 夜雨聆风
夜雨聆风





让智能体真正“学会做事”:OpenClaw-Skill 用技能树训练长程 Agent
-
来源:arXiv
-
原文标题:OpenClaw-Skill: Collective Skill Tree Search for Agentic Large Language Models -
作者:Tianyi Lin, Chuanyu Sun, Jingyi Zhang, Changxu Wei, Huanjin Yao, Shunyu Liu, Xikun Zhang, Liu Liu, Jiaxing Huang -
机构:The Hong Kong Polytechnic University;Nanyang Technological University;Tsinghua University;Royal Melbourne Institute of Technology -
原文链接:http://arxiv.org/abs/2606.16774v1
这是「每日 AI 深读」:每天只深入读一个高信号的论文,不追热点数量,只抓住一个真正值得带走的思路。读完它,希望你今天对 AI 的理解多前进一点点。
这篇论文的核心贡献可以用一句话概括:它不是只教大模型某个零散技巧,而是提出了一套自动构建“技能树”的方法,让 Agent 在复杂任务中能更系统地规划、调用工具、检查反馈、修复错误,并且这些技能尽量能跨模型迁移。
这里的背景很重要。今天的 LLM Agent 已经不只是聊天模型,它们会读文件、改代码、跑命令、看网页、调用工具、根据报错继续修复。论文中提到的 OpenClaw 类系统,就是这种真实交互环境:模型需要在多步任务里协调文件、工具、网页、执行反馈和中间产物。
问题是,复杂 Agent 任务往往不是“一步答对”就结束。它更像一次小型工程流程:先理解目标,再定位文件,再检查配置,再构造命令,再执行,再看错误,再修复,再验证。过去很多所谓“技能”只覆盖其中一个局部动作,比如“如何调用某个工具”或“如何根据报错改命令”。这些技能有用,但容易碎片化,缺少结构,也未必能迁移到别的模型上。
OpenClaw-Skill 想解决的,正是这个问题。
这篇论文想解决什么问题
论文把当前自动技能构建方法的不足归纳为三类。
第一类是 Skill Fragmentation,技能碎片化。也就是说,已有方法常常从某条执行轨迹里总结出一个局部经验,但这个经验只适合一个小步骤。它可能知道“遇到某种错误时重试”,却不知道这个动作应该放在整个任务流程的哪一层,也不知道前后步骤如何衔接。
第二类是 Limited Skill Diversity,技能多样性不足。很多方法依赖单个模型生成轨迹,再从这些轨迹中抽取技能。问题是,每个模型都有自己的偏好:有的喜欢先读 README,有的喜欢直接搜文件,有的喜欢多跑测试,有的偏向推理解释。只靠一个模型,抽出来的技能也会带着这个模型的路径依赖。
第三类是 Poor Transferability,迁移性差。一个模型总结出来的技能,换到另一个模型上未必有效。比如某个技能描述对强模型来说足够明确,但小模型理解不了;或者某个技能依赖特定模型的推理习惯,其他模型照着做反而效果下降。
论文 Figure 1 就是在讲这个动机。
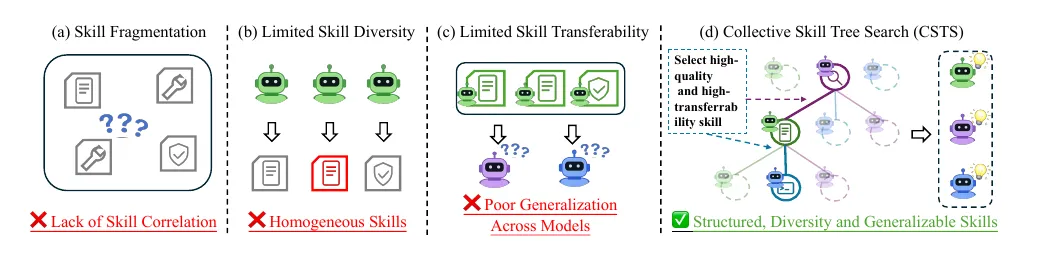
这张图的重点不是“又提出一个 skill bank”,而是把技能从孤立片段变成结构化、可组合、可筛选的树。树上的每一层对应复杂任务中的一个子任务,每个节点是候选技能,穿过这棵树的一条路径就是一套完整的解题流程。
换句话说,作者想让 Agent 学到的不是“一个锦囊”,而是一套能串起来用的工作流。
