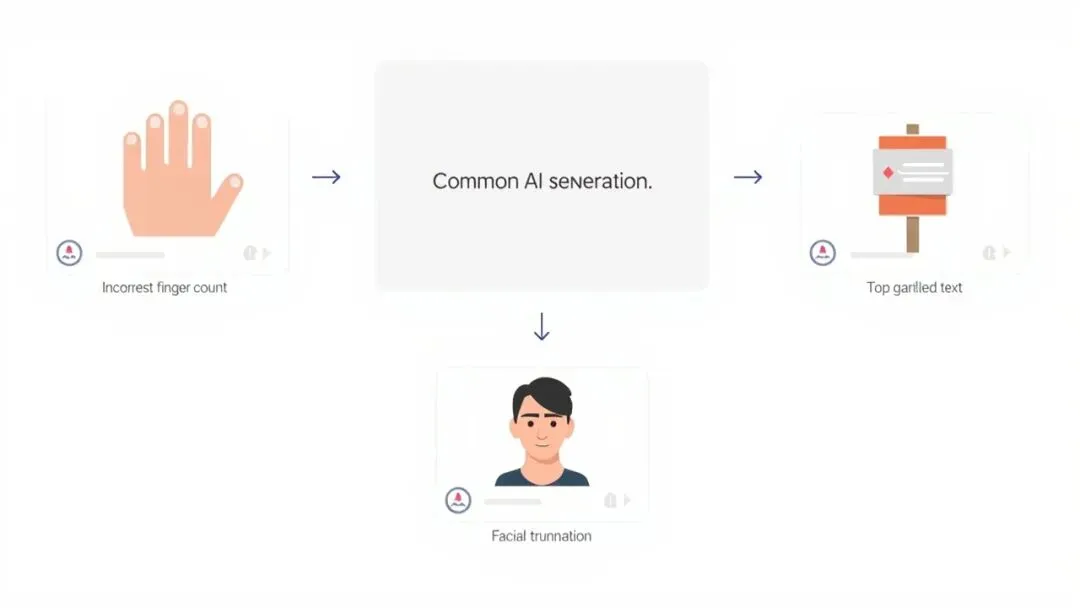
文字渲染(在图片里写字):训练数据里带文字的图片少之又少 -
手指数量:人手的图像样本多,但”多指/少指”的样本极少,模型对这个特征不敏感 -
空间关系:左右、上下、前后——文字描述里这类关系词少,模型靠猜 -
物理规律:水往低处流、影子方向和光源方向一致——模型不懂物理,只学”看起来对”
1.4 从原理看模型的三大局限
知道模型怎么训练的,就能理解为什么它总是出某些特定的错误。
局限一:手指和文字经常出错
训练数据里,手的图像多,但”六指””缺指”的图几乎没有。模型学的是”大多数手长这样”,遇到极端情况就崩。图片中的文字同理——整个互联网的图片里,带清晰可辨认文字的图占比极低,模型根本没机会学好。
局限二:组合复杂概念容易崩
Cross-Attention(文字引导去噪的机制)对每个词分配注意力权重。当你的 Prompt 包含太多概念(”一只猫 + 戴帽子 + 在月球 + 背景有教堂”),每个概念分到的注意力就少,模型就顾此失彼。
解决思路:减少同屏概念数量,或者把多个概念合并成一个更简洁的描述。
局限三:物理空间错乱
模型不懂物理,它只知道”在大量图片里,’天空’通常在图片上部,’地面’通常在下部”。当你让模型画”水中倒影”,它经常分不清倒影和实物谁在上、谁在下。CLIP 只学过判断图文匹配,不学过物理关系。
实际案例:手指问题
手指是扩散模型最经典的统计偏差之一。我在同条件下让模型生成手部特写:

Prompt:a close-up portrait of a woman's hand with long fingernails, soft natural lighting, detailed skin texture
这张图整体质量不错,但如果你仔细数手指,会发现——手指数量并不总是准确的。这就是训练数据里”正常手”的图片极多、”六指/缺指”的图片几乎没有,导致模型学不到这个变体特征。
这也印证了前面的原理:模型学的是统计规律,不是语义规则。模型不知道”正常人手有5根指头”,只知道”在大量手部图像里,通常出现X根手指”。
第二部分:从原理推导 Prompt 写法
2.1 为什么风格词和艺术家名有效
你写”in the style of Van Gogh”,模型就能生成梵高风格的图——这不是魔法。
原因:训练数据里,有大量”Van Gogh + 梵高作品”的图文对。梵高的笔触(粗犷的短线条、漩涡状的天空、厚重的色块)反复和”Van Gogh”这个词一起出现。CLIP 在训练时,把”Van Gogh”这个词和这些视觉特征牢牢绑定了。
当你使用艺术家名时,直接激活了模型记忆里对应的视觉模式。
同理有效的词:
-
媒介词:oil painting、watercolor、digital art、ink wash painting -
风格词:cyberpunk、art deco、impressionist、minimalist -
摄影师名:Annie Leibovitz(人像)、Ansel Adams(风光)
注意:艺术家名对 Midjourney 这类模型效果最明显,因为它们的数据里艺术相关内容占比高。对 Stable Diffusion 开源模型来说,艺术家名也有效,但部分小众艺术家模型可能不认识(训练数据里没有)。
实际对比:
我用同一张底稿,分别生成「无风格」和「Van Gogh 风格」:
| 无风格(写实摄影) | Van Gogh 风格 |
|---|---|
 |
 |
Prompt对比:
-
无风格版: a cat sitting on a wooden windowsill, warm afternoon light, realistic photography -
Van Gogh版:相同主体 + in the style of Van Gogh, thick brushstrokes, swirling patterns, vivid colors
同一条猫+窗户的底稿,加了艺术家名,笔触、配色、质感全部改变——这正是 CLIP 在训练时建立了”Van Gogh ↔ 漩涡笔触/厚重色块”的强关联。
2.2 为什么描述越具体越好
先看一个对比:
模糊 Prompt:
a sunset
具体 Prompt:
a dramatic sunset over coastal cliffs with pink and purple clouds,
golden light rays breaking through scattered clouds, seagulls in
the distance, lush green grass in foreground, warm-to-cool color
gradient, cinematic composition, 8k photography
