 夜雨聆风
夜雨聆风





李宏毅:AI 能自我修正吗?
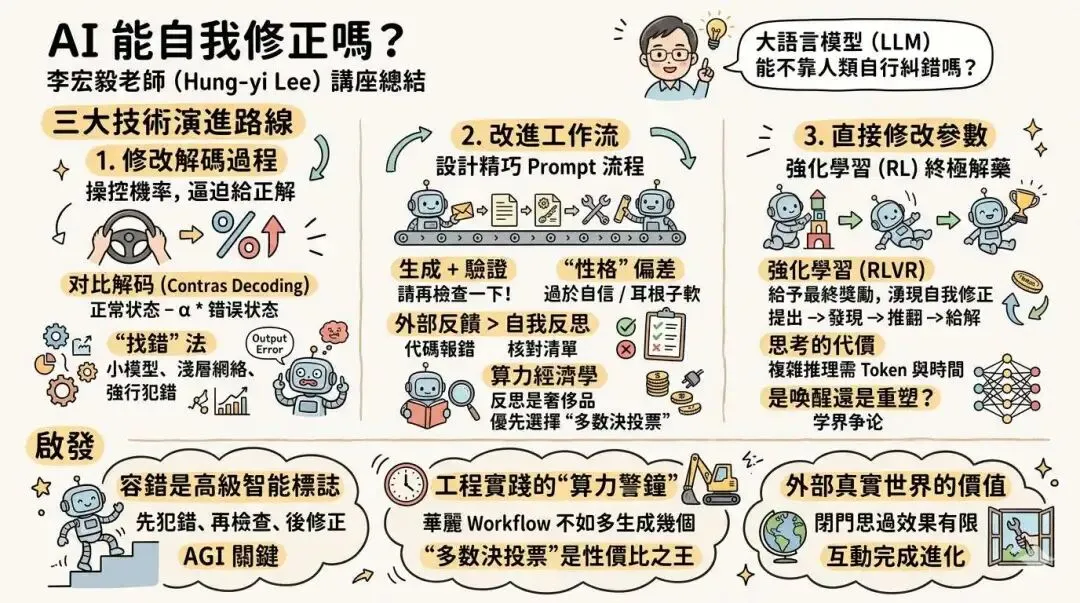
在 AI 能自我修正嗎?從 decoding、workflow 到 reasoning 的技術發展整理[1] 这节课中,李宏毅老师带我们深入探讨了当今 AI 领域最前沿的话题之一:大语言模型(LLM)能否在没有人类介入的情况下,自行发现并修正错误?
要点速览 (Quick Takeaways)
-
AI 自我修正并非天生:拥有正确知识不代表拥有“自我修正”的能力,自我修正是一种需要被激发或特殊训练的状态。 -
三大技术演进路线:目前的自我修正技术主要分为三个流派——在生成时拦截(Decoding)、在流程上反思(Workflow),以及深入骨髓的推理训练(Reasoning)。 -
反思的“性价比”陷阱:让 AI 停下来反思(Reflection)虽然有时有效,但在算力有限的情况下,不如直接让 AI 多生成几个不同答案去“多数决投票”(Majority Vote)来得划算。 -
强化学习(RL)是终极解药:通过 RL 训练,模型能在摸爬滚打中自然地学会“先犯错、再检查、后修正”的类人推理过程。
详述要点 (Detailed Points)
李宏毅老师将 AI 的自我修正技术发展归纳为三个主要方向。
1. 修改解码过程 (Modify Inference / Decoding)
这是在不改变模型参数、不用重新训练的情况下,通过“操控概率”来逼迫模型给出正确答案的技巧。
-
对比解码 (Contrastive Decoding):核心思想是“正确答案 = 正常状态 – * 错误状态” 08:12[2]。只要我们能刻意制造出一个让模型大概率会答错的场景(比如给它加降智咒语、遮挡图片关键部分、去掉检索到的上下文),提取出错误的概率分布,再从正常的分布中将其减去,就能把模型往正确的方向推。 -
各显神通的“找错”法:为了提取错题本,学者们脑洞大开。比如用小模型的输出当反面教材、用浅层网络的输出当反面教材(DoLa、Layer CD),甚至直接给模型输入 "Output Error"让它强行犯错以提取特征 35:01[3]。
2. 改进工作流 (Modify Workflow)
不改底层代码,而是通过设计精巧的 Prompt 流程来诱导模型反思。
-
生成 + 验证 (Generation + Verification):模型给出一个答案后,系统自动塞入一句“请再检查一下” 41:01[4]。因为“批判往往比生成容易”,而且生成过程像泼出去的水无法回头,反思则给了模型一个找补的机会。 -
AI 的“性格”偏差:不是所有模型都听劝。有的模型过于自信(Confidence Level 高),打死不改;有的模型耳根子软(Critic Score 高),别人一诈它,反而把对的改成了错的 52:28[5]。 -
外部反馈 > 自我反思:实验证明,纯靠模型自己“空想”反思效果极不稳定。真正能让正确率飙升的,是给模型提供真实的外部反馈(如代码报错信息、核对清单) 49:16[6]。 -
算力经济学:反思是一件“奢侈品”。研究发现,在前期算力有限时,与其花大量算力让模型反思,不如把算力用来多生成几个答案做“多数投票”(Majority Vote)。只有当投票的收益达到极限时,引入反思才划算 59:54[7]。
3. 直接修改参数 (Reasoning via RL)
这是目前最火的路线,目标是让模型摆脱外在的提示词,把“自我检查”刻进 DNA 里。
-
