 夜雨聆风
夜雨聆风





读 Claude Code 源码学到的几件事
Claude Code 源码泄露有一段时间了,正好五一假期抽时间拆解了一遍,收获很大。
不想读技术细节的:直接跳到文末的「8 条原则总览」(约 600 字)。中间几节是源码层的展开,按需要选读。
本文所有代码引用都来自开源项目 claude-code-best/claude-code[1] 的 main 分支,TypeScript 源码约 51 万行。拆解基于 commit a2cfaf9(2026-04-28),package version 1.10.10,CLI 自报 MACRO.VERSION = 2.1.888。源码仓库活跃迭代中,当前本地源码已经演进到更新版本;行号、函数名、feature flag 列表可能随版本变化——本文讨论的设计原则不依赖具体行号。
从哪里开始读
代码量大,但入口路径较短。三步定位入口:
-
看 package.json的bin字段。claude-code-best 仓库里写的是"ccb": "dist/cli-node.js"——装上后跑ccb命令调用这个文件。 -
dist/是构建产物,回找源码。看build.ts里的入口配置(或vite.config.ts/package.json里的main),对应到源码侧的src/entrypoints/cli.tsx。这个文件顶部有#!/usr/bin/env bunshebang,是独立可执行 entry。 -
顺着 import一路下钻。cli.tsx 末尾一行await import('../main.jsx')调起main();main.tsx 里import { launchRepl } from './replLauncher.js';replLauncher 把控制权转给 QueryEngine;QueryEngine 调 query 里的 agent loop。
src/entrypoints/cli.tsx pre-flight 检查 + daemon/runner 分支 + 调起 main()
→ src/main.tsx CLI 参数解析、子命令注册、初始化(单文件巨型)
→ src/replLauncher.tsx REPL 交互层,转发
→ src/QueryEngine.ts 外壳:系统 prompt 装配、cost 追踪、文件历史
→ src/query.ts ★ agent loop 真身在这里
→ tools / services / hooks / ...
本文后面讨论的工具调度、记忆、多 agent,都是从 query.ts 顺着 import 再向下展开一层之后的内容。本文按这个顺序展开:先看 agent loop 本身,再依次往外。
1. agent loop 就是个 while(true)
src/query.ts 的 queryLoop 是每次用户提问后 agent 跑起来的入口。函数主体是一个 while(true) 循环:
// src/query.ts
async function* queryLoop(params: QueryParams, ...) {
let state = { messages, toolUseContext, turnCount: 1, ... }
while (true) {
// 1. 拼装本轮 prompt(merge 静态 system + system context + user context)
// 2. 上下文压缩判断(防 token 超限)
// 3. 调模型,流式拿响应
// 4. 解析模型返回的 tool_use
// 5. 跑工具,拿结果
// 6. 把结果追加到对话历史
// 7. 没新工具调用就结束,否则继续
}
}
每一轮”采样 → 工具 → 反馈”反复转,直到模型不再发起 tool_use。这种 reasoning + acting 交替进行的循环,业内叫 ReAct 范式。
循环本身只是一个调度骨架,复杂度都在它每一步调用的下游模块里。query.ts 顶部的 import 显示:每一轮迭代之前要走 services/compact/autoCompact.ts 决定要不要压缩;模型返回之后要走 services/tools/toolOrchestration.ts 编排工具的执行顺序;一轮收尾要走 query/stopHooks.ts 触发记忆抽取、prompt 推荐、autoDream;token 用量要走 query/tokenBudget.ts 判断要不要主动续跑。
