 夜雨聆风
夜雨聆风





AI科学家:迈向科研全流程自动化

论文推介
Towards end-to-end automation of AI research
期刊:NATURE(JCR 1区, 影响因子:11.14)
DOI:10.1038/s41586-026-10265-5.
01 Smmary
1. 研究问题和动机
2. 主要假设
3. 研究设计
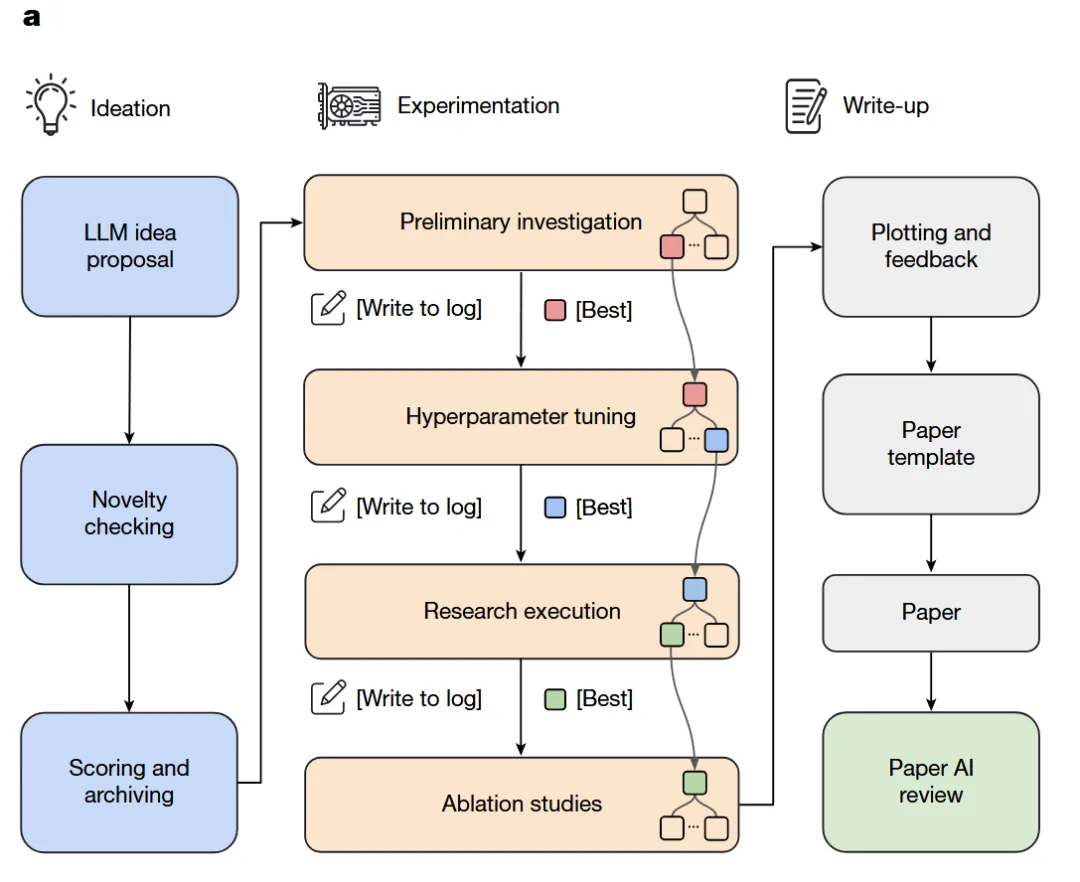
6. 可能的拓展研究点
02 数据与方法
数据来源
无模板式AI科学家
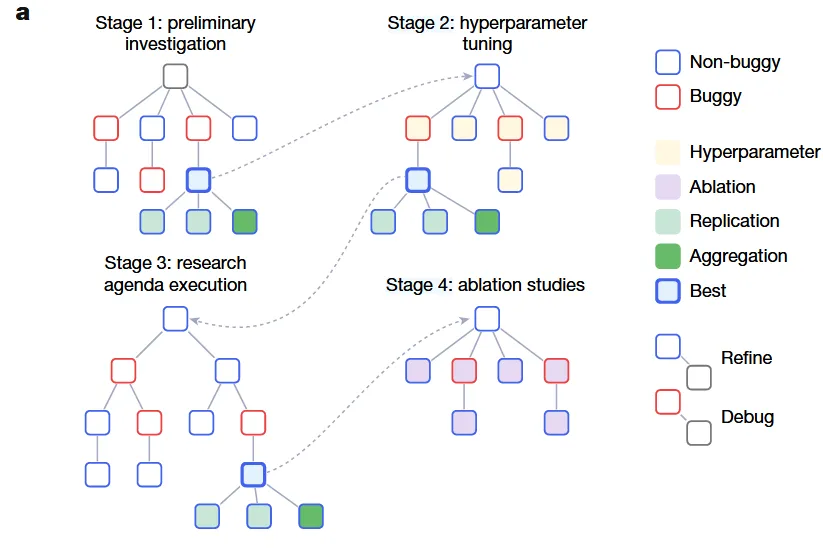
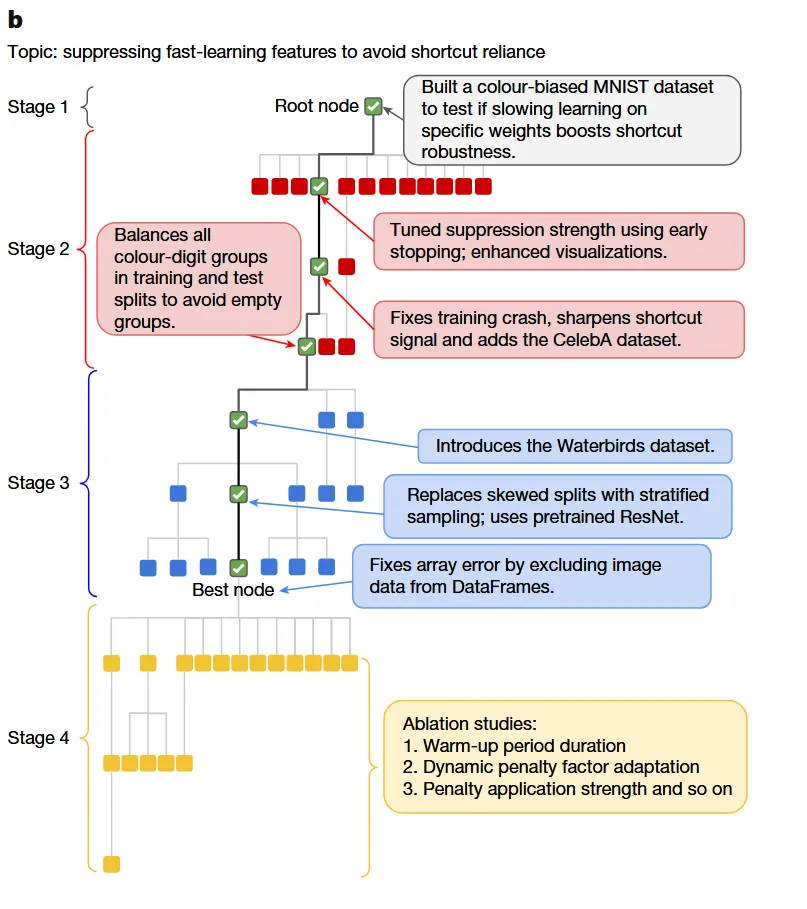
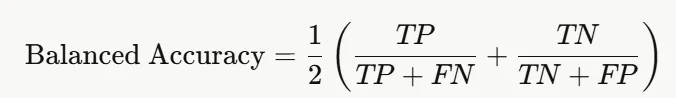

