夜雨聆风
夜雨聆风





AI算力的底层逻辑和机会-台积电专题报告
台积电在 2026 年技术研讨会上,公布了最新的先进制程和先进封装路线图。
很多人看到这些词会觉得很专业:N2、A16、A14、A13、CoWoS、SoIC、HBM、硅光子、背面供电……
但如果用一句简单的话概括,这份报告其实在讲:
AI 发展到最后,拼的不只是模型有多聪明,而是谁能真正把支撑 AI 的算力系统造出来。
今天我们看到的 AI,好像只是手机或电脑上的一个软件,一个聊天框,一个应用。
但它背后其实是巨大的物理工程:芯片、封装、内存、供电、散热、数据传输、工厂产能、良率和供应链。
所以 AI 看起来很轻,但底层非常重。
一、AI不是短期热点,而是一轮新的半导体超级周期
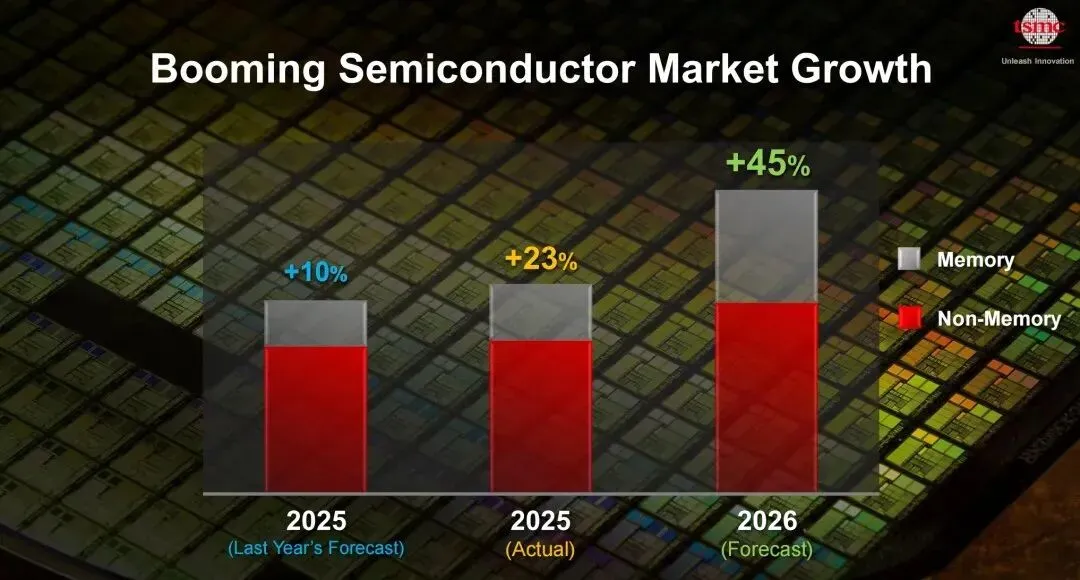
这份报告给出的第一个信号,是半导体行业的增长速度变了。
过去几十年,半导体行业每一轮大增长,背后都有一个核心产品。
最早是 PC,后来是互联网,再后来是智能手机。
每一轮新终端出现,都会带动芯片需求上升。
但这一次 AI 不太一样。
AI 不是简单多了一个新产品,而是让整个社会对算力的需求突然大幅增加。
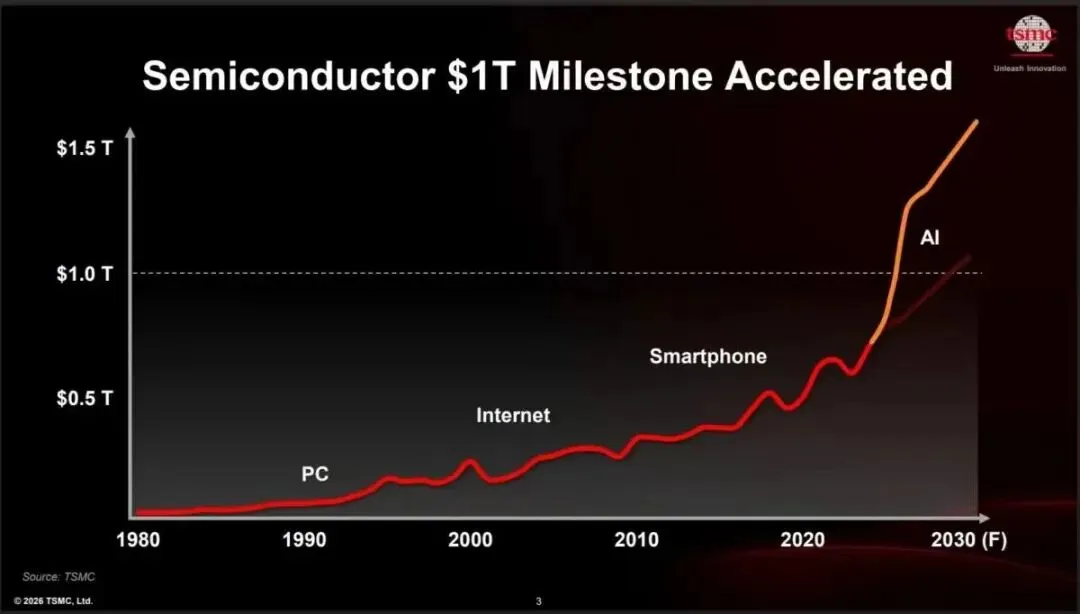
台积电判断,全球半导体市场正在加速走向 1 万亿美元规模,并有可能在 2030 年前后达到 1.5 万亿美元。
更重要的不是市场变大,而是谁在贡献增长。
到 2030 年,HPC/AI 预计会占半导体市场的 55%。

简单理解,未来半导体最大的需求来源,不再是手机,而是 AI 算力。