后面几节会展开这 7 步里的几个关键设计:拼装 prompt 怎么做(system prompt 切两半、记忆分层、工具按需加载)、上下文压缩怎么触发、工具调度怎么并发。其余几步是常规模型调用 + 历史追加,不专门展开。最后还会聊两件超出 while 循环本身的事——一个是贯穿循环的工程方法(关键阈值都是事故反推的),一个是另一种 agent 运行模式(多 agent 协作)。
关键是把 agent 内核做薄、复杂度往下游推——好处是每段独立可换(Claude Code 里多种压缩策略并存就是这种设计的产物),代价是追踪一个动作得跨 query、compact、tool orchestration、hooks 等多个模块。这种 trade-off 适合要长期迭代的项目;如果是写完不改的 demo,langgraph 那种显式 state machine 反而更清晰。
2. system prompt 切两半,系统内置部分共享缓存
Anthropic API 支持 prompt caching——你在请求里标记 prompt 哪一段稳定不变,服务端就把这段的处理结果缓存起来,后续相同内容的请求直接复用,省钱省时。Claude Code 把这个机制用到了极致。
agent loop 每轮第一步是”拼装本轮 prompt”。本节展开其中一项设计:Claude Code 用一个特殊 marker 把 system prompt 切成静态、动态两半。src/constants/prompts.ts 的 getSystemPrompt() 末尾的代码结构展示了这件事:
return [
// --- 静态内容(可缓存)---
getSimpleIntroSection(...),
getSimpleSystemSection(),
getSimpleDoingTasksSection(),
getActionsSection(),
getUsingYourToolsSection(...),
getSimpleToneAndStyleSection(),
getOutputEfficiencySection(),
// === BOUNDARY MARKER ===
SYSTEM_PROMPT_DYNAMIC_BOUNDARY,
// --- 动态内容(每次请求重建)---
...resolvedDynamicSections,
]
7 个静态 section 函数显式列在 boundary 之上:Intro / System / DoingTasks / Actions / UsingYourTools / ToneAndStyle / OutputEfficiency。这 7 段是系统内置的 prompt 内容,所有用户共享同一份缓存。每一个函数返回什么文字,打开 prompts.ts 同名函数即可逐字看到。boundary 之后的 resolvedDynamicSections 由 registry 装配,每次请求按当前会话状态重新构造(当前时间、git 状态、CLAUDE.md、MCP 工具等)。
发请求时,src/utils/api.ts 找到 marker 的位置,把 prompt 按位置切成两段,分别打不同的 cacheScope 标签:
const boundaryIndex = systemPrompt.indexOf(SYSTEM_PROMPT_DYNAMIC_BOUNDARY)
// boundary 之前 → cacheScope: 'global' 系统内置部分,所有用户共享缓存
// boundary 之后 → cacheScope: null per-session,不缓存
整个流向:
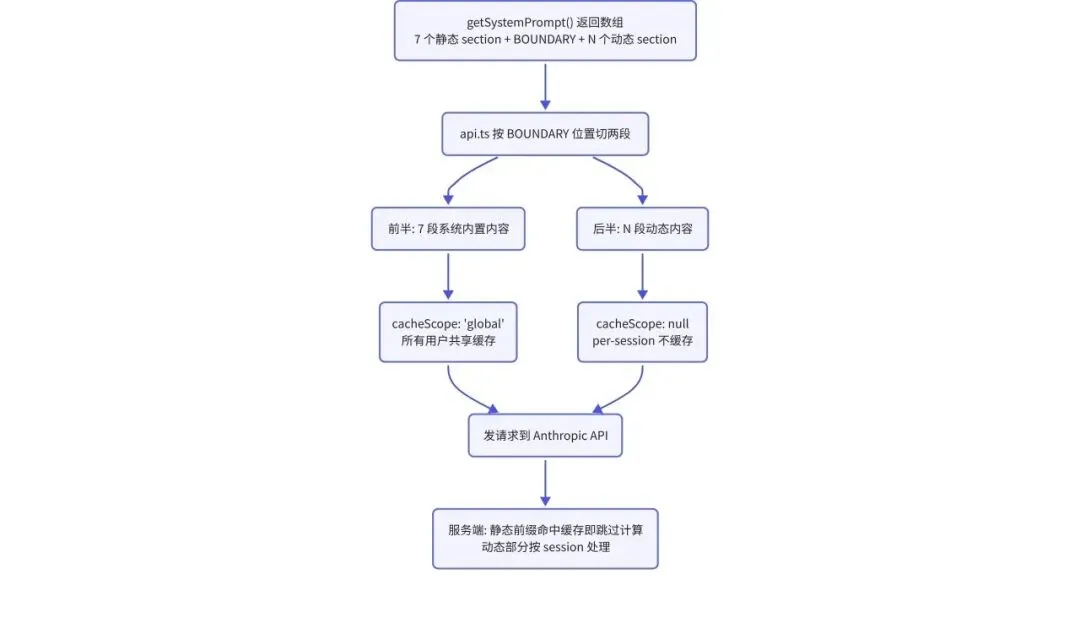
prompt cache 的正确用法是显式切分——把 system prompt 拆成全局 const + 动态构造两段,用一个 boundary 字符串拼起来,别用模板字符串一把梭。代价是决策被推给开发者:一个用户级变量错放到 boundary 之前,全用户的命中率都会崩。prompts.ts 顶部那条 WARNING 注释(不要乱挪 marker)就是为了防止这种事故。
3. 工具调度复用 OS 思路
模型在一次响应里返回 4 个 tool_use(3 个读 + 1 个改),这些工具是排队执行还是并发执行?