模糊 Prompt 生成的是”记忆里最常见的日落”。具体 Prompt 提供了更多可匹配的视觉特征,模型在生成时会同时满足所有条件——暖色渐变、礁石、海鸟、草地——这些细节锁定了你想要的具体画面。
模糊版 a sunset |
具体版(完整描述) |
|---|---|
 |
 |
Prompt对比:
-
模糊版: a sunset -
具体版: a dramatic sunset over coastal cliffs with pink and purple clouds, golden light rays breaking through scattered clouds, seagulls in the distance, lush green grass in foreground, warm-to-cool color gradient, cinematic composition
模糊版就是”记忆里最通用的日落印象”——没有礁石、没有海鸟、没有草地,模型根据训练数据里最常见的日落统计特征自由发挥。具体版锁定了7个视觉条件(海岸峭壁/紫粉色云/金光穿透/海鸟/草地/暖冷渐变/电影构图),每个条件都是一次额外的像素方向约束,最终画面因此稳定在你想要的结果附近。

原理:Diffusion 的 Cross-Attention 对每个描述词分配注意力。具体描述的词更多,每个词的权重虽然会被稀释,但如果描述之间存在协同关系(如”暖光+金色草+黄昏色温”互相印证),整体效果反而更稳定。
2.3 为什么加权重(prompt:a:1.2)有效
这也是模型的内在机制,不是玄学。
在 Diffusion 的去噪过程中,每一步都会参考文字条件。文字向量里的每个概念(词或词组)会对应一个注意力权重,这个权重决定了模型”多在乎”这个概念对应的视觉特征。
写 cat:1.2 的意思是:把”cat”这个概念的权重提高 20%,模型就会在去噪的每一步更多地考虑”猫”这个视觉特征。
适用场景:
-
某个主体在生成结果里被弱化了 → 提高它的权重 -
某个风格不够明显 → 提高风格词的权重
注意:权重太高(超过 1.5)会让画面失衡——猫变成画面主体,其他元素被压缩,甚至出现局部过曝、噪点增多。
实际对比(来自同一基础 Prompt):
| 权重 1.0(正常) | 权重 1.5(整体增强) |
|---|---|
 |
 |
-
基础版: a cat and a dog sitting together on a couch, living room setting, warm lighting -
增强版:相同内容,外层整体权重加到 :1.5
权重 1.5 时,沙发、猫狗、暖光所有元素同步增强——这说明权重影响的是 Diffusion 去噪全程的注意力分配基准,不是针对某一个词。
2.4 为什么有些概念模型不认识
因为你描述的概念,在它训练时没见过——或者说,训练数据里这类样本太少。
两种情况:
情况一:新品类、亚文化概念
举例:”Y2K 风格””Brat 绿””多巴胺穿搭”——这些是 2023 年以后才火起来的概念,训练数据截止到 2023 年的模型就不认识。
解决思路:用模型认识的已知概念来描述你想要的风格。Y2K 可以拆解为”高饱和度、塑料质感、浅蓝粉色、字体带反光、1990 年代未来感”。
实际案例:
| 直接写”Y2K 风格” | 用已知描述替代 |
|---|---|
 |
拆解成具体视觉元素:霓虹粉+塑料质感+浅蓝+反光字体 |
左图是我直接写 Y2K aesthetic 生成的结果——模型虽然能跑出来,但如果你对 Y2K 有明确印象,会发现这张图并不是你想象中的样子。根本原因:CLIP 训练时没见过”Y2K aesthetic”这个图文对,模型只能通过相似词汇做间接匹配,效果不稳定。
情况二:纯个人想象,没有对应的视觉参考
举例:”赛博朋克风格的中国龙”——模型认识”赛博朋克”和”中国龙”,但这两个概念的组合在训练数据里极少,模型会顾此失彼。
实际案例:
| 赛博朋克 × 中国龙(罕见组合) |
|---|
 |
Prompt:a Chinese dragon with long serpentine body and antlers, cyberpunk neon city background with rain and neon reflections, glowing red and gold scales
龙和赛博朋克各自单独出现都很稳,但组合在一起时,模型需要在”龙的姿态”和”赛博朋克的霓虹质感”之间找到平衡——结果往往是龙的身形被霓虹背景削弱,或者龙的风格偏向写实而非赛博朋克。这不是模型能力问题,是训练数据里这类图文配对太少了。
解决思路:明确指定哪个是主体、哪个是风格背景。用权重来区分主次。
2.5 为什么图片示例(图生图)比纯文字更准
因为图文匹配比纯文字更确定。
