 夜雨聆风
夜雨聆风





为什么「传几个文档就很准」的 AI,一进公司就变蠢了?几十万份、两家大厂翻车——问题,真不在模型

你大概有过这种体验:打开一个公开大模型,传上去三五个文档,随口一问,它答得又快又准,你忍不住感叹「AI 真行」。
于是一个很自然的念头冒出来:把公司所有系统的文档都接进来、自动切片、灌进知识库,不就能让全员「问什么答什么」了吗?
最近我们接触的一家省级国有投资控股集团,正是这么想的。设想是:让 AI 平台直连 5–7 个业务系统,把近几十万份历史文档自动切片、批量入库,前端挂一个智能体,员工一个入口问所有。
结果呢?这条路此前已经有两家头部厂商(一家运营商系、一家互联网大厂)分别试过——准确率低到没法用,双双折戟。
为什么「传几页很神」,一上规模就翻车?今天掰开讲清楚。
一、先说结论:错的不是模型
几乎所有人第一反应都是「模型能力不够」。这是个自然、但错位的归因。
一条典型的 RAG(检索增强)链路是这样:文档解析 → 切片 → 检索 → 重排 → 大模型生成。大模型只在最后一环,基于你「喂给它」的那几段上下文做推理。
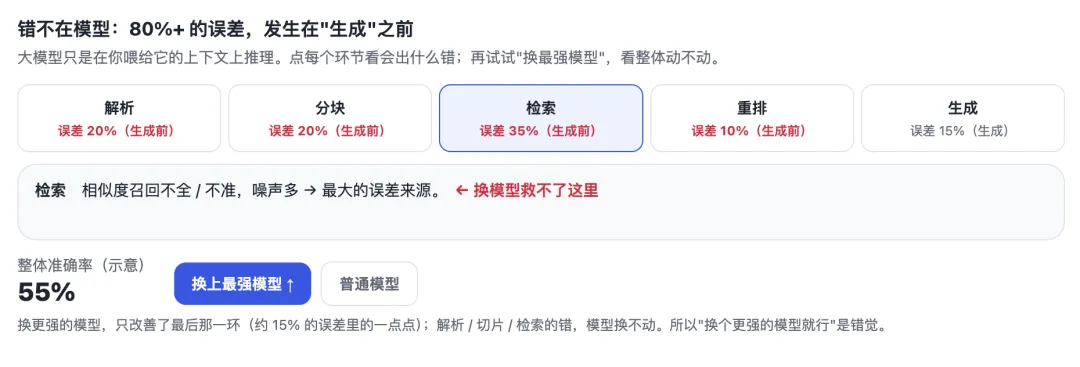
真相是——绝大多数错误发生在「生成」之前:文档没解析对、切片把表格和条款切碎了、检索召回的是不相关的片段。垃圾进,垃圾出。这时你把模型换成最强的,准确率也只动几个百分点,因为瓶颈根本不在它那一环。
二、为什么「越喂越蠢」
几个反直觉、但真实的机制:
•范围越大,越不准。几页文档时检索几乎不会错;到几十万份,库里塞满过期、重复、版本冲突的内容,相似片段互相竞争,检索精度直接塌方。越「全自动、越全量」,反而越糟。
•把结构化数据当文档切,是类别错误。业务系统里大量是表格、流程、状态,本该被「查询」,硬切成文本块喂模型,方向从一开始就错了。
•「一个入口问所有」本身是伪命题。库越大越杂精度越低;而且「找文档」和「答问题」是两类任务,混在一起两边都做不好。
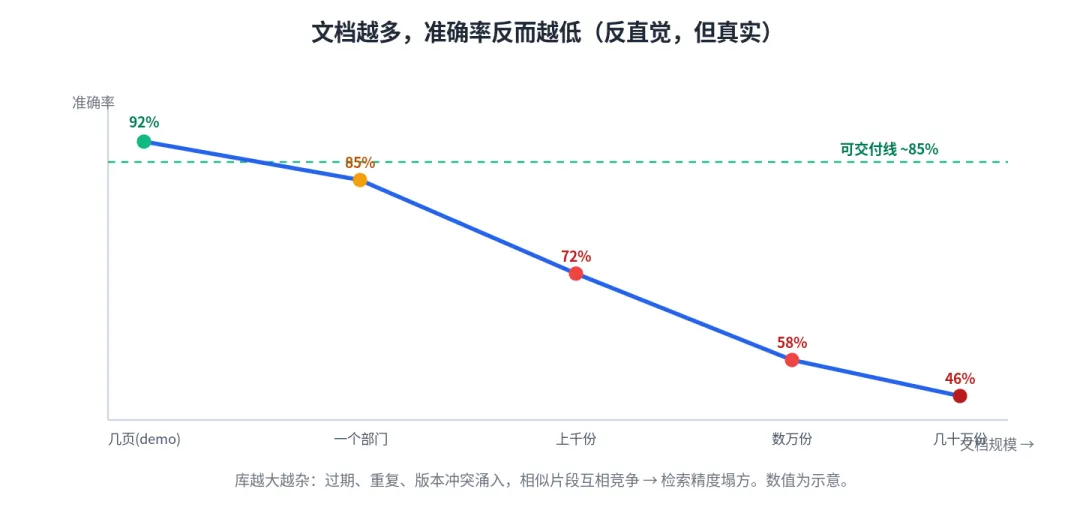
图1 文档越多,准确率反而越低(示意)
三、C 端「传几页就准」,到企业为什么失灵?
公开大模型那个「爽」,恰恰因为它天然满足了高准确率的全部前提,而这些前提在企业里被一条条抽走:
•范围:你传 3 份 vs 企业几十万份,差几个数量级;