src/services/tools/toolOrchestration.ts 实现的是”读读并行、读写互斥”,与操作系统中读写锁的处理方式一致:
// 默认最多 10 个并发,可用 CLAUDE_CODE_MAX_TOOL_USE_CONCURRENCY 调整
// partitionToolCalls 的核心判断
const isConcurrencySafe = parsedInput?.success
? (() => {
try { return tool.isConcurrencySafe(parsedInput.data) }
catch { return false } // 抛异常按不安全处理 ← fail-closed
})()
: false // 参数解析失败也按不安全处理
// 然后:连续 isConcurrencySafe 的合并到同一批,遇到 not safe 切批
逻辑:默认最多 10 个工具并发,连续若干个 isConcurrencySafe 的合并到同一批一起跑,遇到一个不 safe 的就切批,让前面那批跑完再开下一批。批与批串行,批内并发。Read 是 safe 的,Edit / Write / Bash 不 safe,所以 3 读 + 1 写会被切成两批:3 个并发 Read 跑完 → 1 个 Edit。
切批过程可视化:
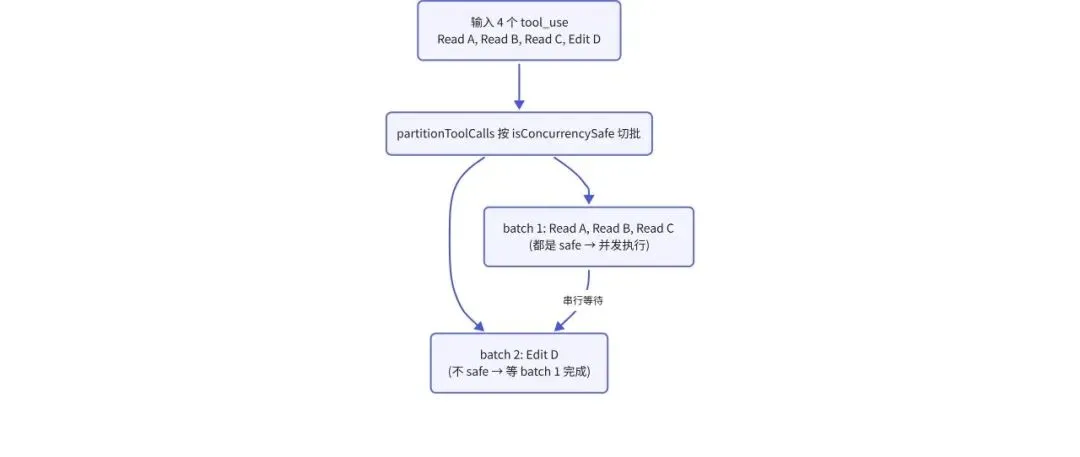
两条带走的事:一是别自己发明并发模型,”读读并行、读写互斥”这套既有方案覆盖 90% 场景;二是 fail-closed(出错降级到最保守路径)应当是 agent 工具调度的默认——看 try / catch 那段,理论上 isConcurrencySafe() 不会抛,但 Claude Code 仍包了一层。
fail-closed 留下一笔技术债:某个工具误抛会让原本能并发的批次悄悄降级成串行,但没有可观测性。自己实现时至少在 dev 模式输出并发降级原因。
4. 记忆要分层,且不记代码
让 AI 在长对话中保持上下文连贯,常见做法是 RAG——把项目数据做 embedding 存到向量库,每次问答先检索再回答。
Claude Code 不使用 RAG。它的方案是分层缓存 + grep 搜索。
第一层是始终在上下文里的索引文件,叫 MEMORY.md,每次对话都被完整加载。src/memdir/memdir.ts 用几行常量定义了它:
export const ENTRYPOINT_NAME = 'MEMORY.md'
export const MAX_ENTRYPOINT_LINES = 200
// ~125 chars/line at 200 lines. At p97 today; catches long-line indexes that
// slip past the line cap (p100 observed: 197KB under 200 lines).
