 夜雨聆风
夜雨聆风





基于 Claude Code 源码:我是如何打造自己的 AI 智能体 Harness 的
Anthropic 刚刚教会了你如何构建最好的 AI Agent harness。Claude Code 的源码就摆在那里:55 个目录,331 个模块,当今生产环境中经过最多实战检验的 Agent harness。
我拆解了每一个文件。每一个架构决策。每一条重试路径,每一个压缩策略,每一个权限阶段。
这不是一次拆解,而是一份蓝图。以下是其中的每一条原则,以及如何利用它们构建一个能在生产环境中存活的框架。
Claude Code 的架构揭示了业界最受欢迎框架的什么
你听过这三层:模型权重、上下文、框架(harness)。业界在每场会议、每个教程、每个框架的 README 中都在重复它们。
-
模型权重:冻结的智能,你通过 API 调用的东西。 -
上下文:提示词、对话历史、检索到的文档。 -
框架:模型周围的脚手架。工具、循环、错误处理。
这个框架到目前为止是正确的。Princeton NLP 的 SWE-agent 论文表明,仅仅改变接口设计,就在 SWE-bench 上获得了 64% 的相对提升。同样的 GPT-4,同样的任务,只改变了环境。性能提升存在于第 2 层和第 3 层,而非第 1 层。
然后你打开 Claude Code 的源码,意识到 Anthropic 不是在为模型构建,而是在为系统构建。
在 Claude Code 内部,一个四层 CLAUDE.md 层级让企业管理员通过 MDM 执行策略,项目维护者设定约定,个人开发者在本地覆盖。一个基于磁盘的任务列表配合文件锁,防止并行子 Agent 互相损坏状态。Git worktree 隔离让五个 Agent 在同一个仓库上拥有五个分支,零冲突。一个权限管道从企业到项目到用户到会话级联拒绝规则。
这些都不是框架。这些都不是上下文。这些都不是权重。这是基础设施:多租户、RBAC、资源隔离、状态持久化、分布式协调。
真正的框架有四层:
-
模型权重:冻结的智能。 -
上下文:运行时输入。 -
框架:Agent 的设计环境。 -
基础设施:多租户、RBAC、资源隔离、状态持久化、分布式协调。
大多数团队只谈论前三层,因为它们很有趣。第四层才是产品死亡的地方。
Claude Code 是我见过的第一个认真对待所有四层的 Agent 系统,架构在每个层面都体现了这一点。
核心 Agent 循环:异步生成器,而非 While 循环
Claude Code 的核心在 query.ts 中:1,729 行 TypeScript。最重要的决策在函数签名中:
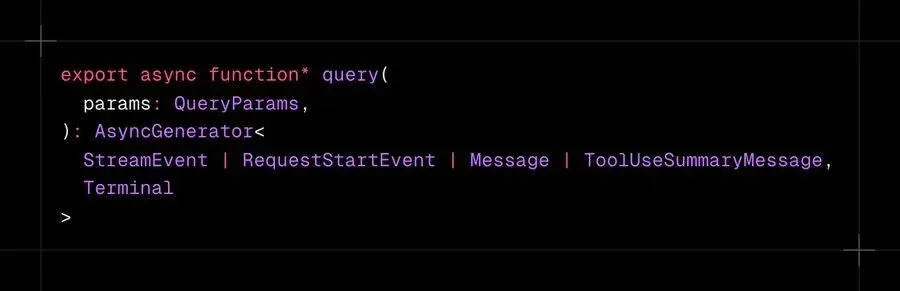
那个 function* 承载的分量比看起来要重得多。异步生成器随时间产出值,按需暂停,并允许任何调用者在任何时刻退出。
Agent 循环不是请求-响应周期。它是一个长时间运行的、流式的、可取消的进程。生成器无需额外附加就赋予了你所有这些属性。
对比大多数教程教你的:
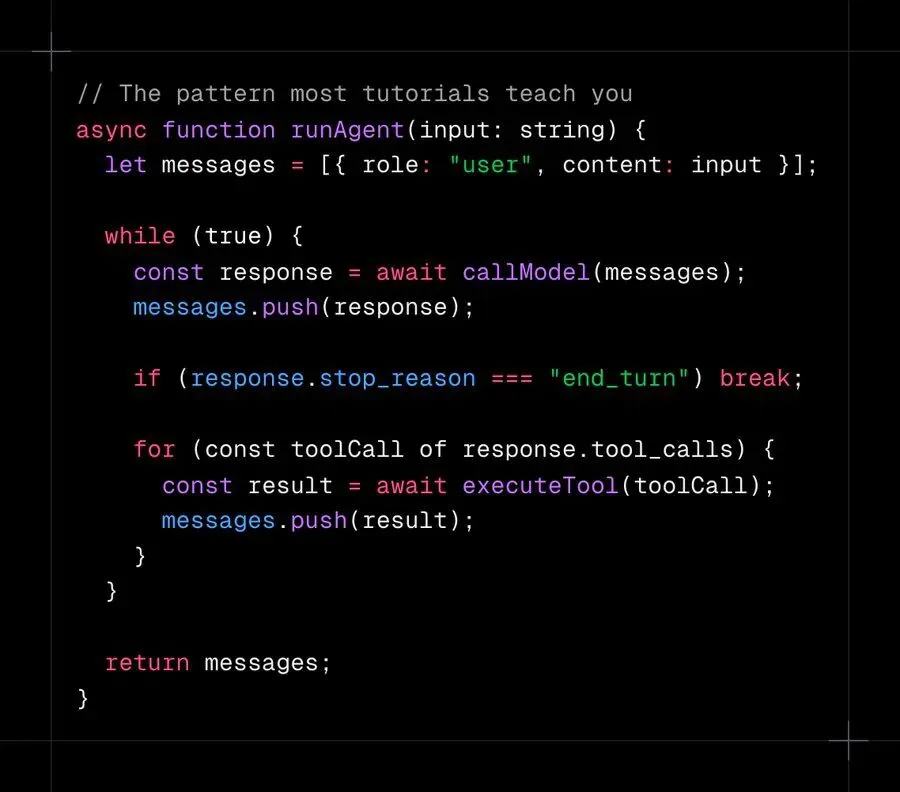
这在教程中能工作。在生产环境中会因为五个原因崩溃:
-
没有流式输出。 用户在模型生成时盯着空白屏幕 10-30 秒。Claude Code 的生成器随着 token 到达产出
StreamEvent对象。用户逐字符看到模型在工作。能看到 Agent 在做什么的用户更信任它。更信任的用户给它更多自主权。自主权是有用工作发生的地方。 -
没有取消。 While 循环版本中的 Ctrl+C 需要从外部接入单独的中止机制。使用生成器,调用者停止调用
.next()即可。finally块运行,清理发生。Claude Code 在每一层都穿过了AbortSignal,生成器让这变得自然。 -
没有可组合性。 REPL UI 消费生成器。子 Agent 消费它。测试消费它。一个
query()函数,三个调用者,零重复。生成器是流式数据的通用接口。 -
没有背压。 如果模型生成速度比终端渲染快,while 循环会把所有内容缓冲在内存中。生成器在消费者停止拉取时暂停生产。在长会话中,这个差异决定了内存是保持有界还是增长到进程死亡。
-
循环内没有错误恢复。 这是关键所在。
每次迭代的五个阶段
Claude Code 的 Agent 循环每次迭代运行五个阶段。这些阶段是框架具有弹性的原因。
阶段 1:设置
在调用模型之前,循环应用工具结果预算,如果对话很长则运行压缩策略,并验证 token 计数。大多数框架将原始消息数组传给模型然后祈祷不出问题。
阶段 2:模型调用
循环通过依赖注入接口调用 queryModelWithStreaming(),包装在一个处理十种错误类的重试系统中。流式工具执行器在模型完成生成之前就开始执行工具。一个 Grep 调用在其输入 JSON 在流中完成的瞬间就开始运行,比下一个工具调用开始到达还早几秒。
阶段 3:错误恢复与压缩
模型响应后,循环检查可恢复的错误。prompt-too-long?压缩并重试。max_output_tokens 达到上限?从 32K 升级到 64K 并重试。上下文溢出?对媒体密集的消息运行反应式压缩。这些是循环状态机中的一等状态,不是外部 try-catch 块中的边缘情况。
阶段 4:工具执行
尚未被流式执行器执行的工具在这里运行。结果在完成时产出给 UI。Haiku 异步生成工具使用摘要,这样主模型不会在簿记上消耗 token。
阶段 5:继续决策
模型的 stop_reason 告诉循环是否需要更多工具调用。轮次计数器检查 maxTurns。钩子可以请求停止。中止信号被检查。如果继续,循环递增状态并返回阶段 1。
错误恢复存在于循环内部,而非周围。每个阶段知道什么可能出错,并有特定的恢复路径。这就是一个在速率限制时崩溃的 Agent 和一个退避、重试、回退到不同模型并继续工作的 Agent 之间的区别。
依赖注入使其可测试
循环通过 QueryDeps 接口接收其依赖:
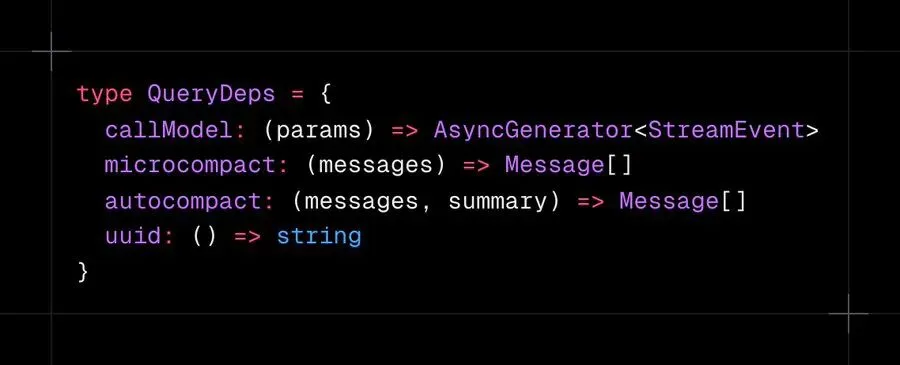
