 夜雨聆风
夜雨聆风





AI编程新范式| OpenSpec接入老项目完整实战+踩坑记录
用AI写新代码很爽,但如果你维护的是一个跑了三年的老项目,情况就完全不同了。
我遇到的问题大概是这样:
项目有十万多行Go代码,Gin + GORM + MySQL的技术栈,十几个业务模块交织在一起。
让它去改这样的老代码,就比较费劲,它会生成不同的代码风格、不同的接口调用方式,甚至还会顺手帮你优化出几个bug……你跟AI反复拉扯,可能比自己从头写还耗时。
问题在哪?心里其实都很清楚,上下文缺失的问题。
AI 不懂读心术,我脑海中那个“模糊的、理想中的代码”,它无法感知。 它只能基于海量训练数据”猜测”我的意图,按照自己训练数据里的”通用最佳实践”来写,而这个猜测往往与实际情况相去甚远。
后来我开始在项目里引用了OpenSpec,一个专门为AI编程设计的规范驱动开发框架。它解决的核心问题就是:在AI写代码之前,先把”这个项目应该怎么写”这件事讲清楚。
这篇文章记录了我在老项目中使用OpenSpec的完整过程,从环境准备到第一个功能真正落地,以及过程中的8个踩坑、经验总结等。

一、先理解一个前提:AI编程缺的不是能力,是”图纸”
AI 编程正在经历的演进
在深入 OpenSpec 之前,我们需要理解 AI 编程正在经历的演进:从”让模型写代码”走向”让模型像团队一样开发”。
借鉴传统软件的分层思想,这可以分为三层:

1. Spec Layer 规范层:管“做什么”。
AI 启动执行任务前,先把「要做什么」沉淀为机器可读、结构化规范文档,所有参与者(人类开发者 + AI Agent)严格遵循同一套规范行事,拒绝口头需求、私自变更需求。
2. DISCIPLINE LAYER 纪律层:管“怎么做”。
AI Agent 不能自由发挥、随意创作,必须遵循标准化执行纪律、安全护栏、工程最佳实践,全程持续验证自检,保障执行结果稳定可控、符合规范。
3.协作层 Collaboration Layer:管“谁来做。
解决多 AI Agent 之间的协作问题,完成角色分工、任务调度、依赖管理、权限管控,让多个 AI Agent 像专业开发团队一样高效有序运转。
OpenSpec要做的,就是把这套“隐性知识”变成”显性规范”,让AI在动手之前先读图纸。至于第二层(典型Superpowers)、第三层(典型Harness),在后续的文章会陆续讲到;
市面上类似工具不少,为什么选OpenSpec?
OpenSpec是Fission-AI团队开源的项目,GitHub 21k+ stars,原生支持20多种AI编程工具,比如Claude Code、Cursor、Trae、Codex等。对比一下主流方案,OpenSpec具有两个突出优势:
-
轻量:四个核心命令就能跑完整流程,50KB 上下文限制,无需维护复杂的 constitution 文件。
-
老项目友好:它的设计理念就是 Brownfield-first老项目优先,不需要你重写任何东西,只需要把现有的约定写下来。OpenSpec几乎是唯一一个”开箱即用”的选择,其他工具大多假设你从零开始。
具体来说,OpenSpec定义了一套标准化的工作流。一次完整的变更会经历四个阶段:
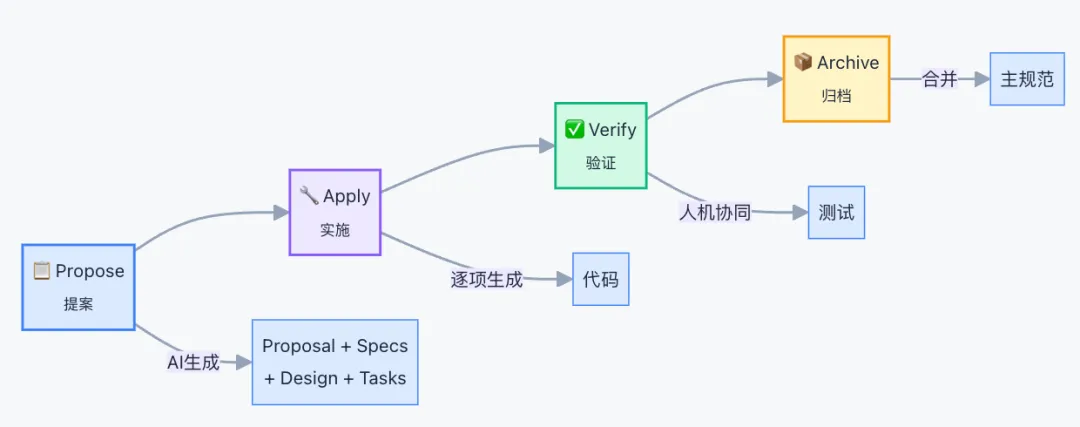
-
提案(Propose):把需求描述变成结构化的变更文档,包含提案、规范、设计和任务清单。AI一次性生成这四份文档,你负责审查和修改 -
