 夜雨聆风
夜雨聆风





AI时代需要什么样的CPU?CPU的时代机遇
过去市场一直不相信Intel的业绩,这次是实打实看到缺货导致CPU供不应求,而且确实传导到价格上了。这种供需反转体现在股价上的爆发力会非常恐怖。周五资金几乎是FOMO抢筹,但实际上对CPU的需求没有深入的认知。
一、CPU已经成为现代AI数据中心的瓶颈
二、Nvdia Grace问世,重新定义AI CPU
三、AMD EPYC在8卡机市场的统治
四、ARM CPU历史性的机遇
五、到底需要多少CPU?从1:8到8:1
全文4000字,阅读大约需要10分钟,欢迎各位留言讨论。
一、CPU已经成为现代AI数据中心的瓶颈
2021年Nvdia GTC大会上,老黄首次提出,CPU已经成为现在AI数据中心的瓶颈。

要理解传统x86 CPU在AI数据中心的致命瓶颈,那么必须要理解一个核心概念:通信墙。
传统的通用服务器里面,CPU是整个系统的大脑,负责执行操作系统,运行应用程序,这些都涉及大量的逻辑计算和浮点计算。然而在AI时代,CPU从过去的大脑变成了数据的搬运工。GPU更多地依靠CPU来处理串行任务(例如数据调度、分词、反分词、提示词调度等)。因此CPU更需要的是足够的核心数量来并发运行各种搬运工作,反而单线程性能要求降低了,只要能快速地处理简单任务即可。
很明显传统的x86 CPU已经不能满足新的需求,一场关于AI CPU的深刻革命正在悄然发生。
二、Nvdia Grace问世,重新定义AI CPU
Grace CPU的概念在2021年首次提出,但实际上是到了2023年,Grace才真正的问世。Grace Hopper(也就是大家常说的GH200平台),彻底定义了未来AI CPU的形态。
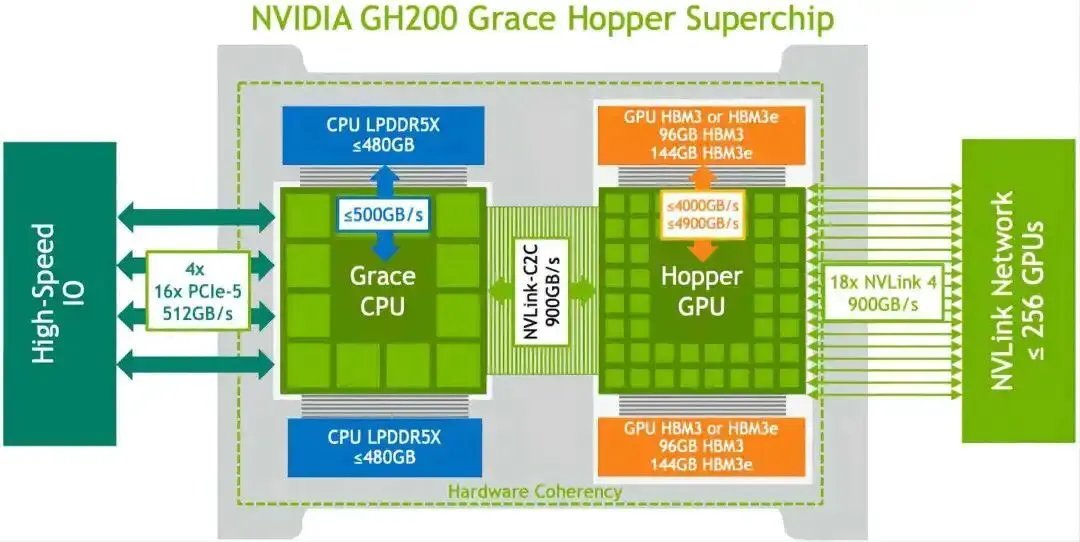
首先是通信墙的问题。得益于Nvdia成熟的NVLink技术,Nvdia直接跳过PCIe这种老弱病残,Grace CPU与Hopper GPU之间通过直接NVLink-C2C互连,能够提供高达900GB/s的双向带宽,是PCIe5.0(64GB/s的双向带宽)的整整7x!
