 夜雨聆风
夜雨聆风





智商145的AI“天才”入场,视觉革命正在重构世界
清晨的第一缕阳光穿透百叶窗,在会议室的白板上投下斑驳光影。工程师马克盯着屏幕上跳动的数字,手指不自觉地收紧——145,这个数字安静地躺在评估报告的“视觉智商”一栏,像一颗无声惊雷。
就在此刻,世界某个角落的服务器集群正以人类无法想象的速度“理解”着视觉信息。这不是简单的图像识别,而是一种近乎直觉的视觉推理:它能从CT扫描中看到医生忽略的早期病变,能从卫星云图中预测三天后的风暴路径,甚至能从文艺复兴时期油画的笔触中,还原画家创作时的心跳节奏。
这就是GPT-5.5 Pro交出的答卷——在权威的LisanBench测试中,视觉智商达到145分,正式进入人类定义的“天才区”,超越了全球99.9%的人口。这个分数不仅跨越了门萨俱乐部的入会门槛,更标志着一个转折点:人工智能在理解视觉世界方面,开始展现出超越普通人类的抽象思维能力。
一、视觉智能的“质变”:从“看到”到“懂得”
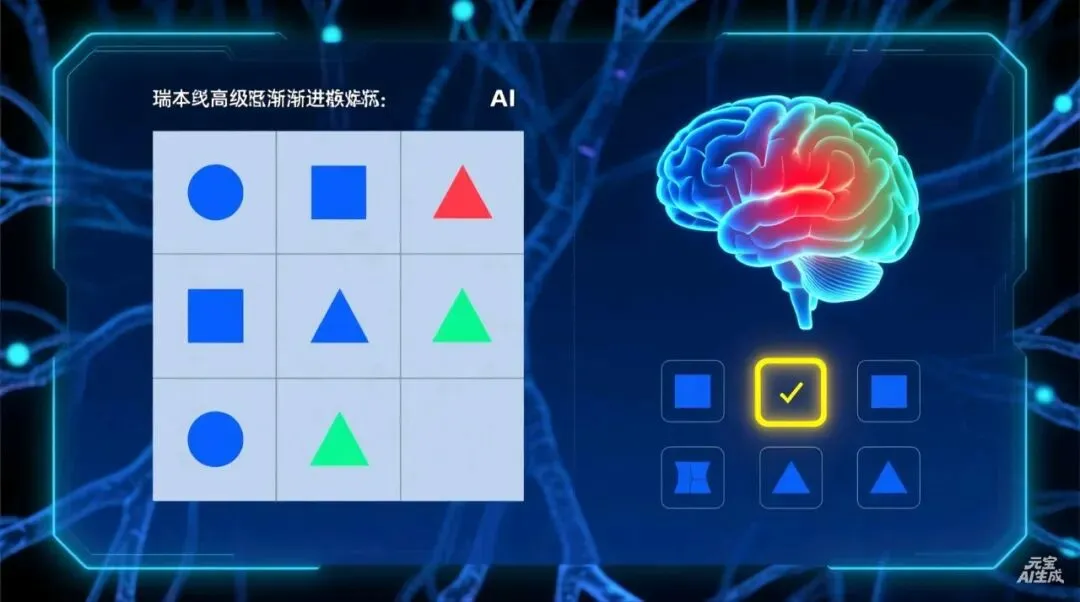
传统计算机视觉像是高度专业化的“工匠”——人脸检测模型只识别人脸,车牌识别模型只看车牌,每个任务都需要专门训练。而GPT-5.5 Pro代表的是一种“通才”的诞生。
它的强大不在于单一任务的精准,而在于跨领域的视觉理解力。在测试中,它能够解答复杂的瑞文推理矩阵题——那些由几何图形组成的逻辑谜题,需要从九个选项中找出缺失的那一块。对人类来说,这需要空间想象、类比推理和模式识别的综合能力。而对GPT-5.5 Pro来说,这不过是又一次常规的“思考练习”。
更令人震撼的是它的“视觉常识”。给它看一张雨中的街道照片,它不仅能看到车辆、行人和红绿灯,还能推理出“行人可能会加快脚步找地方躲雨”,“路面湿滑可能导致刹车距离变长”。这种对物理世界因果关系的理解,曾经被认为是AI难以逾越的鸿沟。
二、四百亿美金的豪赌:谷歌的算力宣言

