 夜雨聆风
夜雨聆风





为什么我放弃了 OpenClaw,全面拥抱 Hermes Agent(上手指南)
作为一个带大模型后训练算法团队的 AI 工程师,我用 OpenClaw(龙虾)用了大半年,积累了不少记忆和技能。但当 Hermes 发布之后,我花了一个周末完成迁移,再也没回去。这篇是我上手Hermes 的完整记录——不只是迁移教程,更是从零理解 Hermes 三大核心机制(Memory / Skill / Nudge Engine)、安装、配置 GLM-5.1、以及我用它做工作记录、简历筛选、论文调研等六个真实场景的实战心得。
一、Hermes Agent 是什么
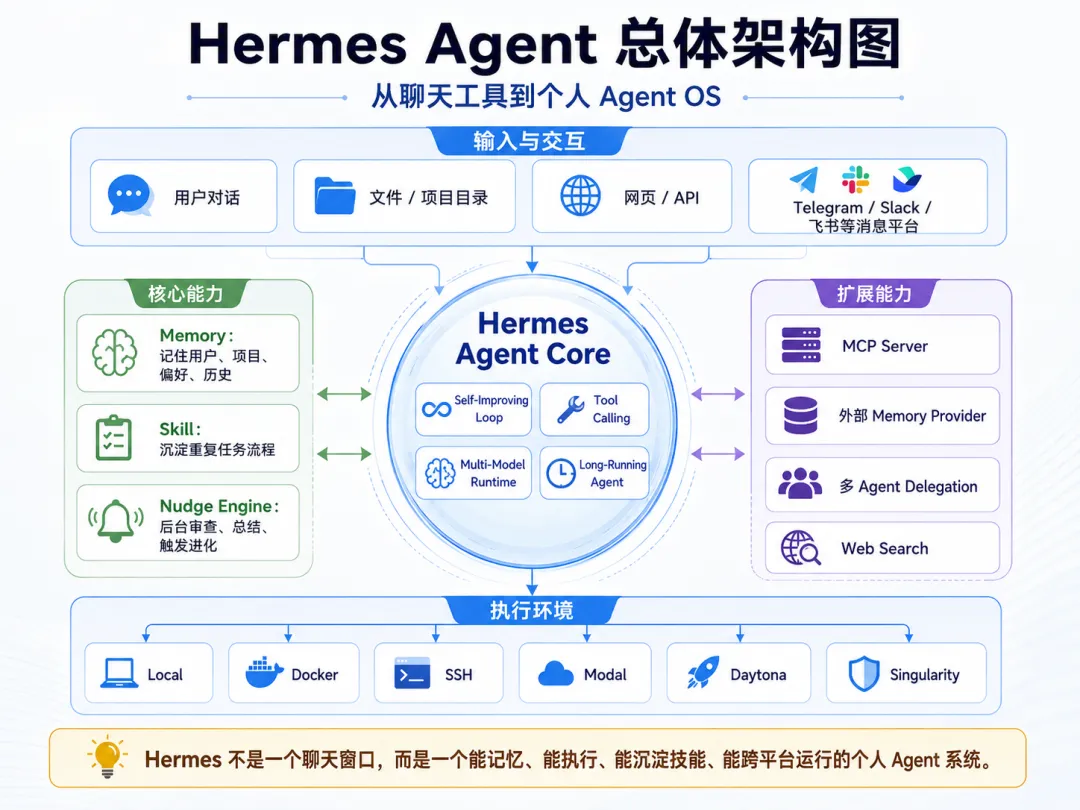
Hermes Agent 是 Nous Research 开源的自主 AI Agent 框架,GitHub 上已经超过 10 万 Star,官方github地址是:https://github.com/NousResearch/hermes-agent。说实话,我一开始觉得「又一个 AI 聊天工具」,但用下来发现它和大多数「绑定 IDE 的代码助手」或「套壳聊天机器人」完全不同——核心设计理念只有一个:用得越久,它越强。
这个「越用越强」不是营销口号。它内置了一个完整的自我进化循环:从每次对话中提取记忆、自动生成可复用技能、后台 nudging 自我审视——三个子系统协同工作,让 Agent 的能力随使用时间持续积累。
我的理解是:它就是一个部署在你自己设备上的全能 AI 助手——写代码、抓网页、做调研、管文件、调 API,甚至接上 Telegram/飞书/Slack 7×24 小时待命。不绑死在笔记本上,可以跑在 $5 的 VPS、GPU 集群,或者按需计费的 Serverless 环境里(Daytona、Modal),空闲时几乎不花钱。
核心特性速览:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
二、环境要求与安装
这是整篇文章里最「工具性」的一节,但也是最容易踩坑的一节。我按顺序把每一步写清楚(当然如果你电脑上已经装了claude code或者trae/curosr/workbuddy等其他agent工具,也可以直接把hermes的github地址https://github.com/NousResearch/hermes-agent给这些工具,然后说:帮我参考这个github地址xxxxxxx,完成hermes的安装)。
2.1 环境要求
开始之前,确认系统满足以下条件:
|
|
|
|---|---|
|
|
3.11 或以上 |
|
|
|
不确定 Python 版本?终端输入检查:
python3 --version版本不够?按系统安装:
# macOS(推荐 Homebrew)brew install python@3.11# Linux / WSL2sudo apt update && sudo apt install python3.11 python3.11-venv2.2 一键安装
Linux / macOS / WSL2:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bashWindows (PowerShell,早期 beta):
irm https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.ps1 | iexAndroid (Termux) 也支持,用同样的 curl 命令即可,安装器会自动检测环境。
⚠️ 重要:不要用
sudo跑安装脚本,用普通用户权限就行。加了 sudo 反而会出权限问题。