实施(Apply):AI按照任务清单逐项生成代码,每完成一项自动勾选 -
验证(Verify):手动或者让AI自动测试功能,确认AI生成的代码符合预期 -
归档(Archive):把增量规范合并到主规范中,变更记录归档保留
整个流程的核心思想是:先定义”做什么”,再决定”怎么做”,最后才是”动手做”。
听起来像是软件工程的常识,但在AI编程的场景下,这一步经常被跳过。大家习惯直接在对话框里说需求,然后让AI直接写代码。对于简单的功能这没问题,但一旦涉及老项目的复杂上下文,跳过这一步的代价就会显现出来。
二、环境准备:1分钟搞定
OpenSpec基于Node.js运行,要求版本不低于20.19.0。安装过程很直接:
# 检查Node.js版本,不够的话用nvm升级node -vnvm install 20.19.0nvm use 20.19.0# 全局安装OpenSpec CLInpm install -g @fission-ai/openspec@latestopenspec --version没有什么特别的依赖,装完就能用。
三、在老项目里初始化OpenSpec
进入你的项目根目录,执行初始化命令。
cd /path/to/your-projectopenspec init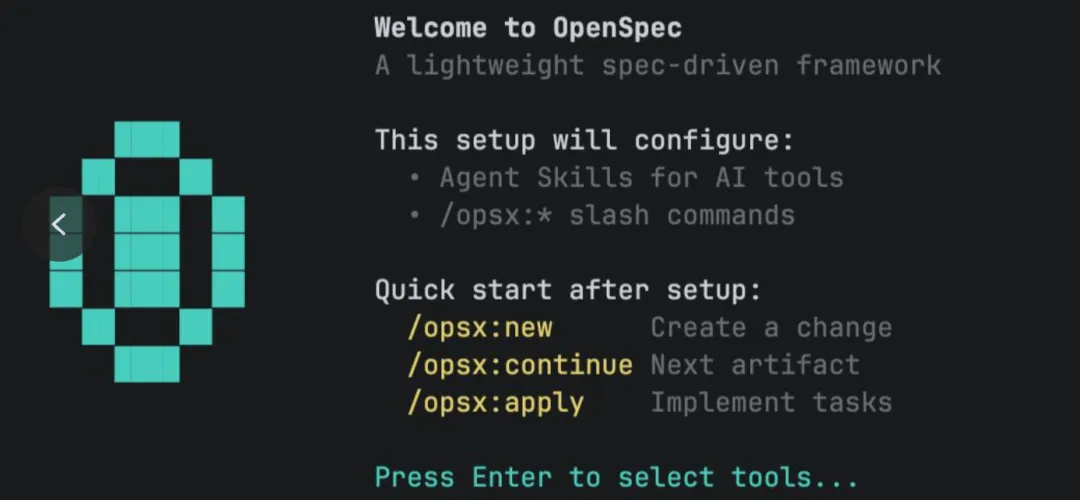
正常情况下,你会看到交互式提示:
? Select tools to configure (Press <space> to select, <a> to toggle all, <i> to invert selection)❯◯ cursor ◯ claude-code ◯ trae ◯ windsurf⚠️ 踩坑预警:
如果你使用的是 Trae,直接按回车可能会报错:
Select at least one tool这是因为新版 OpenSpec CLI 与 Trae 版本存在兼容性问题,对折叠分组的空格选中状态读取异常——界面显示选中了,但后台识别为空。
解决方案:直接指定工具参数,跳过交互式选择
openspec init --tools trae如果需要配置多个工具,可以用逗号分隔:
openspec init --tools trae,cursor初始化过程中,OpenSpec会根据你选择的工具生成对应的技能文件和斜杠命令。不同工具的命令格式略有差异,比如Claude Code用/opsx:propose,Trae用/openspec-propose,但功能完全一样。
初始化完成后,项目里会多出这些内容:
your-project/├── openspec/ # 核心目录,必须提交到Git│ ├── specs/ # 系统规范存放位置│ ├── changes/ # 正在开发的变更│ └── config.yaml # 项目配置(可选但推荐)└── .trae/skills/ # AI技能文件(Trae为例)openspec/是整个框架的核心。specs/目录存放的是系统的”主规范”——描述系统当前应该具备哪些能力、每个能力的行为规则是什么。changes/目录存放的是正在进行的变更——每次新功能或修改都会在这里创建一个独立的目录,包含提案、设计、任务和规范增量。