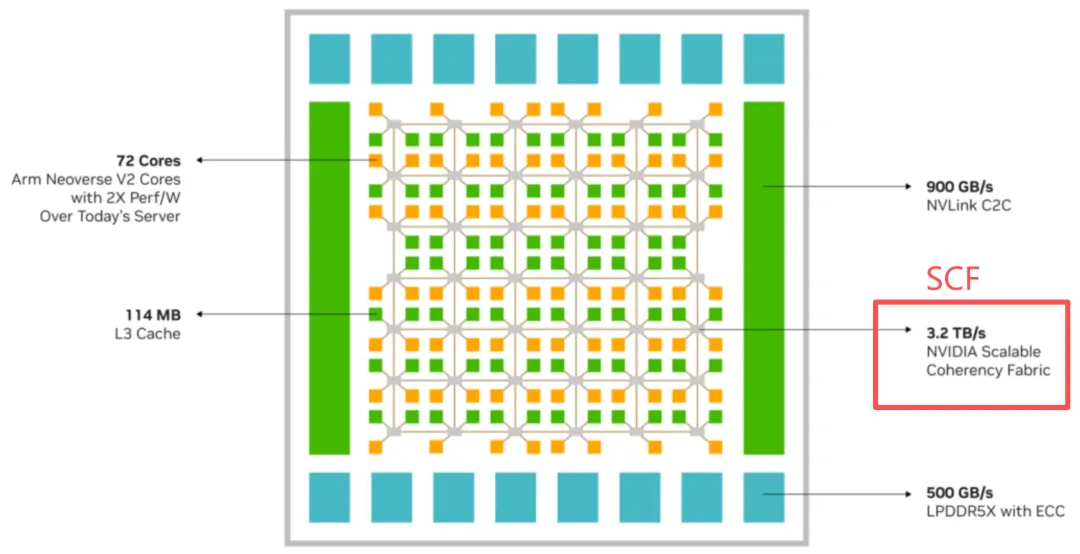
Grace拥有72颗核心,为了保证GPU访问CPU内存时,数据能在CPU内部被快速汇集并传输至NVLink-C2C,NVIDIA为Grace设计了定制的网格缓存架构SCF(Scalable Coherency Fabric)。它能提供高达3.2TB/s的对分带宽,确保分布在芯片各处的核心都能实现高速访问。
Grace CPU和Blackwell GPU在物理和逻辑上共享一个完全一致的统一虚拟内存空间(ATS)。ATS+SCF+NVLink-C2C,使得Grace完美地解决了传统架构中PCIe总线导致的通信墙问题,GH200系统的GPU不仅可以使用自身极快但容量有限的HBM显存,还可以以极高的速度直接访问CPU侧的高容量内存。
另外Nvdia放弃了传统的x86架构,采用了专门针对云计算优化的ARM Neoverse V2核心,单个Grace包含72个核心,这种设计在保持极高单线程性能的同时,也满足了高数据吞吐需求。ARM架构的低功耗优势也不可小觑,Grace CPU在相同的功耗下,能够提供传统领先x86服务器CPU多达两倍的性能。
三、AMD EPYC在8卡机市场的统治
前面已经见过,在典型的8卡服务器中,前端CPU承受着极大的并发压力,需要同时处理海量用户的网络并发连接、文档清洗、分词、连续批处理调度等。这些任务不缺单核绝对性能,但极度缺乏核心数。
为此AMD走上了狂推核心的道路,把chiplet玩到炉火纯青。AMD的Zen4就率先将单路核心数推向了128核,更是在Zen5c里面塞进去了192核。尤其是Zen5c这种小核心设计,牺牲了单核性能,换来极致的并发处理能力,完美契合了AI agent的容器化需求,也非常适合AI推理场景。

AMD为了把这么多CPU Die链接起来,推出了Infinity Fabric高速互联架构,可以实现Die-Die,Core-Core的互联。利用IF的能力,AMD从第四代EPYC开始推广双路系统。每个EPYC处理器最多可提供4条xGMI链路用于CPU间互联,每条链路的带宽等效于PCIe5.0x16,也就是说能够提供512 GB/s的CPU-CPU双向互联带宽,CPU几乎可以像访问自己的内存一样快速访问另一颗CPU的内存。
