 夜雨聆风
夜雨聆风





AI记忆的底层逻辑:为什么ChatGPT总是"忘事"?OpenAI花了3年才搞清楚
为什么ChatGPT总是”忘事”?OpenAI花了3年才搞清楚AI记忆的底层逻辑 🧠
你有没有遇到过这种抓狂的场景:
上周你跟ChatGPT聊了一个小时,把自己的项目背景、团队情况、技术栈全部讲清楚了。今天打开新对话,它对你一无所知,你得从头再讲一遍——像是跟一条患了失忆症的金鱼对话。
这不是bug,这是AI架构层面最根本的问题。
更反直觉的是:就算你给它配备了100万token的超长上下文窗口,这个问题依然存在。一项2026年的研究发现,当上下文窗口使用率超过60%,模型就开始”遗忘”关键信息——答案就在窗口里,它就是视而不见。
更大的窗口,只是更贵的遗忘。
那真正的解法是什么?这就要从AI记忆的底层架构说起。
上面两张图展示了AI记忆的整体架构和处理流程。下面用详细解释底层逻辑:
一、为什么AI需要记忆?
传统大模型(如GPT-4)本质上是**”无状态”**的——每次对话都从零开始,上下文窗口(通常是128K token)就是它全部的”记忆”。一旦对话超过窗口长度,早期内容就被截断丢弃,这就是为什么ChatGPT会”忘事”。
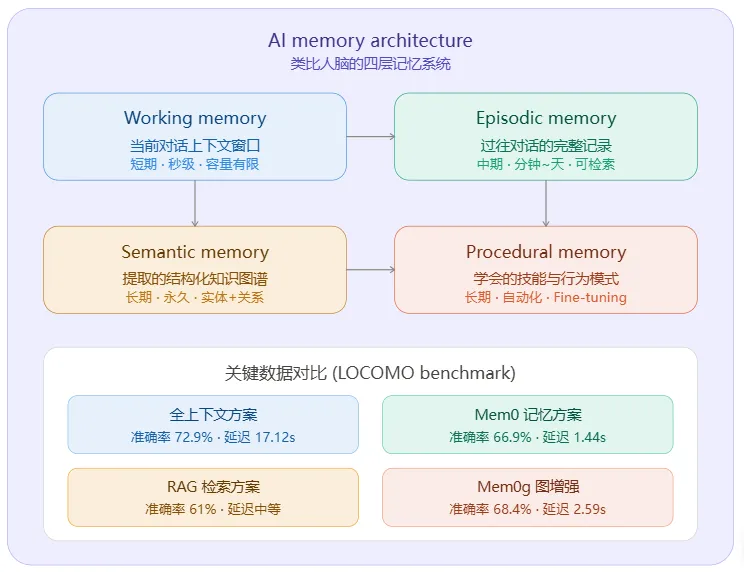
二、四层记忆架构(类比人脑)
AI的记忆系统借鉴了认知心理学对人脑记忆的分类:
1️⃣ 工作记忆(Working Memory)
- 是什么:就是当前的上下文窗口,存储当前对话中的所有token
- 特点:容量有限、速度最快、用完即丢
- 问题:窗口越大,计算成本越高(注意力机制是O(n²)复杂度),延迟也越长
2️⃣ 情景记忆(Episodic Memory)
- 是什么:存储过往完整对话的记录,类似”你上次跟我说过什么”
- 实现:把对话片段存入向量数据库,下次对话时根据语义相似度检索相关片段
- 关键:不是原封不动地存,而是用LLM从中提取关键事实(如”用户喜欢吃辣”、”用户有个5岁的女儿”),压缩存储
3️⃣ 语义记忆(Semantic Memory)
- 是什么:从对话中提取的结构化知识图谱,存储实体+关系
- 实现:用知识图谱(Graph)存储,比如”用户→居住在→北京”、”用户→职业→程序员”
- 核心优势:向量记忆只能检索语义相似的事实,而图记忆能检索实体关系链。比如问”我上次推荐的那本书的作者还写了什么?”——向量检索会迷失,图检索可以沿着
用户→推荐→书→作者→作品的关系链精准找到
4️⃣ 程序记忆(Procedural Memory)
- 是什么:模型通过训练学会的”自动化技能”,类似于你骑自行车不需要思考
- 实现:通过Fine-tuning(微调),把常见行为模式固化到模型权重中
- 状态:目前业界对这一层的研究最少,是最前沿的方向
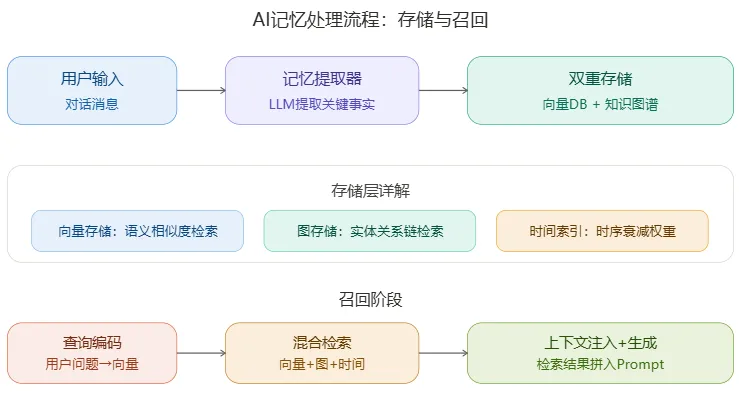
三、记忆的存储流程
- 用户输入 → 发送对话消息
- 记忆提取器 → 用LLM从对话中提取关键事实和实体关系
- 双重存储 →
- 向量数据库:把事实编码为向量,按语义相似度检索
- 知识图谱:把实体和关系存入图结构,按关系链检索
- 时间索引:加上时间戳,越近的记忆权重越高(时序衰减)
四、记忆的召回流程
- 查询编码 → 把用户的新问题编码为向量
- 混合检索 → 同时从向量DB(语义匹配)+ 知识图谱(关系匹配)+ 时间索引(时序排序)中检索相关记忆
- 上下文注入 → 把检索到的记忆片段拼接到Prompt中,作为额外上下文送给LLM
- 生成回答 → LLM基于注入的记忆上下文生成个性化回答
五、核心矛盾:精度 vs 延迟 vs 成本
根据LOCOMO基准测试(ECAI 2025)的关键数据:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
核心洞察:全上下文方案精度最高,但延迟是Mem0的12倍、token消耗是14倍。Mem0用6%的精度损失换来了91%的延迟降低——这就是记忆系统的核心价值。
简单说:不是把所有东西都记住最厉害,而是记住关键的、用最少的token、最快的速度回忆起来,才是AI记忆的真正挑战。
六、向量记忆 vs 图记忆(最关键的区别)
- 向量记忆:像”模糊搜索”——找到语义上相似的事实。适合”你之前说过跟XX相关的事”
- 图记忆:像”关系推理”——沿着实体间的边一步步追踪。适合”我上次提到的那个人的公司最近怎么样了”