当视觉智能的边界被重新定义,背后的算力竞赛也进入白热化阶段。谷歌宣布向AI公司Anthropic承诺最高400亿美元投资的消息,像一颗深水炸弹在科技海洋中引爆。
这不仅是科技史上最大规模的单笔投资之一,更代表着一种战略转向——从单纯追求模型参数的增长,转向构建“模型-算力-数据”三位一体的生态系统。谷歌将把其最先进的TPU算力深度绑定给Anthropic,这种硬件与软件的联姻,可能催生出下一代AI基础设施的标准架构。
市场在惊叹于这个数字的同时,也提出了尖锐的问题:如此巨额的投入,究竟能否带来相应的回报?AI研发的“边际效益递减”是否已经出现?
谷歌的答案藏在投资细节中:400亿美元并非一次性注入,而是与明确的里程碑挂钩。前100亿美元基于约3800亿美元估值投入,后续300亿则取决于技术突破和商业进展。这是一种“为确定性付费” 的新逻辑——资本不再盲目追逐“更大”,而是明智地投资“更好”。
这场豪赌的核心在于相信一个简单却强大的等式:更先进的模型+更充裕的算力=更快的AGI(通用人工智能)路径。在这个等式中,400亿美元不是成本,而是通往未来的门票。
三、VisionBanana:视觉领域的“通用语言”
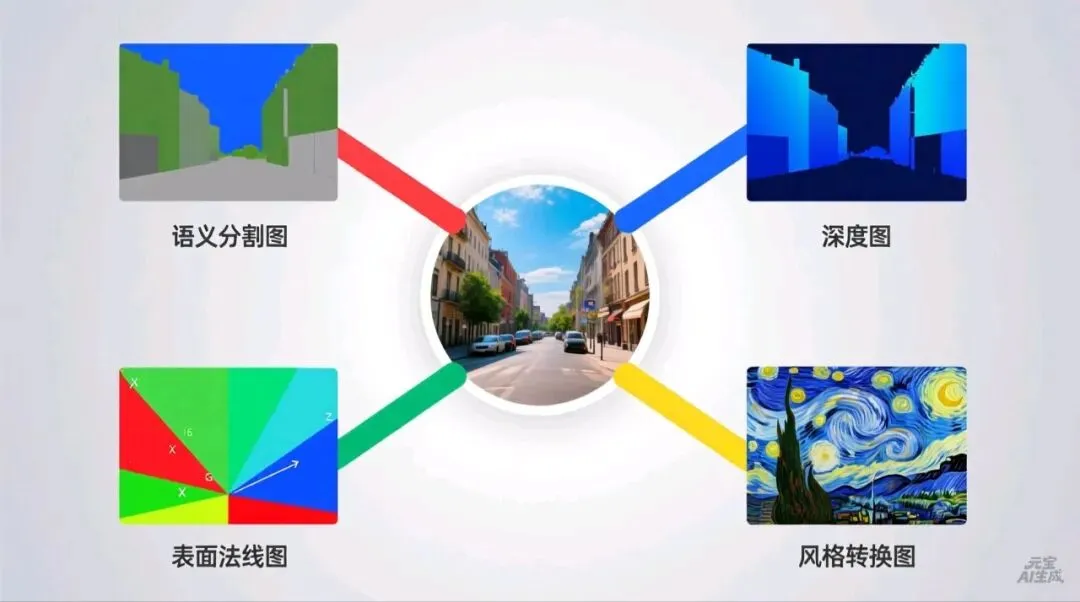
就在同一天,DeepMind发布了VisionBanana——一个试图用“生成一切”来统一计算机视觉的框架。这个名字看似古怪,背后却是深刻的洞察:既然所有视觉任务本质上都是“从图像到某种输出”,为什么不把所有输出都变成图像呢?
这个理念简单到近乎天才。无论是图像分割、深度估计、表面法线计算,还是物体检测,VisionBanana都将其转化为RGB图像生成问题。就像一个画家,根据不同的指令画出不同风格的“解读”——医生需要病变区域标注?画一幅用颜色标记的“分割图”。自动驾驶需要3D场景理解?画一幅用深浅表示距离的“深度图”。
令人惊讶的是,这种“一招鲜”的方法不仅可行,而且在多项任务上超越了专门训练的专家模型。在权威的2D分割和3D估计基准测试中,VisionBanana击败了包括SAM 3在内的多个专用模型,同时保留了强大的图像生成能力。
这代表着计算机视觉领域可能迎来自己的“GPT时刻”——用单一架构统一所有任务,终结过去“一事一模型”的碎片化时代。开发者的门槛将大大降低:你不再需要为每个视觉任务寻找、训练、部署不同的模型,而只需要一个能“理解你需求”的视觉通用模型。
四、效率革命:当智能变得更便宜
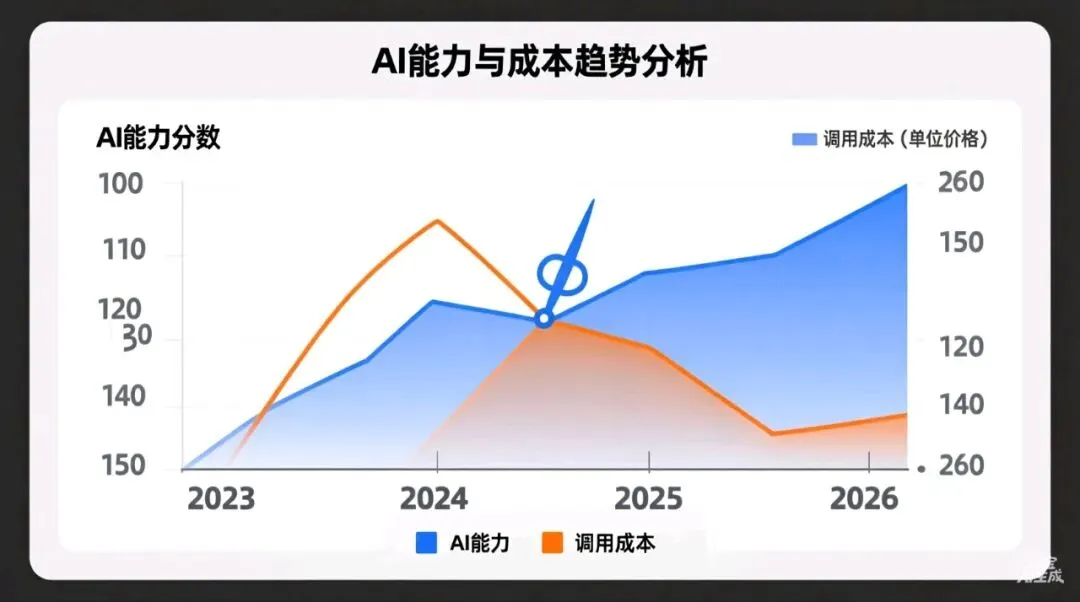
在这场技术盛宴中,最容易被忽视却最重要的趋势是:AI正在变得更智能,也更便宜。
GPT-5.5 Pro在API层面实现了惊人的效率提升:Token消耗减少45.6%,而智能分数却提升了1.77倍。这意味着开发者可以用不到一半的成本,获得接近两倍的能力。这种“性价比”的跃迁,将AI从科技巨头的玩具,变成了中小企业也能负担的工具。
VisionBanana的统一架构同样大幅降低了部署和维护成本。一个模型替代多个模型,意味着更少的内存占用、更快的推理速度、更简单的更新流程。对于医疗、制造、安防等传统行业而言,这种“开箱即用”的特性,可能是他们拥抱AI转型的最后一块拼图。
效率革命的另一面是应用场景的爆发。当视觉AI变得足够便宜、足够易用,它的应用将渗透到社会的毛细血管:帮助视障人士“看见”周围环境,协助农民精准识别病虫害,赋能偏远地区的远程医疗,甚至让每个人都能成为自己生活的“视觉分析师”——只需拍一张照片,就能获得装修建议、穿搭推荐或食谱生成。
五、人机协作的新篇章:赋能而非替代

