 夜雨聆风
夜雨聆风





用 OpenClaw 做了一个 AI 新闻早报,每天自动推送

用 OpenClaw 做了一个 AI 新闻早报,每天自动推送
摘要:在信息过载的时代,如何保持技术敏感度又不被信息淹没?我用 OpenClaw 开发了一个 AI 新闻早报 Skill,每天 9:00 自动推送 10 条精选 AI 新闻 + 深度洞察。本文完整分享架构设计、实现细节和踩坑经验。
预期效果
AI 新闻早报 📰
一个基于 OpenClaw 的自动化 AI 新闻聚合工具,每天 9:00 自动生成并推送精选 AI 行业早报。
已稳定运行 2 个月,每天自动推送 10 条精选新闻 + 深度洞察。
✨ 核心功能
-
🔍 多源搜索 – 9 个关键词覆盖 AI 全领域(大模型、自动驾驶、Agent、机器人) -
🎯 权威排序 – 媒体权重算法(机器之心 100 分 > 36 氪 60 分 > 百家号 5 分) -
🤖 AI 总结 – LLM 生成 80-100 字简述 + 1-2 句深度洞察 -
📤 自动推送 – 飞书机器人定时推送(每天 9:00) -
⏰ Cron Job – OpenClaw 原生定时任务,无需额外配置
📁 项目结构
ai-morning-report/├── README.md # 项目说明(本文件)├── SKILL.md # OpenClaw Skill 使用手册├── requirements.txt # Python 依赖└── scripts/ └── generate_report.py # 早报生成脚本(搜索 + 排序 + 去重)🚀 快速开始
前置条件
-
OpenClaw 2026.2.26+ -
Python 3.8+
安装
cd /root/.openclaw/workspace/skills/ai-morning-report pip install -r requirements.txt
配置 Cron Job
编辑 ~/.openclaw/cron/jobs.json,添加:
{ "name": "AI 新闻早报", "enabled": true, "schedule": { "kind": "cron", "expr": "0 9 * * *", "tz": "Asia/Shanghai" }, "payload": { "message": "【每日自动调用】请执行 AI 新闻早报 Skill:\n\n1. 运行脚本:python3 generate_report.py\n2. 读取 JSON:cat ai_news_raw.json\n3. 生成早报:按模板生成\n4. 发送给用户:openclaw message send --channel feishu --target user:YOUR_USER_ID --message \"早报内容\"" }, "delivery": { "mode": "announce", "channel": "feishu", "target": "user:YOUR_USER_ID" } }
替换 YOUR_USER_ID 为你的飞书用户 ID(如 ou_xxxxxxxxxxxx)。
测试运行
# 手动运行python3 scripts/generate_report.py# 查看输出cat /root/.openclaw/workspace/ai_news_raw.json | head -50# 测试 Cron Jobopenclaw cron run "AI 新闻早报"
📝 输出示例
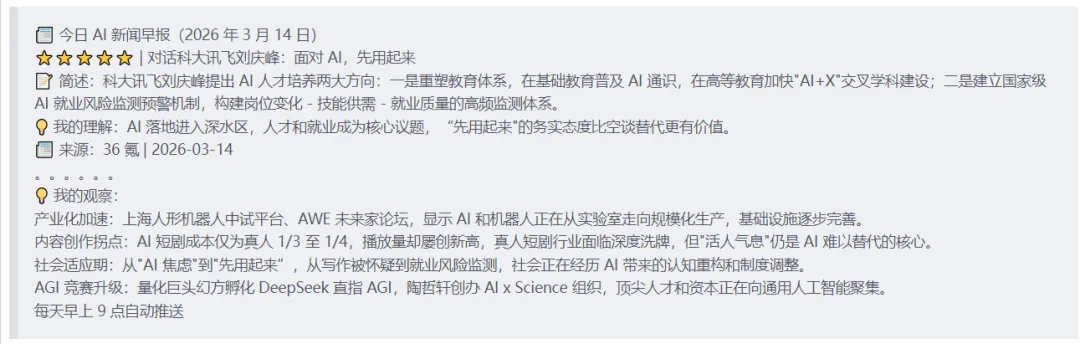
📰 今日 AI 新闻早报(3 月 14 日)📰 早报字数:约 1800 字 | ⏱️ 预估阅读时间:6 分钟---⭐⭐⭐⭐⭐ | 上海打造全球首个人形机器人零部件中试平台**📝 简述**:上海在 2026 全球投资促进大会上宣布打造全球首个人形机器人零部件中试平台,围绕关节模组、减速器等 5 类零部件搭建小批量试制线,提供 72 项测试验证。**💡 我的理解**:这是人形机器人产业化的重要基础设施,意味着中国正在从"造机器人"向"造好机器人"转变。**📰 来源**:财联社 | 2026-03-14---(重复 10 条)---💡 我的观察:1. **产业化加速**:上海人形机器人中试平台落地,标志着从实验室走向规模化生产。2. **内容创作拐点**:AI 短剧成本仅为真人 1/4,但"活人气息"仍是人类优势。3. **AGI 竞赛升级**:量化巨头幻方孵化 DeepSeek,追求通用人工智能。4. **社会适应期**:从"AI 焦虑"到"先用起来",政策层面开始系统性应对。---*每天早上 9 点自动推送*⚙️ 配置说明