过去手机是芯片行业的核心驱动力。以后,AI 服务器、数据中心、AI 加速器,会成为新的核心驱动力。
这背后的逻辑很简单:
PC 时代,解决的是“有没有电脑用”;互联网时代,解决的是“能不能联网”;智能手机时代,解决的是“能不能随时随地上网”;AI 时代,解决的是“算力够不够”。
只要 AI 还在发展,算力就会越来越重要。而算力的底层,就是半导体。
所以,不是 AI 顺便带动了半导体,而是 AI 把半导体重新推回了全球科技竞争的中心。
更多有价值美、科技投资相关分析、具体操作,详见社群
二、先进制程还在推进,但竞争维度已经变了
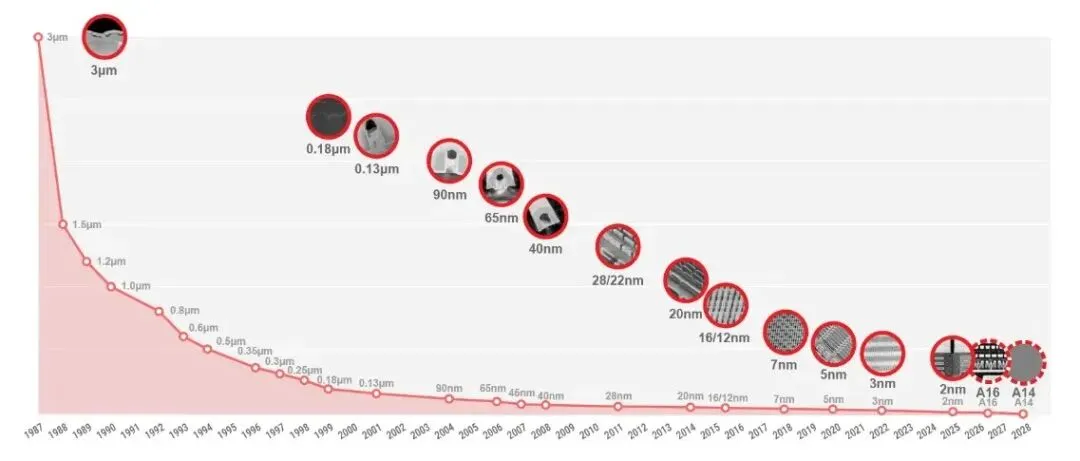
过去我们理解芯片先进不先进,通常看一个数字:
7 纳米、5 纳米、3 纳米、2 纳米。
数字越小,大家就觉得越先进。
这个理解不能说错,但已经不够用了。因为 AI 时代的芯片,和手机芯片不是一回事。
1. 单纯追求节点缩小,已经解释不了全部竞争
1、旧的规模化模式正在瓦解
过去判断芯片先进不先进,大家最习惯看一个数字:
7nm、5nm、3nm、2nm。
数字越小,似乎就越先进。
但现在,这个判断方式已经不够用了。
因为手机芯片和 AI 芯片面对的问题,已经不是同一类问题。
手机芯片更在意省电、续航、面积效率,以及成熟 IP 能不能继续复用。
AI 加速器和高性能计算芯片,则更在意供电是否稳定、带宽是否足够、散热能不能压住、封装能不能承载更大规模,以及整个系统的效率。
这些不再是边缘问题,而是 AI 芯片设计里越来越关键的约束。
所以,台积电的路线图不再只是强调晶体管继续变小,而是把技术分成不同平台,去适配不同的应用场景。
2、报告中的制程路线图依然激进:
台积电的路线图依然很激进。从 N4、N3、N2,一路推进到 A16、A14、A13,时间线延伸到 2029 年,覆盖 AI 加速器、数据中心、移动设备、汽车等核心场景。

一方面,台积电继续推出 N2P、N2U、A14、A13 这类演进平台。
它们的重点,是在继续提升性能、功耗和密度的同时,尽量降低客户重新设计的成本和难度。
另一方面,A16 和 A12 这类技术,更明显是为 AI/HPC 这种高性能、高功耗、高带宽场景准备的。
所以,这份路线图真正要表达的,不只是“节点继续往前走”。
更重要的是,先进制程正在变成不同类型的平台:
有的平台强调平滑升级和设计复用;有的平台强调极限算力、供电能力和系统效率。
这才是 AI 时代制程竞争的新变化。
3、A13被明确规划在2029年量产,具备97% optical shrink和约6%面积节省,同时通过DTCO持续优化性能与功耗,并保持与A14设计规则兼容,降低IP迁移成本。

A13 并不是一个特别激进的节点。
但它的重要性,恰恰在于“不激进”。
台积电把 A13 定位为 A14 的直接缩小版本,在保持设计规则和电气特性兼容的基础上,提高逻辑密度。
简单理解,就是客户之前在 A14 上做好的设计,迁移到 A13 时,不需要大规模推倒重来。这很重要。

因为芯片迁移到新工艺,成本远远不只是晶圆价格。
真正麻烦的是 IP 迁移、设计验证、EDA 流程调整、时序收敛、物理验证、可靠性认证、软件支持,以及量产时间风险。
对大型芯片团队来说,这些成本非常高。
所以,A13 的价值不在于它有多革命,而在于它能让客户用更低成本、更低风险,把已有设计继续往前推进。
这对手机芯片和客户端芯片尤其重要。
这些产品不一定每一代都需要算力大跳跃。