Mem0g(图增强变体)准确率68.4%高于纯向量Mem0的66.9%,正是因为图记忆弥补了向量记忆无法做关系推理的短板。
English Original — In-Depth Reports from Global Media
Source 1: Paperclipped — “AI Agent Memory in 2026: From RAG to Persistent Context Architecture”
(Published March 19, 2026)
Anthropic gave Claude a 1 million token context window. Google pushed Gemini to 2 million. OpenAI shipped 128K with GPT-4 Turbo and kept climbing. The assumption was clear: give agents enough room and they will remember everything. They don’t. A 2026 study on context window overflow found that models start deprioritizing critical information once context exceeds 60% capacity, even when the answer sits right there in the window. More tokens did not produce better memory. It just produced more expensive forgetting.
The fix is not a bigger window. It is a memory architecture that knows the difference between working context, long-term facts, and learned behaviors. In 2026, production AI agent teams have largely converged on a layered approach borrowed from cognitive science: working memory, episodic memory, semantic memory, and procedural memory, each stored differently, retrieved differently, and managed by the agent itself.
Why Context Windows Are Not Memory
The fundamental confusion in early agent design was treating the context window as memory. It is not memory. It is attention. Every token in the context window competes for the model’s processing bandwidth. Stuff 200K tokens of conversation history into the window and the model has the information, but it cannot use it effectively.
Redis documented this problem in their context window overflow analysis: system prompts eat thousands of tokens, RAG retrieval consumes thousands more, and conversation history keeps growing until the model starts losing track of what matters. Their data shows production agents hitting context overflow within 15–20 conversation turns, well before any technical token limit.