这篇最值得学的点
这篇最值得长期记住的点是:复杂 Agent 的能力提升,不只是靠更多轨迹训练模型,而是要把轨迹中的过程知识组织成可组合、可评估、可迁移的结构。
很多 Agent 训练工作容易停留在“收集成功轨迹,然后监督微调”这一层。但真实任务里,成功轨迹本身并不等于可复用能力。因为一条轨迹可能只是偶然成功,里面混着无效动作、模型偏好、环境巧合和不可迁移的步骤。
OpenClaw-Skill 的思路更进一步:它先把复杂任务拆成子任务,然后针对每个子任务让多个模型探索不同做法,再让多个模型评估这些技能的质量和迁移性,最后把技能组织成树,并用这些技能增强训练。
这件事的启发是:Agent 时代的“知识蒸馏”不应该只蒸馏答案,也不应该只蒸馏完整轨迹,而应该蒸馏“可复用的程序性策略”。也就是:什么时候查文件,什么时候运行命令,什么时候相信工具输出,什么时候怀疑结果,什么时候回退,什么时候验证完成。
这比单纯让模型背更多问答,更接近真正的工程能力。
方法拆解:CSTS 如何构建技能树
论文方法分成两部分:CSTS 和 CSRL。
CSTS 是 Collective Skill Tree Search,中文可以理解为“集体技能树搜索”。它负责自动构建技能树。
CSRL 是 Collective Skill Reinforcement Learning,中文可以理解为“集体技能强化学习”。它在训练阶段让模型基于不同技能探索解法,并学习更优的技能使用策略。
先看 CSTS。
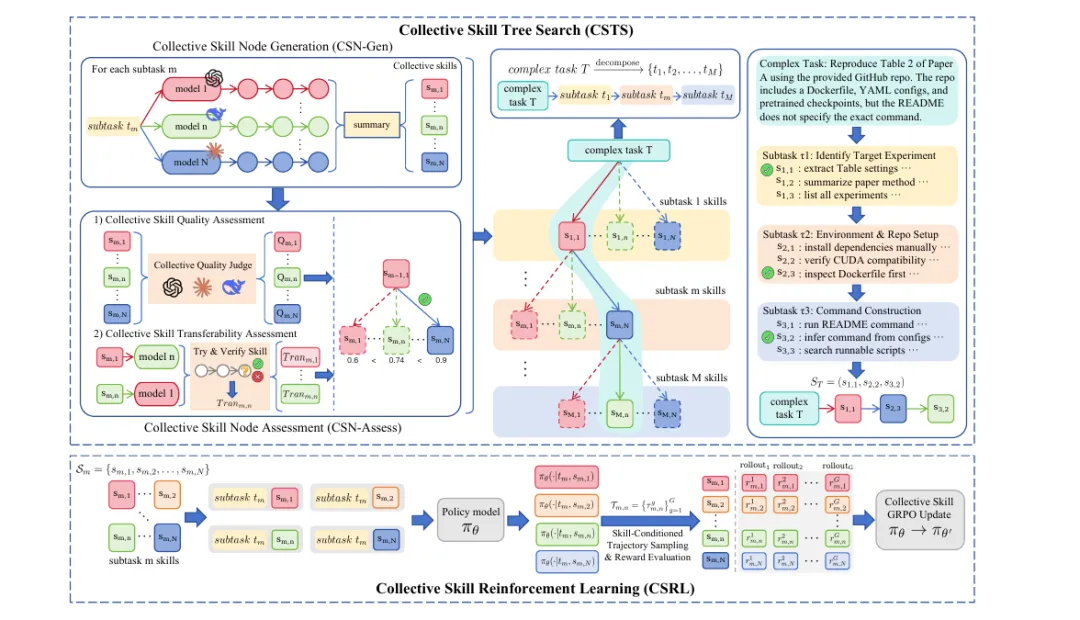
Figure 2 展示了整个 OpenClaw-Skill 框架。给定一个复杂 Agent 任务,CSTS 先把任务拆成多个子任务,然后在每个子任务上生成候选技能,再评估和筛选技能,最终形成一棵技能树。之后,这些技能树和技能增强轨迹会被用于模型训练,CSRL 则进一步优化模型如何选择和使用技能。
第一步:复杂任务分解
论文中,给定一个复杂任务 T,CSTS 会先把它拆成有序子任务:
TL;DR:这个公式只是在说,一件复杂任务会被拆成多个按顺序执行的小阶段,技能树的深度就来自这些阶段。
T -> (t1, t2, ..., tM)用日常语言解释:
-
T:原始复杂任务,比如完成一次真实环境中的代码修复、文件处理或网页交互任务。 -
t_1, t_2, …, t_M:被拆出来的一系列子任务。 -
M:子任务数量,也就是技能树的层数。
论文举的子任务类型包括:定位文件、检查配置、构造命令、执行工具、诊断失败、验证输出等。
这个设计非常符合真实 Agent 工作方式。复杂任务不是一团乱麻,而是由多个阶段组成。CSTS 先确定这些阶段,再在每一层寻找适合这一阶段的技能。
第二步:CSN-Gen,集体生成候选技能节点
CSN-Gen 是 Collective Skill Node Generation,意思是“集体技能节点生成”。
它的做法是:同一个子任务,不只让一个模型来做,而是让一组模型都来尝试。每个模型都会产生自己的执行轨迹。然后系统从这些不同轨迹中总结候选技能节点。
论文用公式描述每个模型在某个子任务上的轨迹:
TL;DR:这个公式别被符号吓到,它只是把一个模型完成某个子任务的全过程拆成“思考状态、动作、观察反馈、最终结果”。
M = {M1, M2, ..., MN}TL;DR:下面的公式先看中文意思:它不是让你记符号,而是在说明系统把哪些因素放进同一个判断或训练目标里。
τm,n = πθn(· | tm)逐项解释如下:
tm:当前第 m 个子任务。Mn:第 n 个参与模型。τm,n:第 n 个模型在第 m 个子任务上的执行轨迹。ψ:模型执行过程中的中间推理状态。a:模型采取的动作,可能是工具调用、文件操作、代码执行,也可能是文本回复。o:环境返回的观察结果或执行反馈,比如命令输出、报错、文件内容。r:最终执行结果或正确性信号。
这一步的关键价值是“多样性”。不同模型会尝试不同路径,也会暴露不同失败方式。比如一个模型先读配置,一个模型先跑测试,一个模型先查日志。把这些轨迹放在一起,系统就能看到更丰富的过程证据。
第三步:CSN-Assess,集体评估技能质量和迁移性
CSN-Assess 是 Collective Skill Node Assessment,意思是“集体技能节点评估”。
它有两个评分机制。
第一个是 collective quality scoring,集体质量评分。多个模型作为 judge,对候选技能进行独立评估,再聚合得到更稳健的质量估计。
这里的 judge 不是法律意义上的裁判,而是“评审模型”。它们会判断某个技能是否真的有效、是否清晰、是否能指导子任务执行。
第二个是 collective transferability scoring,集体迁移性评分。它不只看技能在原模型上是否有效,还会显式验证这个技能能不能迁移到不同模型上。
这点很关键。因为 Agent 技能如果只对生成它的模型有效,就很像某个人的私人笔记;而论文想要的是可复用技能,最好能帮助不同 backbone。
这里也可以解释一下 rubric。Rubric 通常指“评分规约”或“评分标准表”,也就是评估时明确规定看哪些维度、每个维度怎么打分。材料中没有给出具体 rubric 细则,所以不足以判断作者在质量评分和迁移性评分中使用了哪些完整指标。但从描述看,它至少区分了技能本身质量和跨模型可迁移性这两类目标。
技能树到底是什么
CSTS 最终构建的是 tree of skills,也就是技能树。
这棵树里:
-
每一层对应一个子任务。 -
每个节点是某个子任务上的候选技能。 -
从根到叶的一条路径,代表一套跨子任务组合起来的技能路径。
这和普通 skill bank 很不一样。Skill bank 更像一个工具箱,里面有很多工具,但不知道什么时候按什么顺序用。技能树则把“顺序”和“组合关系”显式编码进去,更适合长程任务。
如果用 deep research agent 作类比,它不是只需要“搜索网页”这个技能,也需要一整套流程:提出查询、打开来源、交叉验证、提炼证据、回到问题、补查缺口、最后组织答案。OpenClaw-Skill 面向的是类似这种长程、多反馈、多工具的 Agent 能力,只不过论文实验侧重的是 OpenClaw、QwenClawBench 和 PinchBench 这类真实交互任务。
CSRL:让模型学会在多种技能中选择
CSTS 构建出技能树之后,论文还引入了 CSRL,也就是 Collective Skill Reinforcement Learning。
材料中没有给出完整奖励函数细节,因此不足以判断 CSRL 是否使用了某个具体奖励权重,例如 0.5/0.2/0.2/0.1 这类设置。材料也没有明确说明它是否采用 GRPO。
这里顺便解释一下 GRPO。GRPO 是 Group Relative Policy Optimization,常见于强化学习训练大模型时的一类方法。它通常会让模型对同一问题生成一组答案或轨迹,再根据组内相对好坏来更新策略,而不是依赖单个样本的绝对奖励。它的核心思想是“同题多解,比较优劣,再强化更好的行为”。不过,就用户提供的材料而言,不能断言 OpenClaw-Skill 使用了 GRPO。
那 CSRL 在论文材料中明确做了什么?