面对智商145的AI,人类应该感到恐惧吗?恰恰相反,我们应该感到兴奋。
回顾历史,每一次工具的革命都扩展了人类的能力边界。望远镜让我们看得更远,显微镜让我们看得更细,而视觉AI将让我们“看得更懂”。它不是替代人类的眼睛,而是为我们装上了能透视、能分析、能预测的“智能镜片”。
在医疗领域,AI不会取代医生,但可以帮助医生在早期发现那些容易被忽视的征兆。在科研领域,AI不会替代科学家,但可以处理海量的观测数据,让人类专注于提出更好的问题。在教育领域,AI不会取代教师,但可以为每个学生提供个性化的视觉学习材料。
这种协作关系的核心是互补:人类擅长创造性思维、价值判断和复杂情境下的灵活应变;AI擅长模式识别、大规模数据处理和不知疲倦的重复劳动。当两者结合,产生的不是简单的加法,而是乘法。
六、未来的轮廓:我们正站在什么位置

这一周发生的三件大事——GPT-5.5 Pro的视觉突破、谷歌的400亿投资、VisionBanana的范式统一——看似独立,实则相互呼应。它们共同描绘了AI发展的新阶段:
从比拼规模到比拼效率:模型不再盲目追求参数量的增长,而是在架构创新中寻找“更聪明”的路径。
从单一突破到生态构建:竞争从模型层面扩展到算力、数据、工具链的全栈能力。
从技术炫技到价值落地:焦点转向如何让AI变得更可用、更可及、更有实际价值。

我们正站在一个临界点上。过去十年,AI学会了“看”和“说”;未来十年,AI将学习“理解”和“创造”。当视觉智商145的AI开始理解这个世界的深层结构,当千亿级别的投资持续注入这个领域,当统一的框架让技术变得平易近人,一场静默但深刻的变革已经拉开序幕。
这不仅仅是一场技术的进化,更是一次认知的扩展。AI的“眼睛”将帮助我们看见曾经看不见的模式,理解曾经无法理解的关联,解决曾经难以解决的难题。在这个过程中,人类不是旁观者,而是共同进化的参与者。

或许,真正的问题不是“AI有多智能”,而是“有了这样的AI,人类可以变得多智能”。当机器能处理信息的“是什么”,人类就可以更专注于探索“为什么”和“应如何”。这,才是这场视觉革命最令人期待的篇章。