 夜雨聆风
夜雨聆风





AI通用智能体的能力进化-从OpenClaw到Hermes的分析和对比
大家好,我是人月聊IT。
今天聊下OpenClaw和Hermes的区别。注意该文完全由GPT5.5+Image2采用Codex完整提示词workflow一次完全生成。整个生成分为三个步骤。
其一是搜索和整理完整的文字版本的markdown文章。其二是用image2进行配图。其三是调用工具进行合成,将其合成为一个完整的word文档,方便我在各种互联网编辑器中导入。
从工具调用到经验沉淀:这轮智能体竞争的真正焦点
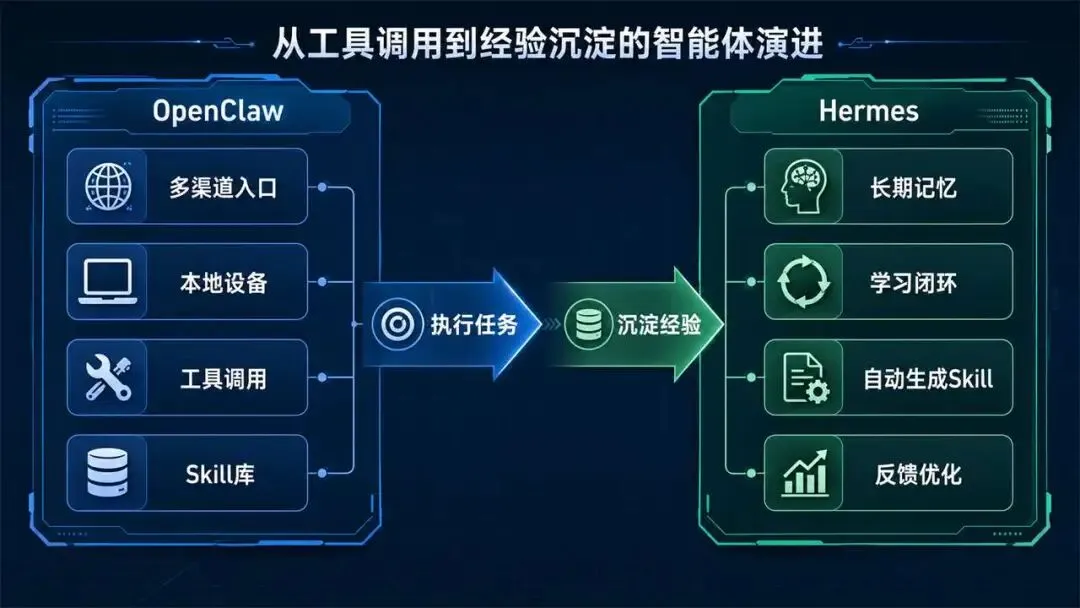
最近围绕OpenClaw和Hermes的讨论,表面看是两个开源智能体框架之间的竞争,实质上是个人AI助手从“能调用工具”走向“能沉淀经验”的路线分化。OpenClaw先把多渠道入口、本地设备访问、Skill扩展和自动化执行串成系统,让用户感受到AI不只是聊天窗口。
但使用一段时间后,OpenClaw的问题也会暴露出来。它能够理解意图、选择工具、拆分步骤,也能够连接各类消息入口,还能访问本地文件、浏览器和桌面环境。可一旦任务进入复杂、多轮、重复和需要改进的阶段,系统真正缺的不是更多工具,而是把成功经验、失败路径和个人偏好持续沉淀下来的闭环能力。
Hermes的出现切中了这个缺口。它并不是简单复刻OpenClaw的多渠道助手形态,而是在“记忆、技能、反馈、再利用”之间建立学习循环。OpenClaw更像智能体操作系统,Hermes则试图让系统内部长出进化机制。