注入一个产出预设事件的 mock callModel,你就可以验证上下文溢出处理、工具失败和取消,而无需触碰真实 API。大多数 Agent 框架不可测试,因为它们将 API 调用硬编码到循环中。Claude Code 的循环是一个带有注入效果的纯状态机。
工具执行:为什么并发分类改变一切
Claude Code 内置 45+ 个工具。数量不是重点。执行方式才是。
大多数 Agent 框架逐个运行工具:模型生成工具调用,框架顺序执行,结果返回。安全但慢。有些框架并行运行工具。快但危险:两个并行写入同一路径的文件会损坏它。
Claude Code 按并发行为对每个工具进行分类:
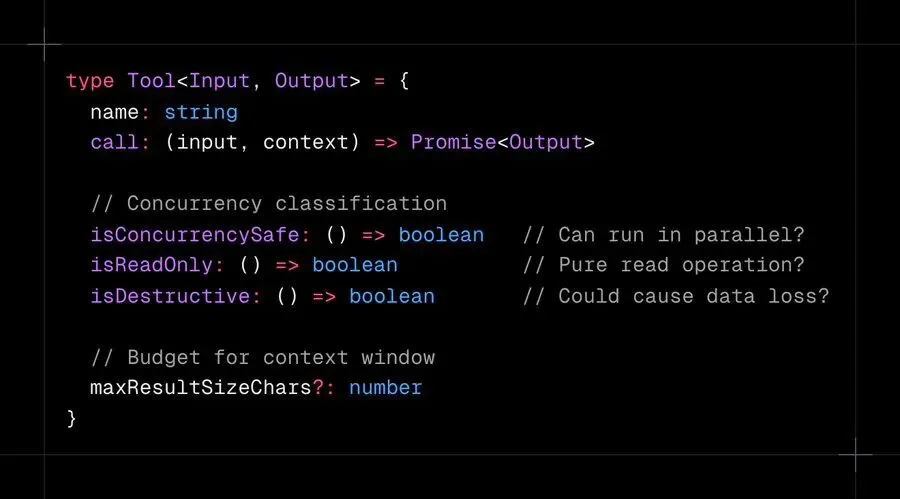
toolOrchestration.ts 中的编排层将工具调用分区为批次。只读工具(Glob、Grep、Read、WebFetch)并发运行,最多 10 个并行。写入工具(带变更的 Bash、Edit、Write)串行运行。没有竞态条件。
Claude Code 并行搜索五个文件,然后编辑一个。并行性的速度和串行执行的安全性,同时拥有。多工具轮次上 2-5 倍加速,每个会话累计节省数分钟。
流式工具执行器
StreamingToolExecutor 是更有趣的组件。大多数框架等待模型完成生成后才执行任何工具。Claude Code 在流中间开始执行。
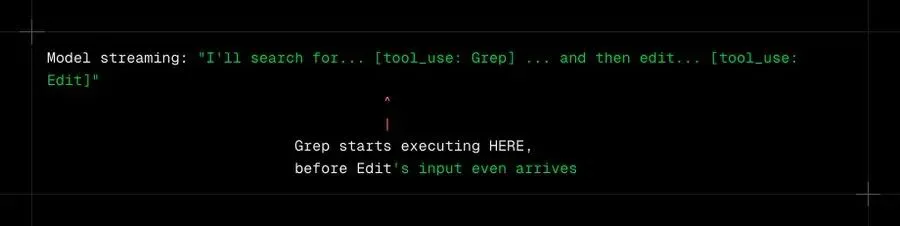
对于包含三个工具调用的轮次,这隐藏了 2-5 秒的延迟。模型在第一个工具已经运行时生成下一步的描述。到模型完成时,早期工具的结果可能已经在等待了。
困难的情况也被处理了:
-
如果并行批次中的工具失败,每个工具的 siblingAbortController会杀死兄弟进程。父查询控制器保持存活。对话继续。模型收到错误并恢复。 -
如果流失败并回退到非流式,执行器丢弃排队的工具并为进行中的任何工具生成合成错误结果。 -
结果按原始顺序产出,即使工具 2 在工具 1 之前完成,保持对模型和用户的叙事连贯性。
工具结果预算
一个输出 1MB 日志的 Bash 命令如果原样传给模型,会用垃圾填满上下文窗口。Claude Code 运行一个预算系统:
-
每个工具指定 maxResultSizeChars。超过限制的结果持久化到磁盘。模型收到文件路径引用加上前 N 个字符的预览。 -
applyToolResultBudget()在每次 API 调用前运行,约束总工具结果 token。
用户会对巨大文件运行 cat。他们会管道产生兆字节输出的命令。没有预算,上下文会被噪音填满,Agent 失去连贯性。这个细节不会出现在架构图中。它决定了 Agent 是否能在真实使用中存活。
大规模提示词工程:系统提示词是一个缓存问题
Claude Code 中的系统提示词不是一个字符串。它是一个带有缓存元数据的结构化节数组。
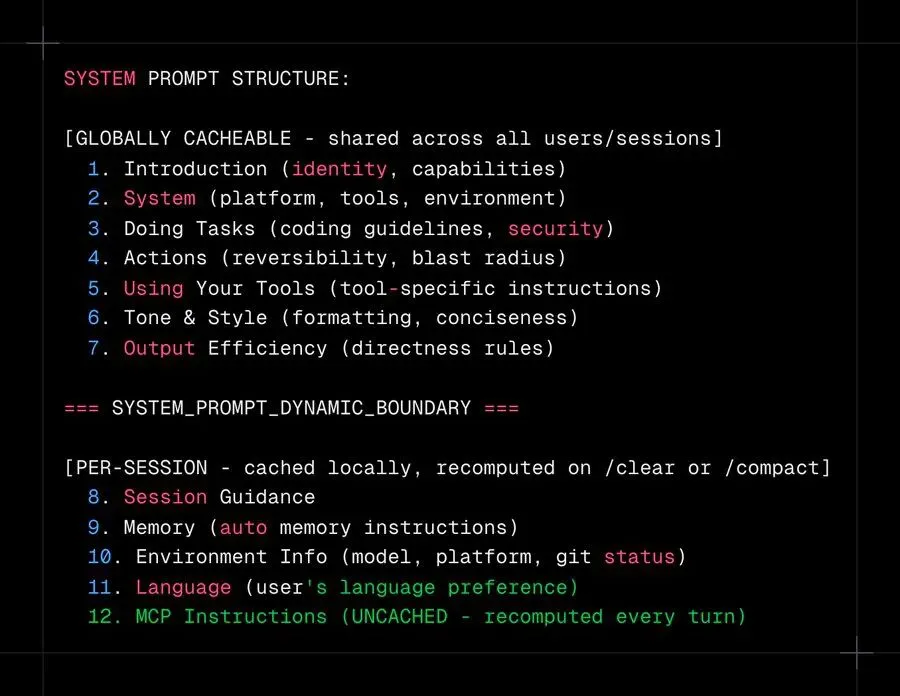