它会针对同一子任务,比较“在不同技能条件下生成的轨迹”。这样做的目的,是避免模型被某一个技能锁死。如果只给模型一个技能,模型可能沿着同一种解法反复探索,即使这条路是次优的。CSRL 则鼓励模型从技能树中主动选择多个相关技能,扩大解空间,并学习哪些程序性策略更有效。
可以把它理解为:CSTS 负责建图,CSRL 负责教模型在图上走路。
关键图表怎么读
Figure 1:论文动机图
前面已经插入了 Figure 1。它的核心是三组对比:
-
过去方法容易技能碎片化,只捕捉局部过程。 -
过去方法技能多样性有限,容易受单模型偏好影响。 -
过去方法迁移性不足,换模型后效果可能明显下降。 -
CSTS 则试图构建结构化、多样化、可泛化的技能树。
这张图对应的是论文最重要的问题定义。如果只看这张图,你也能理解为什么作者不用普通 skill bank,而要提出 tree-search-based skill construction。
Figure 2:方法总览图
Figure 2 展示的是 OpenClaw-Skill 的完整流水线。最需要抓住的是三个模块:
-
复杂任务被拆成多个子任务。 -
每个子任务上通过 CSN-Gen 生成多个候选技能。 -
通过 CSN-Assess 评估质量和迁移性,再结合 CSRL 训练模型选择和利用技能。
图中所谓 collective,不是简单投票,而是贯穿生成和评估两个环节:多个模型生成轨迹,多个模型评估技能,多个技能条件下比较 rollout。

Table 3:消融实验说明每个模块都有贡献
Table 3 是这篇论文最直接证明方法有效性的表格之一。它在 Qwen3.5-9B backbone 上做消融:
-
原始 Qwen3.5-9B:Overall 34.5 -
加入 CSN-Gen:Overall 39.8 -
加入 CSN-Gen + CSN-Assess:Overall 42.8 -
完整 OpenClaw-Skill,也就是再加入 CSRL:Overall 44.9
这个结果说明三件事。
第一,光是从集体轨迹中生成技能,就能把 34.5 提到 39.8,说明多模型轨迹蒸馏出的程序性知识确实有帮助。
第二,加入评估后从 39.8 提到 42.8,说明不是所有生成出来的技能都值得学。筛掉噪声技能、保留更可迁移技能很重要。
第三,加入 CSRL 后到 44.9,说明训练模型如何在技能条件下探索和选择,也能继续带来收益。
这张表的逻辑比较干净:生成、评估、强化学习三个组件是逐步叠加的,每一步都有增益。
实验结果是否站得住
论文主要在两个 benchmark 上评估:QwenClawBench 和 PinchBench。
QwenClawBench 覆盖多类长程 Agent 任务。材料中列出的类别缩写包括 W、AO、SOA、KMM、FQT、DAM、SVM、CS、RIR,但材料没有提供这些缩写的完整含义,因此不足以准确展开解释。可以确定的是,它们共同覆盖了工具使用、文件操作、代码执行、网页交互、多步决策等 Agent 能力。
PinchBench 也是真实 Agent benchmark,论文报告了 23-task 原始版本和 123-task 扩展版本的 best success rate 与 average success rate。
QwenClawBench 上的结果
OpenClaw-Skill 在所有评估的 Qwen backbone 上都提升了 overall score:
-
Qwen3-4B:提升 5.8 分 -
Qwen3-8B:提升 4.3 分 -
Qwen3.5-4B:提升 9.7 分 -
Qwen3.5-9B:提升 10.4 分