The cost problem makes it worse. A single 1M-token inference call on Claude costs roughly $15 per 1M input tokens in pricing. Running that per turn in a customer support agent handling 1,000 conversations daily is $15,000 per day just for context, not counting output tokens. No production team fills the entire window, which means every agent has a practical memory ceiling far below the theoretical limit.
The Four-Layer Memory Stack
The architecture that has emerged across frameworks like Letta, Mem0, and LangGraph mirrors how cognitive scientists categorize human memory. It is not a coincidence. The problems are structurally similar: a limited processing window (working memory) backed by multiple types of long-term storage, each optimized for different retrieval patterns.
1. Working Memory: The Active Scratchpad
Working memory is what the agent sees right now: the current context window contents. It includes the system prompt, the active conversation turn, tool definitions, and any state the agent needs for the immediate task. Think of it as the desk you are sitting at, holding only the documents relevant to the task in front of you.
Letta’s architecture treats this like RAM in an operating system. Their “core memory” is a small, agent-editable block that lives directly in the context window. The agent reads and writes it on every turn, keeping only the most relevant facts in the active space. When a piece of information is no longer needed for the current task, the agent pages it out to longer-term storage.
The key insight Letta borrowed from the MemGPT research: agents should manage their own working memory. Instead of a developer deciding what goes in and out of context, the agent itself uses tool calls to read, write, and archive memory blocks. The agent decides what it needs to remember right now and what it can look up later.
2. Episodic Memory: What Happened Before
Episodic memory stores specific interactions and events:
- “The user asked about DSGVO compliance last Tuesday.”
- “The deployment failed because of a missing environment variable.”
- “The customer escalated after three failed resolution attempts.”
It is autobiographical, timestamped, and session-specific.
In practice, episodic memory is searchable conversation history stored outside the context window. Letta calls this “recall memory,” implemented as a database the agent queries via tool calls. Mem0 implements it as extracted “memories” from conversation turns, compressed and indexed for retrieval. Their research shows a 26% accuracy improvement over baseline RAG when agents use structured episodic memory instead of raw conversation retrieval.
The critical difference from just stuffing history into the context: episodic memory is summarized and indexed. A 50-turn conversation becomes 8–12 distilled observations, each tagged with what happened, when, and why it mattered. The agent retrieves episodes by relevance to the current task, not by recency or embedding similarity alone.
3. Semantic Memory: What the Agent Knows
Semantic memory holds facts, rules, and relationships that persist across sessions and users:
- “The company uses Salesforce for CRM.”
- “The user prefers email over phone.”
This is where knowledge graphs and vector databases earn their keep. A fact like “Alice manages the Berlin office” connects to “The Berlin office handles DACH compliance” through explicit graph relationships, not embedding proximity. When the agent needs to answer a question, the graph traversal is direct and reliable.
4. Procedural Memory: How the Agent Acts
Procedural memory is the least discussed and most underrated layer. It stores learned behaviors, workflows, and skills:
- “When a customer mentions billing, check Stripe before asking clarifying questions.”
- “To deploy to staging, run the test suite first, then the Terraform plan, then apply.”
These are not facts to retrieve. They are behaviors to execute.
In most frameworks, procedural memory lives in the system prompt as instructions and few-shot examples. More advanced implementations derive procedural patterns from past successful interactions. If the agent solved a problem five times using the same three-step approach, the system compresses that pattern into a reusable procedure.
The Cost Arithmetic of Layered Memory
Running a full four-layer memory stack is not free, but it is far cheaper than the alternative of maxing out context windows. Analysis of agent context costs found that semantic compression across memory tiers reduces context-related token costs by 38% while actually improving accuracy.
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
Instead of sending 100K tokens of history per turn, a well-architected memory stack sends 15–20K tokens of curated context, broken down as working memory (3–5K), episodic retrieval (5–8K), and semantic lookup (3–5K). The total is 80% less than brute-force — and the retrieval is actually more accurate because each layer uses the right retrieval strategy for its data type.
Source 2: Mem0.ai — “State of AI Agent Memory 2026”
(Published April 1, 2026 · Engineering Team)
The term “AI agent memory” barely existed as a distinct engineering discipline three years ago. Developers shoved conversation history into context windows, called it memory, and moved on. The results — stateless agents, repeated instructions, zero personalization across sessions — were accepted as the cost of working with LLMs.