export const MAX_ENTRYPOINT_BYTES = 25_000
MEMORY.md 最多 200 行、25KB,里面只放指针(路径 + 一句话标题),不放正文。一份典型的 MEMORY.md 长这样:
# MEMORY.md
## 项目设置
- [项目架构](architecture.md) — 关键模块依赖关系
- [部署流程](deploy.md) — staging 和 prod 的发布步骤
## 已知坑
- [redis 集群](gotchas/redis.md) — 别用 KEYS *,会卡主线程
- [webhook 重试](gotchas/webhook.md) — idempotency 必须走 deduper
每行就是一个指针,正文都在外部 .md 文件里。正文是第二层——散落的 <topic>.md 文件,按需加载:新对话开始时由一个小模型挑最多 5 个跟当前问题相关的加载进来。第三层是更早的对话,被存成 .jsonl 历史文件,手动检索:agent 需要时通过 Bash 工具用 grep -rn 翻历史。
findRelevantMemories.ts 的 system prompt 里还有一条挑选规则:
const SELECT_MEMORIES_SYSTEM_PROMPT = `...
- If a list of recently-used tools is provided, do not select memories that are
usage reference or API documentation for those tools (Claude Code is already
exercising them). DO still select memories containing warnings, gotchas, or
known issues about those tools — active use is exactly when those matter.`
正在使用某个工具时,不加载它的使用文档,但加载它的已知问题。
三条带走的事:索引—正文分离(IDE 代码导航、OS page table 本质都是这一招)、正在使用的工具加载已知问题而非文档(文档可以边用边查,但已知问题不会自动暴露)、记忆只记偏好和判断不记代码。最后一条反过来用在 CLAUDE.md 这种长期指令文件:不要写”函数 X 在第 30 行”,要写”函数 X 改了要跑 e2e,因为它触发 webhook”——前者是事实会过期,后者是判断长期适用。
5. 上下文压缩分 5 级触发
agent loop 每轮第 2 步是”上下文压缩判断”。这里的”上下文”指 messages 数组(用户消息 + assistant 消息 + 旧的 tool_use 结果),不包含工具定义——工具描述的成本由 ToolSearch 单独解决(下一节展开)。Claude Code 的压缩不是一次性算法,而是 5 级从轻到重的策略,按当前 token 占用率决定使用哪一级:
| 级别 | 强度 | 实现位置 | 做什么 |
|---|---|---|---|
| 1. Snip | 轻 | services/compact/snipCompact.ts |
旧 tool_use 结果只保留结构,不保留正文 |
| 2. Microcompact | 轻 | services/compact/microCompact.ts |
把体积大的工具结果卸载到磁盘缓存,引用替换正文 |
| 3. Context Collapse | 中 | services/contextCollapse/index.ts |
对中间对话做摘要折叠 |
| 4. Autocompact | 重 | services/compact/autoCompact.ts |
超阈值时整块上下文做摘要压缩 |
| 5. Reactive Compact | 兜底 | services/compact/reactiveCompact.ts |
API 返回 413 prompt too long 时紧急触发 |
query.ts 顶部三段 conditional import 显示这些级别都按 feature flag 加载:
const reactiveCompact = feature('REACTIVE_COMPACT')
? require('./services/compact/reactiveCompact.js') : null
const contextCollapse = feature('CONTEXT_COLLAPSE')
? require('./services/contextCollapse/index.js') : null