PCIe5.0的带宽硬伤一时半会儿是改变不了的,但是AMD选择狂堆通道数,单路/双路系统能提供高达128到160条PCIe5.0通道,内存也升级到12通道DDR5。海量的原生通道意味着可以减少对PCIe Switch的依赖,让网卡和存储几乎直连CPU。
AMD EPYC并非原生AI CPU,但是在x86框架下,尽可能地满足了AIDC对CPU的需求。尽管Nvdia极力推崇GB200/GB300 NVL72液冷整机柜,但单个机柜功率需求巨大,且强制要求液冷,只有巨型CSP才有实力采购。实际上更多客户还是选择了HGX方案。这是为什么EPYC双路系统在HGX B300占据着统治级的地位,几乎是各大OEM的主推方案。

不过Intel过去几年也在疯狂补齐短板。
在第三代至强(Ice Lake)时期,Intel的PCIe4.0通道数仅有 64 条,导致Xeon在8卡机系统中非常吃亏,必须依赖复杂的PCIe Switch拓扑。从第四代升级到PCIe5.0和8通道DDR5,再到最新的第六代,Intel已经实现了 136 条PCIe5.0通道,并首发支持了12通道MRDIMM的内存通道。也是从第六代开始,也将产品线拆分为大小核两个产品线,全小核 E-core最高可以干到288核,主攻高并发与能效。
另外值得一提的是,Intel和AMD两个老对头也放弃恩怨,共同推动了CXL联盟的建立。
为了极致的访问速度,Grace的LPDDR5内存是直接焊死在CPU旁边的,然而x86生态不可能彻底放弃PCIe可插拔的扩展性。x86架构为了解决GPU对CPU的内存访问问题,复用了现有的PCIe接口,在其之上建立了一套CXL(缓存一致性)协议。
CXL并不能直接提高GPU-CPU之间的带宽,但实现了两个核心突破:1)允许GPU直接访问CPU内存中的数据,不需要CPU在中间介入,减少对PCIe带宽的占用;2)实现了内存池化,内存不再必须插在 CPU 旁边的插槽里,可以额外扩展,将CXL内存作为大容量后备存储,GPU则可以直接访问池中的大容量CXL内存。