当你上传一张参考图,模型不只是”理解”这张图,而是直接”看到了”具体的像素布局、色彩分布、构图方式。它不需要猜测”你说的暖色调是什么”,而是直接参考你图里的具体色调。
纯文字 prompt 再怎么写,都有”理解误差”——模型对”电影感”的理解,可能和你想要的不一样。但参考图直接消灭了这个误差。
这就是 IP-Adapter、StyleLoRA、Reference Image 等功能的意义——图片是比文字更精确的沟通语言。
实际案例:同一 Prompt,两次生成,差异明显
| 参考图(你想要的效果) | 纯文字 Prompt 生成 v1 | 纯文字 Prompt 生成 v2 |
|---|---|---|
 |
 |
 |
三次生成用的是完全相同的文字 Prompt:
a young woman sitting at a cozy coffee shop by the window, warm golden light, soft bokeh background, film photography aesthetic, 35mm lens, Canon AE-1
三张图的差异说明:即使是同一个 Prompt,每次生成也是一次独立采样——光线冷暖、构图角度、人物姿态、背景虚化程度,都在”电影感”这个大框架下自由波动。
参考图(第一张)锁定了你想要的具体结果:暖调偏青的色调、窗口逆光、坐姿视线方向、Canon AE-1 的色调风格。这些细节用纯文字几乎不可能精确描述,更无法保证每次生成都一致。这就是图生图的核心价值——消灭理解误差,让模型直接看到你要的结果。
第三部分:Prompt 框架——让描述结构化
有了原理基础,现在把描述框架化,让你的 prompt 有结构、不遗漏。
以下是经过原理验证的图片 Prompt 框架:
| 维度 | 作用 | 写作技巧 | 示例 |
|---|---|---|---|
| 色调 | 决定整体情绪和氛围 | 用具体色系词,不用模糊的”好看” | warm orange and pink palette / cool blue tones |
| 主体 | 核心视觉焦点 | 细节越多越可控(颜色、材质、姿态) | a fluffy orange tabby cat with green eyes |
| 风格 | 决定表现形式 | 艺术家名 / 媒介词 / 风格词 | in the style of Van Gogh / digital art |
| 场景 | 背景和环境 | 影响光影和氛围基准 | on a mossy stone wall in an ancient garden |
| 光线 | 塑造质感 | 光源方向 + 光线性质 | soft golden hour light from the left / dramatic rim lighting |
| 构图 | 决定画面布局 | 视角 + 黄金分割 + 留白 | centered composition / rule of thirds / bird’s eye view |

使用示例:
Soft pink and lavender color palette,
a woman in a flowing white dress standing in a wheat field at dusk,
in the style of natural light photography,
vast open meadow with rolling hills in the background,
warm sunset lighting from behind creating a halo effect,
side-angle composition with subject on the right third line,
abundant sky留白占据画面上方三分之二,
cinematic, 8k
这个框架不是死板的模板,而是确保你不遗漏重要维度的检查清单。每个维度不一定要写满,但想过一遍能帮你发现自己是不是漏了关键描述。
总结:从原理到技巧
-
模型是记忆+重组,不是真正的理解——它生成的东西是训练数据里见过的东西的组合 -
训练数据决定能力边界——模型认识什么、不认识什么,取决于它见过什么样的图文对 -
描述要具体,因为越具体匹配特征越多——模糊描述让模型自由发挥,具体描述锁定目标 -
风格词有效是因为训练数据里有对应标注——艺术家名、媒介词激活了特定的视觉记忆 -
权重调节是干预 Cross-Attention 注意力分配——有内在原理,不是玄学调参 -
模型局限(手指、文字、空间)来自训练数据的统计偏差——知道这个就不会浪费时间用 prompt 硬解
理解原理不是为了背知识,而是为了在面对新模型、新场景时,能自己判断该怎么写 prompt——而不是永远跟在别人后面抄作业。
你有什么反复踩坑的例子,欢迎在评论区说,我们下一期可以专门讲特定场景的针对性解决方案。