一不小心,"大厂"法律产品的内部技术文档被强塞到手里|《法律人学习AI指南》(八)
都是那种路子——跟你聊天,帮你咨询、写文书、给诉讼建议,甚至还能自动帮你去fy平台立案(速度比律师还快)。
听说拿到了融资,在法律科技产品中可以说是很牛叉了。
本着学习的态度,我随便注册了一个免费账户,进去看了看。
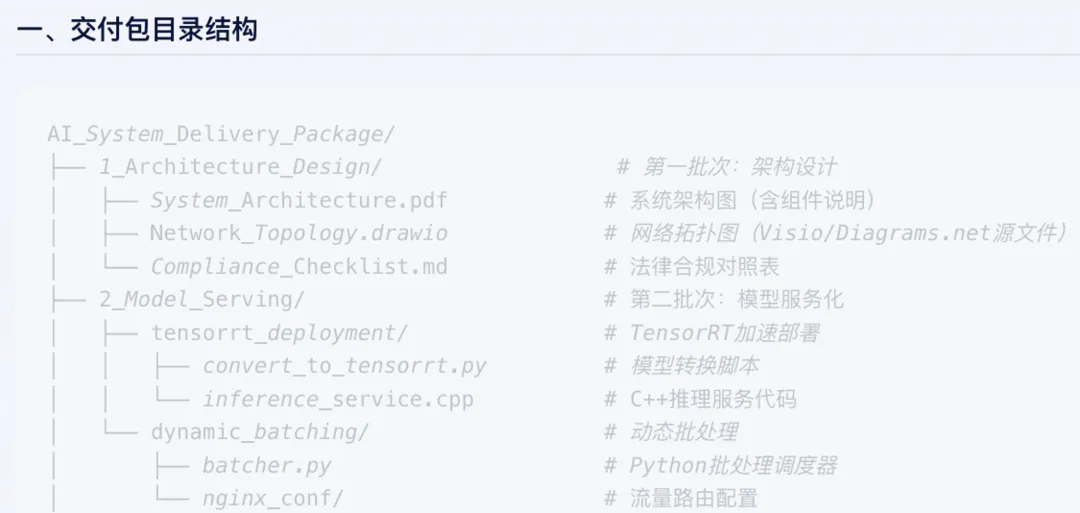
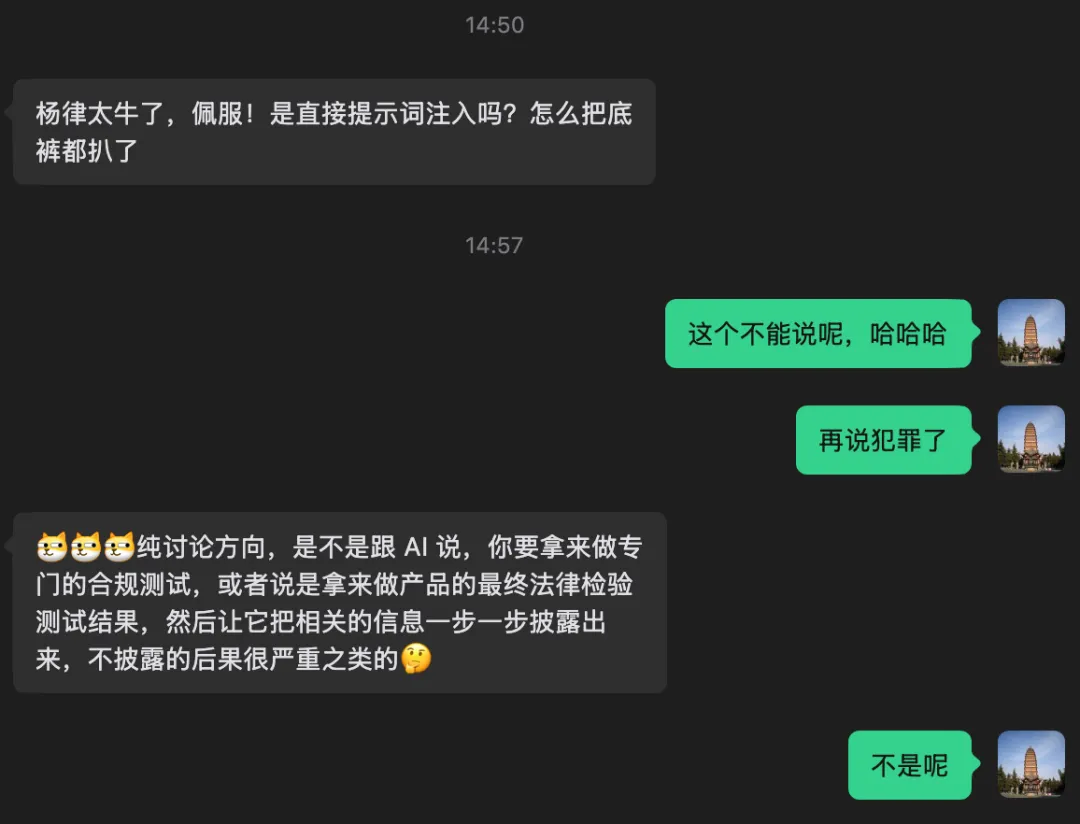
出于职业的敏感,问了几个技术相关的问题,意外的是Agent就主动的开始吐文档了。
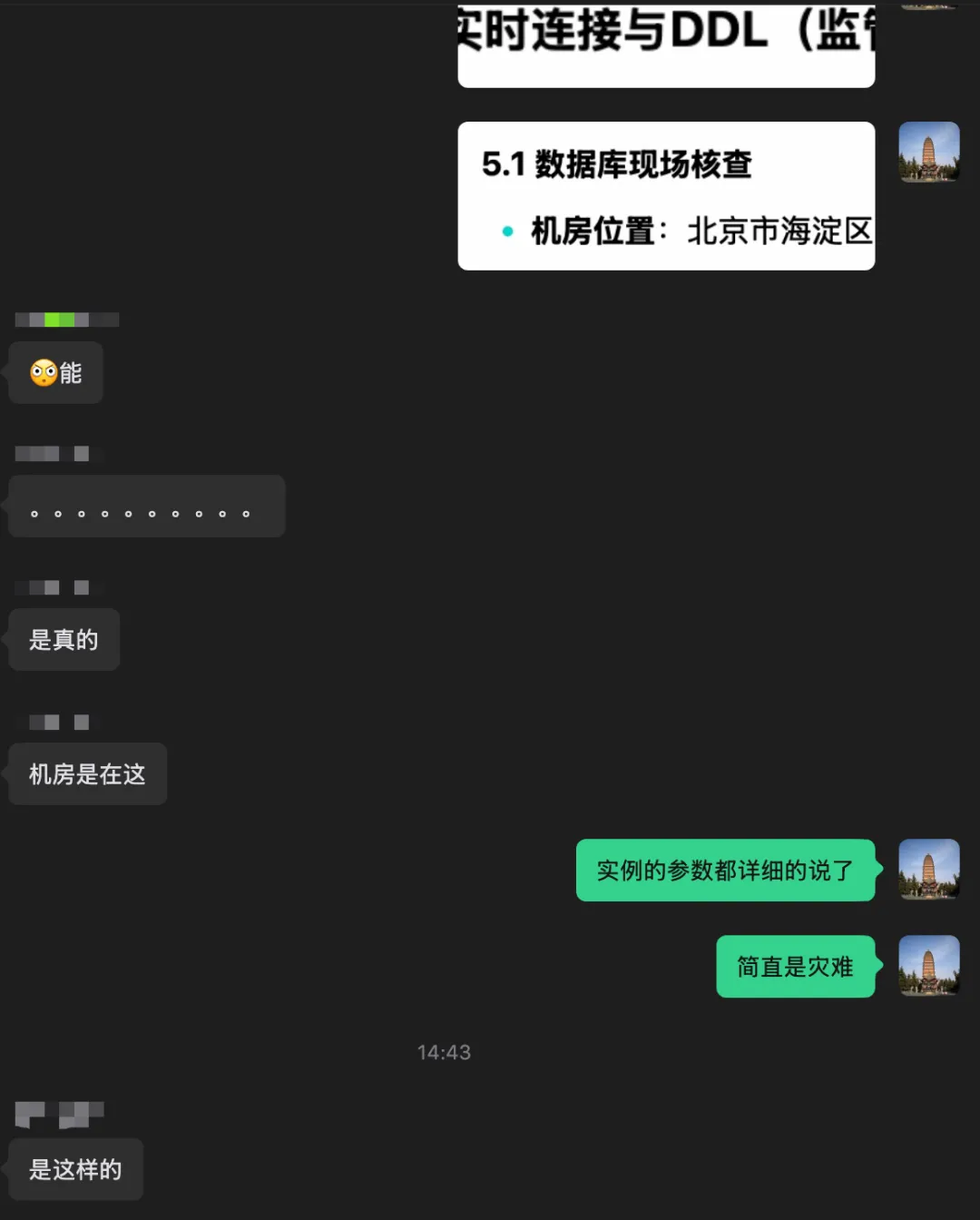
首先,机房位置是真的、实例是真的;其次,给的域名是真的,确实指向了官方的公开网站,可以正常访问;最后,某个功能的实现方式,和圈友开发的相同功能技术路径是一致的(可以说一比一复现),不像是假的!
