 夜雨聆风
夜雨聆风
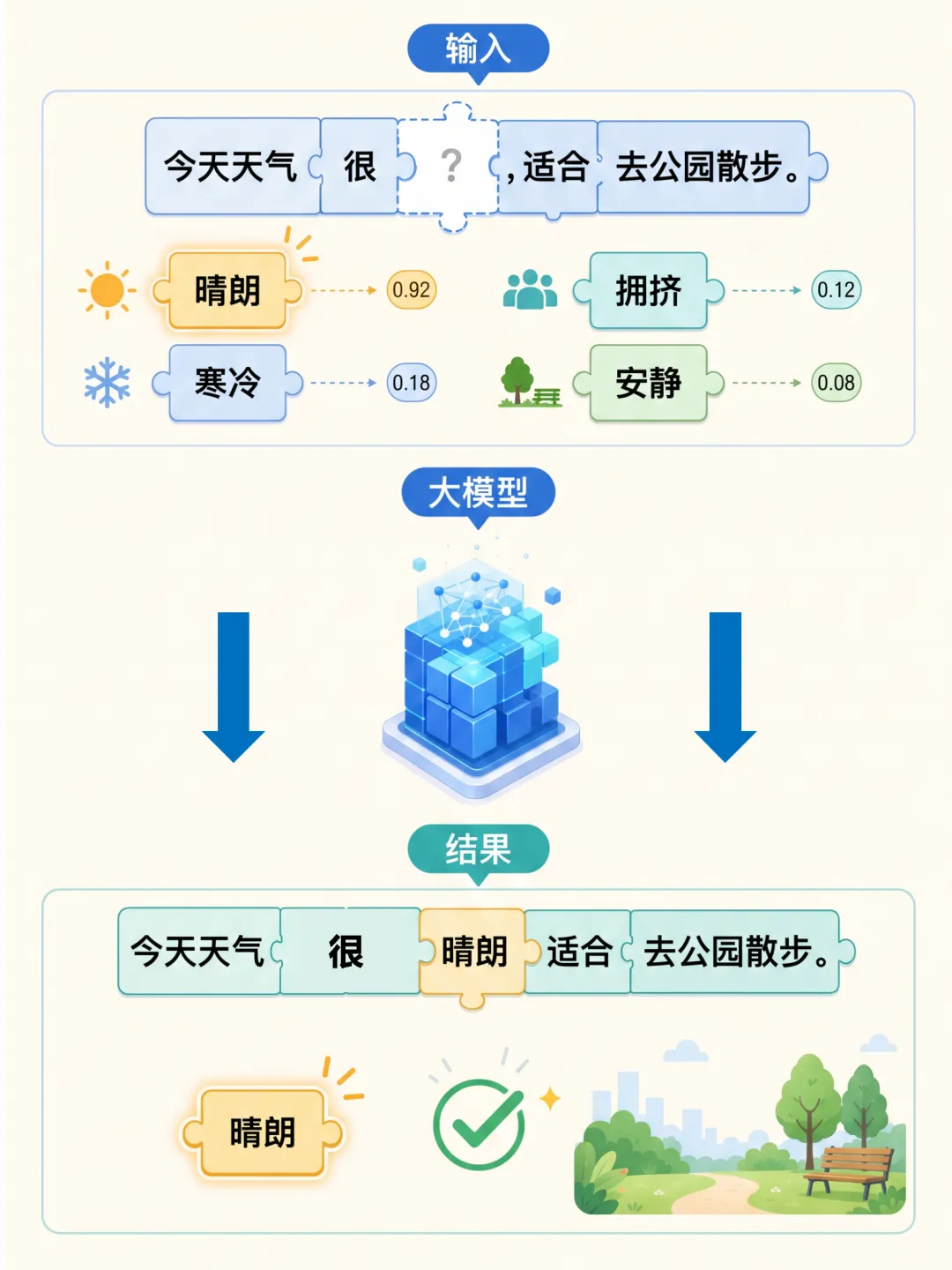
还记得被“英语完形填空”
支配的学生时代吗?