OpenClaw的底层逻辑:个人入口、控制平面和执行节点
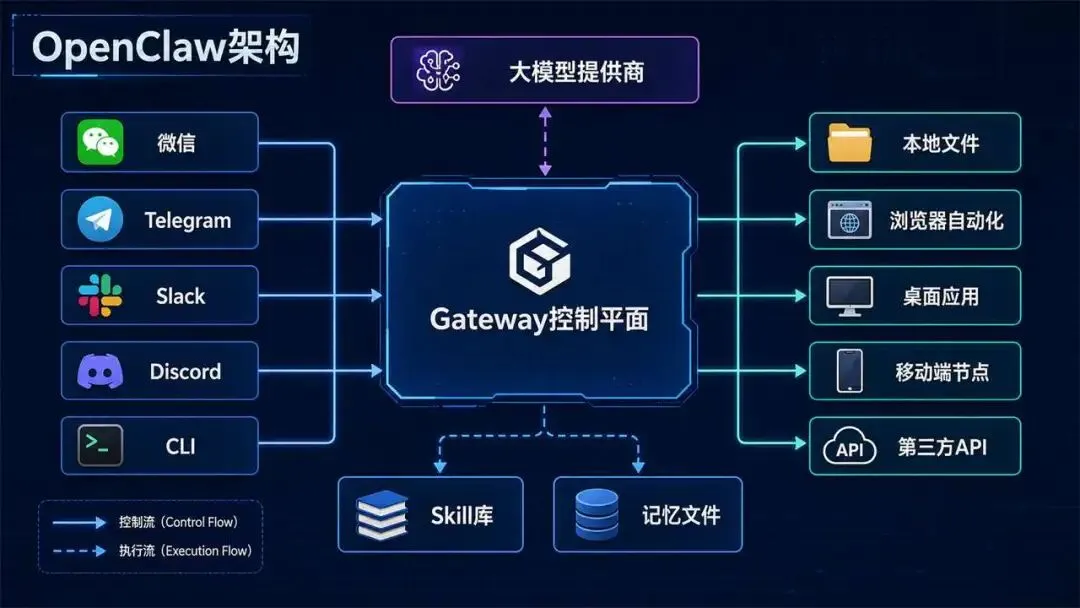
OpenClaw的核心定位是运行在用户自己设备上的个人AI助手。它不是单纯的网页聊天机器人,而是把消息入口、Gateway控制平面、Agent执行环境、桌面和移动端节点连接在一起。用户从常用IM入口发起任务,Gateway接收消息并维护会话,Agent再调用本地命令、浏览器、文件系统或第三方API完成动作。
这个架构的价值在于把“人在哪里沟通”与“任务在哪里执行”分离。用户可以在IM里发一句话,真正执行任务的却可能是本地电脑、远程服务器、浏览器脚本或某个Skill。Gateway负责连接、转发、权限和状态,执行节点负责访问文件、运行命令和返回结果。
因此OpenClaw最适合的场景并不是随口问答,而是本地资源访问和自动化任务。例如定期整理下载目录,读取PPT和Word并输出摘要,采集网页公开信息后生成日报,或者基于已有文档调用Skill输出PPT、邮件、周报。它的优势在于连接广和能动手,缺点则是对流程定义、数据质量、模型能力和API成本都有要求。
从工程角度看,OpenClaw的强项是生态接口和技能编排。它能把本地电脑、消息工具、浏览器和云端模型串联起来,形成个人自动化底座。但这个底座是否有用,取决于用户是否有稳定任务、结构化资料和可复用流程。
Hermes的技术抓手:闭环学习、分层记忆和Skill自生成
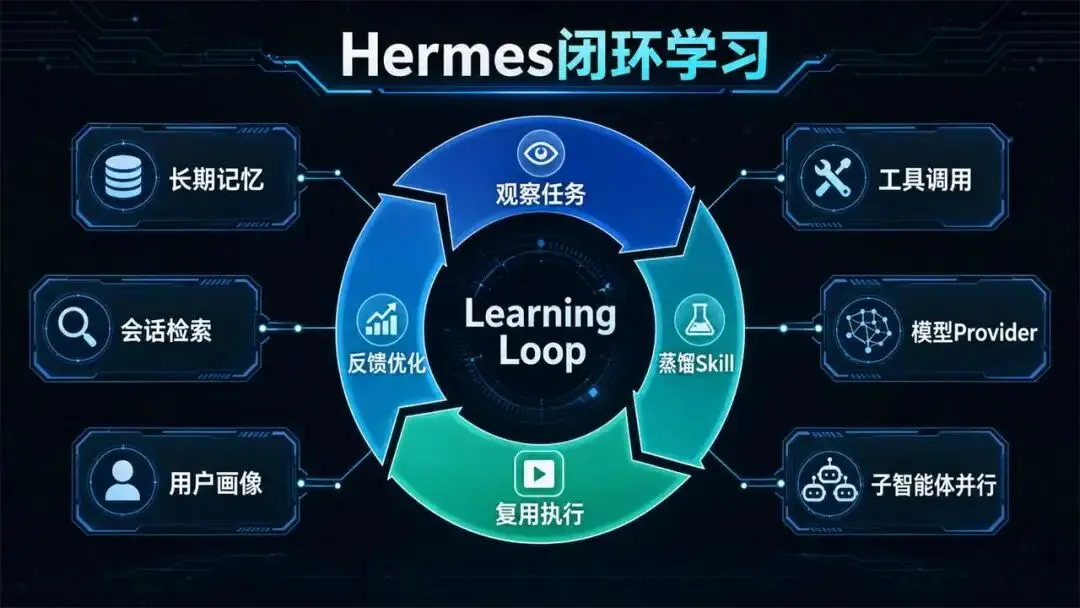