它们更需要的是功耗低一点、面积小一点、上市快一点、成本更可控一点。
所以,A13 重要,不是因为它激进,而是因为它在商业上更现实。

4、N2U则在2028年量产,针对AI/HPC与移动场景,在同功耗下提升3–4%速度,在同速度下降低8–10%功耗

N2U 计划在 2028 年量产,主要面向 AI/HPC 和移动应用。
台积电给出的指标是:在相同功耗下,速度提升约 3%—4%;或者在相同速度下,功耗降低约 8%—10%。同时,逻辑密度较 N2P 提升约 2%—3%,并保持与 N2P IP 的兼容性。
这些数字看起来不大。
但在先进制程走到后期之后,每一点提升都很难。
N2U 的意义,不是重新开一条完全不同的路,而是把 N2 平台继续用好。
很多芯片公司并不希望每一代产品都全部重做。
它们更希望基于已有平台,继续推出旗舰版、升级版和成本优化版。
N2U 正好满足这种需求。
这说明,台积电卖的不只是晶圆,而是一整套平台能力。
里面包括 IP、设计工具、良率经验、量产能力,以及客户从一个节点迁移到另一个节点的路径。
未来代工厂的竞争,不只是看谁的晶体管参数最好,也要看谁能让客户更稳定、更低风险地持续推出产品。
5、A16 和 A12 属于另一个世界:人工智能和高性能计算不能再依赖渐进式方法了。
如果说 A13 和 N2U 代表的是平滑升级,那么 A16 和 A12 代表的就是另一类需求:AI/HPC 的极限算力需求。
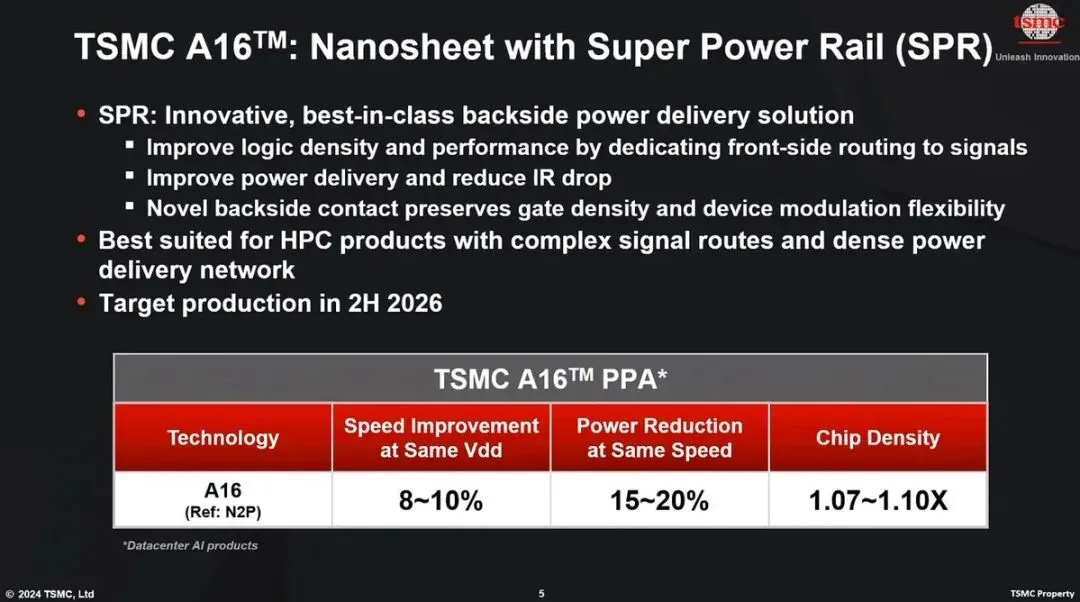
A16 采用 Super Power Rail 背面供电技术,主要面向数据中心级高性能应用。
背面供电听起来很专业,但可以简单理解:
过去芯片里的电力线路和信号线路,很多都挤在同一面,空间越来越紧。
背面供电,就是把一部分供电线路移到芯片背面,让电力传输和信号传输分开。
这样可以减少拥挤,提高供电效率,也让信号传输更顺畅。
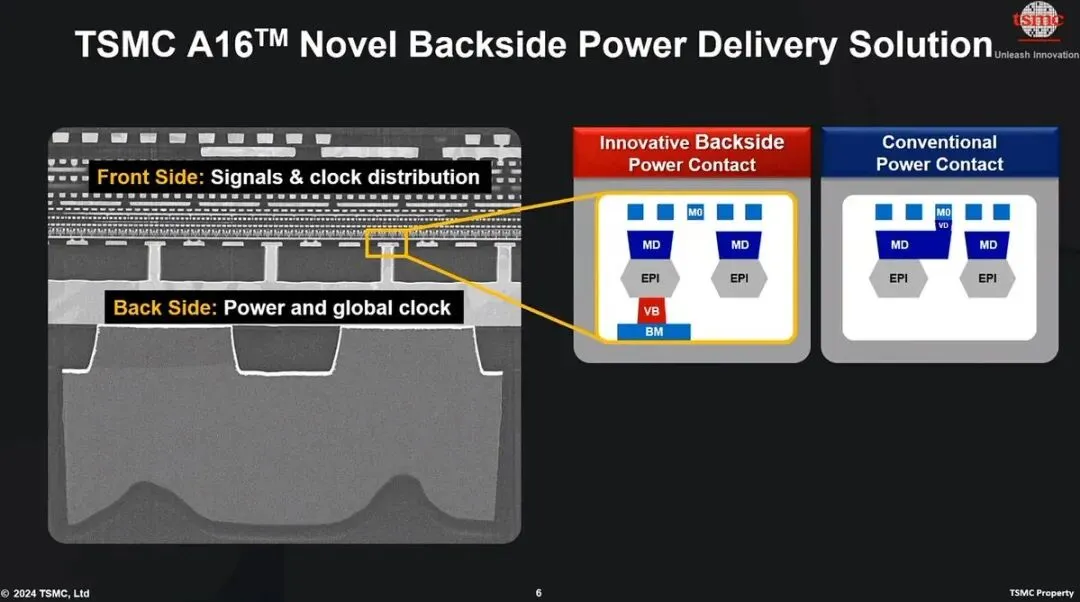
AI 芯片越做越大,耗电越来越高,传统供电和布线方式会越来越吃力。
这时候,供电本身就会变成性能瓶颈。
所以 A16 和 A12 的意义,不只是节点名字更新,而是说明 AI 芯片的竞争,正在从“晶体管继续缩小”,转向“供电、布线和系统架构一起优化”。
这次研讨会上,台积电还重申:2029 年之前,不会在 A13 和 A12 等节点上使用 High-NA EUV。
High-NA EUV 是更先进的光刻技术。
但它的问题也很明显:设备极其昂贵,配套生态复杂,工艺集成难度高,投资回报不一定马上划算。
台积电的态度很务实:
如果现有 EUV 技术仍然可以继续支撑先进制程,而且成本和量产更可控,就没有必要为了“看起来更先进”而过早切换。
这正是台积电的制造判断能力。
芯片制造不只是看技术名词,也不是看 PPT 参数。
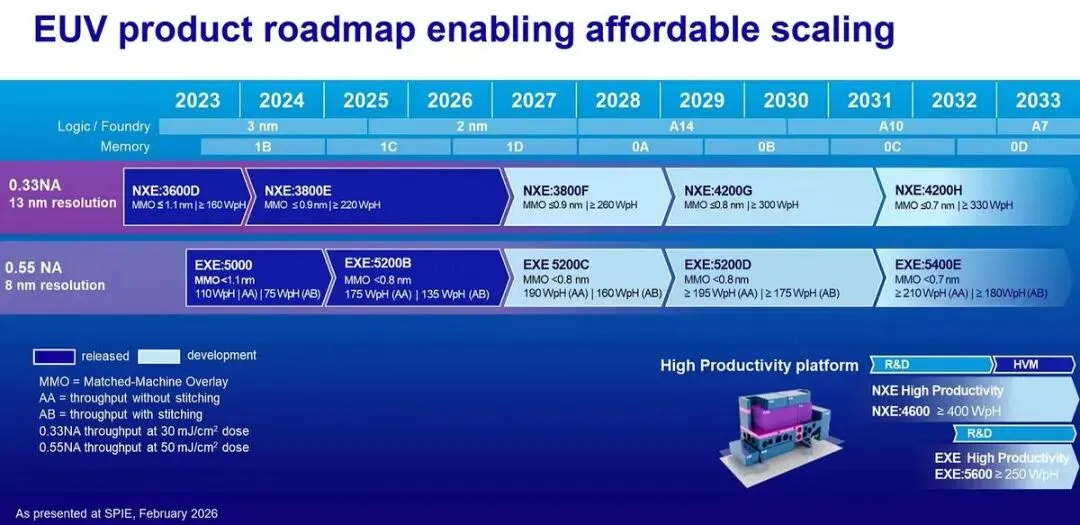
真正重要的是能不能稳定量产,良率能不能控制,成本能不能接受,客户愿不愿意采用。
所以,这里真正关键的变化是:制程不再是唯一主战场。
台积电正在把重点放到先进逻辑、先进封装、3D 堆叠、HBM 和高速互连的组合能力上。
过去比的是“谁的晶体管更小”。
现在比的是“谁能把整个算力系统做出来”。
先进制程决定上限,系统集成决定差距。
三、算力增长的真实引擎:CoWoS、SoIC、HBM