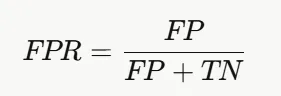
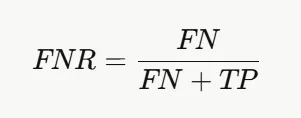
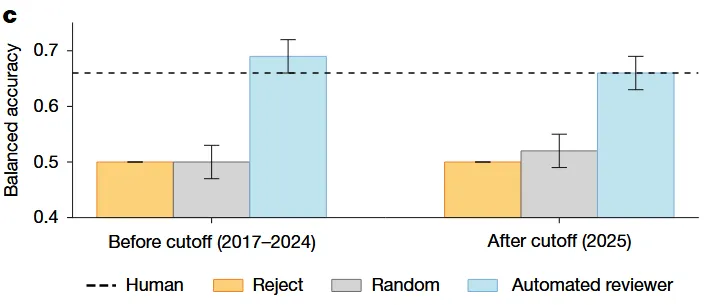
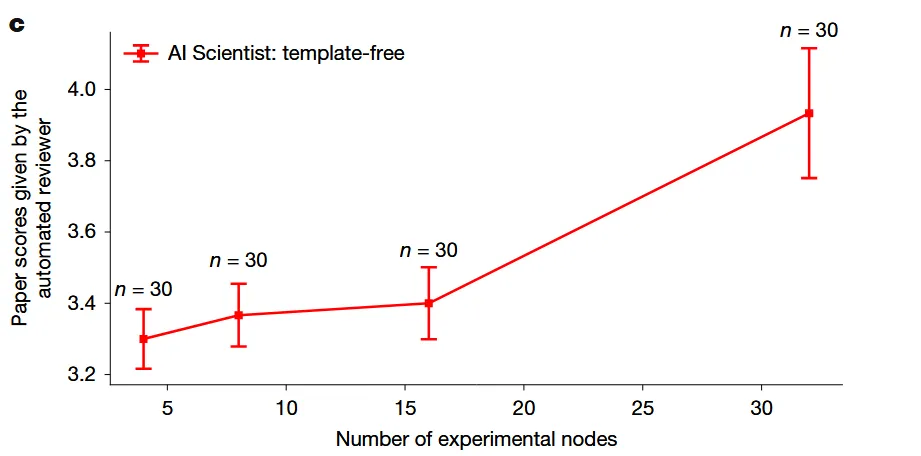
03 结果
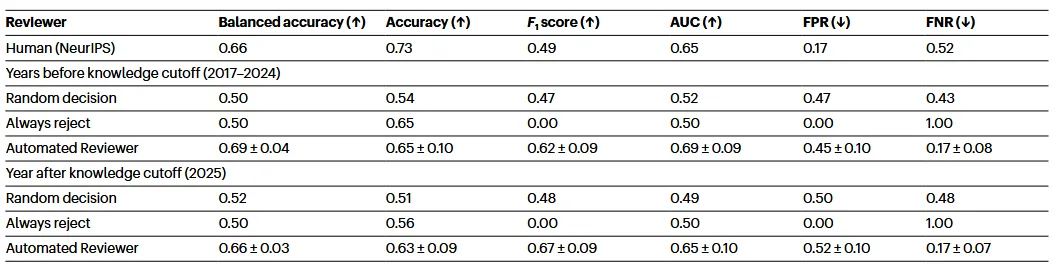
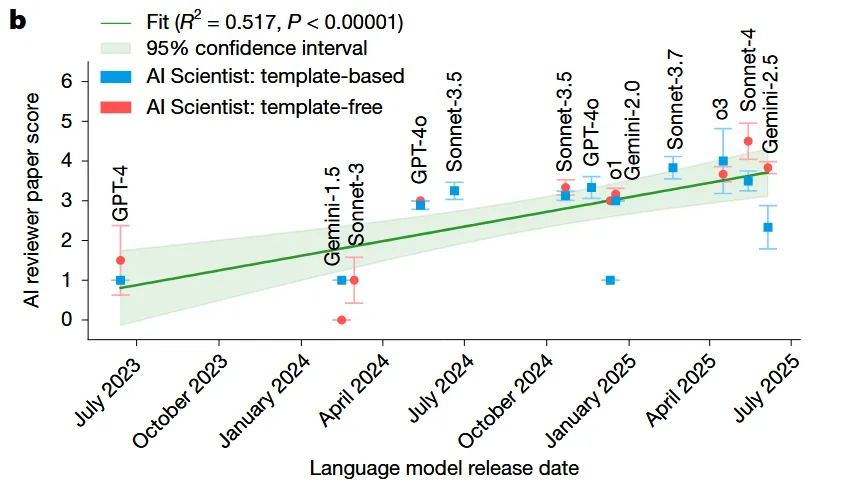

张丽娜|编辑 排版
李仁德|审核
[ 分享者介绍 ]
LinaZhang graduated from Dalian University in 2024, majoring in engineering management. She is currently studying Management Science and Engineering at University of Shanghai for Science and Technology.

微信号|共读共享共思