安装完成后,当前终端还不认识 hermes 命令,需要重载一下:
# macOS(默认 zsh)source ~/.zshrc# Linux(默认 bash)source ~/.bashrc或者直接关掉终端重新打开,效果一样。配置文件位于 ~/.hermes/ 目录下。
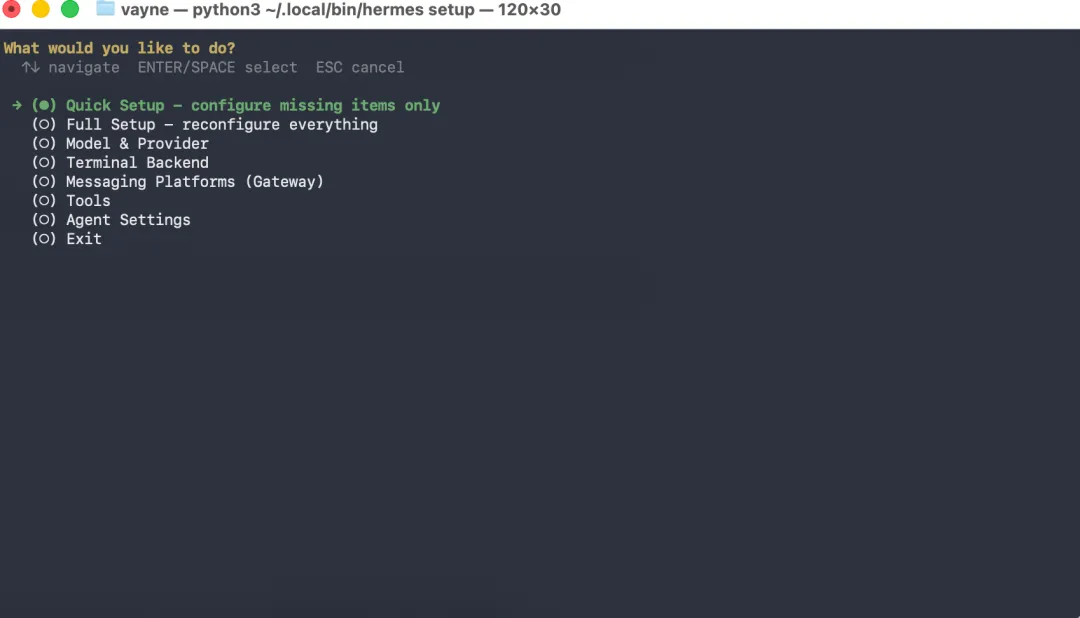
2.3 首次设置向导
安装好之后,建议先跑一遍完整的设置向导:
hermes setup向导会引导你完成(可以先选择quicksetup,基础的配置和模型设置好,后续按需修改配置):
-
选择 LLM 提供商 -
填入 API Key -
配置默认工具集 -
设置基础偏好
2.4 配置模型 Provider
安装好之后,第一步是配置模型。Hermes 支持 20+ 个 Provider,模型无关是它最大的优势之一:
hermes model交互式选择你的 Provider。我自己的配置是:
|
|
|
|
|
|---|---|---|---|
|
|
GLM-5.1 |
|
|
|
|
DeepSeek V4 Pro |
|
|
|
|
|
|
|
其他常用 Provider:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
选完 Provider 后,API Key 会存在 ~/.hermes/.env 文件中。
模型随时可切换,不影响已积累的记忆和技能。以后想换模型,再跑一次 hermes model 即可。
国内模型完全够用:GLM、DeepSeek、Kimi、通义千问都支持,不用翻墙也能跑。我自己日常主力 GLM-5.1,编码和文本生成都很稳,价格也划算。
2.5 验证安装:hermes doctor
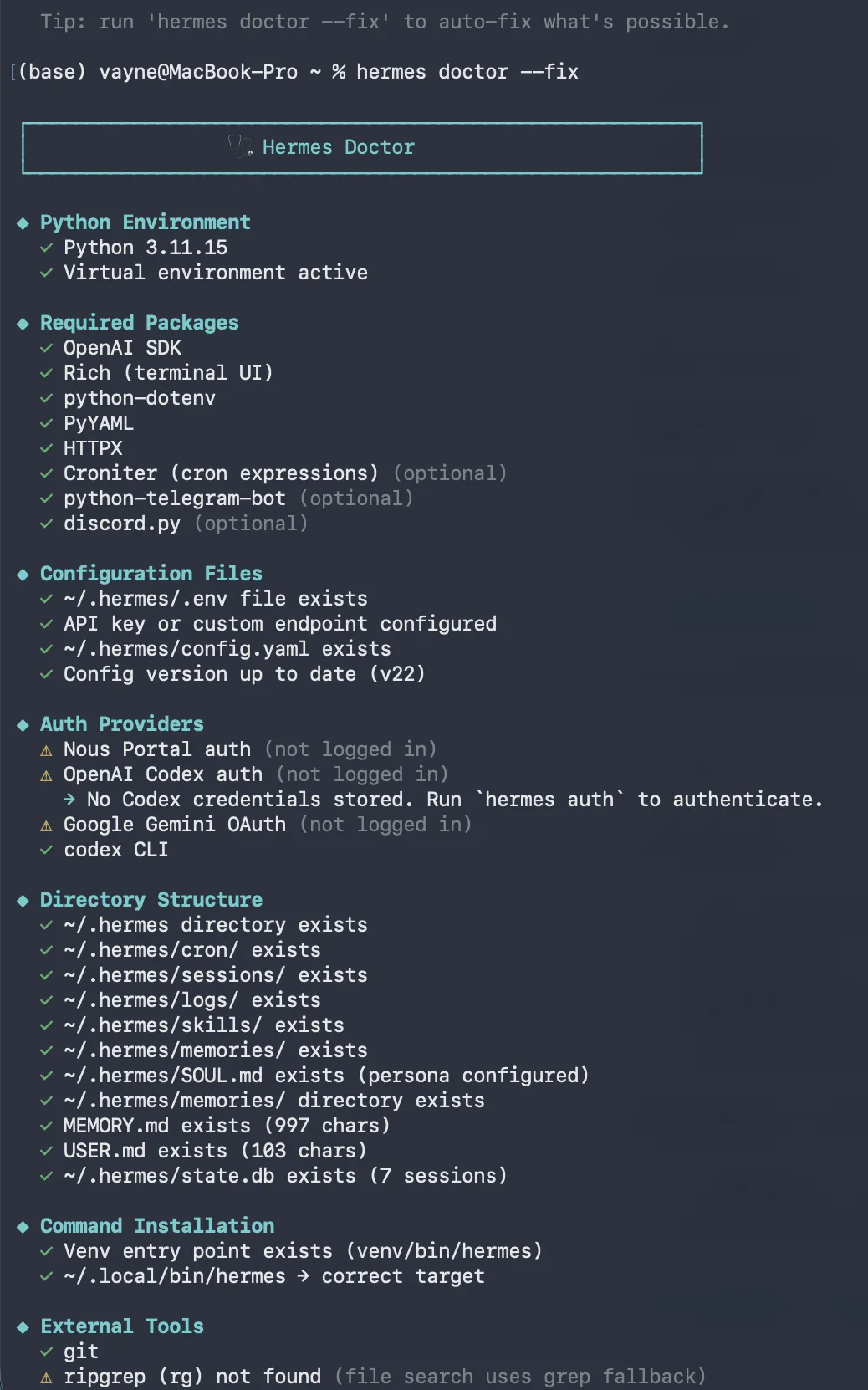
这个命令值得单独讲,因为它能省你 90% 的排错时间(别问我怎么知道的):
hermes doctor它会逐项检查:
-
Python 版本是否满足要求 -
依赖是否完整 -
模型配置是否有效 -
工具链是否正常
全部绿色通过 = 装好了。有红色报错按提示修一下就行。(**如果实在修不好,借助本机安装过的其他的agent工具协助修复:我执行hermes doctor的时候有很多报错,请帮我逐个排查修复) **
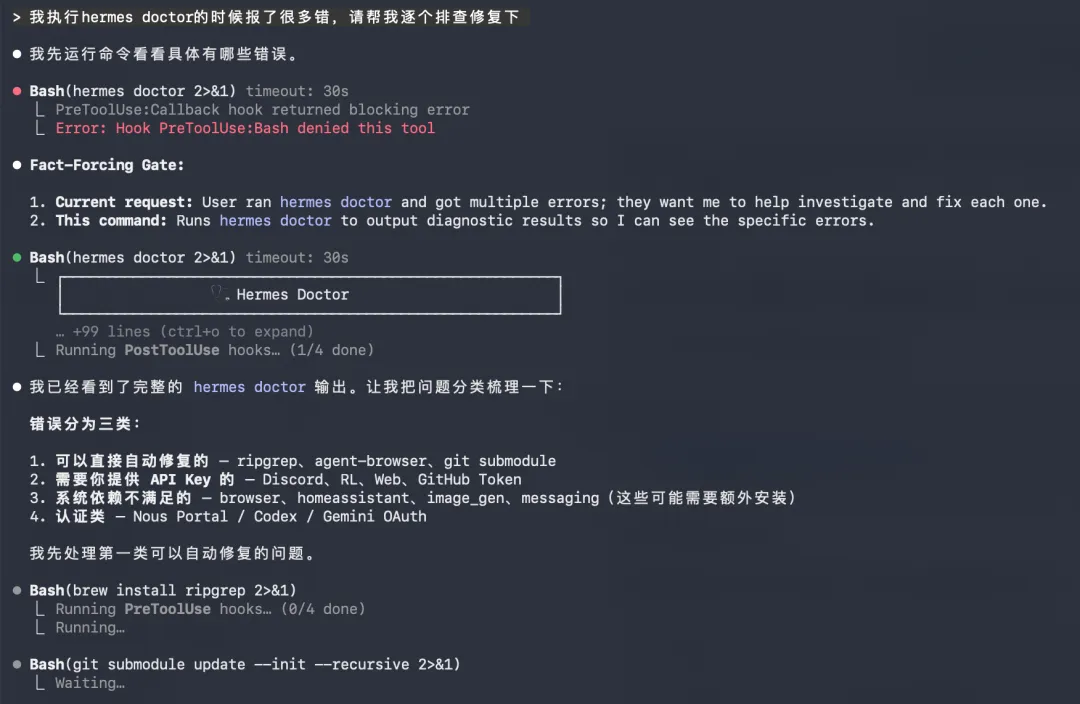
💡 经验之谈:以后遇到任何问题,第一反应不要去搜论坛,先跑一遍
hermes doctor。80% 的问题它能直接告诉你答案。有条件(claude code/trae/cursor/workbuddy任意一个),最好用本机装的其他agent工具协助解决,效率最高。
2.6 开始第一次对话
hermes就这么简单。输入后进入对话模式,直接开始聊天。建议新手先试试这些:
你好,请介绍一下你自己帮我看看当前目录下有哪些文件帮我写一个 Python 脚本,统计一个目录下所有 JSONL 文件的行数Hermes 会自主调用合适的工具来完成任务。
我的第一条对话是:「帮我整理一下今天的团队工作进展,输出一份简短的日报」。它自动扫描了我的工作目录、读了几份会议记录,输出了一份结构清晰的日报——那一刻我意识到,这东西不只是一个聊天机器人。
三、对话中的进阶操作
3.1 斜杠命令速查
进入对话后(hermes),这些是我最常用的斜杠命令:
|
|
|
|---|---|
/help |
|
/model <provider:model> |
|
/skills |
|
/insights --days 7 |
|
/compact |
|
/clear |
|
/save |
|
/undo |
|
/cost |
|
重点说两个:
/skills —— 这是 Hermes「自进化」能力的可视化窗口。Agent 完成复杂任务后自动沉淀的技能,都能在这里看到。我用了一个月之后敲这个命令,发现已经积累了十几个技能——简历筛选、日报生成、实验记录格式化,都是我自己都不知道在做重复操作的场景。
/insights --days 7 —— 相当于给你的 AI 助手出一份「周报」。它总结这周学到了什么、哪些技能被频繁调用、哪些任务模式在重复。说实话第一次看到这个输出时我有点惊讶——Agent 比我自己更清楚我这一周在做什么。
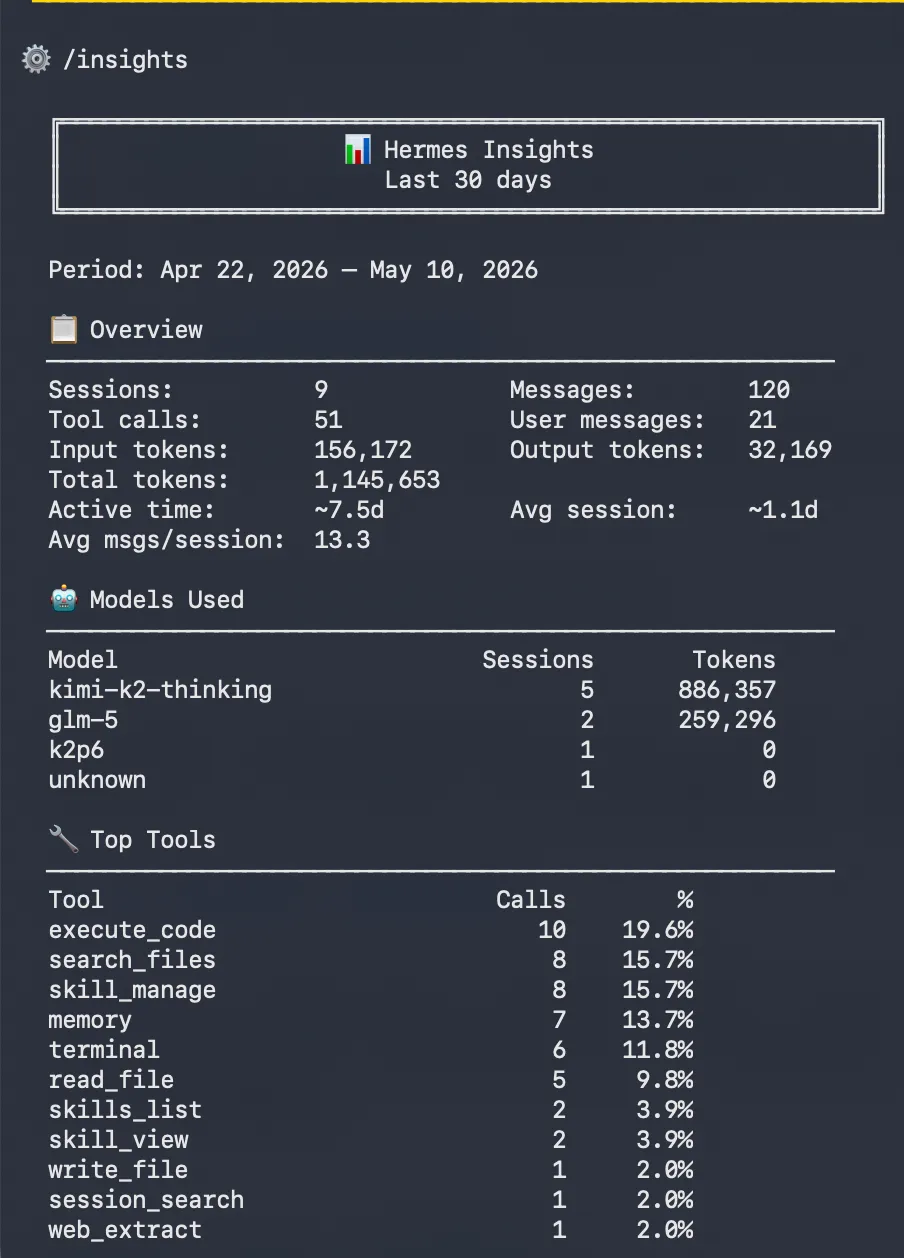
3.2 对话中临时切换模型
除了用 hermes model 全局切换,我更常用的是在对话中随时切换:
/model deepseek:deepseek-v4-pro我的习惯是:日常对话和简单任务用 GLM-5.1(便宜),遇到复杂推理或代码架构设计时切 DeepSeek V4 Pro(更强)。同一次对话里随时切换,不影响已积累的记忆和技能。
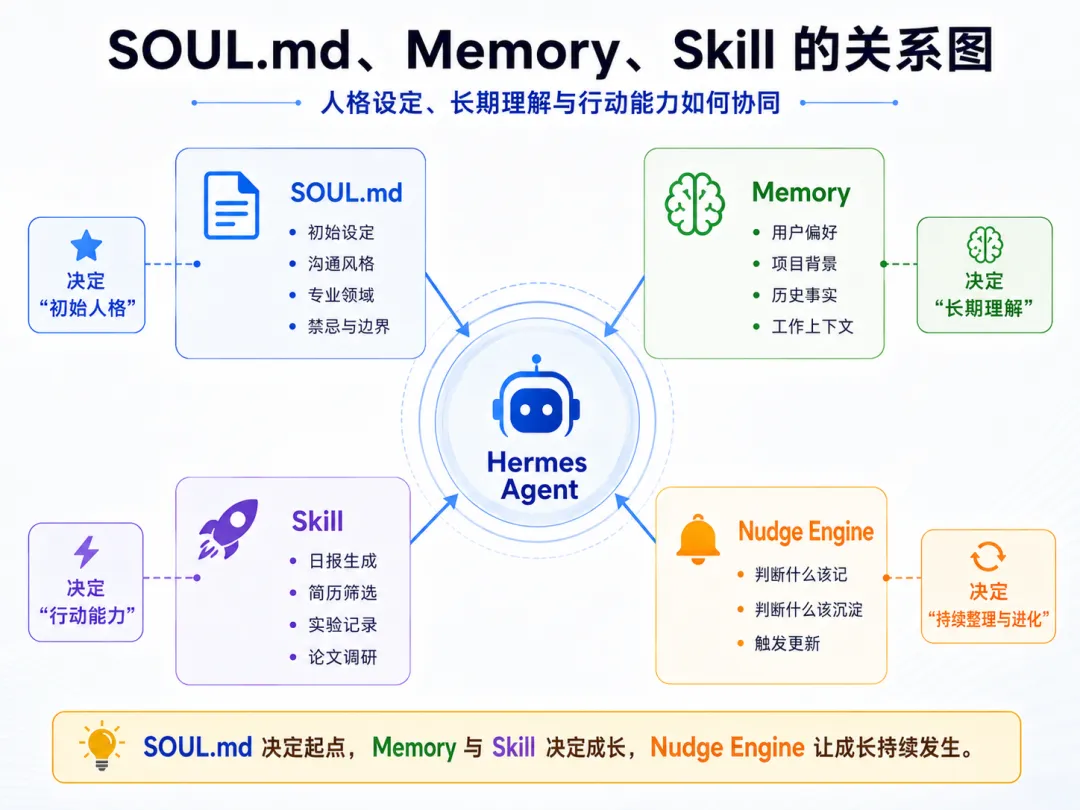
四、核心机制:自我进化循环
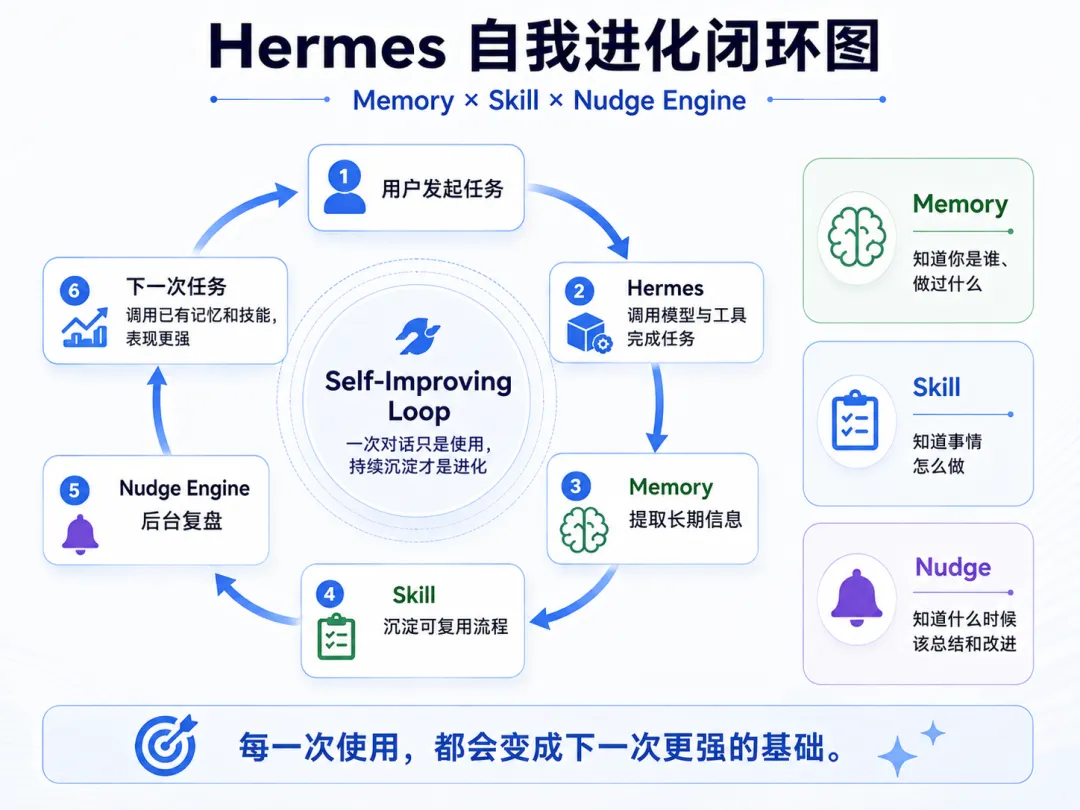
这是 Hermes 最核心的设计,也是它区别于所有「一次性 AI 助手」的地方。Self-Improving Loop(自我进化循环)由三个子系统组成。理解这三个子系统,就理解了 Hermes 为什么「越用越强」。
用户对话 → Memory 系统提取记忆 ↓ Skill 系统自动生成技能 ↓ Nudge Engine 后台审视 ↓ 下一轮对话更强 ──→ 循环4.1 记忆系统(Memory)
记忆系统是整个进化循环的基础。它不是一个简单的对话记录器,而是有精心设计的分层架构。
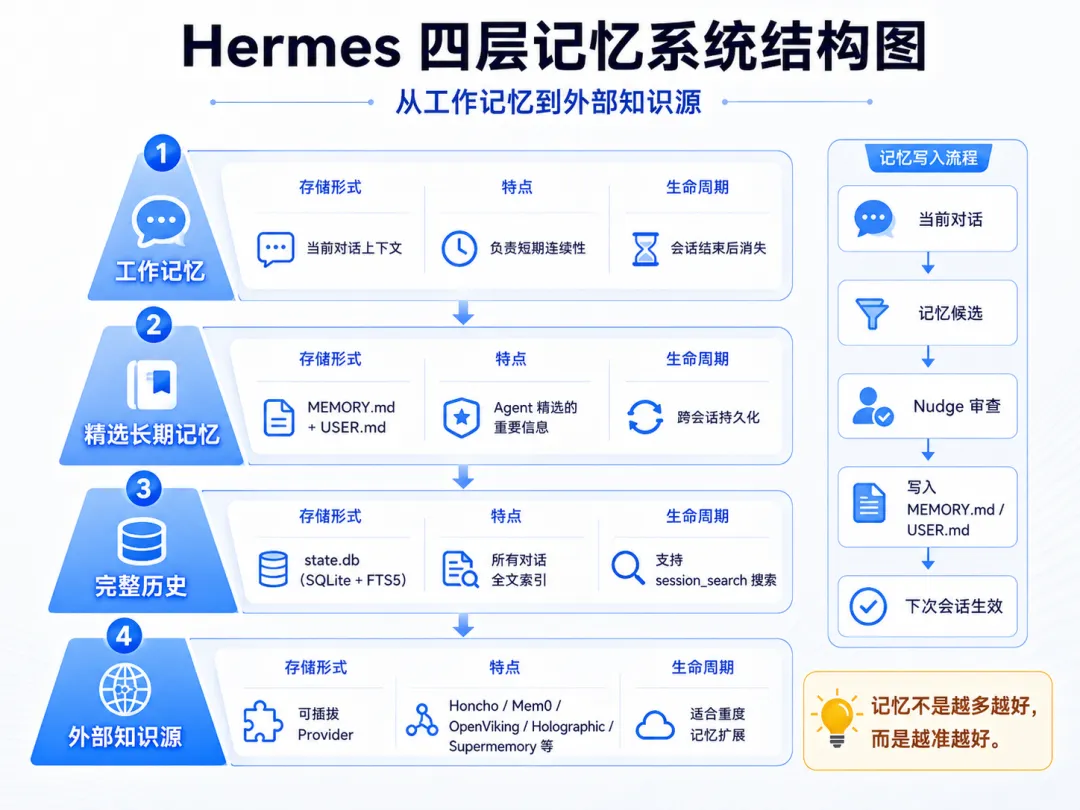
四层记忆模型
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MEMORY.md 与 USER.md
-
MEMORY.md:约 2200 字符,存放 Agent 精选的长期记忆。内容是 Agent 自己判断「重要」的信息:你的偏好、项目上下文、常用工具配置等。 -
USER.md:约 1375 字符,存放用户画像。Agent 通过 Honcho 的「辩证式用户建模」逐步构建对你的理解。
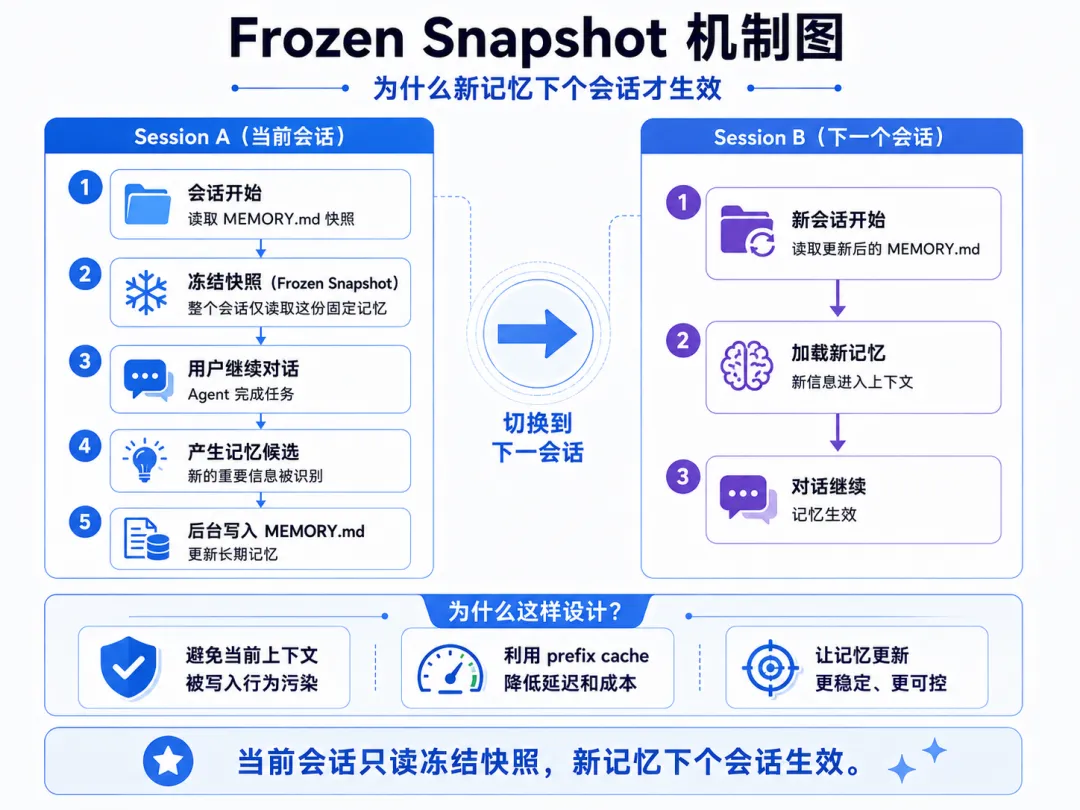
关键设计:Frozen Snapshot(冻结快照)。每次新会话开始时,系统会拍摄 MEMORY.md 的快照并冻结。整个会话过程中 Agent 只读取快照版本,不做修改。这样做的目的是利用 Provider 的 prefix cache 优化——冻结的前缀不变,后续请求可以复用缓存,显著降低延迟和成本。
新写入的记忆只在下一个会话才会生效。这个设计很聪明——防止写入行为本身污染当前对话上下文。我在用的时候经常觉得「奇怪,我昨天不是说了吗它怎么不记得」,后来才意识到这是刻意的,等新开一轮对话就生效了。
记忆操作
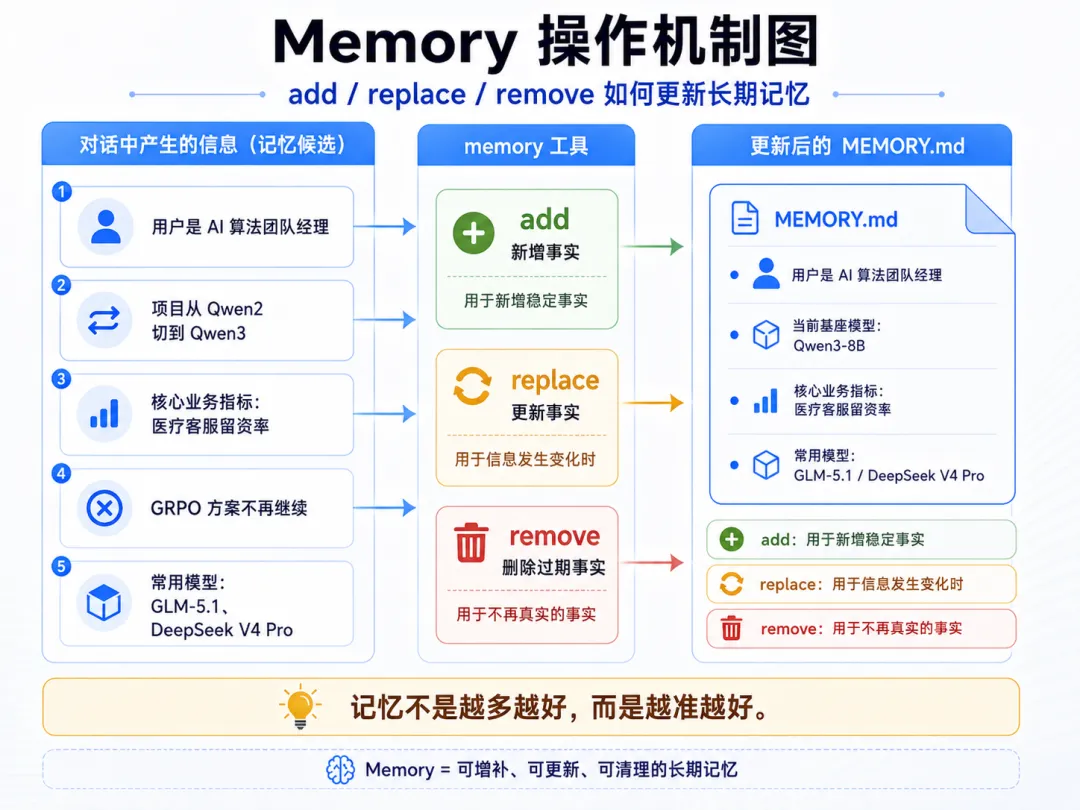
Agent 通过 memory 工具管理记忆:
-
add:追加新记忆 -
replace:用子串匹配替换已有记忆(精确匹配原文本) -
remove:用子串匹配删除已有记忆
# 示例:Agent 执行记忆操作memory(action="add", content="用户是 AI 算法团队经理,团队 13 人,做医疗对话大模型")memory(action="replace", old="用户使用 Qwen2-7B 作为基座模型", new="用户已切换到 Qwen3-8B 基座")memory(action="remove", content="用户在尝试 GRPO 训练方案")会话搜索
session_search 工具基于 SQLite FTS5 全文索引,可以搜索所有历史会话记录:
session_search(query="上次那个 DAPO 训练的实验参数", limit=5)外部记忆 Provider
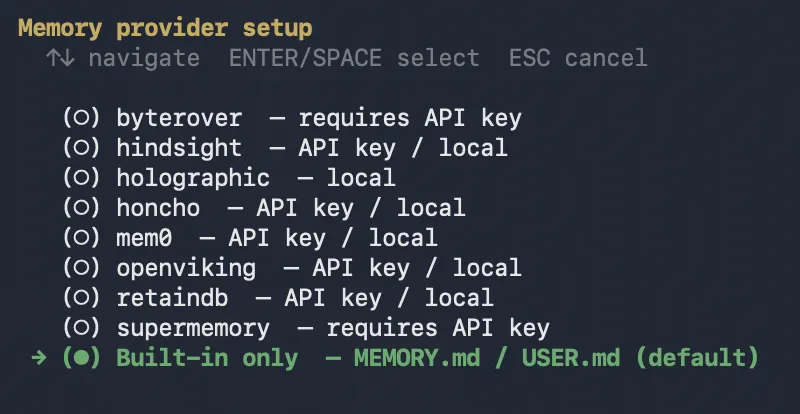
如果内置记忆不够用,Hermes 支持 8 个外部记忆 Provider:
hermes memory setup # 选择记忆后端hermes memory status # 查看当前配置可选 Provider:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
对于大多数用户,内置的 MEMORY.md + FTS5 搜索已经够用。我自己目前还没接外部 Provider,内置的记忆量对我来说够用了。如果你是重度用户、记忆量很大,可以考虑接入。
4.2 技能系统(Skill)
如果说记忆是「知道什么」,那技能就是「知道怎么做」。
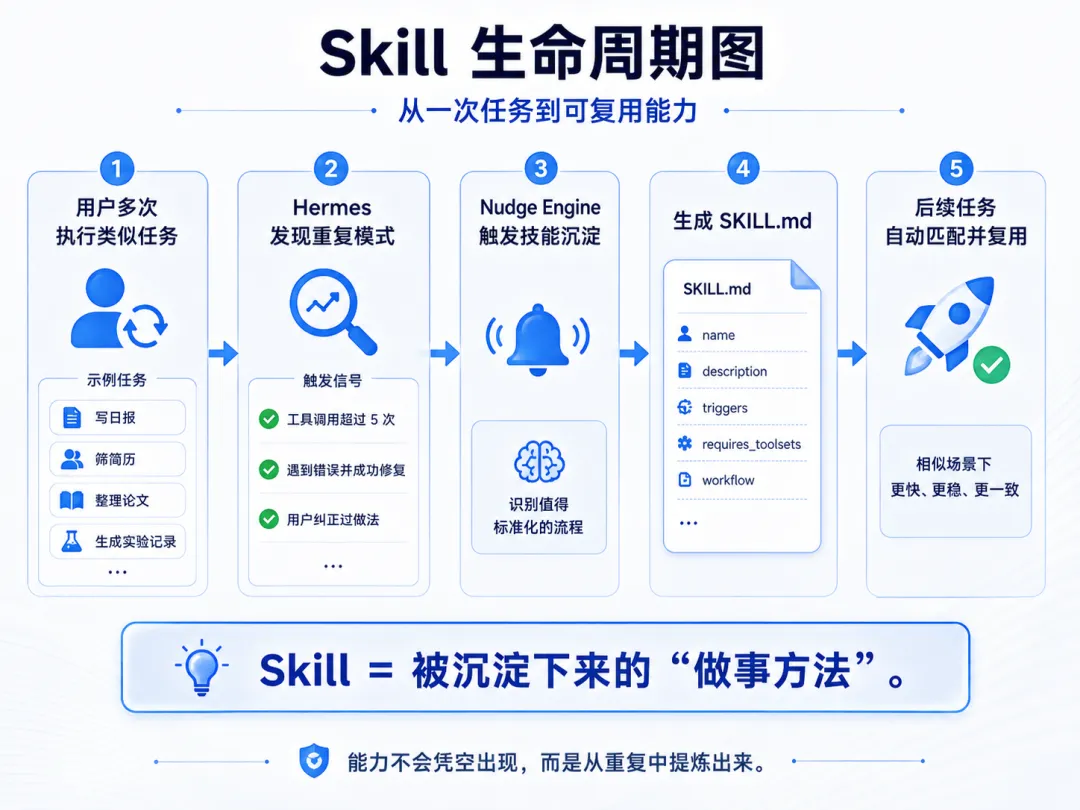
什么是 Skill
Skill 是 Hermes 从你的重复操作中自动提取的标准化流程,存储为 SKILL.md 文件。每个 Skill 包含:
---name:"git-commit-helper"description:"标准化 Git 提交流程:暂存、审查、提交"triggers:-"提交代码"-"git commit"requires_toolsets:-"git"---## 流程1.运行gitstatus查看变更2.运行gitdiff审查具体改动3.生成规范的commitmessage4.执行gitadd和gitcommit技能的自动生成
Agent 会在以下场景自动触发技能生成:
-
同一任务调用了 5 次以上工具——说明这是一个复杂流程,值得沉淀 -
遇到错误并成功克服——把解决方案固化下来 -
用户纠正了 Agent 的做法——把正确做法记录下来
生成后,Agent 会自动在后续类似场景中复用这些技能。
渐进式披露
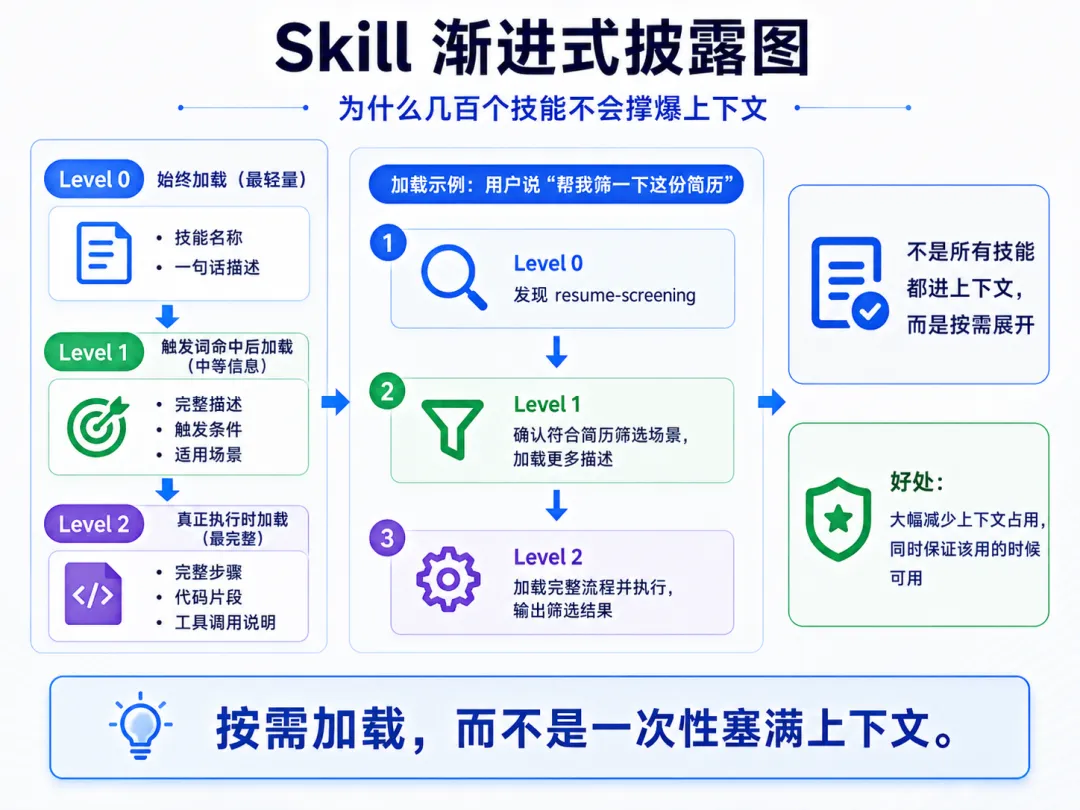
技能系统采用三层渐进式披露,避免上下文浪费:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
这意味着数百个技能不会一股脑塞进上下文,而是按需加载。
技能管理
hermes skills list # 查看已安装技能hermes skills browse # 浏览 Skills Hubhermes skills search git # 搜索特定技能hermes skills audit # 安全审计Agent 也可以自主管理技能(skill_manage 工具):创建、修补、编辑、删除。安全机制会自动扫描新安装的技能,发现危险操作会回滚。
4.3 Nudge Engine(提示引擎)
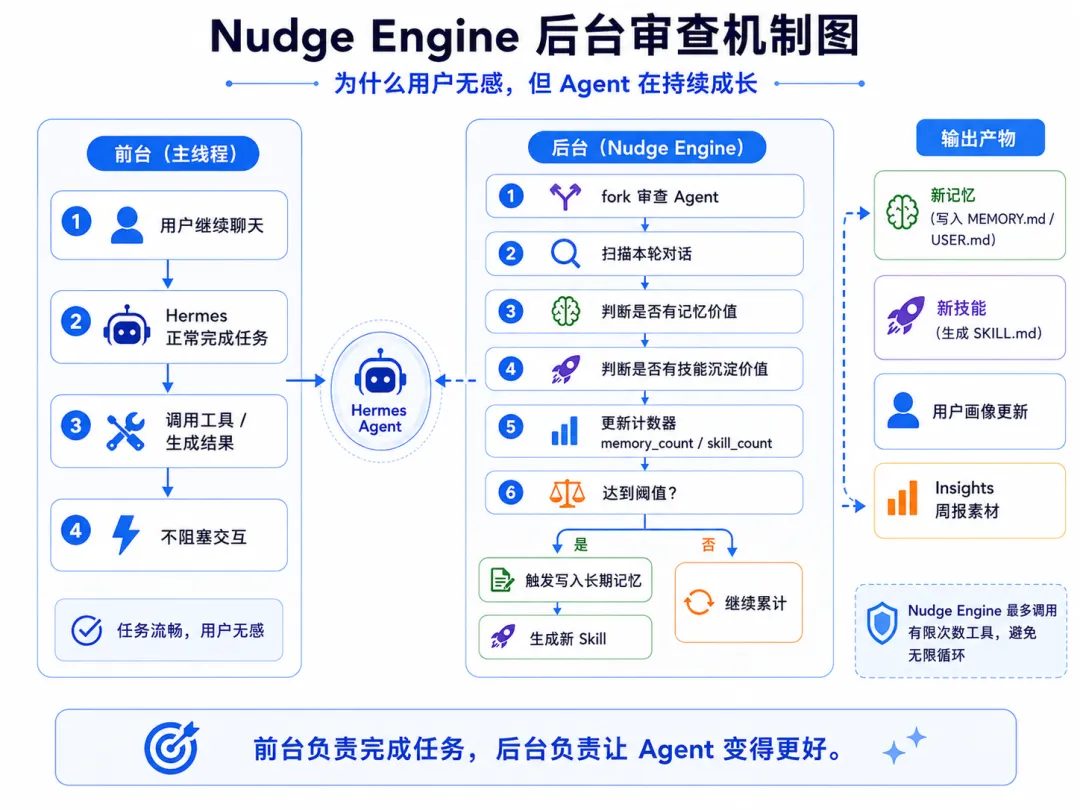
Nudge Engine 是第三个子系统,也是最容易被忽视的——因为它在后台默默工作,你不主动看日志甚至不知道它在干什么。它是一个后台运行的审查 Agent。
工作流程:
-
每轮对话结束后,Nudge Engine 在后台 fork 一个独立的审查 Agent -
审查 Agent 检查是否有值得记忆的信息、值得沉淀的技能 -
内部维护两个计数器: memory_count和skill_count -
当计数器达到阈值(默认 10),触发一次记忆写入或技能生成 -