1、如果说制程是底座,那么CoWoS、SoIC和HBM,就是AI算力继续扩张的核心机制。
CoWoS、SoIC 和 HBM 这几个词都很专业,但可以先简单理解:
CoWoS,是把计算芯片和 HBM 高带宽内存更紧密地封装在一起。
SoIC,是把芯片做 3D 堆叠,提高芯片之间的连接密度。
HBM,是 AI 训练和推理非常依赖的高速内存。
台积电给出的路线非常明确:
2026 年量产 5.5-reticle CoWoS,良率超过 98%;2028 年推进到 14-reticle,支持 20 颗 HBM;2029 年以后超过 14-reticle,支持 24 颗 HBM。

这说明,AI 算力增长已经不能只靠单颗芯片变强。
它越来越依赖把更多计算芯片、更多 HBM、更复杂的封装和更高效的互连组合起来。
在 AI 时代,先进节点的价值,不只取决于晶体管密度。
还要看它能不能和封装、内存、散热、供电、互连一起工作。
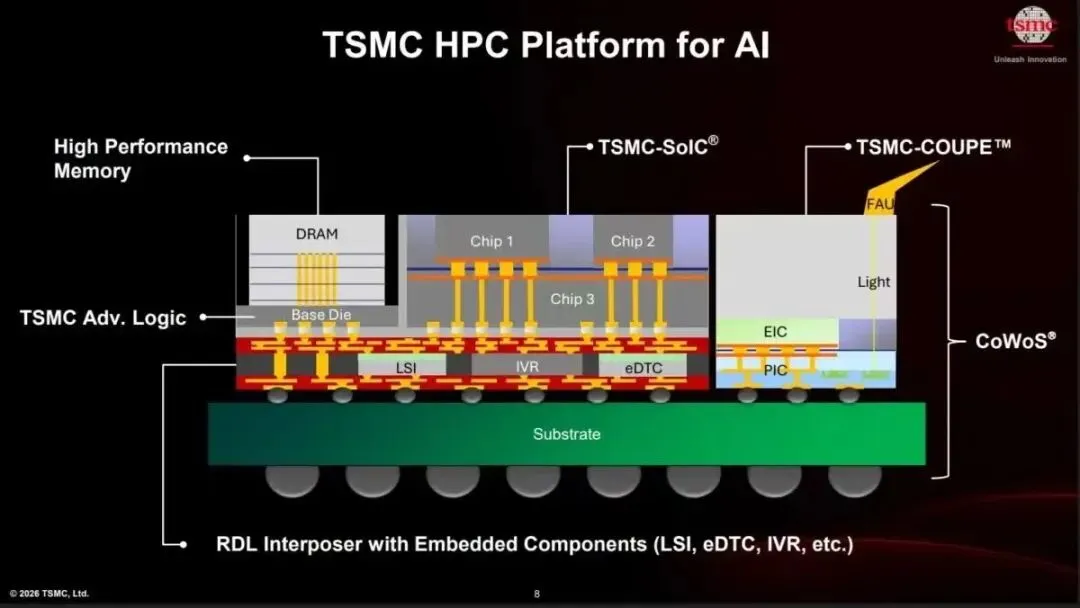
所以,最强的半导体公司,不只是做出最小晶体管。
而是能把芯片、内存、封装、供电、互连和量产能力,整合成一套完整系统。
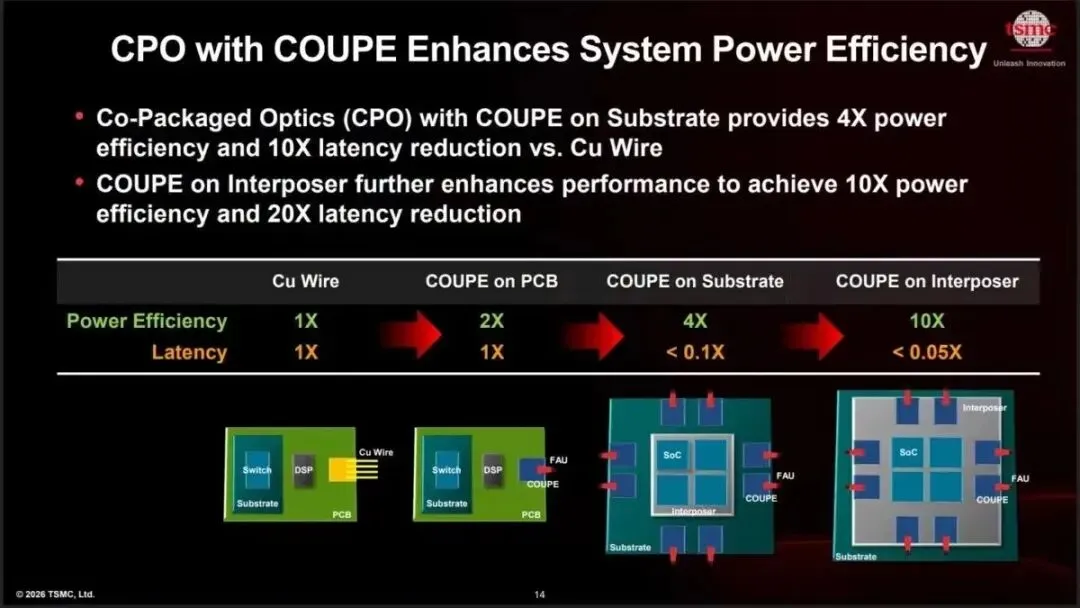
AI 系统的瓶颈,不只是算力本身,还有数据传输。
芯片之间、封装内部、服务器之间,如果数据传输跟不上,再强的计算芯片也会被浪费。
硅光子技术,就是用光来传输数据,目的在于提高速度、降低损耗。
台积电推进 COUPE 平台,就是希望把光子芯片和电子芯片更紧密地集成在一起,服务高性能计算。
这说明,台积电不只是做晶体管,也不只是做封装。
它正在把能力延伸到封装内部的数据传输环节。