const snipModule = feature('HISTORY_SNIP')
? require('./services/compact/snipCompact.js') : null
调用顺序遵循”先轻后重”:每轮先看能否用 Snip / Microcompact 处理,再升级到 Context Collapse / Autocompact,Reactive Compact 是最后兜底。除 Snip 是纯结构裁剪外,每一级都是独立的模型调用。
长上下文管理用渐进式策略——每一级应对一种特定失败模式(见上表),损失信息量递增,每轮只用一级。自己实现长会话 agent 时至少要有最重两级——Autocompact 和 Reactive Compact;工具调用频繁的话再补 Snip 和 Microcompact。
6. 工具按需加载(ToolSearch)
先和「工具调度」划清边界:前面”工具调度”讲的是模型已经决定要调哪些工具之后的执行编排;这里讲的是更早一步——哪些工具的 schema 出现在 prompt 里让模型看到。两件事作用在 agent loop 的不同时刻:这里在装 prompt 时(请求前),工具调度在模型回复 tool_use 之后(响应后)。
agent 启动时 prompt 里要列出可用工具的列表和 JSONSchema。工具不多时全部列出来没问题;但工具数量大时,prompt 会被工具描述塞满。最常见的触发场景是 MCP(Model Context Protocol,Anthropic 推的工具协议,让 agent 接第三方工具源)——用户接了 5 个 MCP 服务器、每个带几十个工具时,几千 token 全花在工具描述上。Claude Code 的方案是 deferred loading:默认只列工具名字,不展开 schema。
packages/builtin-tools/src/tools/ToolSearchTool/prompt.ts 的判断逻辑:
export function isDeferredTool(tool: Tool): boolean {
if (tool.alwaysLoad === true) return false // 显式 opt-out
if (tool.isMcp === true) return true // MCP 工具默认 deferred
if (tool.name === TOOL_SEARCH_TOOL_NAME) return false // ToolSearch 自己不能 deferred
// ...
}
内置工具(Read / Edit / Bash / Glob / Grep 等)默认 alwaysLoad: true,全部展开进 prompt。MCP 工具默认 deferred,prompt 里只看到一行名字。模型想调用一个 deferred 工具时,先调 ToolSearchTool,按 query 拿回完整 JSONSchema,之后才能调用。
举个具体例子(你接了 Slack MCP,模型要发一条消息):
1. prompt 里只有一行: slack_send (没 schema)
2. 模型先发: ToolSearchTool({query: "select:slack_send"})
3. 拿回 slack_send 的完整 JSONSchema (channel + text 两个参数)
4. 模型用 schema 发起真正调用: slack_send({channel: "#general", text: "..."})
三条带走的事:工具描述也是 prompt 成本(多个 MCP 同时挂轻松占 10%+ 上下文,按需加载几乎是必须的);lazy load 的 query 接口要支持精确 select(模型看到工具名就有 hint,能按名字直接命中,比纯模糊搜索快一轮);默认 + opt-out 比默认 + opt-in 健壮(新接入的 MCP 自动享受 lazy load,alwaysLoad: true 是 escape hatch,只少数关键工具需要写)。
7. 关键限制都是事故反推的
读源码时关注带具体日期和数字的注释。src/services/compact/autoCompact.ts 有这么一段:
// Stop trying autocompact after this many consecutive failures.
// BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures (up to 3,272)
// in a single session, wasting ~250K API calls/day globally.