CXL2.0在软件层的支持尚未完全普及,CXL3.0和4.0又提出了更激进的技术蓝图,未来可能成为x86 CPU在AI时代的关键技术基座。
四、ARM CPU历史性的机遇
当单张GPU的功耗超过1000W时,机柜的供电和散热已经成为显著的瓶颈,Nvdia标配的DGX B300总功耗高达14kW,如果上双路EPYC功耗更甚。如果能将CPU的功耗下降一半,就能为GPU腾出极其宝贵的功耗资源,而ARM CPU的低功耗特性恰好满足了这一点。
在传统的云计算时代,x86 CPU是绝对的主力,负责处理所有的复杂逻辑和高并发计算,而AI时代CPU更多只需要起到搬运工的作用,精简指令集的ARM CPU也足够胜任。
AWS是最早探索服务器级ARM CPU的云厂。2018年推出第一代Graviton CPU,这颗CPU是基于较老的Arm Cortex-A72,性能并不突出,主要定位于对成本极度敏感、且对单核性能要求不高的工作负载。
2019年的Graviton 2是真正颠覆行业认知的一代产品。根据AWS自己的测算,Graviton 2在通用计算、Web服务器、内存缓存、视频编码等多种工作负载中,与同规格的第五代x86相比(主要是基于Intel至强铂金处理器),性价比提升最高可达40%!
AWS在Graviton上的成功是巨大的,北美CSP大厂纷纷跟进。微软2023年底推出ARM CPU Azure Cobalt 100,市场反馈极佳。2025年底又紧锣密鼓地发布了Cobalt 200,已经开始用在各类云原生工作负载。
根据AWS CEO在2026年股东信中的披露,截至2026年初,AWS内部超过50%的新增CPU算力是Graviton驱动的。ARM CPU已经充分证明能够稳定、高效地承载企业级核心应用。
2025年底发布的Graviton 5更是成为Agentic AI场景的首选。2026年初,Meta与AWS签署了一项数十亿美元级别的历史性协议,未来将部署数千万颗Graviton 5核心,专门用于支撑其下一代Agentic AI需求。
Google在2024年才正式推出基于ARM的Axion CPU。从第七代TPU开始,Google Axion与自家的Titanium就实现了深度融合,专门用于大规模AI模型的训练及低延迟推理。