Hermes最值得关注的不是它也能聊天、接入消息平台、运行在本地或云端,而是它把“自我改进”设计成框架级能力。按照官方文档,Hermes内置学习闭环,能够从多步任务中观察过程,在相似任务多次成功后生成Skill,并在后续使用中继续修正。
这个闭环大体可以拆成四步:观察、蒸馏、复用、优化。观察阶段记录用户任务、工具调用、失败分支、修正意见和最终结果;蒸馏阶段把稳定的任务模式抽象成结构化Skill;复用阶段通过Skill描述进行轻量匹配,只在任务相关时加载完整Skill;优化阶段则允许系统在遇到更好做法时更新已有Skill,减少下一次重复试错。
Hermes还强调分层记忆和会话检索。它不仅保存某次对话上下文,还可以搜索历史会话、总结过去经验,并形成对用户偏好和工作方式的长期模型。真正的效率提升不只来自单次任务速度,而来自下一次是否记得命名规则、周报格式、可信来源和失败路径。
在执行层面,Hermes的Agent循环也更加工程化。它负责组装提示词和工具Schema,选择模型API模式,处理中断、压缩、重试和模型回退,并支持并发工具调用和子智能体委派。因此它的“进化”是建立在记忆、Skill、执行循环和反馈机制上的工程闭环。
关键能力对比:OpenClaw解决连接,Hermes强化进化
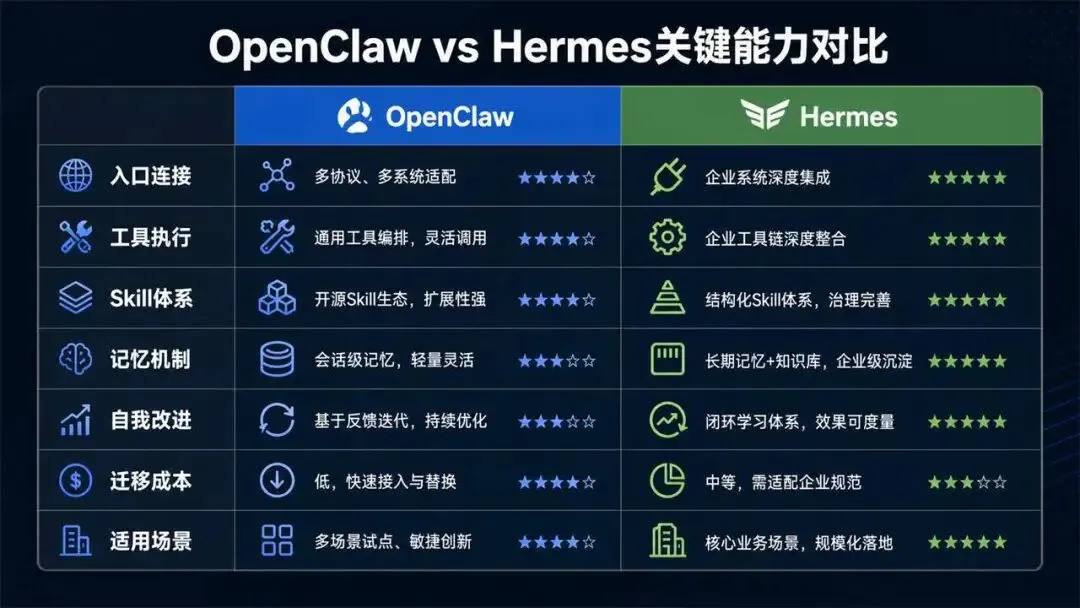
如果把两者放在一张能力地图里,OpenClaw首先解决的是连接问题。它把沟通入口、个人设备、本地文件、浏览器和Skill生态连接起来,让AI从“回答问题”变成“代表用户做事”。它的核心价值是把个人工作环境暴露给智能体。