That framing has been retired. In 2026, memory is a first-class architectural component with its own benchmark suite, its own research literature, a measurable performance gap between approaches, and a rapidly expanding ecosystem of tools built specifically around it.
The Benchmark Reality
The most significant development in AI agent memory research is the arrival of the LOCOMO benchmark — a standardized evaluation dataset designed specifically for long-term conversational memory. Before LOCOMO, memory quality was mostly self-reported or evaluated on ad hoc tasks that were not reproducible across labs. LOCOMO changed the measurement problem: for the first time, it became possible to compare fundamentally different memory architectures on the same evaluation set.
The Mem0 research paper, published at ECAI 2025 and authored by Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav, benchmarked ten distinct approaches to AI memory — from academic baselines like MemGPT and ReadAgent to commercial products like OpenAI Memory and open-source tools like RAG and LangMem. The results are revealing:
| Approach | LLM Score (Accuracy) | End-to-End Median Latency | Token Consumption |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The most important number in this table is not the accuracy column. It is the latency column for full-context: 9.87 seconds median, 17.12 seconds at p95.
Full-context is technically the most accurate approach on the benchmark. It is also the only approach that is categorically unusable in real-time production settings — a 17-second tail latency means one in twenty users waits 17 seconds for a response, at a token cost roughly 14 times higher than the selective memory approaches.
Mem0’s selective pipeline accepts a 6-percentage-point accuracy trade against full-context in exchange for 91% lower p95 latency (1.44 seconds versus 17.12 seconds) and 90% fewer tokens.
The graph-enhanced variant, Mem0g, closes that accuracy gap to under 5 points while staying at 2.59 seconds p95.
Graph Memory: From Experimental to Production
Graph memory in AI agents was largely experimental in 2024. By early 2026, it is in production.
The distinction between vector memory and graph memory is precise: vector memory retrieves semantically similar facts, while graph memory retrieves facts connected through relationships. A vector store can tell you “this user mentioned Python.” A graph store can tell you “this user works with Python, specifically for data pipelines, using pandas, at a company that uses dbt, and they’re migrating from Spark.”
Mem0’s graph-enhanced variant, Mem0g, builds a directed, labeled knowledge graph alongside the vector store during the extraction phase:
-
An entity extractor identifies nodes from conversation text. -
A relations generator infers labeled edges connecting those nodes. -
A conflict detector flags when new information contradicts existing graph elements before they are written.
Open Problems: What Is Still Unsolved
Against the progress, several problems remain genuinely unsolved.
Memory staleness at scale. As memory stores grow, the question of which memories are still accurate becomes harder. A user preference expressed two years ago may no longer apply. Dynamic forgetting applies decay to low-relevance entries, but staleness is a distinct problem: a highly-retrieved memory about a user’s employer is highly relevant until it is not, at which point it becomes confidently wrong rather than just outdated.
Cross-session identity resolution. The current memory model assumes a stable user ID. For applications where users interact across multiple devices or authentication methods, resolving whether two interactions came from the same person — and should share a memory space — is a non-trivial identity problem that memory systems do not currently address.
Privacy and consent architecture. What exactly that governance looks like — how users inspect, edit, or delete their stored memories, how teams audit what is stored, how long memories are retained — is currently an application-layer concern. As persistent AI memory becomes more common in consumer products, the regulatory and ethical expectations around consent architecture will become more specific.
Where Things Stand
AI agent memory in 2026 is a production engineering discipline with real benchmarks, measurable trade-offs, and a growing body of operational knowledge. The selective memory approach — extracting discrete facts, deduplicating, retrieving only what is relevant — has been validated against 10 competing approaches on a standardized benchmark. The infrastructure to deploy it has expanded to cover 21 frameworks, 19 vector stores, and three distinct hosting models.
The field moved faster in the past 18 months than most anticipated. The next phase will be shaped by how the open problems above get addressed, and by what the voice agent ecosystem — the fastest-growing integration category right now — demands from memory systems at real-time latency requirements.