OpenSpec的工作流基于”Schema”驱动。默认的Schema叫spec-driven,包含四种artifact(制品):proposal(提案)、specs(规范)、design(设计)、tasks(任务)。你可以通过修改openspec/config.yaml中的schema字段来切换不同的工作流模式,也可以通过openspec schemas命令查看所有可用的Schema。
四、编写config.yaml:最花时间但最值得的一步
初始化只是搭了架子,真正让OpenSpec发挥作用的是config.yaml。这个文件是AI理解你项目的”入口”。每次AI处理变更时,都会先读这个文件来了解项目的背景、技术栈、目录结构、代码规范。
这个文件它直接决定了AI后续生成代码的质量。以Go电商后台为例:
schema:spec-drivencontext:| # 项目背景 这是一个Go开发的电商后台管理系统,已运行3年,有10万+行代码。 核心模块:用户、商品、订单、权限。# 技术栈-框架:Gin-ORM:GORM-数据库:MySQL8.0-缓存:Redis7.0-配置:Viper-日志:Zap# 目录结构your-project/├──biz/# 业务层│├──handler/# HTTP入口│├──service/# 业务逻辑│├──dal/# 数据访问│├──model/# 业务模型│└──bizerr/# 业务错误码├──pkg/# 公共库├──config/# 配置└──main.go# 入口# 代码规范-错误码规则:1xxxx通用、2xxxx用户、3xxxx认证-API格式:{code,message,data}-密码加密:argon2-日志必须带trace_idrules:proposal:-必须评估对现有功能的影响-涉及数据库变更时需说明数据迁移策略design:-必须和现有架构风格一致-涉及API变更时必须包含请求/响应示例-数据库变更需说明索引和迁移策略-必须考虑并发安全和性能影响specs:-每个需求至少一个正常场景一个异常场景-使用SHALL表示强约束,MAY表示可选tasks:-复杂任务必须拆分成子任务-必须包含验证步骤为什么这一步特别重要?
你可以把config.yaml理解成一份”项目宪法”。AI在生成任何代码之前,都会先读这份文件。如果你把错误码规则写清楚了,AI就不会自己发明一套错误码;如果你把目录结构写清楚了,AI就知道新代码应该放在哪里;如果你把API返回格式约定好了,AI生成的接口就和现有接口保持一致。
这里有一个容易犯的错:只写技术栈,不写约定。很多人写config.yaml时只列了”用Gin、用GORM、用MySQL”,但没写”错误码怎么编、API返回什么格式、密码用什么算法加密”。这些”约定”恰恰是老项目最核心的隐性知识,也是AI最容易出错的地方。
第一次可以让AI阅读你的完整代码,然后生成这个文件,你进行review、补充完善。前期尽量把你知道的项目约定都写进去。后面用起来会越来越省心。每次发现AI哪里做得不对,都可以回来补充config.yaml,相当于在持续完善这份”项目宪法”。
一个需要注意的限制: config.yaml中的context字段有50KB的大小限制。如果你的项目特别大、约定特别多,可能会超限。这时候的策略是:只保留最关键的、AI最容易出错的那部分约定,把详细的文档通过链接引用而不是直接写进去。
context 和 rules 有什么区别?