未来 AI 系统越做越大,高速互连就越重要。
谁能解决这个问题,谁就能在 AI 基础设施里占据更重要的位置。

这份路线图的真正含义:如果把整个故事压缩成一句话:
台积电不再把先进节点看成一条简单直线,而是把它拆成不同平台,分别服务不同计算需求。
A13 和 N2U,代表低迁移成本、IP 复用和平台连续性。
A16 和 A12,代表 AI/HPC 场景下,对供电、布线和系统性能的新要求。
不急着使用 High-NA EUV,也说明台积电更看重技术是否真正带来制造价值和经济价值。
这意味着,AI 算力增长不再只依赖单颗芯片,而是越来越依赖系统封装规模。
当单颗芯片继续扩展变难,就需要把更多芯片和更多 HBM 组合在一起。
进一步,台积电提出 SoW,也就是 System-on-Wafer。
它把集成规模扩展到超过 40 倍 reticle,支持 64 颗 HBM,计划 2029 年量产。

这已经接近“晶圆级系统”。
同时,SoIC 推动 3D 堆叠成为主流路径。
最终,2024—2029 年,单个 CoWoS 内计算晶体管预计提升 48 倍,HBM 带宽提升 34 倍。

这才是 AI 硬件真正的增长曲线。不是简单制程迭代,而是“制程 + 封装 + 堆叠 + 内存”的系统级叠加。
摩尔定律没有消失,只是变成了系统工程。
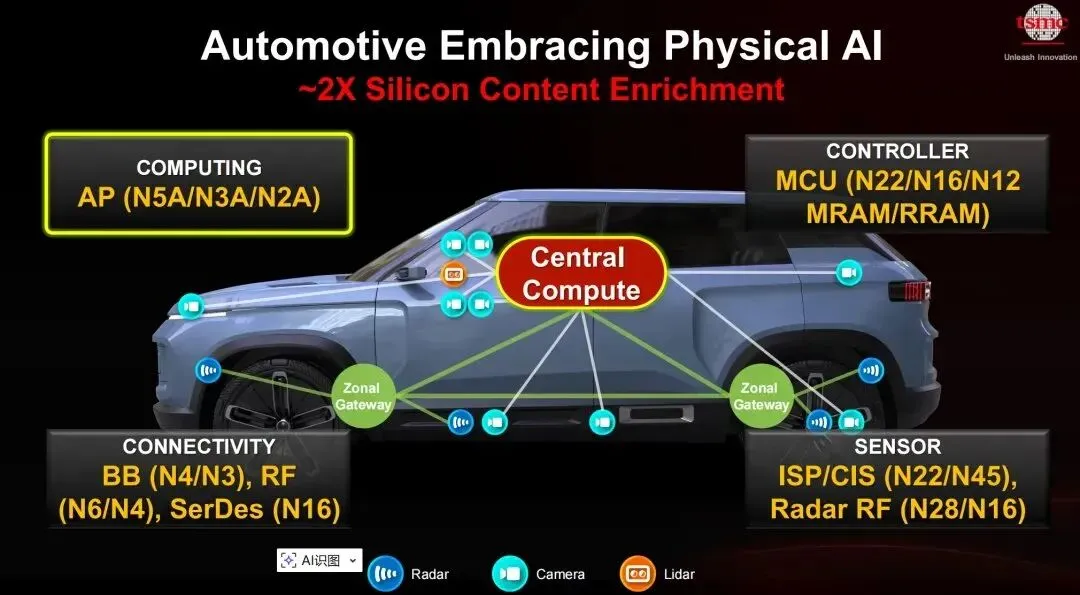
报告后半部分,把 AI 从数据中心延伸到了汽车和机器人。
在汽车领域,台积电提出 Physical AI,并指出汽车中的硅含量将提升约 2 倍。
简单说,汽车正在变成移动计算系统。
芯片需求不再只是 MCU,而是扩展到计算、连接、传感、控制、电源管理等完整系统。