中文精华总结
-
核心矛盾:AI的上下文窗口是”注意力”,不是”记忆”。研究证明,窗口超过60%就开始遗忘,塞入100万token也无济于事,反而造成每天15,000美元的成本。
-
四层记忆架构:工作记忆(当前任务)→ 情景记忆(发生过什么)→ 语义记忆(知道什么事实)→ 程序记忆(会做什么流程),这四层对应人类认知科学的分类体系。
-
数据对比:全上下文方案准确率72.9%但延迟9.87秒、每次消耗26000 token;Mem0选择性记忆准确率66.9%、延迟0.71秒、仅消耗1800 token——用6%的准确率换取了91%的性能提升。
-
未解难题:记忆过时(系统对过时信息依然”自信”)、跨设备身份识别、用户隐私与同意权,这三个问题目前仍是开放性挑战。
核心词汇解析
1. Episodic memory /ˌepɪˈsɒdɪk ˈmem(ə)ri/
n. 情景记忆
认知科学术语,指存储”具体经历”的记忆系统——你记得昨天早餐吃了什么,就是情景记忆。AI中用于存储某次具体对话发生了什么,带时间戳。 📌 例句:Episodic memory stores specific interactions and events — autobiographical, timestamped, and session-specific.
2. Context window /ˈkɒntekst ˈwɪndəʊ/
n. 上下文窗口
LLM每次”能看到”的信息总量,以token数量计算。研究证明它是”注意力”而非”记忆”——超过60%容量就开始遗忘,即使信息还在窗口里。 📌 例句:The context window is not memory. It is attention. Every token in the context window competes for the model’s processing bandwidth.
3. Retrieval-Augmented Generation (RAG) /rɪˈtriːv(ə)l ˈɔːɡmentɪd ˌdʒenəˈreɪʃ(ə)n/
n. 检索增强生成
AI在回答前先去数据库搜索相关信息再生成答案的方法。但测试表明,原生RAG的准确率只有61%,不如专门设计的记忆架构。 📌 例句:RAG scored only 61.0% on the LOCOMO benchmark — significantly below properly designed episodic memory systems.
4. Latency /ˈleɪtənsi/
n. 延迟;响应时间
从发出请求到收到回复的时间。全上下文方案p95延迟高达17.12秒(即最慢的5%用户要等超过17秒),这在生产环境中完全不可用。 📌 例句:A 17-second tail latency means one in twenty users waits 17 seconds for a response.
5. Procedural memory /prəˈsiːdʒərəl ˈmem(ə)ri/
n. 程序性记忆
存储”怎么做事”而非”知道什么”的记忆系统——骑自行车、打字的肌肉记忆就属于这类。AI中对应”学会了某个工作流程”,比如”遇到账单问题先查Stripe”。 📌 例句:These are not facts to retrieve. They are behaviors to execute — the procedural memory layer.
语法精讲
强调倒装句:It is not X. It is Y.
文章开头有一句极具力量的句式:
“The fix is not a bigger window. It is a memory architecture…”
这种”先否定、再肯定”的对比句型,在英文深度报道中极为常见。它的底层逻辑是先打破读者的预期(人们以为更大的窗口能解决问题),再给出真正的答案。
结构公式:
- 否定
:The solution is not [读者的错误预期]. - 肯定
:It is [正确答案].
📌 仿写练习:
-
The problem is not that the model is too small. It is that the training data lacks diversity. -
Success in language learning is not about memorizing more words. It is about building systems to use them.
💡 为什么有力量? 这种结构会触发大脑的”认知纠正”机制——当你否定一个预期时,读者的注意力会瞬间被抓住,然后”正确答案”的记忆度也大幅提升。这是演讲稿、TED Talk和科技深度报道最喜欢用的开场结构之一。
🤔 你觉得AI”记住你”是好事还是坏事?
- 好事派:效率翻倍,不用每次重复背景,AI越用越懂你
- 坏事派:隐私风险,谁在看我的记忆?万一泄露怎么办?
- 中立派:关键在于谁掌控开关——用户应该能随时查看、编辑、删除AI对自己的记忆
文中提到,用户隐私和同意机制是AI记忆领域目前最大的未解难题之一。你期待未来的AI怎样处理你的记忆数据?评论区告诉我 👇
本文英文素材来源:Paperclipped.de(2026.03.19)、Mem0.ai Engineering Team(2026.04.01)数据引用:ECAI 2025 论文 arXiv:2504.19413、LOCOMO Benchmark、Redis Context Overflow Analysis