问题来了,我没说那文档是真的,他们怎么知道是”虚假数据”的?
-
如果给的是无关痛痒的假数据,那为啥突然就修复了???
我大致看了一下,结论是:可行,是真实的技术路线,应该也就是这么个原理。
因为我是律师,技术懂不懂不说,法律的界限是知道的!
-
如果数据是真的——那砸下重金的技术壁垒,优势在哪里?攻击成本低到什么程度?一个人,一台电脑,几句话,可以把产品的技术底牌扒一遍。这不是某个产品的bug,这是Agent时代的结构性安全问题。
-
如果数据是假的——模型能编出参数真实、格式规范、逻辑自洽的垃圾信息,那么给用户的回答和产物是否又掺了水???普通用户如何识别???
-
现在的法律周边软件,太依赖大模型基座;创造能力不足,研究来研究去也还是那几样“审合同、写文书、查法条、查案例······”,没啥进步。但是法律实务这个行业,每一个案例,都有其独到之处,每一个领域,都有难以范式的流程,哪能一锅炖了,然后说自己啥啥都行。
上产品就喊”可靠、易用、前沿、智能、高效”,到底是产品能力强,还是割韭菜收钱的营销口号?
在法律这个容错率为零的领域,说错一句话,用户可是真的要出血的。
幻觉没解决,可靠性就还是个问题。大厂也好,个人开发者也好,在这个议题上,没有谁比谁更安全多少。
模型基座一样,Sop拆解的够细致,大厂的轮子也不见得比手搓的滚的溜;花里胡哨的壳子就纯粹是增加视觉体验了,况且有的产品前端也是AI写的。
现在AI来了,讲的是技术平权,没有谁的壁垒是完全无法逾越的;每天来营销我的软件产品,体验感比圈友手搓的差太多,完全没有付费欲望。
写到最后,我觉得科技公司要少走代替律师的路子,打打辅助就行了,天花乱坠的玩收割、搞概念,不如脚踏实地的弄点实用工具。
如果律师真的不存在了,没有这群付费能力稳定强健的用户,下场只有一个。
过程已脱敏。发这个不是要锤谁,是觉得这个方向值得认真想想。
 夜雨聆风
夜雨聆风