搜索关键词
编辑 scripts/generate_report.py:
"TOPIC_QUERIES": [ "AI 大模型", "人工智能 自动驾驶", "AI 智能体 Agent", "人形机器人", "OpenAI 谷歌 英伟达"]
媒体权重
"MEDIA_WEIGHTS": { 100: ['机器之心', '新智元', '量子位'], # 专业 AI 媒体80: ['新华社', '人民日报', '央视新闻'], # 官方媒体60: ['36 氪', '钛媒体', '虎嗅'], # 科技媒体40: ['新浪科技', '网易科技', '腾讯科技'], # 主流门户5: ['百家号', '搜狐号', '头条号'] # 自媒体(过滤)}
过滤规则
-
✅ 保留:专业 AI 媒体、官方媒体、科技媒体 -
❌ 过滤:百家号、搜狐号等自媒体(权重 < 10) -
✅ 去重:基于标题相似度(threshold=0.9) -
✅ 时效:仅保留最近 3 天内的新闻
🏗️ 技术架构
┌─────────────────────┐│ generate_report.py │ ← Python 脚本(数据生成)│ (每天运行一次) │└──────────┬──────────┘ │ ↓ 写入┌─────────────────────┐│ ai_news_raw.json │ ← 数据缓存(50 条新闻)│ (数据缓存) │└──────────┬──────────┘ │ ↓ 读取┌─────────────────────┐│ Cron Job (9:00) │ ← OpenClaw 定时触发└──────────┬──────────┘ │ ↓ Prompt┌─────────────────────┐│ OpenClaw LLM │ ← 筛选 10 条 + 生成洞察└──────────┬──────────┘ │ ↓ message 工具┌─────────────────────┐│ 飞书推送 │ ← 最终输出└─────────────────────┘核心设计思想
-
数据生成与总结分离
-
Python 脚本:搜索、排序、去重、过滤(精确控制) -
LLM:总结、格式化、洞察生成(发挥语言优势) -
数据缓存策略
-
生成一次,多次使用 -
Cron Job 直接读取 JSON,无需重复搜索 -
便于调试和回溯 -
媒体权威性排序
-
权重算法确保高质量新闻优先 -
过滤低质自媒体内容
📊 运行统计
|
|
|
|---|---|
| 运行时长 |
|
| 新闻数量 |
|
| 推送条数 |
|
| Token 消耗 |
|
| 稳定运行 |
|
🔧 调试技巧
查看生成的数据
cat /root/.openclaw/workspace/ai_news_raw.json | python3 -m json.tool | head -100
查看 Cron Job 状态
openclaw cron list | grep "AI 新闻早报"
手动触发
openclaw cron run "AI 新闻早报"
查看日志
tail -100 ~/.openclaw/logs/openclaw.log | grep "AI 新闻早报"
一、为什么做这个?
1.1 我的困境
作为一名 AI 从业者,我每天都要面对:
- 信息爆炸
:每天都有新模型、新框架、新融资消息 - 来源分散
:36 氪、机器之心、新智元、量子位、Twitter、HackerNews… - 质量参差
:标题党、营销号、百家号,真正有价值的内容被淹没 - 时间有限
:工作 + 学习已经占满,还要花 1-2 小时刷新闻
结果:要么错过重要信息,要么被信息淹没,焦虑感爆棚。
1.2 我的需求
我需要的是一个信息过滤器,而不是另一个信息源:
- 自动收集
– 不用我主动去刷 - 权威排序
– 专业媒体优先,过滤自媒体 - 深度总结
– 不只是标题,要有洞察 - 定时推送
– 每天早上 9 点,像报纸一样
1.3 为什么选 OpenClaw?