config.yaml有两个核心字段:context和rules。初学者经常搞混,不知道什么内容该写在哪里。
|
|
context |
rules |
|---|---|---|
| 作用域 |
|
|
| 内容性质 |
|
|
| 类比 |
|
|
| 长度限制 |
|
|
简单来说:context写”不变的事实”,rules写”阶段的约束”。
比如:
“我们用Gin框架、错误码格式是{code, message, data}”,这是事实,写在context里。
“创建提案时必须评估对现有功能的影响”,这是约束,写在rules里。
还有一个细节:rules中的字段名必须使用英文(proposal、design、specs、tasks),因为它们直接对应OpenSpec工作流中的具体环节。
AGENTS.md 和 config.yaml 是一回事吗?
如果你用Cursor或Claude Code,初始化后会在项目根目录看到一个AGENTS.md文件。这时候你可能会困惑:它和config.yaml有什么区别?
|
|
AGENTS.md |
config.yaml |
|---|---|---|
| 文件格式 |
|
|
| 主要读者 |
|
|
| 内容重点 |
|
|
| 作用范围 |
|
|
| Trae是否生成 |
|
|
简单类比:
AGENTS.md是给AI的”员工手册”(公司文化、工作流程),config.yaml是给OpenSpec的”技术说明书”(用什么技术、怎么写代码)。
如果你用Trae,不会生成AGENTS.md,Trae把AI指导内容放在了.trae/skills/下的SKILL.md文件中,功能是等价的。所以Trae用户只需要关注config.yaml就够了。
哪些文件该提交到Git?
|
|
|
|
|---|---|---|
openspec/ |
|
|
.trae/skills/ |
|
|
AGENTS.md |
|
|
核心原则:openspec/目录是团队协作的基础,必须提交。其他工具特定的配置文件根据团队情况决定。
五、第一个功能落地:管理员找回密码
准备工作做完了,接下来是实战环节。我选择的第一个功能是”管理员找回密码”。这个功能相对独立,不涉及核心交易流程,但又能走完OpenSpec的完整流程,适合作为试点。
5.1 创建变更提案
在Trae的对话中,我输入了这样的指令(Trae使用/openspec-前缀的命令格式):
/openspec-propose add-forgot-password需求描述:1. 用户可以通过邮箱发送验证码找回密码2. 验证码有效期15分钟3. 新密码必须符合复杂度要求4. 不能直接修改数据库密码,必须通过接口AI收到指令后,会在openspec/changes/add-forgot-password/下创建一个新的变更目录,并一次性生成四个文件:
-
proposal.md 变更的意图、背景、影响范围 -
specs 行为规范增量(用GIVEN-WHEN-THEN格式描述) -
design.md——技术方案设计 -
tasks.md——实施任务清单
整个过程大概一两分钟。AI生成的proposal.md会分析这个变更会影响哪些现有模块、是否需要数据库变更、是否涉及安全敏感操作。design.md会给出接口设计、数据模型、缓存方案等技术细节。tasks.md会把整个实施过程拆分成一个个可勾选的任务。
5.2 审查和修改:这是你的核心价值所在
这一步千万不要跳过。
OpenSpec的设计哲学是”人机协同”(Human-in-the-loop):AI负责生成提案和代码,但审查和决策由人来完成。直接批准AI生成的方案,等于放弃了你对项目质量的把控。
我审查时发现了几个问题:
- AI设计的验证码是6位纯数字,但我的项目安全规范要求用4位字母数字混合,纯数字验证码被暴力破解的风险更高- AI把新功能的代码放在了现有的用户模块里,但我认为认证相关的功能应该独立成一个`auth`模块,这样职责更清晰- AI设计的缓存key前缀是`app:reset:`,但项目里认证相关的缓存统一用`auth:`前缀这些都是AI不可能自动知道的项目约定。发现问题后,我直接用自然语言让AI修改:
design.md中的验证码方案需要调整:- 验证码改为4位字母数字混合,而不是6位纯数字- 新功能独立为auth模块,不要放在用户模块里- 缓存key前缀统一用auth:reset:AI会根据反馈修改design.md,然后我再检查一遍。这个”提出问题→修改→再检查”的循环可能需要两三轮,但每一轮都在让方案更贴合你的项目实际。