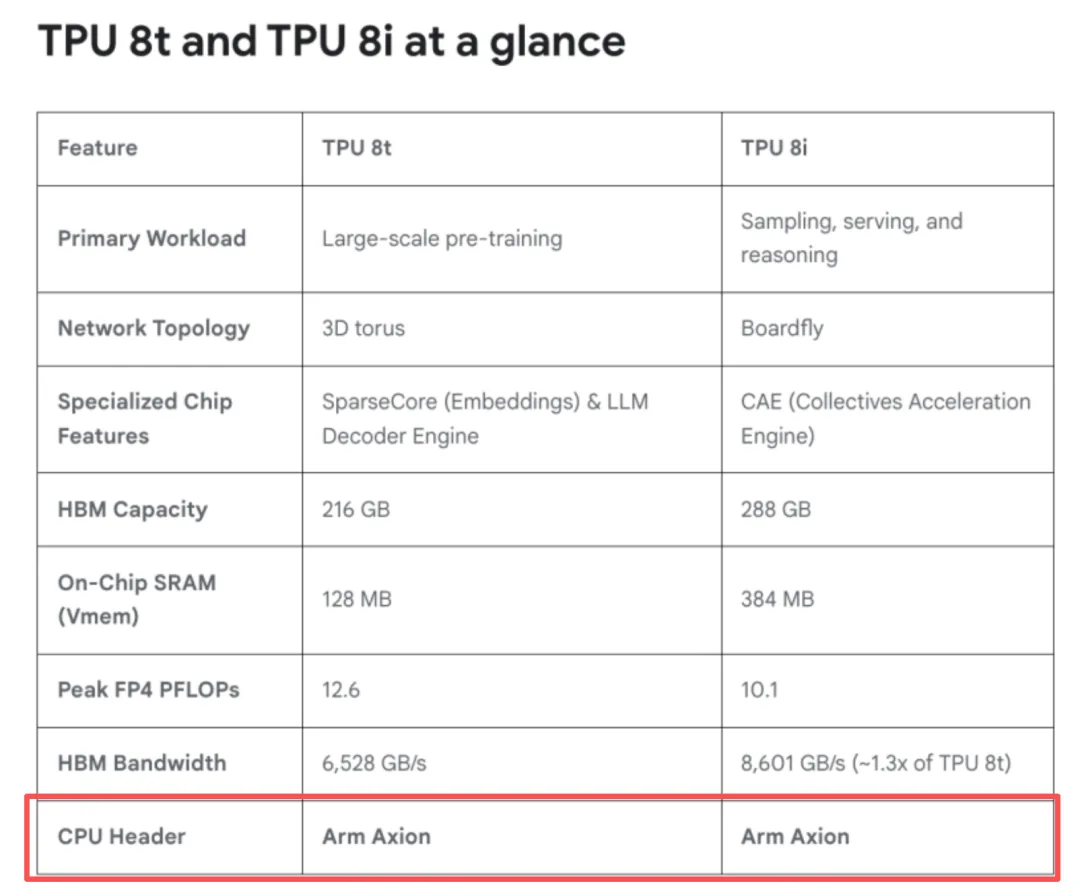
多核+低功耗+稳定的Linux支持,似乎ARM就是Agentic AI的最优选。
不久前我们看到ARM也忍不住自己下场了,推出了ARM AGI CPU。

其实ARM这款AGI CPU其实已经经过充分验证了。136个Arm Neoverse V3核心,2个Die的chiplet,基础频率为3.2GHz,12通道DDR5,96条PCIe6.0,CXL3.0,300W的TDP,纸面参数可圈可点。Graviton 5正是基于Arm Neoverse V3,相当于ARM做了流片测试。也可以说更像Azure Cobalt 200的姊妹版,因为Cobalt正是基于Neoverse V3 CSS的公版方案。
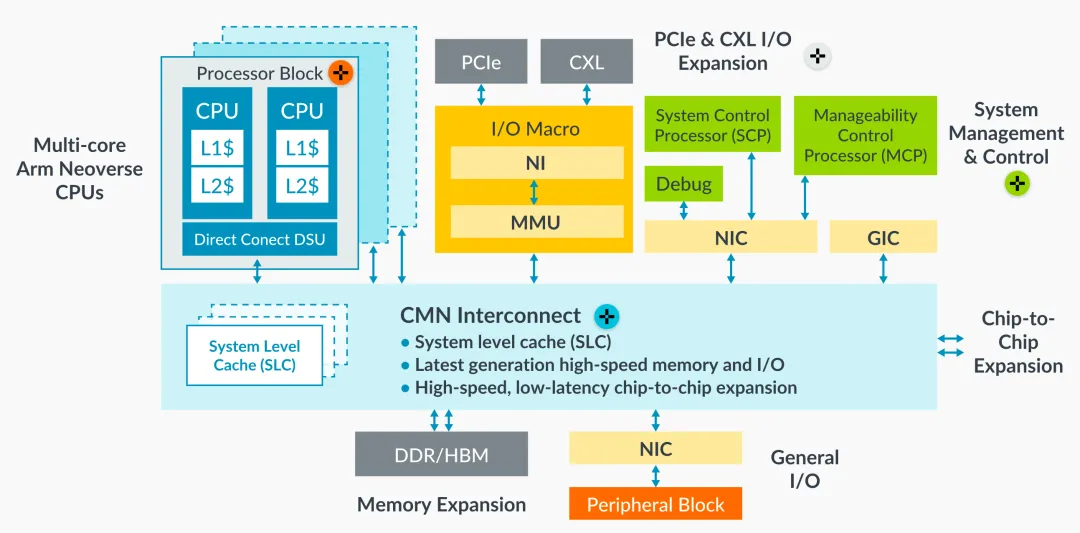
V3从测试指标来看,非常适合Agentic的工作负载。其实说白了,V3就是ARM摸着Nvdia Grace过河的产物。这就不难理解为什么Nvdia的Vera已经全面自研了。
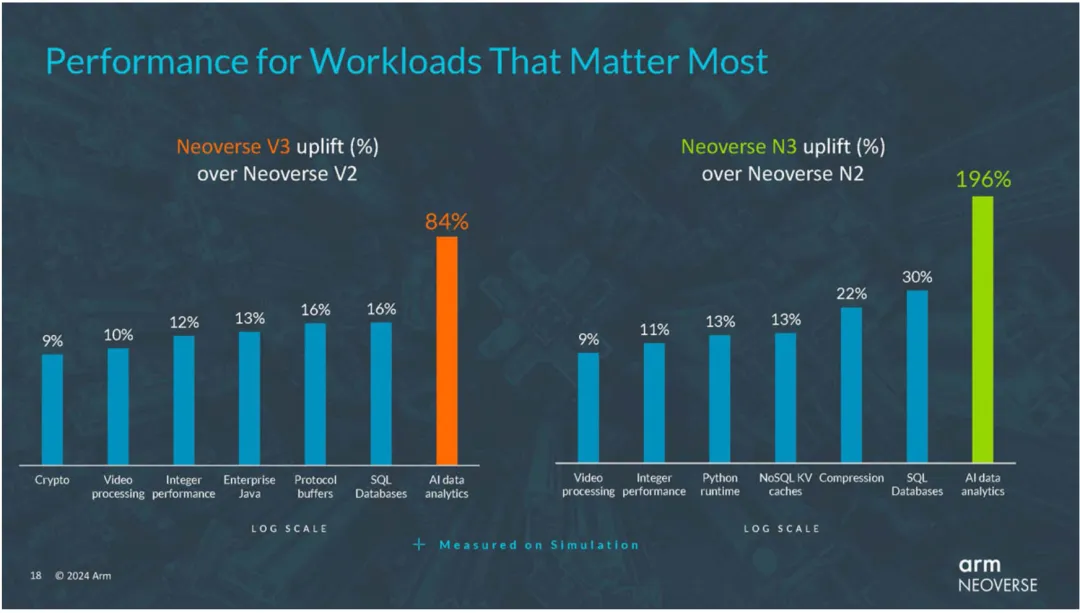
随着今年Agentic AI需求爆发,ARM迎来了一个史诗级市场机遇。根据BAML的测算,全球服务器级CPU市场大约400亿美元,未来几年会快速增长到千亿美金的体量,而这里面ARM CPU至少会拿走50%以上的增量。
这就是为什么ARM冒天下之大不韪,宁可得罪部分客户,也要自己下场干CPU。
五、到底需要多少CPU?从1:8到8:1
最近投资圈很热门的话题就是到底CPU用量需要多少?这个帮大家简单地算一算。
1:8就是指经典的8卡机,比如HGX H200基本都是经典的8卡机。
然而前面章节已经讲过了,HGX B300时代主流已经是双路CPU了,所以这个比例在2026年已经提高到了1:4。
如果考虑到Nvdia的超节点,那么这个比例就是1:2。最早的GH200其实是1:1,但那个属于是技术验证的原型机。Nvdia主推NVL72的GB200/300板卡,CPU:GPU已经是1:2了。今年GTC发布的Vera Rubin也还是1:2的配置。