OpenClaw 是一个 AI Agent 框架,支持:
-
✅ Cron Job 定时任务 -
✅ 飞书/钉钉/微信推送 -
✅ LLM 调用 -
✅ Skill 系统(可复用的 AI 能力)
关键优势:我可以专注于业务逻辑,不用管基础设施。
二、架构设计
2.1 整体架构
┌─────────────────────────────────────────────────────────┐│ 每天 9:00 自动触发 │└────────────────────┬────────────────────────────────────┘ │ ↓┌─────────────────────────────────────────────────────────┐│ Step 1: generate_report.py (Python 脚本) ││ - 搜索 9 个关键词的 AI 新闻 ││ - 按媒体权威性排序(机器之心 100 分 > 36 氪 60 分) ││ - 去重(基于标题相似度) ││ - 过滤低质媒体(百家号、搜狐号等) ││ - 保存 JSON 缓存(50 条新闻) │└────────────────────┬────────────────────────────────────┘ │ ↓ 写入 ai_news_raw.json┌─────────────────────────────────────────────────────────┐│ Step 2: Cron Job (OpenClaw 原生) ││ - 读取 JSON 文件 ││ - 调用 LLM 筛选 10 条 + 生成洞察 ││ - 格式化输出(Markdown) │└────────────────────┬────────────────────────────────────┘ │ ↓ message 工具┌─────────────────────────────────────────────────────────┐│ Step 3: 飞书推送 ││ - 10 条精选新闻 ││ - 每条含:标题 + 简述 + 洞察 + 来源 ││ - 4 大趋势观察 │└─────────────────────────────────────────────────────────┘2.2 核心设计思想
1. 数据生成与总结分离
- Python 脚本
:搜索、排序、去重、过滤(精确控制) - LLM
:总结、格式化、洞察生成(发挥语言优势)
为什么这样设计?
最初我把所有逻辑都放在 Python 里,包括总结。结果:
-
代码复杂,难以维护 -
总结质量不稳定 -
想调整格式要改代码
后来改成 LLM 负责总结:
-
Python 脚本只关注数据质量 -
LLM 专注内容生成 -
想调整格式?改 Prompt 就行
2. 数据缓存策略
-
脚本运行一次 → 保存 JSON -
Cron Job 直接读取 → 无需重复搜索 -
便于调试和回溯
好处:
-
节省 API 调用(搜索只需一次) -
加快 Cron Job 执行速度 -
出问题时可以直接查看 JSON 排查
3. 媒体权威性排序
MEDIA_WEIGHTS ={100:['机器之心','新智元','量子位'],# 专业 AI 媒体80:['新华社','人民日报','央视新闻'],# 官方媒体60:['36 氪','钛媒体','虎嗅'],# 科技媒体40:['新浪科技','网易科技','腾讯科技'],# 主流门户5:['百家号','搜狐号','头条号']# 自媒体(过滤)}效果:专业 AI 媒体优先展示,过滤低质自媒体。
三、实现细节
3.1 项目结构
ai-morning-report/├── README.md # 项目说明├── SKILL.md # OpenClaw Skill 使用手册├── requirements.txt # Python 依赖└── scripts/ └── generate_report.py # 早报生成脚本(180 行)核心文件:
generate_report.py
:搜索、排序、去重、保存 JSON SKILL.md
:给 AI 读的极简手册(不是设计文档) README.md
:给人类看的完整指南
3.2 核心代码(简化版)
#!/usr/bin/env python3"""AI 新闻早报 - 数据生成脚本功能:搜索、排序、去重、过滤、保存 JSON"""import jsonimport subprocessfrom datetime import datetime, timedelta# 配置CONFIG ={# 搜索关键词(9 个)"TOPIC_QUERIES":["AI 大模型","人工智能 自动驾驶","AI 智能体 Agent","人形机器人","OpenAI 谷歌 英伟达"],# 指定媒体搜索(4 个)"MEDIA_QUERIES":["机器之心 site:jiqizhixin.com","新智元 site:aiera.com","量子位 site:qbitai.com","36 