•人在环:你亲手挑了相关文档、还盯着答案;企业是几千人来问,无人挑选、无人校验;
•数据质量:你传的是干净最新的;企业是十年陈的扫描件、混排、过期;
• 还多了权限、合规、口径一致、可审计——这些 C 端根本不存在;
• 私有化部署往往还用较弱的国产模型,而非最强的前沿模型。
一句话:你在 C 端「无意识地」把让模型变准的活儿全干了;企业要在几十万份脏数据上自动地干这些活,才是真正的难题。
四、那正确该怎么做?
不是不能做,是不能那么做。务实的打法就四个字:别一锅端。
•解耦,不是一个入口包打天下。拆成通用问答、场景智能体、文档检索,三者各走各的、各管各的权限。
•分域治理,而不是全量切片。无用文档不进库;复杂的精治理、规整的才自动切片;把口径、规则显式沉淀下来(这些往往不在文档里)。
•上下文工程 + 评估闭环。给模型构造干净、结构化的上下文,每个场景配评估集,能量化、能溯源。
存量先封存,重在「做对」而非「做全」;先拿一个高价值、相对干净的域做样板,见效再扩。
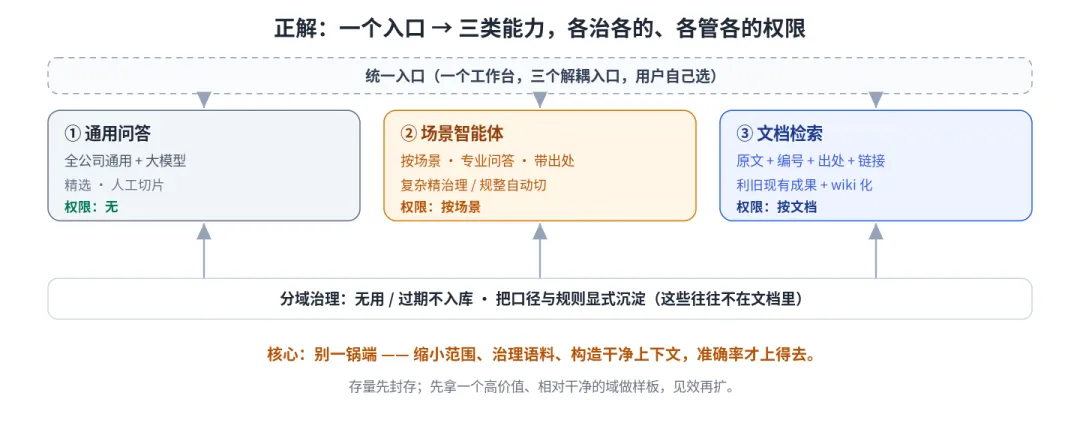
图2 解耦三入口 + 分域治理
五、顺带说个误区:别照搬 C 端的「个人数字人」
很多企业看到 C 端「个人 AI 伴侣」火,就想给每个员工配一个、随便问与自己相关的一切。在 to-B、尤其国资场景,这条基本走不通:「相关 ≠ 有权」,会撞合规;给每人全量切片,又回低准的老路。
更稳的做法是——岗位数字员工:按岗位梳理知识、能力与权限,发布后授权给对应岗位的人;员工私密的问答需求,让他自己搭一个「个人知识库 + 个人智能体」来满足。既给了「我的 AI」的体验,又守住了准确率与合规。
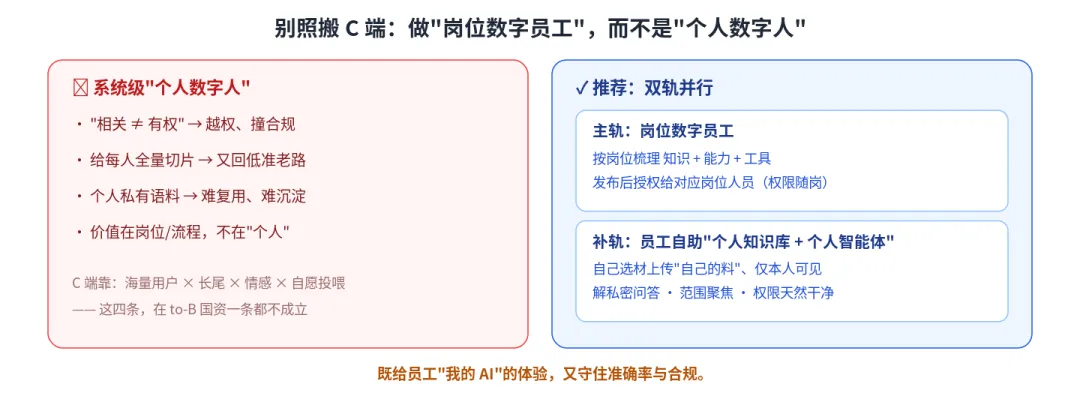
图3 岗位数字员工 vs 个人数字人
写在最后
说到底,大模型是个「推理器」,不是「知识库」。它的表现,取决于你喂给它的上下文有多干净、多对路。
准确率 ≈ 模型 × 范围收窄 × 语料干净 × 上下文构造 × 人在环——模型只是其中一个乘子,通常还不是最关键的那个。「传几个文档就很准」,是因为你亲手把后面几个乘子拉满了。
企业级 AI 真正的功夫,从来不在「喂得多、喂得自动」,而在「治理」和「上下文工程」这件又苦、又不性感、却决定成败的事上。谁先想明白这一点,谁就能少花几百万的冤枉钱。

扫码关注我,继续一起把 AI 变成可交付的业务结果