Hermes更强调的是进化问题。它也需要入口、工具和执行环境,但差异化重点在于任务经验如何变成可复用资产。OpenClaw里用户也可以手工沉淀Skill和Memory,Hermes则把类似动作纳入闭环,在多次执行、反馈和修正后生成或更新Skill。
两者在模型依赖上也有差异。OpenClaw的执行质量很大程度取决于后端大模型是否足够强、工具是否可用、API是否稳定。模型水平不足时,Agent会反复试错,甚至在最优路径失败后转向次优路径。Hermes虽然同样依赖模型,但它试图通过记忆、检索、Skill和错误恢复机制降低重复试错成本,让相同类型任务越做越熟。
从用户价值看,OpenClaw像“个人智能体底座”,适合有明确自动化需求、愿意配置工具和整理流程的人;Hermes像“持续学习的数字同事”,更适合长期重复、步骤复杂、需要积累偏好和方法论的场景。
自我进化的真实边界:不是自动变聪明,而是减少重复试错
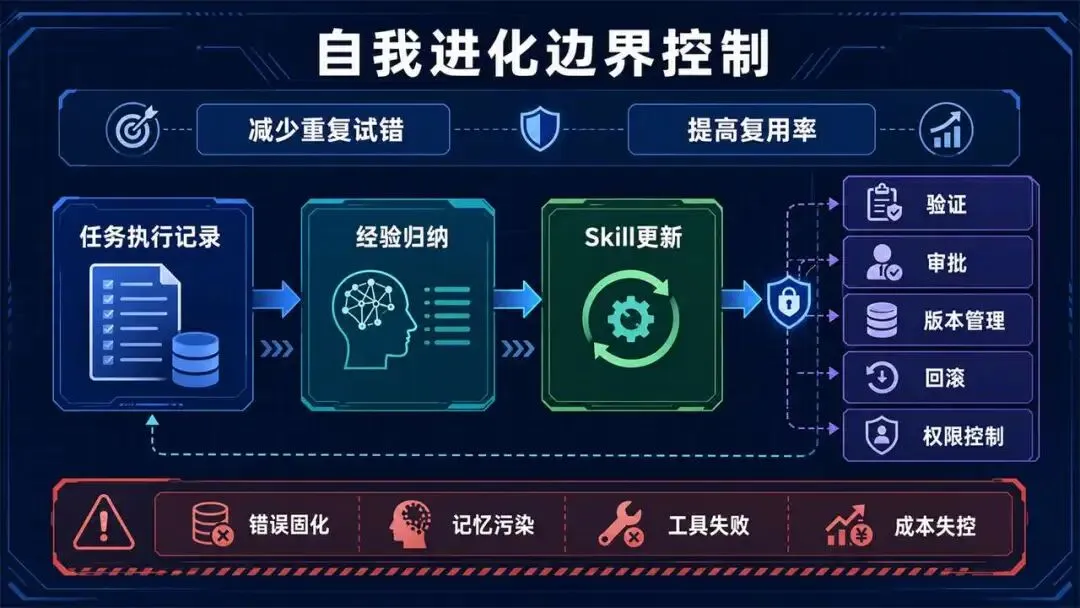
谈Hermes很容易陷入一个误区,以为自我进化就是智能体会无限变聪明。更务实的理解是:系统能不能把可重复任务中的成功路径固化下来,把失败路径记录下来,把用户修正转化成下一次执行规则。它不是自我觉醒,而是经验工程化。