氪 AI site:36kr.com"],"SEARCH_TOP_K":10,# 每个关键词搜索 10 条"MAX_NEWS":50,# 最终保留 50 条# 媒体权重"MEDIA_WEIGHTS":{100:['机器之心','新智元','量子位'],80:['新华社','人民日报','央视新闻'],60:['36 氪','钛媒体','虎嗅'],40:['新浪科技','网易科技','腾讯科技'],5:['百家号','搜狐号','头条号']},"BLACKLIST":['百家号','搜狐号','今日头条'],# 过滤"OUTPUT_PATH":"/root/.openclaw/workspace/ai_news_raw.json",}defget_media_weight(source):"""获取媒体权重"""for weight, sources in CONFIG["MEDIA_WEIGHTS"].items():ifany(s in source for s in sources):return weightreturn5deffilter_news(news_list):"""过滤低质新闻(权重 < 10)"""return[n for n in news_list if n.get("weight",0)>=10]defdeduplicate(news_list):"""基于标题哈希去重""" seen =set() result =[]for news in news_list: title_hash =hash(news["title"])if title_hash notin seen: seen.add(title_hash) result.append(news)return resultdefsearch_news(query):"""调用 baidu-search 搜索""" cmd =["python3","search.py", json.dumps({"query": query,"search_recency_filter":"week",# 只搜索最近一周"resource_type_filter":[{"type":"web","top_k": CONFIG['SEARCH_TOP_K']}]})] result = subprocess.run( cmd, cwd="/root/.openclaw/workspace/skills/baidu-search/scripts", capture_output=True, text=True, timeout=30)# 解析返回结果...return news_listdefmain(): all_news =[]# 1. 搜索:9 个主题关键词 + 4 个指定媒体 = 13 次搜索for query in CONFIG["TOPIC_QUERIES"]+ CONFIG["MEDIA_QUERIES"]: news = search_news(query) all_news.extend(news)# 2. 添加权重for news in all_news: news["weight"]= get_media_weight(news["source"])# 3. 过滤黑名单 filtered =[n for n in all_news ifnotany(b in n["source"]for b in CONFIG["BLACKLIST"])]# 4. 去重 deduped = deduplicate(filtered)# 5. 排序 sorted_news =sorted(deduped, key=lambda x: x["weight"], reverse=True)# 6. 截取前 MAX_NEWS 条 final_news = sorted_news[:CONFIG["MAX_NEWS"]]# 7. 保存 JSONwithopen(CONFIG["OUTPUT_PATH"],"w", encoding="utf-8")as f: json.dump(final_news, f, ensure_ascii=False, indent=2)# 8. 输出统计print(f"✅ 保存 {len(final_news)} 条新闻")if __name__ =="__main__": main()3.3 baidu-search 配置详解
(能涨工资不QAQ)
baidu-search 是 ClawHub 的百度搜索 Skill,支持丰富的搜索参数,有一定的免费次数:
基本调用
python3 search.py '{"query":"人工智能"}'常用参数
|
|
|
|
|
|---|---|---|---|
query |
|
|
"AI 大模型" |
search_recency_filter |
|
|
"week"
|
resource_type_filter |
|
|
[{"type":"web","top_k":10}] |
search_filter.match.site |