SYSTEM_PROMPT_DYNAMIC_BOUNDARY 标记将提示词分为两个区域。它上面的所有内容:在所有用户、所有会话中完全相同,在 API 层全局命中提示词缓存。这大约是提示词的 ~80%。你不需要在每次 API 调用时为每个用户重新 tokenize 577+ 行。
边界以下,节被记忆化(每个会话计算一次)或易失(每轮重新计算)。易失节被最小化,因为每次更改都会破坏其后所有内容的缓存。
没有我遇到过的 Agent 教程、框架文档或会议演讲讨论过为缓存效率设计提示词。这是代码库中最高杠杆的决策之一。在规模上,这决定了你的 Agent 每个会话花费 0.20。
CLAUDE.md 层级
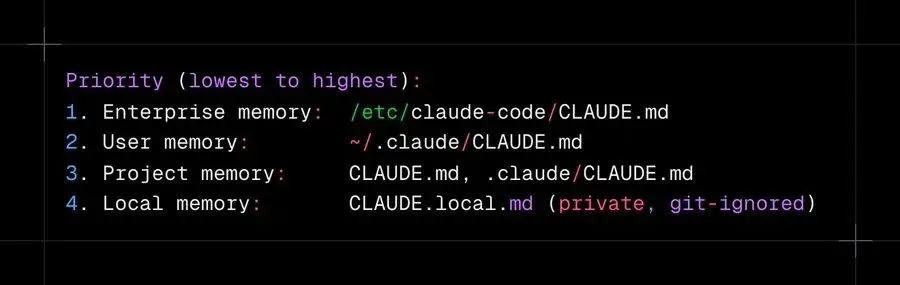
四层指令层级充当可组合记忆:
-
企业级 /etc/claude-code/CLAUDE.md— 组织级编码标准 -
项目级 .claude/CLAUDE.md— 项目约定 -
用户级 ~/.claude/CLAUDE.md— 个人偏好 -
本地级 CLAUDE.local.md— 私有覆盖(不入版本控制)
更高级别覆盖更低级别。企业管理员全组织强制执行编码标准。用户设置个人偏好。项目定义约定。开发者将私有覆盖保持在版本控制之外。
@include 指令启用组合:
@./docs/coding-standards.md
@~/shared-rules.md
企业级与 MDM(移动设备管理)集成以执行策略。这是基础设施工程,不是框架工程。
为什么上下文注入在系统提示词之外
用户上下文(git status、CLAUDE.md 内容、当前日期)作为第一条用户消息注入,包裹在 <system-reminder> 标签中:
<system-reminder>
As you answer the user's questions, you can use the following context:
# claudeMd
[CLAUDE.md 文件的内容]
# currentDate
Today's date is 2026-04-07.
</system-reminder>
上下文每轮都变。把它放在系统提示词中会使缓存在更改点之后失效。将它移到用户消息中使系统提示词逐轮保持缓存稳定。
小细节。显著的成本影响。
上下文窗口管理:四种压缩策略
大多数 Agent 框架在达到上下文限制时截断旧消息或崩溃。Claude Code 通过四种压缩策略支持无限对话长度,按从最便宜到最昂贵排序。
策略 1:微压缩(Microcompact)
每轮运行,在 API 调用之前。如果一个工具被调用且其结果自上次调用以来没有变化,系统用缓存引用替换完整结果。对于像 Read 这样对同一文件重复调用的工具,这每个会话节省数千 token。
成本:几乎为零。
策略 2:裁剪压缩(Snip Compact)
在接近 token 限制时触发,在昂贵的摘要之前。从对话开头移除消息,同时保留最近消息的”受保护尾部”。不需要模型调用。有损但快速。