在看似随机的空格
和难分正误的答案选项中
我们逐渐学会了
一门外语的逻辑和语法

有趣的是
在大语言模型的训练过程中
核心方法之一
也是类似的“完形填空”
让模型“猜”句子中
被盖住的文字
进而理解和生成人类语言
如果把维度从语言世界
拓展到物理世界
有没有可能
也用“完形填空”的方式
让 AI 学习三维世界的
几何空间规律
构建更逼真的世界模型
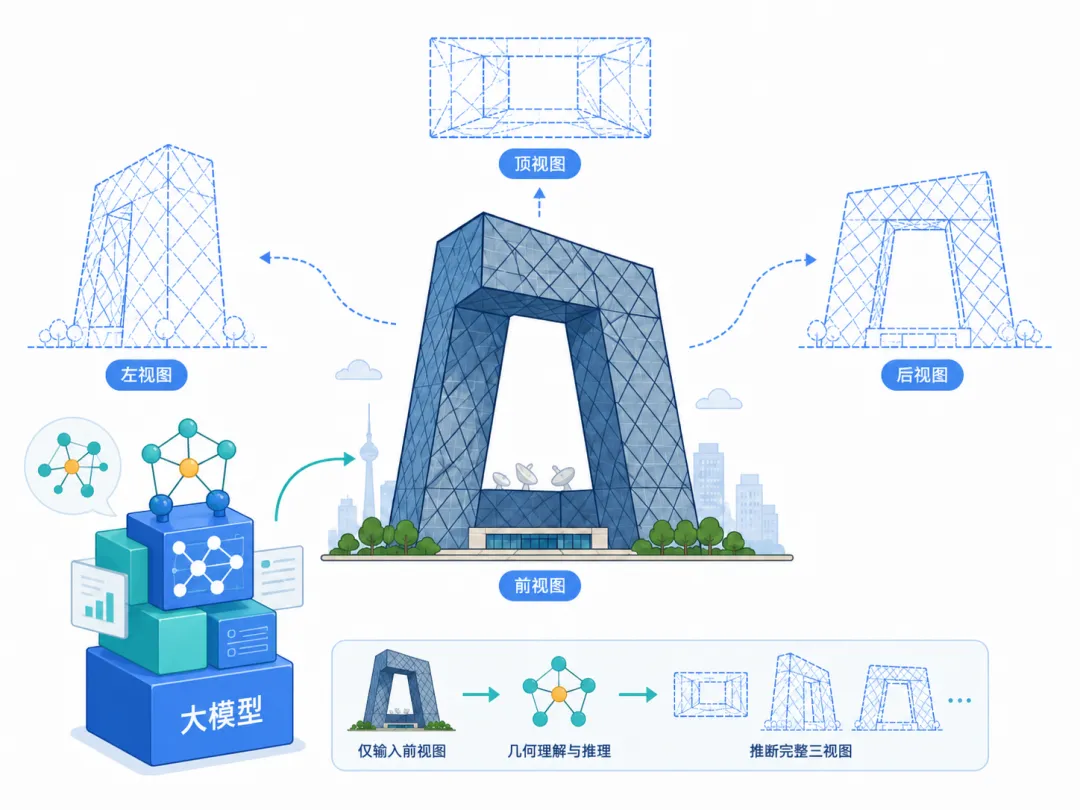
判断 AI 能否真正掌握三维视觉规律,“多视角生成”是一块关键试金石,比如给 AI 输入一个物体的正视图,让它去脑补生成左视图、右视图或其他任意角度的视图。
针对这样的任务,当前主流方法大概分为三派,但都存在局限性:
3D 重建派
先构建完整3D模型再渲染新视角,虽几何精准,但过程繁琐、效率低下。
相机参数派
生成时必须输入目标视角的精确数学方位参数,灵活性差,难以泛化。
图像编辑派
以“修图”思路去生成,一次仅能生成单一视角,效率低且误差易累积。
为了突破这些局限,中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授带领科研团队,基于智传网(AI Flow)理论,提出了一种新的世界模型生成框架 ViewMask-1-to-3。
它不依赖任何 3D 建模工具或几何先验知识,仅通过对 AI 进行“视觉完形填空”训练,便能实现高质量、高一致性的多视角图像生成。

既然 AI 能用“完形填空”(即掩码预测,Masked Language Modeling)学习语言规律,那能否用同样的方式让 AI 学会三维的视觉规律?