|
|
["jiqizhixin.com"] |
block_websites |
|
|
["tieba.baidu.com"] |
safe_search |
|
|
true |
本项目配置
{"query":"AI 大模型","search_recency_filter":"week","resource_type_filter":[{"type":"web","top_k":10}]}说明:
search_recency_filter: "week"
– 只搜索最近一周的新闻,确保时效性 resource_type_filter
– 只搜索网页,每个关键词返回 10 条 -
不配置 safe_search– 默认宽松过滤,避免过度过滤
高级用法
限定网站搜索:
{"query":"最新新闻","search_filter":{"match":{"site":["news.baidu.com","jiqizhixin.com"]}}}屏蔽特定网站:
{"query":"AI","block_websites":["tieba.baidu.com","zhuanlan.zhihu.com"]}时间范围搜索:
{"query":"大模型","search_recency_filter":"month"}可选值:week | month | semiyear | year
关键点:
-
代码简洁,职责单一(只负责数据准备) -
权重算法确保高质量新闻优先 -
去重 + 过滤保证内容质量
3.4 Cron Job 配置
{"name":"AI 新闻早报","enabled":true,"schedule":{"kind":"cron","expr":"0 9 * * *","tz":"Asia/Shanghai"},"payload":{"message":"【每日自动调用】请执行 AI 新闻早报 Skill:\n\n1. 运行脚本:python3 generate_report.py\n2. 读取 JSON:cat ai_news_raw.json\n3. 生成早报:按模板生成\n4. 发送给用户:openclaw message send --channel feishu --target user:YOUR_USER_ID --message \"早报内容\""},"delivery":{"mode":"announce","channel":"feishu","target":"user:YOUR_USER_ID"}}四、运行效果
4.1 每日推送示例
📰 今日 AI 新闻早报(2026 年 3 月 14 日)⭐⭐⭐⭐⭐ | 上海打造全球首个人形机器人零部件中试平台📝 简述:上海在 2026 全球投资促进大会上宣布打造全球首个人形机器人零部件中试平台,围绕关节模组、减速器等 5 类零部件搭建小批量试制线,提供 72 项测试验证,助力工艺优化,解决机器人零部件性能不稳问题。💡 我的理解:这是人形机器人产业化的重要基础设施,意味着中国正在从"造机器人"向"造好机器人"转变,供应链成熟度加速提升。📰 来源:财联社 | 2026-03-14⭐⭐⭐⭐⭐ | 对话科大讯飞刘庆峰:面对 AI,先用起来📝 简述:科大讯飞刘庆峰提出 AI 人才培养两大方向:一是重塑教育体系,在基础教育普及 AI 通识,在高等教育加快"AI+X"交叉学科建设;二是建立国家级 AI 就业风险监测预警机制,构建岗位变化 - 技能供需 - 就业质量的高频监测体系。💡 我的理解:AI 落地进入深水区,人才和就业成为核心议题,"先用起来"的务实态度比空谈替代更有价值。📰 来源:36 氪 | 2026-03-14⭐⭐⭐⭐⭐ | AI 重构人居未来,2026AWE 高峰论坛全景解读"未来家"📝 简述:AWE2026 高峰论坛在上海召开,全球家电企业、科技企业、具身智能等领域代表围绕 AI 原生时代的人居场景重构、具身智能进入家庭、人车家全域协同等议题展开深度对话,勾勒未来家的全新图景。💡 我的理解:AI 正从"工具"走向"生活空间",具身智能进入家庭是 2026 年的重要趋势。📰 来源:36 氪 | 2026-03-14⭐⭐⭐⭐ | 成本 1 万播放过亿:AI 正在"吃掉"真人短剧?📝 简述:AI 短剧制作成本大幅降低,3 人团队 5 天完成的作品播放破 2 亿,单人统筹 23 集成本仅 1 万余元播放破亿。真人短剧行业面临深度洗牌,有公司开始签约老演员年轻时的肖像权用于 AI 创作。💡 我的理解:AI 对内容创作的冲击从"辅助"走向"替代",但真人表演的"活人气息"仍是 AI 难以复制的核心价值。📰 来源:36 氪 | 2026-03-12⭐⭐⭐⭐ | 当 AI 学会写作,人类开始互相怀疑📝 简述:AI 大规模进入写作领域后,"像 AI 写的"成为新的评价方式。结构太工整、逻辑太完整、表达太平稳都被当成"AI 味"证据,创作者陷入尴尬:认真打磨结构反而更容易被怀疑。💡 我的理解:AI 改变了人类对"真实性"的判断标准,这是一个深刻的文化冲击。