其中,默认基于 Qwen3.5 backbone 的 OpenClaw-Skill 4B 和 OpenClaw-Skill 9B 分别达到:
-
OpenClaw-Skill 4B:Overall 41.2 -
OpenClaw-Skill 9B:Overall 44.9
一些类别提升非常明显。比如 OpenClaw-Skill 9B:
-
SVM 从 33.2 提升到 70.9 -
CS 从 30.2 提升到 78.4
OpenClaw-Skill 4B:
-
RIR 从 24.4 提升到 54.1
这些数字说明,方法在涉及长程工具使用和执行反馈的类别上尤其有效。论文也据此认为,CSTS 生成的技能和 CSRL 能提高模型遵循程序性指导、验证中间状态、从执行错误中恢复的能力。
不过也要注意,OpenClaw-Skill 9B 的 Overall 44.9 仍然低于材料中列出的多个更强闭源或开源大模型。例如 Claude Opus 4.6 的 Overall 是 59.5,Qwen3.6-Plus 是 57.4,GPT-5.4 是 56.7,GLM-5.1 是 58.7。也就是说,这篇论文更像是在证明“技能构建和训练方法能显著增强中小 Qwen backbone”,而不是说 9B 模型已经全面超过最强 Agent 模型。
PinchBench 上的结果
PinchBench 的结果同样显示一致提升。
在 23-task 设置上,OpenClaw-Skill 9B 相比 Qwen3.5-9B:
-
best success rate 从 67.5 提升到 72.8 -
average success rate 从 53.8 提升到 58.9
在 123-task 扩展设置上,OpenClaw-Skill 9B:
-
best score 从 61.1 提升到 68.2 -
average score 从 47.1 提升到 53.6
4B 模型也有提升。OpenClaw-Skill 4B 在 123-task 设置上:
-
best score 从 60.9 提升到 61.4 -
average score 从 45.9 提升到 47.6
更小的 Qwen3 backbone 也提升了平均分:
-
Qwen3-4B average 从 13.6 提升到 20.8 -
Qwen3-8B average 从 18.3 提升到 22.5
这些结果说明,方法不只是提升一次最优跑分,也改善平均执行稳定性。对于 Agent 来说,这很重要。因为真实用户不只关心“某次跑通”,更关心“多次执行是否稳定”。
训练设置透露了什么
论文使用了四个 backbone:
-
Qwen3-4B -
Qwen3-8B -
Qwen3.5-4B -
Qwen3.5-9B
训练时,CSTS 会先分解任务、收集多 Agent rollout、合成候选技能节点、构造技能增强轨迹。
数据规模是 2K high-quality SFT examples。训练设置是:
-
fine-tune 2 epochs -
使用 8 张 H100 GPU -
learning rate 为 \(5 \times 10^{-6}\)
这组数字值得注意。2K 高质量 SFT 样本并不算大,但配合结构化技能构建和 CSRL,依然带来明显提升。这支持了一个趋势判断:Agent 训练的数据质量、过程结构和反馈机制,可能比单纯扩大轨迹数量更关键。
当然,材料没有给出数据构建成本、参与模型数量、judge 模型细节、具体任务分解 prompt 或技能节点格式,因此还不足以判断这套流程在更大规模部署时的成本曲线。
局限性