策略 3:自动压缩(Auto Compact)
当 token 使用量超过阈值且裁剪不足时触发。一个单独的模型调用总结之前的对话。旧消息被替换为摘要。系统跟踪压缩状态以防止循环(对摘要的摘要再摘要)。
策略 4:上下文坍缩(Context Collapse)
对于长时间运行的会话,通过功能标志启用。多阶段分级压缩:先压缩工具结果,然后是思考块,最后是整个部分。昂贵的选项,保留给运行了数小时的会话。
为什么层级很重要
最便宜的策略先运行。最昂贵的只在其他方法都不行时触发。大多数实现压缩的框架直接跳到摘要。摘要消耗的 token 既有压缩调用本身,也有摘要本身。微压缩和裁剪以零模型调用处理了大量情况。
层级意味着你只在便宜压缩失败时才为昂贵压缩付费。
“受保护尾部”的概念也很重要。当压缩运行时,最近的消息永远不会被摘要掉。模型在最后 N 次交换上保持完全保真度,即使更早的上下文被压缩。模型可以跟进其当前计划而不会丢失它刚刚做了什么的追踪。
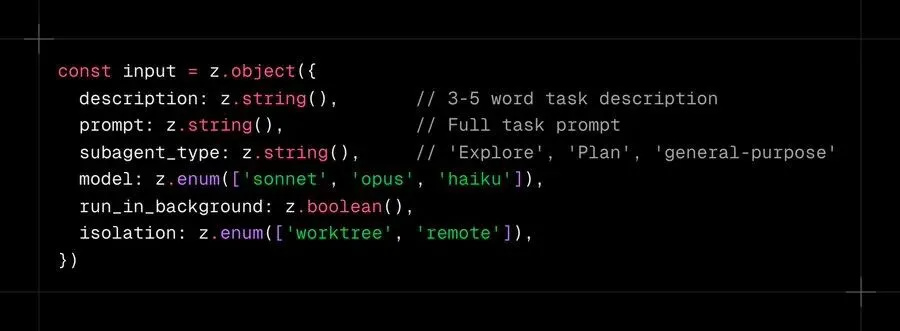
权限系统:信任的七个阶段
大多数 Agent 框架提供一个二进制开关:允许或拒绝。Claude Code 运行一个七阶段管道。

工具调用被请求。规则使用类似 glob 的模式匹配工具名称和输入:

Claude Code 的规则引擎恰好支持这一点。
权限模式创建渐进式信任:
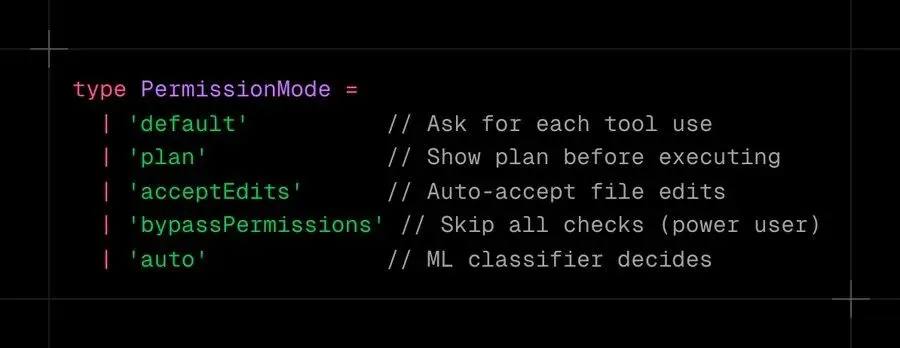
新用户从默认模式开始,批准每个操作。随着信心建立,他们转向 acceptEdits 或 bypassPermissions。不是安全与速度之间的二选一,而是一个光谱。
钩子作为逃生舱:
{
"hooks": {
"PreToolUse": [{
"matcher": {
"tool": "bash",
"action": ".*rm.*"
},
"commands": [{
"cmd": "/path/to/safety-check.sh"
}]
}]
}
}
你的脚本接收工具调用详情并返回 {"decision": "approve"} 或 {"decision": "block"}。组织构建自定义护栏:阻止破坏性操作、完成时发 Slack 通知、每次文件写入后运行 linter。无需修改源码。
错误恢复:823 行的重试系统
services/api/withRetry.ts 有 823 行。每一行都因为一次生产故障而存在。
-
429(速率限制):检查
Retry-After头。低于 20 秒?重试,保持快速模式。超过 20 秒?进入 30 分钟冷却。存在overage-disabled头?永久禁用快速模式,解释原因。 -
529(服务器过载):跟踪连续 529 计数。连续三次且有回退模型可用?切换模型。后台任务?退出以防止级联。前台?带退避重试。
-
400(上下文溢出):解析错误以提取实际和限制 token 计数。重新计算:
available = limit - input - 1000 安全缓冲。强制最低 3,000 输出 token。用调整后的预算重试。 -