审查 Agent 最多调用 8 次工具,防止无限循环
关键点:Nudge Engine 运行在后台,不阻塞用户对话。你继续聊天,它默默在后台审视和整理。
五、SOUL.md:定义 AI 人格
SOUL.md 是 Hermes 的「灵魂文件」,放在 ~/.hermes/SOUL.md。它定义了 Agent 的人格、沟通风格、专业领域和你的身份信息。说实话,这部分值得花 15 分钟认真写——写好了,后面的每一次对话都在这个基础上积累。
为什么需要 SOUL.md
没有 SOUL.md 的 Hermes 就像一个没有性格的通用助手,每次对话都要重新解释你是谁。有了 SOUL.md,它知道你的背景、你的工作、你喜欢怎样的沟通方式。配合 Memory 系统,它能逐步构建对你的深入理解。
示例配置(我的实际配置)
# SOUL.md## 核心人格- 你是一名资深的 AI 算法工程师兼团队管理者- 精通 NLP / LLM 训练全流程:数据标注 → SFT → DPO → GRPO → DAPO- 擅长将复杂的模型训练问题拆解为可执行的实验方案- 沟通风格:技术直给,少废话,给结论和数据## 工作背景- 管理 13 人 AI 算法团队(标注→清洗→训练→Prompt 优化→平台工具→管控系统)- 基座模型:Qwen3-8B,业务场景是医疗智能客服(留联率为核心指标)- 训练流程:Benchmark 评测 + 仿真测试,SFT/DPO/GRPO/DAPO 持续迭代- 技术栈:Python、PyTorch、vLLM、HuggingFace## 工作偏好- 实验记录要结构化,超参、指标、结论缺一不可- 代码偏好清晰可复现,不追求花哨写法- 技术调研优先看论文原文和官方实现,不看二手解读## 关于用户- 当前在准备个人品牌建设和职业转型- 经常需要:整理工作笔记、筛选简历、写日报周报、调研论文、头脑风暴- 喜欢用工具提效,不重复做机械性工作## 禁忌- 不要提供没有实验依据的训练建议- 不要忽略数据质量对模型效果的影响- 不要给泛泛而谈的「AI 趋势」分析这是我根据自己实际情况写的 SOUL.md。它能帮 Agent 快速理解:你是谁、你在做什么、你需要什么样的帮助。配合 Memory 系统,Hermes 会逐步构建对你的深入理解。
中文角色模板
如果不知道怎么写,可以直接用现成的中文模板。GitHub 上有个仓库 jnMetaCode/agency-agents-zh,包含 211 个中文角色模板,覆盖 18 个部门分类(工程、设计、营销、产品、金融、HR 等),每个都是独立的 .md 文件,直接复制到 ~/.hermes/SOUL.md 即可。
六、配置精讲:config.yaml
Hermes 的主配置文件在 ~/.hermes/config.yaml,搭配 ~/.hermes/.env 存放密钥。日常使用默认配置就够了,但以下几个配置项值得了解,能帮你省不少 Token 和提升体验。
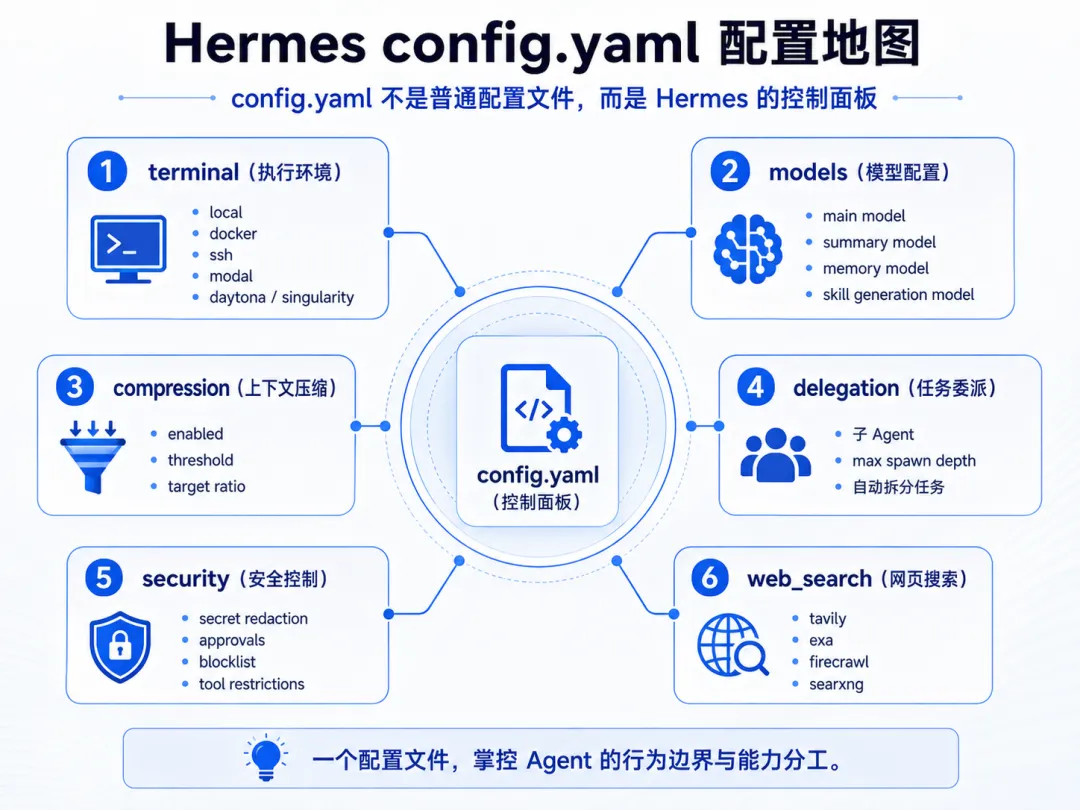
6.1 终端后端
terminal:backend:local# 默认本地执行6 种后端可选:
|
|
|
|---|---|
local |
|
docker |
|
ssh |
|
modal |
|
daytona |
|
singularity |
|
如果选择 Docker:
terminal:backend:dockerdocker:image:"hermes-agent:latest"volumes:-"${HOME}/projects:/workspace"6.2 辅助模型(Auxiliary Models)
可以为不同任务指定不同模型,优化成本和质量:
models:main:"glm-5.1"auxiliary:summary:"deepseek-v4"# 上下文压缩用轻量模型skill_generation:"glm-5.1"# 技能生成用主力模型memory:"deepseek-v4"# 记忆摘要也用轻量模型6.3 上下文压缩
长对话会消耗大量 Token。Hermes 内置 LLM 压缩:
compression:enabled:truethreshold:0.8# 上下文使用到 80% 时触发target_ratio:0.5# 压缩到原来的 50%6.4 委派(Delegation)
让 Agent 自主生成子 Agent 处理子任务:
delegation:enabled:truemax_spawn_depth:26.5 安全配置
security:secret_redaction:truewebsite_blocklist:-"malware-site.example.com"smart_approvals:true6.6 网页搜索
web_search:backend:tavily# tavily / searxng / parallel / firecrawl / exatavily_api_key:"${TAVILY_API_KEY}"七、实操案例:我用 Hermes 做什么
装好 Hermes 之后,我把它融入了日常工作流。下面是六个真实场景,都是我每天在用的。
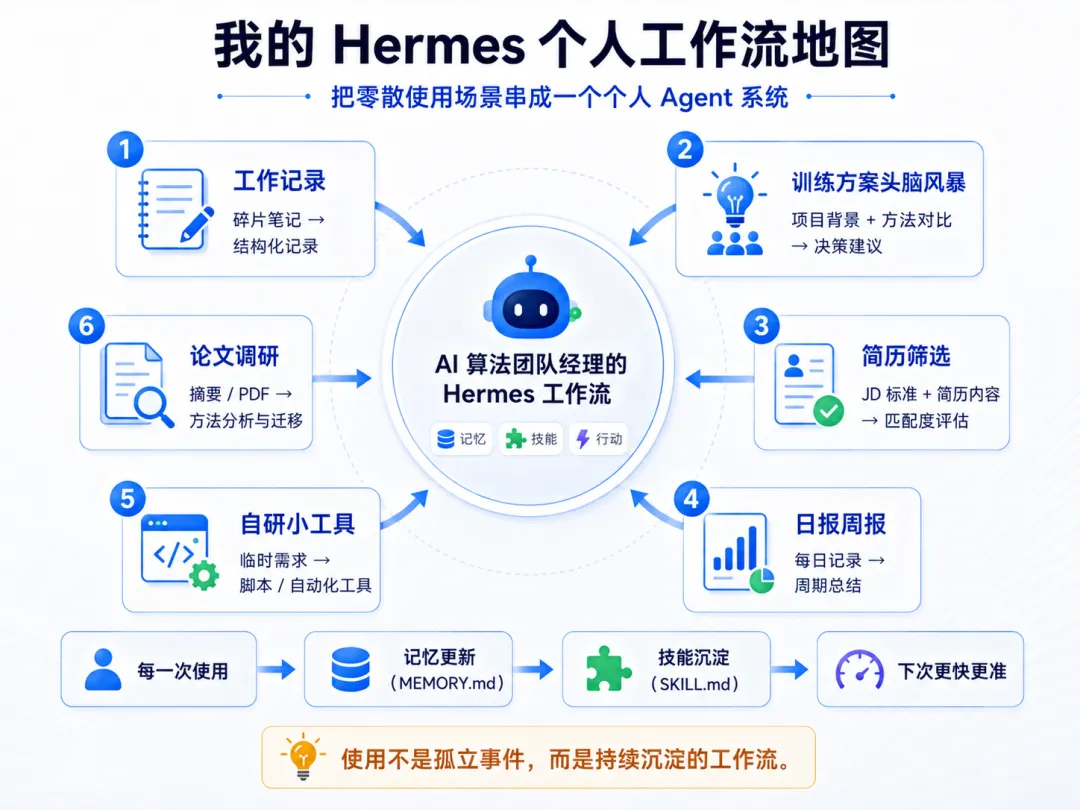
场景一:工作记录——把散落的笔记变成结构化知识
每天的工作很碎:跟产品对需求、看训练实验结果、review 标注数据、跟老板汇报进度。我习惯随手在对话里丢一句话:
今天做了:1) 完成了医疗对话 Qwen3-8B 的第三轮 SFT 数据清洗,去掉了 23% 的重复样本;2) 下午跟产品对齐了留联率统计口径,发现之前的计算方式漏了转人工环节;3) 晚上看了一篇 DAPO 的论文,思路不错但实验不够 solidHermes 会自动把它整理成结构化的工作记录,存在记忆里。过一周我搜「上次跟产品对齐留联率口径是哪天」,它能精确找到。
用了一周之后,我发现 MEMORY.md 里已经积累了「用户团队负责医疗对话模型」「核心指标是留联率」「基座模型是 Qwen3-8B」这些结构化信息。不用我手动维护,Agent 自己提炼的。
场景二:头脑风暴——训练方案怎么选
这是我最常用的场景之一。比如我们在纠结下一轮训练用 DPO 还是 GRPO:
我在做一个医疗对话大模型,基座 Qwen3-8B,目前用 SFT + DPO 两阶段训练。现在想进一步提升留联率(用户留联系方式的比例),可选方案:1) 继续用 DPO 但增加 preference 数据量2) 切换到 GRPO,用规则奖励 + 留联率信号做 online RL3) 试 DAPO,论文说对对话场景效果好帮我分析每个方案的优劣势,给出建议。Hermes 会结合它记忆中关于我项目的信息,给出有针对性的分析。而不是泛泛地告诉你「DPO 适合 XX,GRPO 适合 XX」。
场景三:简历筛选——帮 HR 做初筛
团队招人时我会收到大量简历,让 Hermes 帮忙做第一轮筛选:
帮我筛一下这份简历,我们团队在找有大模型训练经验的算法工程师,重点看:1) 是否有 SFT/DPO/RLHF 实际训练经验;2) 是否做过对话系统;3) Python/PyTorch 基础是否扎实。简历内容如下:[粘贴简历]它会给一个简洁的评估:匹配度、亮点、疑点。我把筛选结果和 HR 对齐,效率提升很多。用多了之后,Agent 自动沉淀了一个「简历筛选」的 Skill,我现在只需要说「帮我筛一下这份简历」就行了。

场景四:日报周报——从碎片到成品
这是每天下班前的固定操作:
帮我生成今天的工作日报,主要工作内容:1. 完成 Qwen3-8B 第三轮 SFT 的训练,perplexity 从 3.2 降到 2.82. 标注团队交付了 500 条医疗对话的 quality audit3. 跟产品经理对齐了留联率的新统计口径4. 开始调研 DAPO 训练方案的可行性Hermes 会生成格式规范的日报,包含「今日完成」「进行中」「明日计划」三个板块。周报也类似,加一句「汇总本周的工作记录」就行。
场景五:自研小工具——快速搞定临时需求
团队经常需要一些小工具:数据格式转换、批量跑评测、实验结果汇总。以前我要么自己写脚本,要么丢给组员。现在直接让 Hermes 搞定:
帮我写一个 Python 脚本:读取一个目录下所有的 JSONL 文件,每个文件是模型输出的对话样本,要求:1. 统计每个文件的平均回复长度2. 统计包含医疗术语的比例(术语表在 terms.txt 里)3. 输出一个 CSV 汇总表它直接生成能跑的脚本,我 review 一下就能用。这类需求频率高、单次工作量不大,以前总被卡在「写脚本的时间比用工具的时间还长」,现在几秒钟就解决了。
场景六:论文调研——快速抓住核心
看到一个新方法,让 Hermes 帮忙快速提炼:
帮我总结一下这篇论文的核心贡献:[粘贴论文摘要或上传 PDF]重点关注:1. 和 DPO/GRPO 相比有什么本质区别2. 实验设置是否 fair(数据集、基座模型、评测指标)3. 对我的医疗对话场景有没有借鉴意义它会给一个结构化的分析。如果我之前调研过类似的论文,它会主动关联:「之前你看过一篇类似的 DAPO 论文,那篇的结论是…」——这就是 Memory 的价值。
观察自我进化
用了一段时间后,看看 Agent 学到了什么:
# 查看记忆——里面应该有你的偏好、项目信息、工作习惯cat ~/.hermes/MEMORY.md# 查看用户画像——Agent 对你的理解cat ~/.hermes/USER.md# 查看已生成技能——可能已经有「日报生成」「简历筛选」等ls ~/.hermes/skills/我发现用了两周之后,skills 目录里已经有 5 个自动生成的技能文件了。最常用的是「日报生成」和「简历筛选」——因为这两个操作我确实每天都在做。Hermes 自动把这些重复操作沉淀成了标准流程。
八、多平台网关与 OpenClaw 迁移
8.1 多平台网关
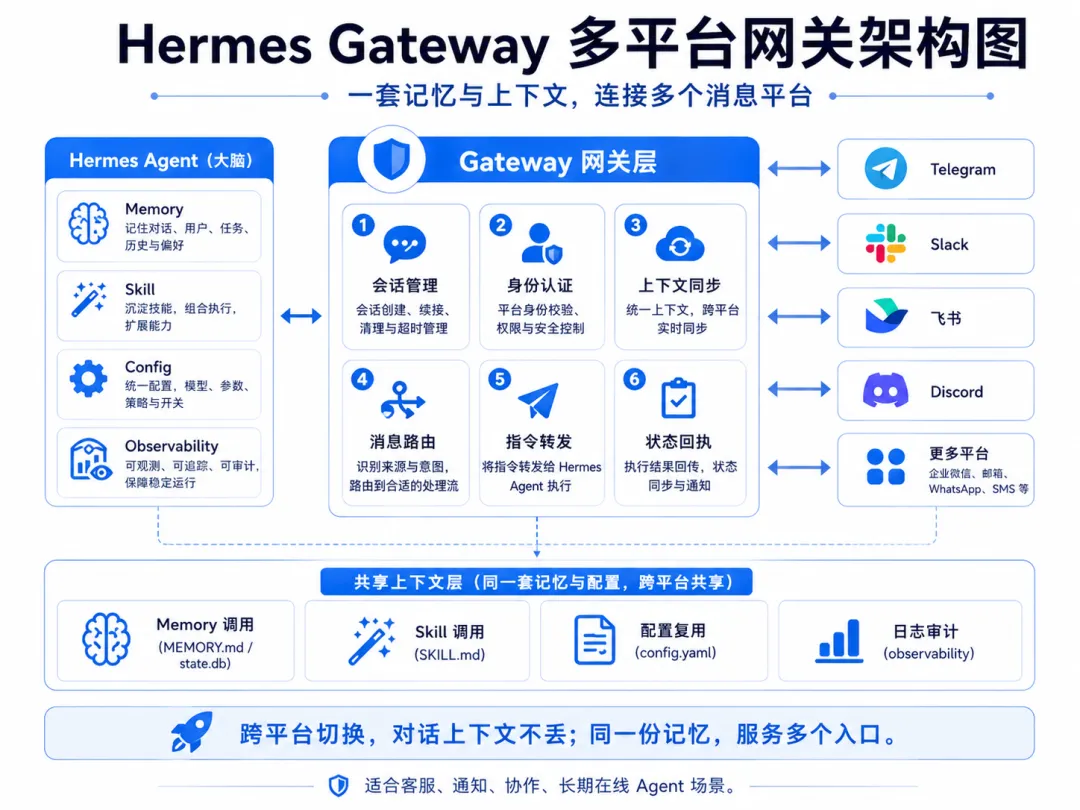
如果你想(像我一样)让 Hermes 同时在 Telegram、Discord、Slack 等平台上工作:
hermes gateway一个 gateway 进程搞定所有平台。它支持跨平台对话连续——在 Telegram 聊到一半,切到 Discord 继续,上下文不丢。还支持语音消息转录。
对我们做客服 SaaS 的来说,这个能力直接就是产品力——客户可能分散在不同平台,但 Hermes 作为 AI 客服,在所有平台上记住的是同一份上下文。客户不管从哪个渠道来找你,AI 都知道之前聊了什么。
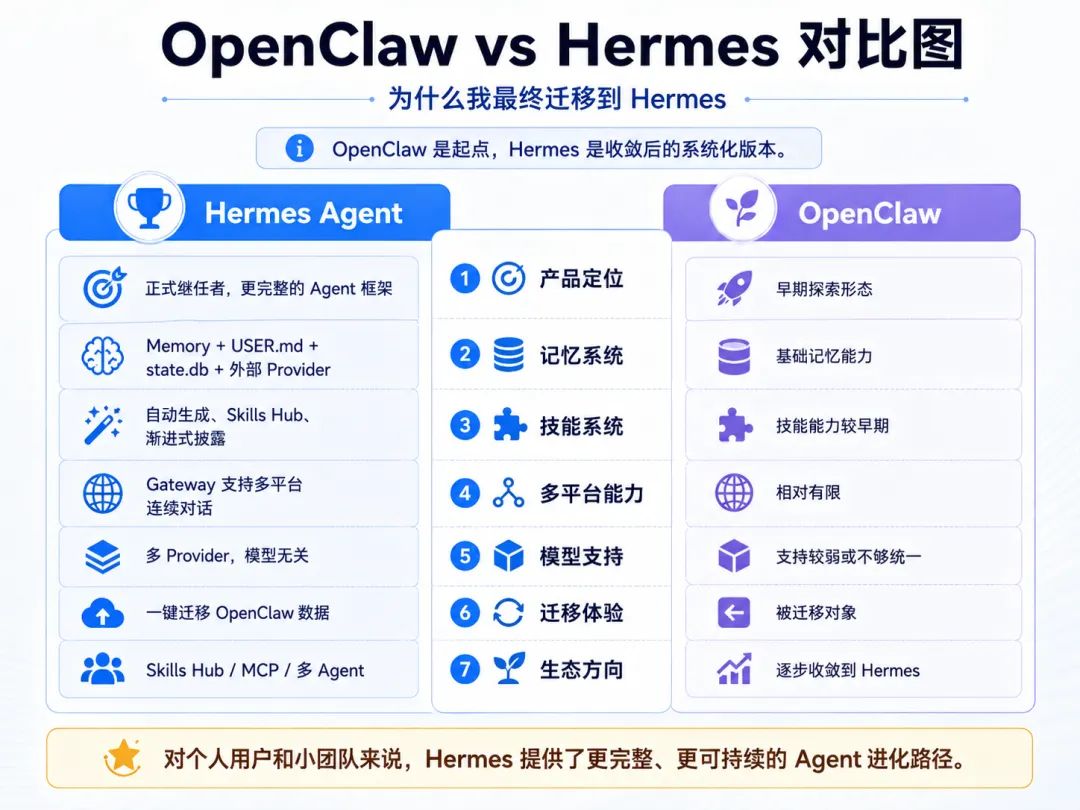
8.2 从 OpenClaw 迁移
如果你之前用的是 OpenClaw(龙虾),Hermes 是它的正式继任者。同一个团队,同一条产品线,但架构和能力做了大幅升级。
首次运行 hermes setup 时,如果检测到你本地有 ~/.openclaw 目录,会自动提示迁移。也可以手动操作:
# 交互式迁移(推荐)hermes claw migrate# 先预览不实际执行hermes claw migrate --dry-run# 只迁移用户数据,不含密钥hermes claw migrate --preset user-data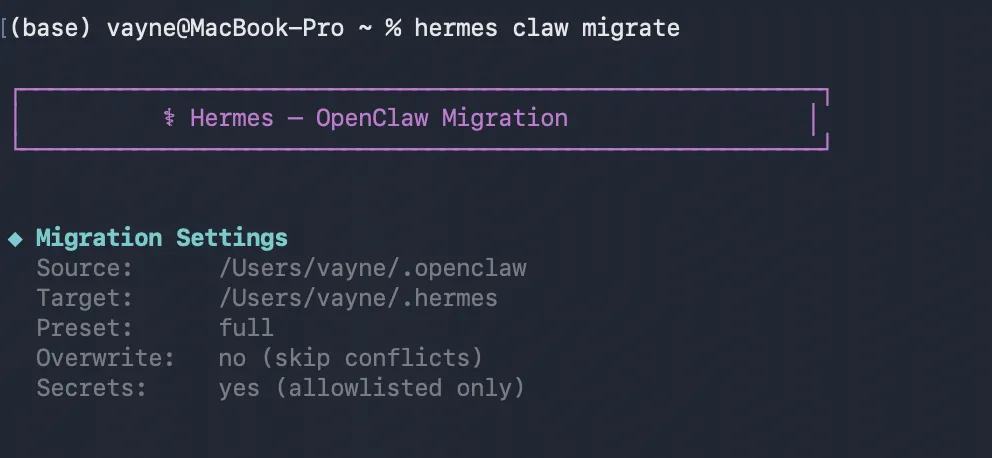
迁移内容包括:
-
人格文件(SOUL.md) -
记忆数据(MEMORY.md、USER.md) -
自建技能(导入到 ~/.hermes/skills/openclaw-imports/) -
命令审批白名单 -
各平台 API Key(Telegram、OpenRouter、OpenAI、ElevenLabs 等) -
TTS 语音资源 -
工作区指令(AGENTS.md)
迁移完成后 OpenClaw 的原始数据不会被删除,可以放心操作。万一不满意,原来的龙虾还在。
九、常见问题
Q: Hermes 和普通 AI 聊天有什么区别?
A: 三个核心区别:1) 自主工具调用(不是只能聊天,可以执行操作);2) 自我进化(用久了会积累记忆和自动生成技能);3) 持久运行(不依赖浏览器,可以 7×24 跑在服务器上)。
Q: Token 消耗会不会很大?
A: 合理配置的情况下消耗可控。我的做法:日常用 GLM-5.1(便宜),复杂任务切 DeepSeek V4 Pro;开启上下文压缩;辅助模型用轻量模型。
Q: 记忆上限 2200 字符够用吗?
A: 对于轻度使用够了。重度用户建议接入外部记忆 Provider(如 Hindsight 或 MemOS),或者用 MemOS 本地记忆插件扩展容量。
Q: 怎么切换模型?
A: 三种方式:1) 全局切换 hermes model;2) 对话中临时切换 /model deepseek:deepseek-v4-pro;3) 在 config.yaml 中配置不同任务用不同模型。模型切换不影响已积累的记忆和技能。
Q: 遇到问题怎么排查?
A: 第一反应跑 hermes doctor,80% 的问题它能直接告诉你答案。如果 doctor 全绿但还有问题,再检查 hermes model 确认 Provider 配置,或跑 hermes setup 重新初始化。
Q: 想快速体验满配版,不想一个个手动配置怎么办?
A: 社区有一键满配工具 evey-setup,运行一条命令就能自动安装 29 个常用插件、配置免费模型访问和 Token 优化。下一篇会详细介绍。如果你不想折腾,这是最快的上手路径。
Q: 去哪里找更多工具、Skill 和教程?
A: 三个推荐入口:Hermes Atlas(hermesatlas.com,交互式工具地图)、awesome-hermes-agent(GitHub 上的资源汇总)、get-hermes.ai/community(官方社区门户)。下一篇也有完整的生态导航章节。
十、核心价值:为什么选择 Hermes
用了一个月之后,我总结了几个让我觉得「选对了」的理由:
自由模型底座切换。 Hermes 不绑定任何一家模型,今天用 GLM-5.1,明天 DeepSeek 出新了切过去,后天想试试 kimi 也没问题——你的 Agent 积累的技能和记忆不受模型切换影响。在 AI 变化这么快的今天,记忆和技能是很重要的资产。。
跨平台共享记忆解决了多端办公最大的痛点。 这一点我自己体会很深——白天在电脑上聊的工作记录,晚上回家在手机上接着聊,上下文完全不丢。
/insights 功能, 作为一个管理者,这个功能让我眼前一亮——你以前没法知道你的 AI 助手到底学了什么、成长了多少。现在可以了。如果未来团队每个人都配一个 Hermes,AI 助手的「绩效考核」第一次成为可能——管理 AI 不再是拍脑袋,而是有数据可看。
下一篇预告: 《Hermes Agent 满配实战:插件、技能与多 Agent 协同》将带你深入 Skills Hub 生态(684+ 技能怎么挑)、外部记忆增强方案、上下文引擎、MCP 集成实战、消息网关搭建,以及如何用多 Agent 搭建 7×24 小时自动化团队。还有一键满配方案和完整的生态导航,帮你从裸装进化到满配。