强化学习 (RLVR):给予模型一个明确的最终奖励(比如数学题答案正确)。在追求这个奖励的过程中,模型会自然而然地涌现出自我修正的行为:提出初步答案 发现不对劲 自我推翻 给出最终答案 01:09:01[8]。 -
思考的代价 (Cost of Thinking):为什么要绕弯路?心智学研究表明,无论人类还是 AI,复杂的推理就是需要付出“标记(Token)”与时间的代价 01:11:24[9]。把大问题拆解成多步,能以指数级减少模型需要死记硬背的训练数据量 01:14:04[10]。 -
哲学思辨:是唤醒还是重塑? 学界目前在争论,强化学习到底是不是真的赋予了 AI 新的推理能力?有一派认为,正确的推理路径模型本来就有,只是被乱七八糟的杂念掩盖了,RL 只是提高了正确路径的概率(颇有“众生皆具如来智慧德相”的禅意) 01:21:45[11];但也有证据表明,在长期的 RL 训练中,模型确实学到了原先不存在的新技巧。
启发 (Inspirations)
-
容错是高级智能的必经之路:模型之所以能学会推理,往往是因为在 RL 训练中经历了大量的“先错后对”。这启发我们,绝对的正确率可能不是衡量智能的唯一标准,能够自我发现错误并动态修正,才是迈向 AGI 的关键标志。 -
工程实践中的“算力警钟”:在开发现实世界的 AI 应用时,不要盲目迷信华丽的 Workflow(比如各种复杂的 Agent 反思套娃)。“多数决投票”这种大力出奇迹的朴素方法,在很多时候依然是性价比之王。引入机制前,先算算算力账。 -
外部真实世界的价值:AI 的“闭门思过”效果有限,真正让它突飞猛进的是外部工具和环境的反馈。与其苛求语言模型成为全知全能的圣人,不如为它搭建好一套能与物理世界/代码编译器进行互动的环境,让它在真实的碰撞中完成进化。
AI 能自我修正嗎?從 decoding、workflow 到 reasoning 的技術發展整理: https://www.youtube.com/watch?v=m3i2mk5hs8U
[2]08:12: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=492
[3]35:01: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=2101
[4]41:01: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=2461
[5]52:28: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=3148
[6]49:16: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=2956
[7]59:54: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=3594
[8]01:09:01: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=4141
[9]01:11:24: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=4284
[10]01:14:04: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=4444
[11]01:21:45: http://www.youtube.com/watch?v=m3i2mk5hs8U&t=4905