401/403(认证):清除 API 密钥缓存。强制刷新 OAuth token。用新凭据重试。
-
网络错误(ECONNRESET、EPIPE、超时):禁用 keep-alive socket 池。用新连接重试。
退避公式:
delay = min(500ms × 2^attempt, 32s) + random(0, 0.25 × baseDelay)
对于无人值守会话(CI/CD 管道、后台 Agent),持久重试模式无限重试 429 和 529 错误。最大 5 分钟退避。6 小时重置上限。30 秒心跳发射防止空闲杀死。
流式层运行自己的可靠性机制:
-
空闲超时看门狗在 90 秒无数据块到达时中止流,45 秒时发出警告。 -
停滞检测记录首字节时间后连续数据块之间 30+ 秒的间隔。 -
流式回退在流式完全失败时切换到非流式请求,保留连续 529 计数,使回退逻辑不会重复计数。
三次重试的 fetch 包装器不是生产可靠性。一个理解每种错误类语义并为每种错误有特定恢复路径的状态机才是。
子 Agent 架构:隔离的并行性
Claude Code 生成子 Agent:Agent 循环的独立实例,每个都有自己的上下文、工具和工作目录。
每个子 Agent 获得隔离上下文:
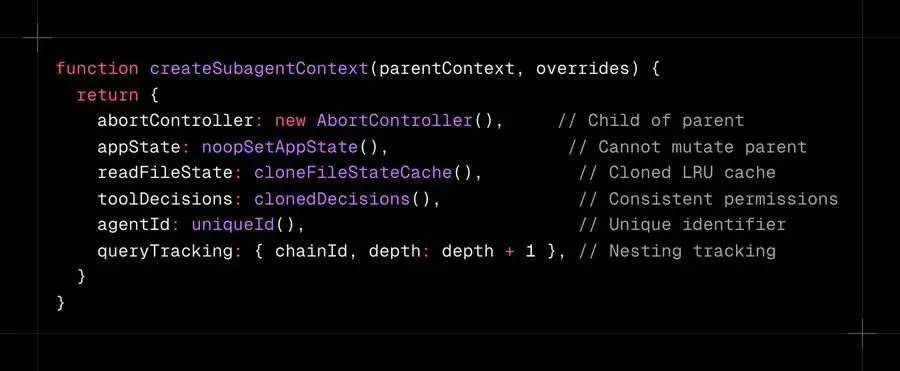
-
中止父级级联到所有子级。 -
但子级不能修改父级的状态: appState是一个空操作 setter。 -
文件状态缓存被克隆,防止一个 Agent 的读取污染另一个的缓存。
Git Worktree 隔离
修改代码的子 Agent 获得自己的 worktree:
getOrCreateWorktree(repoRoot, slug)
→ 验证 slug(最多 64 字符,无路径遍历)
→ 检查 worktree 是否已存在(快速恢复)
→ git fetch(带 no-prompt 环境变量)
→ git worktree add(新分支:worktree-<slug>)
→ 符号链接大目录(node_modules, .cache)
→ 复制 CLAUDE.md、项目设置、.env 文件
→ 返回 { path, branch, headCommit }
一个 Agent,一个 worktree。共享工作区的并行 Agent 会产生冲突。Worktree 隔离将每个 Agent 放在自己的分支上;更改在验证后合并。node_modules 符号链接防止磁盘膨胀:五个并行 Agent 不需要五份依赖副本。
三种生成后端
多 Agent 系统支持三种执行后端:
-
进程内(直接 Node.js,最快,共享内存) -
Tmux 面板(终端复用器隔离,每个 Agent 在自己的标签页中可见) -
远程(CCR 环境,完整机器隔离)
任务协调使用基于磁盘的任务列表,配合文件锁,位于 ~/.claude/tasks/<taskListId>/<taskId>.json。锁争用通过指数退避处理(30 次重试,5-100ms)。高水位标记防止重置后任务 ID 重用。