这也是评价OpenClaw和Hermes时最需要保持清醒的地方。无论哪个框架,底层仍然依赖大模型推理、工具调用、权限控制和外部API。语音识别、OCR、图片生成、网页解析、代码执行等能力如果缺少可靠工具或高质量API,Agent本身无法凭空弥补。所谓自动化,最终仍要落到数据、接口、模型、成本和验证机制上。
自我进化还必须有边界控制。系统如果能自动修改Skill,就必须具备版本记录、回滚机制、权限审批和质量校验。否则它可能把偶然成功固化成错误规则,也可能长期积累混乱记忆。可用的学习闭环必须有证据地归纳、有约束地更新。
因此Hermes对OpenClaw的启发不在于新热点替代旧热点,而在于提醒我们:未来个人智能体的核心竞争,不只是入口多、工具多、模型多,而是谁能把人的工作经验变成可验证、可迁移、可复用的流程资产。
落地方法:先流程化,再记忆化,最后Skill化
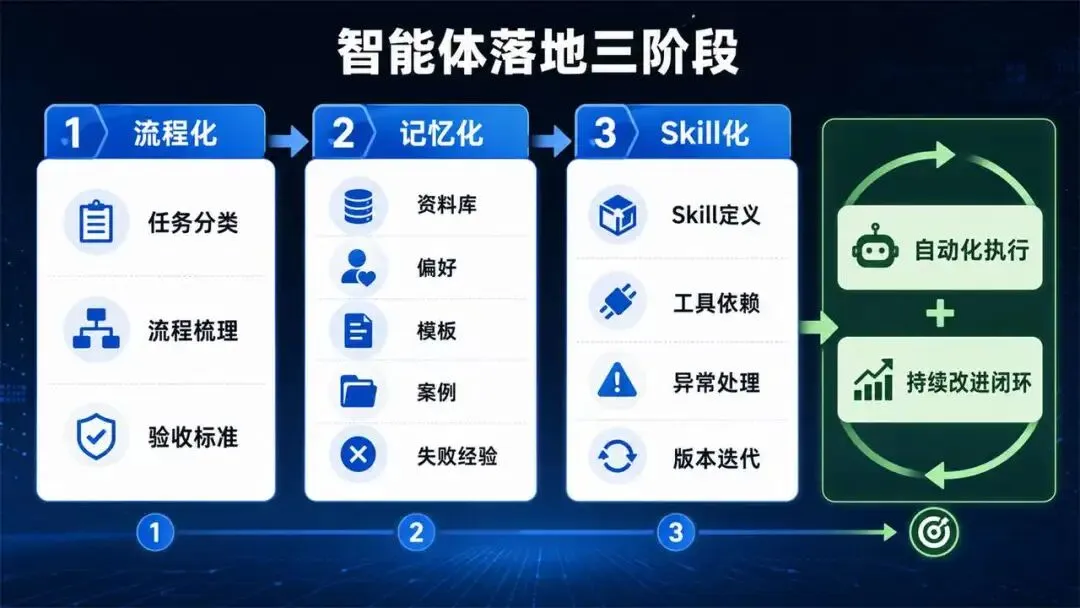
对个人或企业来说,从OpenClaw走向Hermes式进化,第一步不是安装新工具,而是先把工作流程想清楚。任何智能体都不擅长替一个混乱的人自动变得有序。用户需要先识别哪些任务高频、重复、可验证,哪些任务只是偶发探索。
第二步是记忆化。用户要把关键资料、偏好、术语、模板、历史案例、失败经验和质量标准显性写出来。OpenClaw时代很多人说“养虾缺饲料”,本质就是缺少结构化输入。Hermes具备闭环学习,也仍然需要高质量材料作为经验来源。
第三步是Skill化。一个可复用Skill不应只是提示词,而应包括触发场景、输入格式、执行步骤、工具依赖、异常处理、输出模板和验收标准。比如“热点文章写作”这个Skill,就要明确如何搜索资料、如何构建标题层次、如何生成配图提示词、如何检查逻辑、如何合成Word,而不是只写一句“帮我写文章”。