第一,论文材料没有提供完整的奖励函数或 CSRL 训练细节。我们知道 CSRL 会比较不同技能条件下的 rollout,并鼓励更有效的程序性策略,但不知道具体奖励项、权重、优化算法和稳定性设置。因此,对于“强化学习部分到底贡献来自哪里”,只能根据消融结果判断它有效,不能进一步拆解机制。
第二,迁移性评估的具体 rubric 不足。论文强调 collective transferability scoring,但材料中没有展示完整评分标准,也没有说明不同模型之间如何验证迁移效果。迁移性是这篇论文的核心卖点之一,如果要完全信服,还需要看到更细的评估协议。
第三,OpenClaw-Skill 虽然显著提升中小 Qwen backbone,但绝对性能仍低于材料中列出的多个强模型。比如 QwenClawBench 上,OpenClaw-Skill 9B Overall 为 44.9,而 Claude Opus 4.6 为 59.5,GLM-5.1 为 58.7。这说明方法有效,但还不是最终形态。
第四,任务类别缩写在论文材料中不完整。比如 W、AO、SOA、KMM、FQT、DAM、SVM、CS、RIR 的完整定义没有给出,所以无法精确分析每个类别对应的能力边界。
第五,技能树的规模、节点数量、搜索深度、筛选阈值等关键工程参数在材料中不足。对于想复现的人来说,这些会影响成本和效果。
对 AI 趋势的意义
这篇论文放在 Agent 发展趋势里看,有三个信号。
第一个信号是,Agent 能力正在从“会调用工具”走向“会管理过程”。早期工具调用只要求模型知道什么时候用哪个 API;现在的真实任务要求模型长期维护状态、处理失败、验证中间结果、切换策略。OpenClaw-Skill 的技能树设计,正是为这种长程过程管理服务的。
第二个信号是,技能会成为 Agent 训练的重要中间层。过去我们常见三类训练材料:指令-答案、推理链、执行轨迹。技能树则介于轨迹和策略之间:它比单条轨迹更抽象,比普通自然语言规则更可执行,也比最终答案更接近可复用能力。
第三个信号是,多模型协作可能不只是用来投票生成答案,也可以用来构建训练资产。CSTS 里的 collective intelligence 很有意思:多个模型不是一起回答用户,而是一起生成轨迹、暴露策略、互相评估,最终沉淀成可训练的技能结构。这可能是未来高质量 Agent 数据生产的一种重要方式。
对于 deep research agent、代码 Agent、浏览器 Agent、办公自动化 Agent 来说,这个方向都很有参考价值。因为这些 Agent 的难点往往不是某一步不会,而是步骤之间无法稳定衔接,遇到错误不会恢复,执行完不会验证。
看完应该记住什么
OpenClaw-Skill 这篇论文最重要的不是某个单点技巧,而是一种构建 Agent 能力的范式:
把复杂任务拆成子任务;
让多个模型在每个子任务上探索不同轨迹;
从轨迹中生成候选技能;
用多模型 judge 评估技能质量和迁移性;
把技能组织成树;
再训练模型学会利用这棵技能树完成长程任务。
实验上,它用 2K 高质量 SFT examples,在四个 Qwen backbone 上都带来了提升。QwenClawBench 上,Qwen3.5-9B 从 34.5 提升到 44.9;PinchBench 123-task 上,OpenClaw-Skill 9B 的 best score 从 61.1 提升到 68.2,average score 从 47.1 提升到 53.6。消融实验也显示,CSN-Gen、CSN-Assess、CSRL 分别都有贡献。
如果只带走一句话,那就是:未来强 Agent 的训练,不只是喂更多成功轨迹,而是要把成功和失败轨迹中的过程知识,整理成结构化、可组合、可迁移的技能系统。