第四层:基础设施
以上所有描述的都是框架,第 3 层。现在看看 Claude Code 在其周围构建了什么。
多租户
CLAUDE.md 层级是一个多租户系统。/etc/claude-code/CLAUDE.md 中的企业策略适用于组织中每个开发者。.claude/CLAUDE.md 中的项目策略适用于贡献者。~/.claude/CLAUDE.md 中的用户偏好是个人的。CLAUDE.local.md 中的本地覆盖是私有的。
这是 Agent 行为的 RBAC。企业管理员设置护栏。项目维护者设定约定。开发者设置偏好。每一级覆盖下一级。冲突确定性解决。
跨会话状态持久化
压缩策略是状态持久化。自动压缩产生一个摘要,成为下一个循环迭代的起始上下文。CLAUDE.md 文件跨会话保留项目级记忆。钩子将任意状态持久化到磁盘。任务协调系统跨多个 Agent 进程维护状态。
Claude Code 在三个层面解决会话管理:会话内(压缩)、跨会话(CLAUDE.md)、跨 Agent(任务列表)。
资源隔离
Git worktree 隔离给每个子 Agent 自己的文件系统。siblingAbortController 包含工具故障使其不会级联到兄弟。企业级拒绝规则防止 Agent 触碰它们不应访问的资源。
分布式协调
任务列表上的文件锁是分布式协调。父子 Agent 之间的提示词缓存共享是分布式资源优化。持久重试模式中的心跳是保活模式。Worktree 管理处理并发 Agent 对共享仓库的访问。
这些是基础设施问题,有基础设施解决方案:锁、协调、隔离、状态管理、访问控制、资源共享。
为什么这对你的构建很重要
你会遇到这些每一个问题。问题是你用胶带解决它们还是从一开始就为它们设计。
三层模型没有为你做好准备。它将框架定义为天花板。但框架描述的是一个模型实例如何与一组工具在一个会话中交互。当你需要多个用户、多个会话、多个 Agent,或部署到你无法控制的环境时,你就进入了第 4 层。
分布式系统工程正在成为 Agent 构建者的核心能力。生产 Agent 系统运行在 CI 服务器上,生成子进程,跨会话共享状态,为不同权限的用户服务。理解这一点的团队构建出能工作的 Agent。停在框架层的团队构建的是演示。
可扩展性:四种机制,零源码修改
Claude Code 有四种扩展机制。都不需要修改源代码。
Skills(Markdown 文件作为命令)
---
name: commit
description: Commit staged changes with a generated message
allowed-tools: [Bash, Read, Grep]
model: haiku
context: inline
user-invocable: true
---
Review the staged changes and create a commit message...