在人形机器人部分,台积电把它拆成四个部分:
Brain,决策;
Sensing,感知;
Movement,运动;
Power,供能。
对应到芯片上,就是处理器、连接芯片、传感器、MCU、PMIC 等完整芯片体系。
台积电对人形机器人的定义是:
人形机器人 = Agentic AI + Physical AI。
简单理解,就是机器人不只是会思考,还要能感知环境、做出决策,并在真实世界里行动。
这意味着 AI 正在从“理解世界”,走向“参与世界”。
一旦 AI 进入汽车、机器人和工业场景,对算力、延迟、功耗和可靠性的要求都会明显提高。
云端 AI 可以慢一点,但机器人和自动驾驶不行。

所以,AI 越走向现实世界,半导体的重要性就越高。
当 AI 开始动起来,芯片就不只是成本,而是整个系统的生命线。
结语:AI越抽象,底层越具体
如果把整份报告压缩成一句话:
AI 竞争正在进入“系统级制造时代”。
第一,市场重心在迁移——HPC/AI 成为最大平台。High Performance Computing,即高性能计算
第二,技术路径在重构——制程、封装、堆叠、HBM、供电和互连,正在共同决定 AI 算力上限。
第三,应用边界在扩展——AI 正在从数据中心走向汽车、机器人和现实世界。
对行业来说,这意味着一个认知切换:
不要只盯模型和应用,真正决定胜负的,是底层算力系统。
那些不会出现在热搜里的东西——制程节点、HBM 数量、封装尺寸、互连密度、功耗曲线、良率和供应链——才是 AI 时代最硬的变量。
AI 越像魔法,半导体就越像现实。
最终赢的人,是最能把故事变成物理系统的人。
更多有价值美股、科技投资相关分析、具体操作,详见社群