ViewMask-1-to-3的答案是:可以!
01
[ 第一步:拆词 ] .
研究团队以离散大语言模型为底座,用 MAGVIT-v2 视觉分词器,把图像压缩成一串“视觉词元”(token)。
02
[ 第二步:组句 ] .
将目标物体(如一把椅子)的前、后、左、右四个视图的所有词元,按顺序拼接成一个“视觉长句”。同时,将参考图与文本描述作为前缀加入,提供上下文。
03
[ 第三步:猜词游戏 ] .
在训练中,随机“盖住”(掩码)目标视角的部分词元,让模型根据上下文(参考图、文本及其他可见视角)来预测被遮住的内容。
通过海量的随机掩码与双向注意力学习,模型在“残缺信息”中学会了补全,深刻理解了何为“跨视角一致性”。
此外,在模型训练过程中,其多模态理解与生成的能力也得到进一步提升。
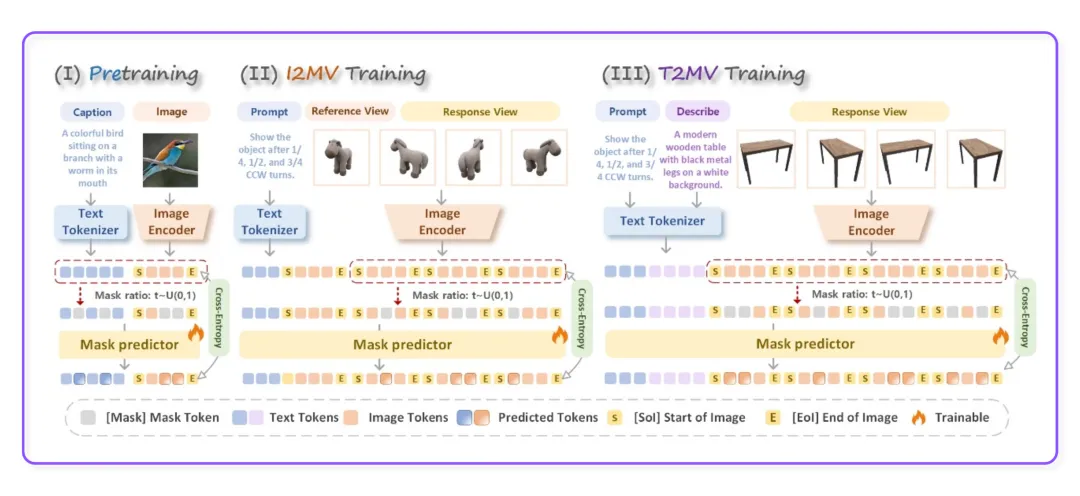
1
预训练阶段
团队用 120 万张图文对,让模型学会把"文字 token"和"图像 token"映射到同一套空间里,互相对齐。
2