const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3
BQ 是 BigQuery 查询的简写。这个 3 不是凭直觉选定,而是源自 2026-03-10 的一次查询:当时全网 1279 个会话连续 autocompact 失败超过 50 次,其中一个会话连续失败 3272 次仍在重试,每天因此消耗 25 万次 API 调用。
同样的事故修补痕迹在前面 MEMORY.md 那段限制里也有:注释 p100 observed: 197KB under 200 lines 说明一个用户写了 200 行索引但每行很长,总计 197KB,逼近上下文上限,所以字节限制是后来加的,上线之初只有 200 行限制。
模式一致:上线时未设限制 → 用户触发边界 → telemetry 暴露问题 → 代码层补一道约束。
三条带走的事:所有阈值留 env var 入口(补限制不用发版);用 BQ <日期>: 这种注释把决策痕迹钉在代码身边(比 design doc 活得久,三年后看到也知道这个 3 是有数据支撑的,不该乱改);看到一个断路器主动检查失效模式同构的姐妹模块——MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3 补完后,5 级压缩里另外四级源码里看不到等价的连续失败上限,可能只是还没踩过同类事故,但失效模式(模型调用、timeout / rate limit / 返回不可解析)是一样的。
8. 多 agent 协作 = 工具权限的主从差异
多 agent 协作通常被认为需要独立的”协议状态机”。Claude Code 的实现路径不同。
src/coordinator/workerAgent.ts 里核心机制只有十几行:
const INTERNAL_ORCHESTRATION_TOOLS = new Set([
TEAM_CREATE_TOOL_NAME,
TEAM_DELETE_TOOL_NAME,
SEND_MESSAGE_TOOL_NAME,
SYNTHETIC_OUTPUT_TOOL_NAME,
])
function getWorkerTools(): string[] {
return Array.from(ASYNC_AGENT_ALLOWED_TOOLS).filter(
name => !INTERNAL_ORCHESTRATION_TOOLS.has(name),
)
}
Claude Code 开启 COORDINATOR_MODE 之后,主 agent 变成”协调员”,只能调一个叫 worker 的子 agent;worker 拿到一份”全标准工具集减去 4 个”的工具白名单。协调员能用、worker 不能用的,只有这 4 个:建团队、解散团队、发消息、合成输出。worker 拿不到这 4 个,意味着它不能再开新的子 agent、不能跨 agent 通信、不能直接出最终答案——只能完成具体任务、汇报回协调员。
用现有 primitive 的差分关系表达层级,比发明新协议成本低得多——主-从被实现成”主 agent 工具集 ⊃ 子 agent 工具集”,权限约束自然形成层级,复用 agent 已有的”用工具”心智模型。适用边界:Claude Code 的多 agent 是单根树(无 sibling 通信、无跨层 broadcast),90% 场景够用;剩下 10%(多 worker 协商任务分配)只能让协调员当中间路由,token 开销和延迟显著增加。落地路径:先确定工具的差分边界,再考虑是否需要协议——遇到那 10% 时再设计协议,届时也才知道协议要长什么样。
9. 8 条原则总览
这 8 件事放在一起看,Claude Code 的设计重点不是“让模型更聪明”,而是把模型放进一个有边界的执行系统里:入口可控、工具可控、记忆可控、成本可控、失败可控。拆成可借用的设计原则,就是下面几条:
-
agent 内核要薄。核心是 while(true)的“模型采样 → 工具执行 → 结果回灌”循环;压缩、工具调度、权限、记忆、生命周期 hooks 等复杂度拆到外围模块,模块之间保持可替换。 -
system prompt 物理切两半。前半是系统内置部分(共享缓存),后半 per-session 动态,用一个明确的 boundary marker 切开。不要用模板字符串一次性拼出。 -
工具调度复用 OS 思路。读读并行、读写互斥,fail-closed 默认 + env var 调上限。不必自行设计 DAG。 -
记忆要分层。索引常驻、正文按需、历史 grep。不记代码,只记偏好和判断。 -
上下文压缩用渐进式策略。从轻量裁剪到全量摘要按 token 占用率逐级触发,不要一上来就做全量摘要。 -
工具描述按需加载。MCP / 外部工具默认只列名字,模型用 ToolSearch 按需取 schema。避免几千 token 工具描述塞满上下文。 -
关键阈值预留覆盖入口、决策痕迹钉在代码身边。数字用 env var 可覆盖,决策原因用 BQ <日期>:注释。看到一个断路器,主动检查失效模式同构的姐妹模块。 -
多 agent 协作用工具权限差异表达。先确定”协调员独占哪几个 primitive”,主从层级自然形成,不必先设计协议。
生产级 agent 的优秀设计,绝大多数不是设计阶段想出来的,而是在生产流量中迭代出来的。MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3 没有论文会教,它来自 1279 个会话出错之后的一次 BQ 查询。Claude Code 真正稀缺的不是 51 万行代码,而是每一处带日期注释背后大量真实会话的反馈循环——这些反馈已经经过实际验证,结论可以直接借用。
引用链接
[1]claude-code-best/claude-code: https://github.com/claude-code-best/claude-code