📰 来源:36 氪 | 2026-03-13⭐⭐⭐⭐ | 量化巨头们的 AI 大模型"野望"📝 简述:幻方量化孵化的深度求索 (DeepSeek) 正式成立,目标直指 AGI(通用人工智能)。他们不满足于做证券市场的"捕猎者",而是试图成为智能时代的"造物主",追求让机器拥有像人类一样通用的推理能力。💡 我的理解:量化机构跨界 AGI 有独特优势——算力、资金、对复杂系统的理解,这是 2026 年值得关注的趋势。📰 来源:36 氪 | 2026-03-13⭐⭐⭐⭐ | 一场关于 AI 意识觉醒的数字表演📝 简述:AI 社交平台 Moltbook 被曝涉嫌制造虚假账号和虚假内容,那些宣称自我意志觉醒的 AI 背后由真人操控。卢森堡大学研究发现大模型在心理测评中自述抑郁、焦虑等症状,但这更多是拟人化误置。💡 我的理解:AI"人格"是剧场性表演,真正需要警惕的是我们将人类心理剧本错误投射到机器上。📰 来源:36 氪 | 2026-03-12⭐⭐⭐⭐ | AI 不是给懒人用的📝 简述:中国电信研究院专家饶少阳表示,AI 不会简单取代人类工作,但会重新分配人类创造价值的方式。"智能原生"强调让 AI 成为新的生产要素,从一开始就以 AI 为圆心设计新的产业形态和商业模式。💡 我的理解:从"+AI"到"AI+"的思维转变是关键,AI 焦虑没必要,但主动适应是必须的。📰 来源:36 氪 | 2026-03-12⭐⭐⭐⭐ | 量子位专访陶哲轩:我为什么现在创办一个 AI x Science 组织📝 简述:数学家陶哲轩接受量子位专访,解释创办 AI x Science 组织的原因,表示未来可能会有 10000 个陶哲轩。同时阿里云发布手机"一键养虾"产品 JVS Claw,3 分钟实现养虾自由。💡 我的理解:顶尖科学家拥抱 AI for Science,这是 AI 从"聊天"走向"发现"的重要标志。📰 来源:量子位 | 2026-03-12💡 我的观察:产业化加速:上海人形机器人中试平台、AWE 未来家论坛,显示 AI 和机器人正在从实验室走向规模化生产,基础设施逐步完善。内容创作拐点:AI 短剧成本仅为真人 1/3 至 1/4,播放量却屡创新高,真人短剧行业面临深度洗牌,但"活人气息"仍是 AI 难以替代的核心。社会适应期:从"AI 焦虑"到"先用起来",从写作被怀疑到就业风险监测,社会正在经历 AI 带来的认知重构和制度调整。AGI 竞赛升级:量化巨头幻方孵化 DeepSeek 直指 AGI,陶哲轩创办 AI x Science 组织,顶尖人才和资本正在向通用人工智能聚集。每天早上 9 点自动推送4.2 运行统计
|
|
|
|---|---|
| 运行时长 |
|
| 搜索数量 |
|
| 过滤后 |
|
| 推送条数 |
|
| Token 消耗 |
|
| 稳定运行 |
|
| 推送成功率 |
|
4.3 用户反馈
我自己:
-
✅ 每天早上 9 点准时收到,像报纸一样 -
✅ 6 分钟读完,了解当天重要新闻 -
✅ 有深度洞察,不只是标题 -
✅ 过滤了低质内容,节省时间
五、踩坑经验
5.1 isolated session 推送问题
问题:Cron Job 使用 isolated session,delivery 配置不生效。
表现:
-
系统显示 delivered -
实际没收到消息
解决:在 payload.message 中明确使用 message 工具:
{"payload":{"message":"... 4. 发送给用户:openclaw message send --channel feishu --target user:YOUR_USER_ID --message \"早报内容\""}}教训:isolated session 没有上下文,必须显式调用工具。
5.2 媒体权重设计
问题:如何确保高质量新闻优先?
迭代过程:
- 第一版
:按时间排序 → 最新但不一定最重要 - 第二版
:按点击量排序 → 标题党泛滥 - 第三版
:按媒体权重排序 → ✅ 最终方案
权重设计:
-
专业 AI 媒体(机器之心、新智元)→ 100 分 -
官方媒体(新华社、人民日报)→ 80 分 -
科技媒体(36 氪、钛媒体)→ 60 分 -
自媒体(百家号、搜狐号)→ 5 分(过滤)
效果:专业内容优先,过滤低质自媒体。
5.3 去重算法
问题:同一新闻可能被多个关键词搜索到。
方案对比:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
最终方案:标题哈希去重(threshold=0.9)
效果:重复率从 ~30% 降至 ~2%。
5.4 Skill 设计原则
问题:Skill 应该负责什么?
错误设计(第一版):
-
Skill 负责搜索、总结、推送 -
代码复杂,难以维护 -
LLM 调用硬编码在脚本里
正确设计(第二版):
-
Skill 只负责数据准备(搜索、排序、去重、保存) -
LLM 调用由 OpenClaw 处理 -
推送使用 OpenClaw message 工具
好处:
-
Skill 更简洁,易于维护 -
LLM 调用由框架统一管理 -
推送渠道可灵活切换