图生多视角(I2MV)
将一张参考图,随机遮住目标视角的部分 token,让模型预测。
3
文生多视角(T2MV)
没有参考图,只给文字提示,随机遮住所有视角的部分 token,让模型预测 4 个不同角度的图像。
模型在推理时,将待生成的目标视角全部遮蔽,模型逐步预测、还原,再依据置信度对低把握的位置重新遮蔽,直到所有视角清晰浮现。
这与 TeleAI 团队长期研究的“正激励噪声”(Positive-incentive Noise,Pi/π-Noise)理论一脉相承:精心设计的噪声不是干扰,反而驱动着模型不断优化。

在 GSO 和 3D-FUTURE 两个标准测试集上,ViewMask-1-to-3 在图像质量、几何一致性等关键指标上均超越 Zero-1-to-3、ViVid-1-to-3 等主流基线模型。
在生成效率上,其优势尤为显著。zero-1-to-3 需要 2.66 秒/视角,ViVid-1-to-3 需要 5.99 秒/视角,AR-1-to-3 需要 5.35 秒/视角,而 ViewMask-1-to-3 只需 1.28 秒/视角——快了约 2-4 倍。
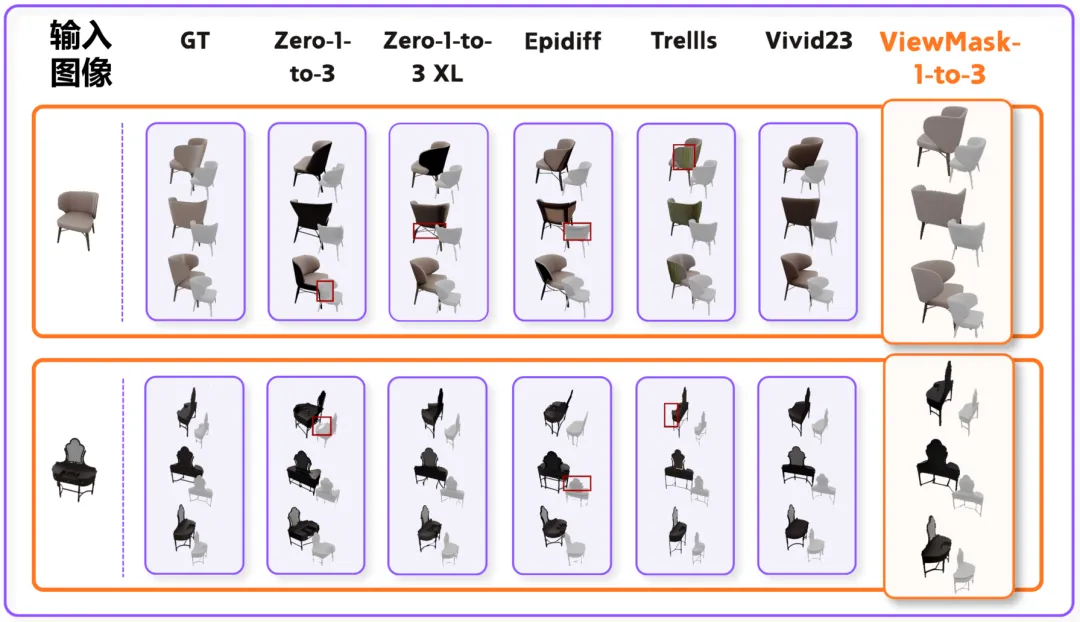
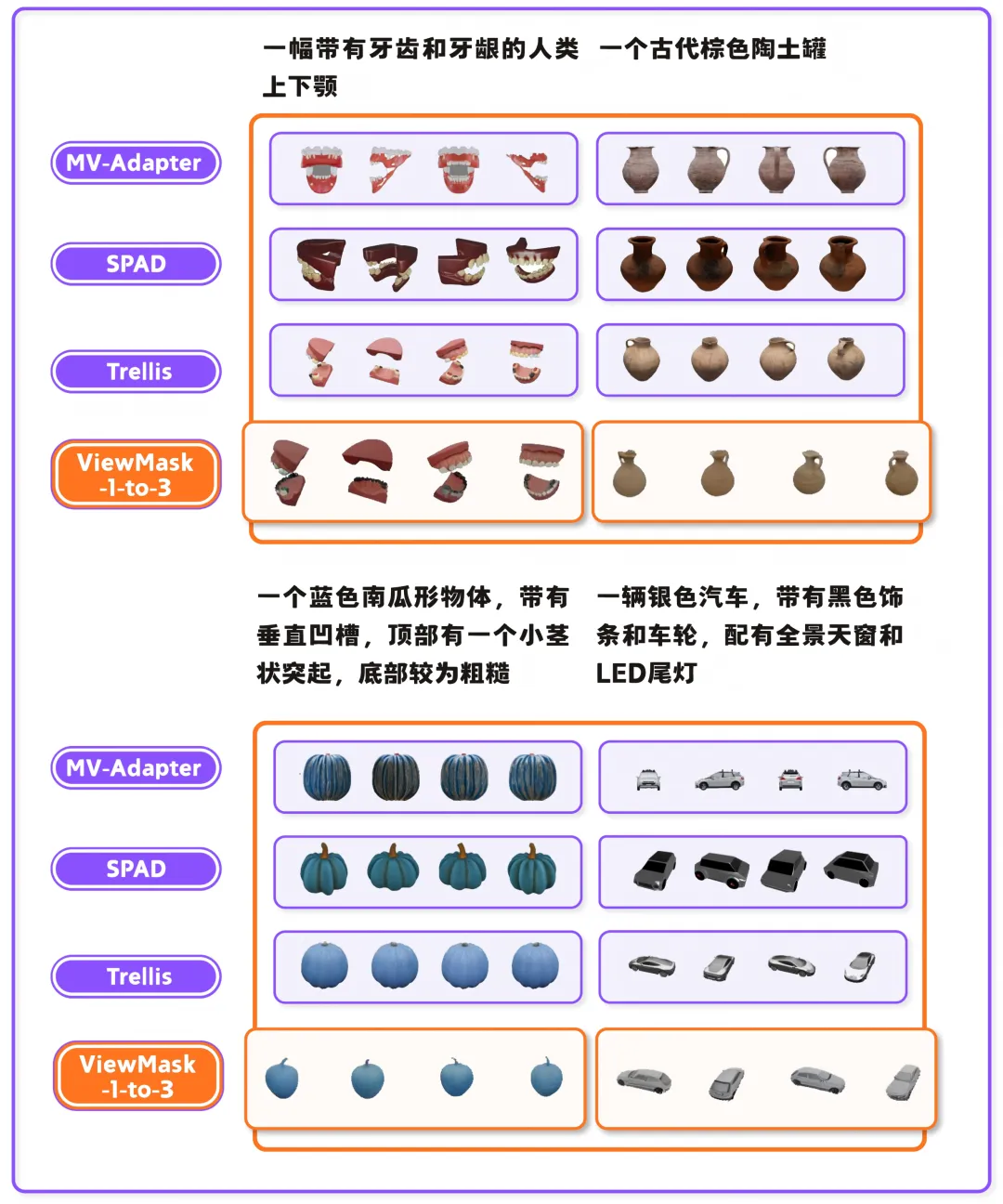
在能力泛化上,ViewMask-1-to-3也展现了出色的潜力。
规模可扩展
从 4 视角扩展到 6 视角、8 视角,只需约 9k 步微调,且性能几乎不变。8 视角甚至超出了原本训练时的最大序列长度,模型仍能稳定泛化——说明这套"完形填空"范式具有天然的扩展性。
能力可扩展
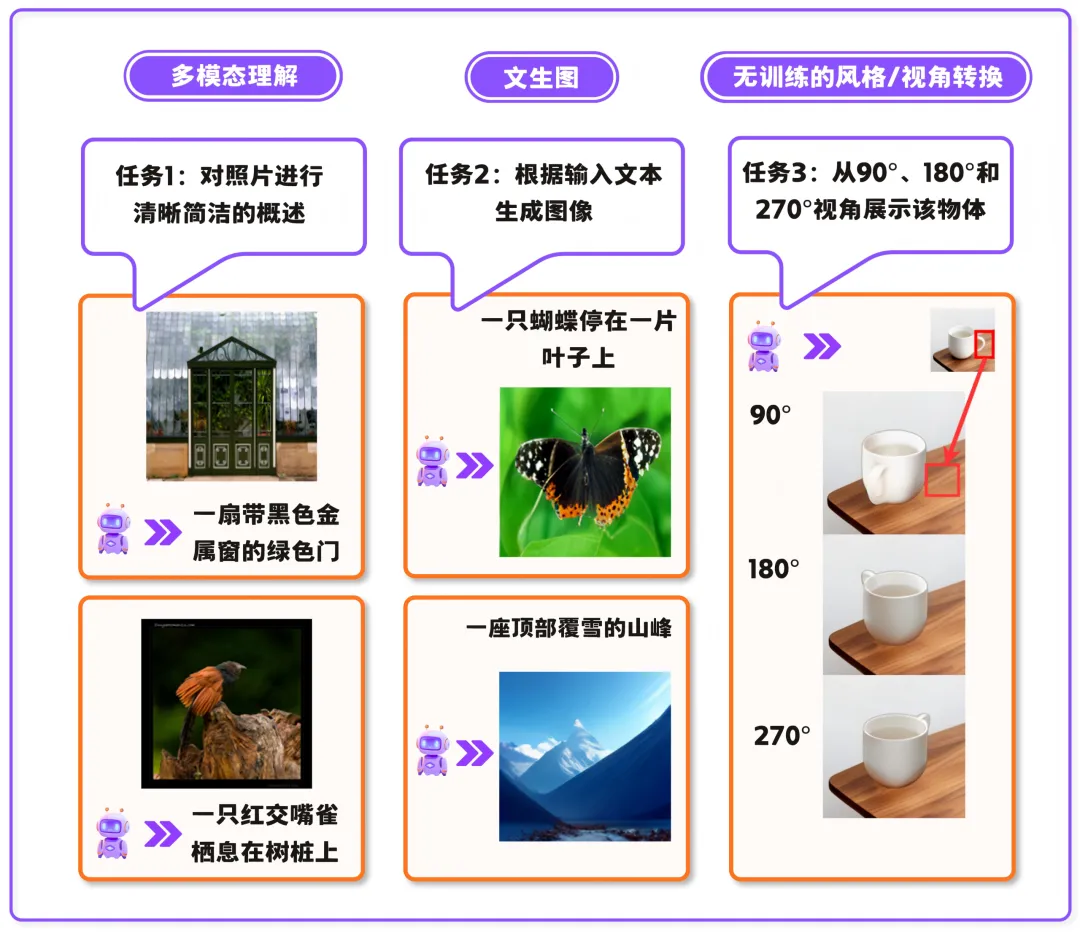
由于底座是统一的离散扩散框架,ViewMask-1-to-3 的能力边界远不止于多视角生成,模型本身即可做到图像补全与"指哪转哪"(结合 SAM 对画面中指定物体旋转视角);稍加数据微调,多模态理解、文生图同样信手拈来。
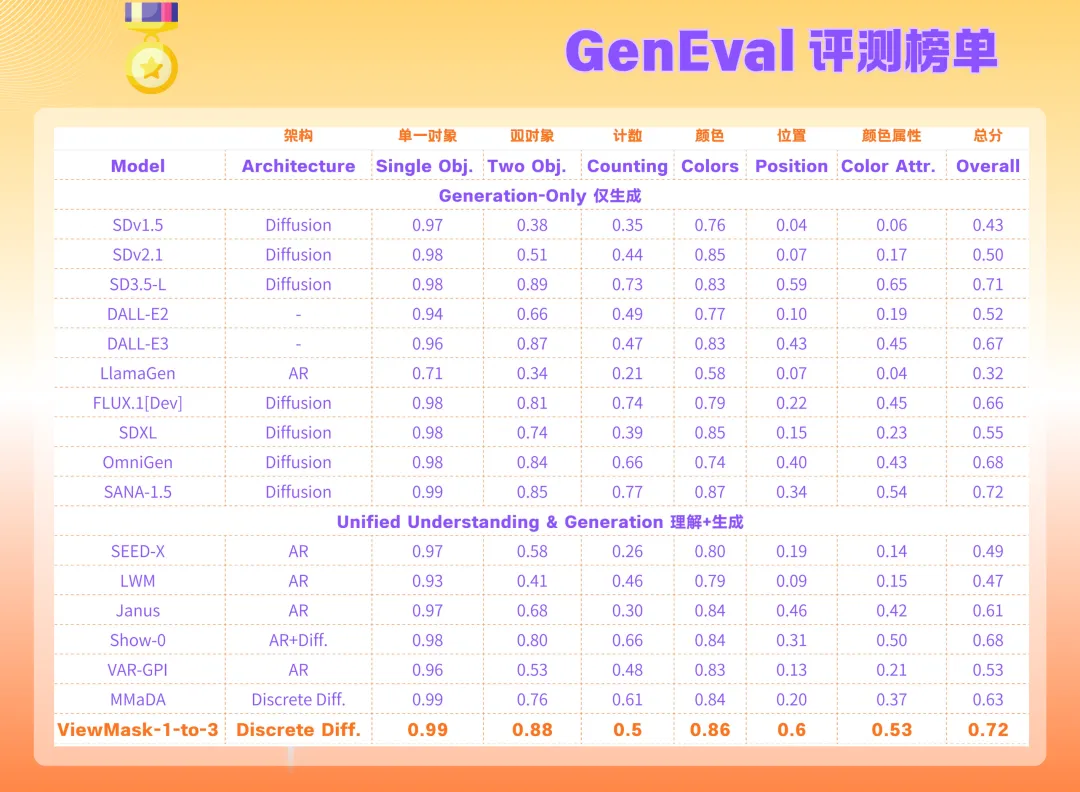