带有 YAML frontmatter 的 Markdown 文件。五个来源:内置、项目、用户、插件、MCP。基于路径的发现意味着指定 paths: ["*.tsx"] 的 skill 只在 Agent 触及匹配文件时激活。Agent 看到相关的 skill,而不是所有 skill。
Hooks(事件驱动自动化)
六种类型:shell 命令、LLM 评估、Agent 验证、HTTP 端点、TypeScript 回调、内存函数。在 PreToolUse、PostToolUse、SessionStart、FileChanged、Stop 时触发。
钩子将框架连接到现有基础设施。任务完成时发 Slack 通知。每次 bash 命令前运行安全扫描。每次文件编辑后触发 CI。无需更改 Agent 循环。
MCP(模型上下文协议)
五种传输类型:stdio、SSE、HTTP 流式、WebSocket、进程内。在三个级别配置:企业管理、项目、用户。MCP 通过标准化协议让 Agent 访问外部系统(数据库、API、内部工具)。
Plugins
包含 skill、agent、hook 和配置的目录。顶层组合机制:添加能力而不触碰现有文件。
所有四种机制遵循同一原则:组合优于修改。通过添加扩展,而非更改。核心更新不会破坏扩展。扩展之间互不干扰。
UI 是信任机制
Claude Code 的终端 UI 运行在 Ink(终端的 React)的自定义分支上:251KB 的渲染引擎。对于 CLI 来说听起来很重。其实不然。
-
实时流式文本逐字符渲染。 -
动画旋转器根据停滞时长从正常色插值到错误红色。 -
Diff 渲染显示语法高亮、三行上下文、单词级变更标记。 -
多 Agent 状态树显示活跃 Agent 的层级。 -
六个主题包括色盲友好选项。 -
状态栏显示模型名称、美元成本、上下文窗口使用百分比、速率限制利用率。
能看到 Agent 在做什么、调用了哪个工具、结果长什么样、消耗了多少上下文、花了多少钱的用户,会给那个 Agent 更多自主权。更多自主权意味着更多有用工作完成。
UI 是力量倍增器。
上下文窗口使用条给用户一种剩余容量的直觉感受,无需理解 tokenization。当它填满时,他们知道该收尾或让 Agent 压缩了。
你从中带走什么
你不需要重建 Claude Code。你需要它背后的工程决策。
-
Agent 循环用异步生成器。 流式、取消、可组合性、背压:都是抽象固有的。返回完整结果的 while 循环放弃了所有四个。
-
工具的并发分类。 只读工具并行运行。状态变更工具串行运行。2-5 倍加速,零竞态条件。在定义时标记每个工具,让编排层处理批处理。
-
流式期间的工具执行。 增量解析工具调用。输入 JSON 完成的瞬间开始执行。每个多工具轮次免费的延迟节省。
-
为缓存边界设计的系统提示词。 静态内容在前。动态内容在后。边界显式标记。生产中最高杠杆的成本优化。
-
压缩层级,而非单一策略。 便宜优先(微压缩、裁剪)。昂贵最后(摘要、坍缩)。只在便宜压缩失败时为昂贵压缩付费。
-
错误恢复作为循环中的一等状态。 每种错误类型(速率限制、上下文溢出、认证失败、网络错误)在状态机内部有自己的恢复策略。不是外部的 try-catch。
-
从第一天起就考虑第 4 层。 跨会话状态存在哪里?权限如何扩展到团队?添加并行性时协调如何工作?改造基础设施比一开始就设计难一个数量级。
-
不需要代码更改的扩展点。 Markdown 文件、shell 脚本、基于协议的工具覆盖 95% 的扩展需求。如果用户 fork 你的代码来定制行为,你的架构有缺口。
模型是商品。环境决定结果。
Princeton NLP 用 SWE-agent 证明了:同样的模型,更好的环境,64% 的提升。Anthropic 用 Claude Code 每天证明:一个 55 目录、331 模块的 TypeScript 应用,将驱动聊天界面的同一个 Claude 模型变成了一个可以无人值守运行数小时、从 API 中断中恢复、跨千轮会话管理自己的上下文、并在同一代码库上协调多个并行子 Agent 的编码 Agent。
四层。业界大多数优化第 1 层:更大的模型,更高的基准分数。赢的团队投资第 3 和第 4 层。更好的环境。更好的错误恢复。更好的权限系统。更好的上下文管理。更好的协调。
源代码就在那里。模式已被记录。决策清晰可读。构建框架。然后在它周围构建基础设施。