那么1:1是怎么来的呢?其实这是Nvdia在GTC上面提出一个概念,本来Vera Rubin已经是1:2了,8台NVL144再额外配1台Vera CPU柜,基本就可以实现1:1了。

到底需不需要这么多CPU呢?只要养过龙虾应该是有感觉的。当用户在云端开启一个agent实例时,需要服务器CPU开启一个容器实例。
当然如果只是跑虚拟化环境,其实需要的CPU算力并不多。Agent的Orchestration计算图能够很清楚地展现CPU的工作量。每个sub-agent完成一次inference之后,CPU需要解析LLM输出(token反解)、判断是否触发工具调用(条件分支)、执行工具(I/O)、维护依赖关系图(哪些agent在等哪些agent的输出)、集成中间结果、决定是否进入下一轮反思循环。当并发sub-agent数量达到数百个时,这套数据编排和调度逻辑对CPU都提出了极高要求。
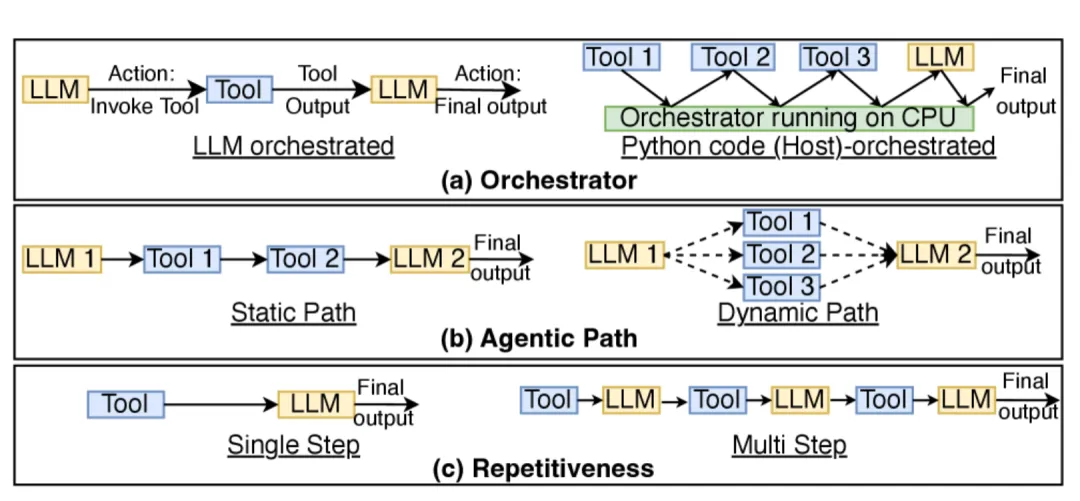
根据Georgia Tech与Intel的联合研究论文,针对5类代表性Agentic工作负载,CPU耗时占到工作负载延迟的50%-90%。说白了还是GPU在等CPU。为了提高GPU的利用效率,提高CPU数量是ROI非常高的方案。
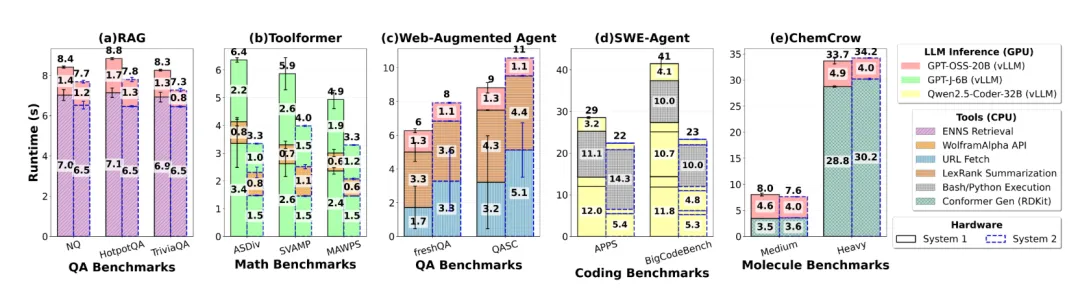
至于8:1我觉得可能就是分析师顺口一提,讲起来比较方便。
当然我还看过更牛逼的。去年底AWS和OpenAI战略合作的新闻,提到GPU的量级是数十万颗(假设是50万颗吧),而提到CPU的量级是千万级。那这岂不是CPU:GPU是20:1了?

写在最后
不管是1:1还是多少,Agentic AI驱动下,一场关于AI CPU的深刻革命正在悄然发生。CPU是时候回归C位了。
海外市场老罗是很看好ARM的,另外国产CPU机会更大。因为海外CPU缺货,今年国产是有机会实现KA客户的突破的,海光已经拿下阿里了,就看今年能否突破字节。除了X86之外,国产ARM CPU今年也是爆发元年,具体A股标的大家可以自己找找。