在文生图任务的评测榜单 GenEval 上,ViewMask-1-to-3 拿到了 0.72 的综合分,超越专门做图像生成的 SD3.5-L,比同类型统一模型 MMaDA(0.63)高出 0.09。
ViewMask-1-to-3
摆脱了复杂 3D 先验的依赖
架构更简洁、更优雅、更有效
它将立体的视觉与线性的语言
统一在同一套“词汇表”中
不仅为 AI 领悟三维空间的深层规律
提供了创新的学习方法
更为世界模型的落地
开辟了一条全新的路径
从机器人对环境的几何理解
到 VR/AR 内容的自动生成
乃至电商商品的全视角展示
或者游戏资产的快速构建
……
这项“完形填空”式的训练方式
正在为更高效、更通用的
人工智能应用落地
打下更坚实的基础
One More Thing
ViewMask-1-to-3 相关研究成果
已被人工智能领域顶会 ICML 2026
正式收录
相关工作

R. Zhu, Z. Huang, J. Sun, P. Luo, H. Zhang, X. Li*, “ViewMask-1-to-3: Multi-View Consistent Image Generation via Multimodal Diffusion Models”, ICML 2026, arXiv:2512.14099.
J. Shao and X. Li*, "AI Flow at the Network Edge", IEEE Network, vol. 40, no. 1, pp. 330-336, Jan. 2026, doi: 10.1109/MNET.2025.3541208.
H. An, W. Hu, S. Huang, S. Huang, R. Li, Y. Liang, J. Shao, Y. Song, Z. Wang, C. Yuan, C. Zhang, H. Zhang, W. Zhuang, X. Li*. "AI Flow: Perspectives, Scenarios, and Approaches", Vicinagearth 3, 1 (2026).