5.3 实施:让AI按规范写代码
方案确认没问题后,进入实施阶段:
/openspec-apply-changeAI会逐行读取tasks.md,按顺序生成代码。每完成一个任务,会自动把tasks.md中对应的[ ]改成[x]。我看着AI依次生成了:
-
数据库迁移脚本(新建密码重置表) -
model定义(密码重置记录的结构体) -
service层(验证码生成、验证、密码重置的业务逻辑) -
handler层(HTTP接口处理) -
路由注册(把新接口挂载到路由树)
整个过程大约二十分钟。但这里有一个关键点:生成完代码不等于完成,你必须手动验证。 有些AI自己能运行的也可以让AI自己验证;
我用curl测试了几个关键场景:
# 测试发送验证码curl -X POST http://localhost:8080/api/v1/auth/forgot-password \ -H "Content-Type: application/json" \ -d '{"email":"admin@example.com"}'# 测试验证码校验和密码重置curl -X POST http://localhost:8080/api/v1/auth/reset-password \ -H "Content-Type: application/json" \ -d '{"email":"admin@example.com","code":"A3xK","new_password":"NewP@ss2026"}'测试通过后,我把tasks.md中的”手动验证”任务也勾选为完成。
5.4 归档:让变更成为项目资产
功能验证通过、任务清单全部勾选完毕,最后一步是归档:
/openspec-archive-change归档做了三件事:
-
把变更目录移动到 openspec/changes/archive/2026-04-22_add-forgot-password/,作为历史记录保留 -
把 specs/下的规范增量合并到openspec/specs/主规范中——以后AI处理其他变更时,就能看到”系统已经支持密码重置”这个能力 -
整个变更过程(提案→设计→任务→规范→实施)完整保留,随时可以回溯
归档后的目录结构:
openspec/├── specs/│ └── auth/spec.md # 新增的认证规范,已合并到主规范└── changes/ ├── archive/ │ └── 2026-04-22_add-forgot-password/ # 完整的变更历史 └── README.md这个归档机制有一个容易被忽视的价值:它让规范变成了活的文档。传统的项目文档写完就过时了,但OpenSpec的规范是随着每次变更自动更新的。三个月后新同事加入团队,他不需要翻wiki或问老员工,直接看openspec/specs/就能了解系统当前具备哪些能力、每个能力的行为规则是什么。
六、第一个功能落地之后的思考
回顾整个过程,OpenSpec给我带来的价值不是”让AI写代码更快”。说实话,对于一个小功能,我自己写可能也差不多快。真正的价值在于:
第一,AI生成的代码第一次就符合项目规范。 以前我需要花大量时间修改AI生成的代码风格,现在因为有了config.yaml和specs作为约束,AI从一开始就按照项目的规矩来写。审查阶段的工作量从”大改”变成了”微调”。
第二,变更是可追溯的。 每个功能从提案到归档的完整过程都有记录。什么时候加的什么功能、当时做了什么设计决策、任务完成情况如何——这些信息在传统开发中往往只存在于Git commit message和脑子里的记忆中。
第三,我敢让AI在老项目里写代码了。 这可能是最重要的变化。以前每次让AI改老项目代码都提心吊胆,生怕它改坏什么地方。现在有了规范作为护栏,有了任务清单作为进度追踪,有了归档作为历史记录,整个过程变得可控。
当然,OpenSpec也不是万能的。它解决的是”规范定义和执行”这一层的问题,对于特别模糊的需求、对于需要大量创造性思考的架构设计,它的帮助有限。但对于老项目中那些”需求明确、但上下文复杂”的功能开发,它确实是一个值得认真尝试的工具。
几个上手过程中的实用建议:
第一,模型选择有讲究。OpenSpec官方推荐使用高推理能力的模型,比如Claude Opus 4.5+、GPT-5.2+、国内的Qwen、GLM、Kimi等。在规划阶段(生成proposal、specs、design)对模型的推理能力要求较高,在实施阶段(apply)对代码生成能力要求较高。如果条件允许,不同阶段可以用不同的模型。
第二,注意上下文窗口的管理。OpenSpec在干净的上下文窗口中效果最好。开始实施之前,建议清除之前的对话历史,避免早期的大量讨论占用上下文空间,导致AI在生成代码时”遗忘”前面的规范。
第三,不要追求一步到位。第一次用OpenSpec时,config.yaml不可能写得完美。我的做法是:每完成一个变更,就把发现的新约定补充进去。几个变更下来,config.yaml就会越来越完善,AI生成的代码质量也会越来越高。
以上是正面经验,下面整理一些我踩过的坑,提前了解可以少走弯路。
七、新手最容易踩的8个坑
这部分整理了我第一次用OpenSpec时遇到的问题,提前了解可以少走弯路。
坑1:Trae 里没有 /opsx: 快捷命令
看到官方文档用 /opsx:propose,但在 Trae 里输入毫无反应。原因是 Trae 采用 skills-only 集成模式,命令格式不同:Claude Code 用 /opsx:xxx,Cursor 用 /opsx-xxx,Trae 用 /openspec-xxx 或 /openspec-xxx-change。用对应的格式就行。
坑2:openspec init 后没有 config.yaml
执行完初始化,openspec/ 下只有 specs/ 和 changes/,没有 config.yaml。这是正常的,config.yaml 是可选配置,OpenSpec 不会自动生成。你需要手动创建,参考本文第四章的示例。虽然可选,但强烈推荐创建。
坑3:只有4个技能,没有11个
.trae/skills/ 下只有4个技能文件夹。原因是默认安装的是 Core Profile。切换到 Expanded:
openspec config profile # 选择 expandedopenspec update # 重新生成技能文件如果命令无法交互,手动编辑 ~/.config/openspec/config.json,把 "profile": "core" 改为 "profile": "expanded",再执行 openspec update。11个具体的技能我们后面文章会讲到。
坑4:AI 生成的 MODIFIED 规范不完整
MODIFIED Requirements 中只写了变更的部分,缺少未变更的场景。归档后,主规范中那些没变的场景丢失了。原因是归档时 OpenSpec 用 MODIFIED 的内容完整替换对应的 Requirement,不是逐行 diff。
在 config.yaml 的 rules 中加一条可以预防:
rules:specs:-MODIFIEDRequirements必须写出变更后的完整需求,包含所有仍然有效的场景坑5:归档后 changes 目录里的文件”消失”了
归档操作是将变更目录移动到 changes/archive/,不是复制。去 archive 目录下查看即可。
坑6:spec.md 格式错误导致解析失败
缺少 ## Purpose 或 ## Requirements 标题,或者没有使用 SHALL/MUST 关键字。记住口诀:”结构用英文,描述用中文,关键字不能错”。
坑7:context 内容过长被截断
context 有 50KB 限制,超出会被截断。建议控制在 10KB 以内,只保留最关键的信息。
坑8:多人协作时规范冲突
两个人同时改同一个 spec,归档时冲突。建议每个变更独立 Git 分支,在 proposal 阶段就同步给团队。如果有多个变更同时完成,用 /openspec-bulk-archive-change 批量归档,它会自动检测冲突。
下一篇预告
这篇讲的是从零接入OpenSpec并完成第一个功能。下一篇我会深入讲几个更实际的问题:
-
规范到底怎么写才合适?太粗了AI乱来,太细了维护成本高,怎么找平衡点 -
修改已有功能时,规范怎么处理?OpenSpec的ADDED/MODIFIED/REMOVED机制详解 -
团队多人协作时,怎么保证大家用同一套规范 -
规范越来越多会不会难以管理?OpenSpec的设计如何应对这个问题
如果你正在维护老项目并且想引入AI辅助开发,建议先跟着这篇把环境搭起来、跑通第一个功能,有了直观感受之后再来看进阶内容。