最后才是自动化和进化。系统每完成一次任务,都要把过程日志、用户修改、最终结果和失败原因沉淀下来。多次成功后归纳为Skill,多次失败后形成避坑规则。Hermes式闭环学习不是替代思考,而是帮助人把思考结果产品化。
趋势判断:从开源智能体到个人能力操作系统
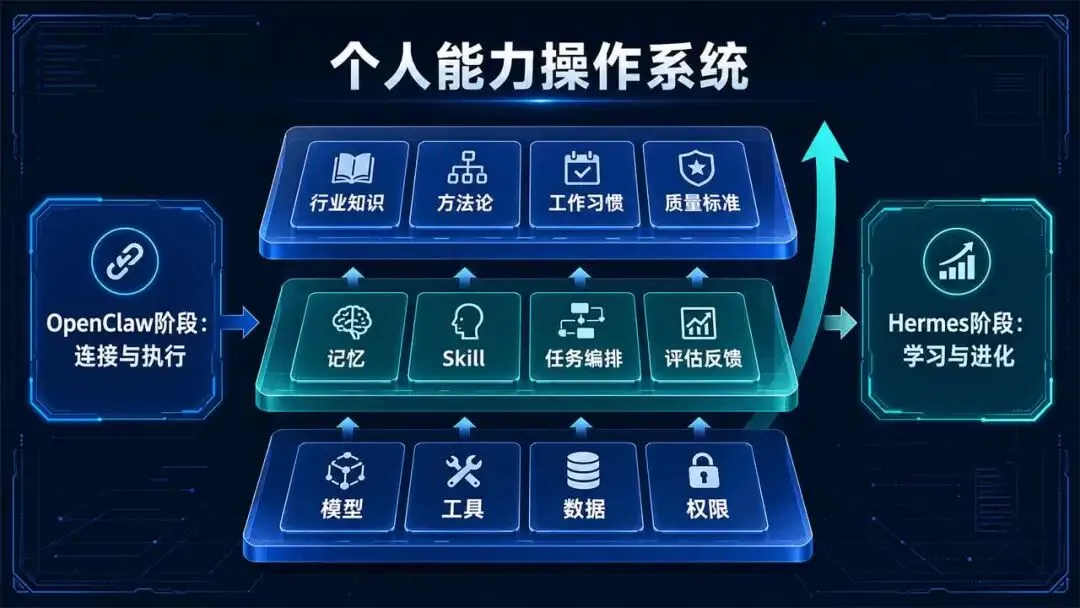
从OpenClaw到Hermes,表面是智能体产品形态在快速迭代,深层则是个人能力操作系统的雏形正在形成。过去效率工具解决文档、日程、邮件、知识库等单点问题;OpenClaw把这些点串起来;Hermes进一步把经验、规则和偏好沉淀下来。
未来有价值的智能体,不会只是更会聊天的助手,也不会只是能跑脚本的自动化工具,而是由三层组成:底层是模型、工具、数据和权限;中层是记忆、Skill、任务编排和评估;上层是用户的行业知识、方法论、工作习惯和质量标准。
这也意味着普通用户要改变预期。不要指望买一个热点工具就马上获得十倍效率,更现实的路径是先把工作结构化,把资料沉淀下来,把可复用经验写成Skill,再让智能体反复执行、记录和改进。工具只是放大器,能放大有序,也会放大混乱。
所以我对OpenClaw到Hermes的判断是:OpenClaw完成了智能体进入个人工作环境的第一步,Hermes则把下一步问题摆上台面,即如何让智能体在长期使用中理解你、记住你、复用你的方法,并在反馈中逐步改善。