 夜雨聆风
夜雨聆风





2亿人AI问诊,80%从一开始就错了——三大期刊联合警告
【导读】
全球每周超过2亿人在向ChatGPT等AI询问”我得了什么病”——《自然·医学》《JAMA Network Open》最新研究泼来冷水:AI早期鉴别诊断错误率超过80%,50%的医学回答存在问题,近20%属于”高度有问题”。讽刺的是,AI最终诊断准确率却能达到90%以上。问题不在于技术不行,而在于:当AI给出了错误答案,谁来负责?
一、2亿人每周问AI看病:一个危险的信任游戏
凌晨两点,你突然感到胸闷不适。第一反应不是去医院急诊,而是打开ChatGPT,输入”我胸口疼是怎么回事”。这个场景,正在全球数亿人身上真实上演。
哈佛大学团队与OECD(经济合作与发展组织,涵盖38个成员国)联合发布的研究报告显示,每周有超过2亿人向AI咨询健康问题。这个数字,已经超过了绝大多数国家的人口总数。
更让人揪心的是,麻省总医院研究发现,相当比例的患者会把AI的诊断建议作为实际就医的参考。想想看:当你在凌晨两点得到一个错误的AI诊断,你可能真的会因为”感觉没什么大问题”而错过最佳治疗窗口。
《自然·医学》《JAMA Network Open》《BMJ Open》三大顶级医学期刊在2026年4月密集发布的研究,用数据和案例揭示了一个令人不安的事实:AI医疗正以超乎想象的速度渗透进普通人的健康管理,但这场信任游戏的代价,可能是你的健康甚至生命。

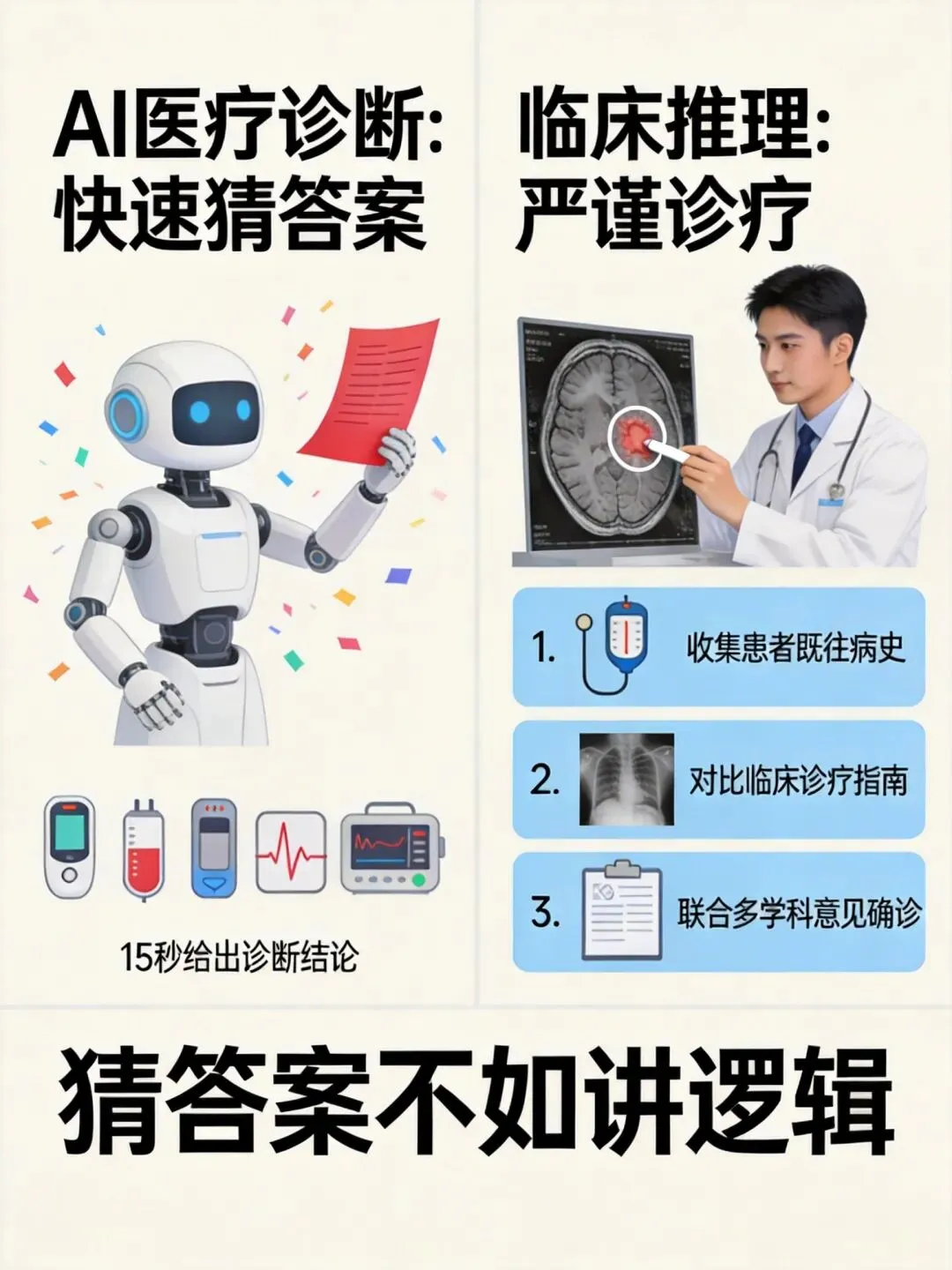
二、80%错误率背后的真相:AI很会”猜答案”,但不擅长”推理过程”
80%的早期鉴别诊断错误率,加上90%以上的最终诊断准确率——这两个数字听起来矛盾吗?
这恰恰揭示了AI医疗最核心的问题:大模型擅长的是”给答案”,而不是”推理过程”。
牛津大学医学AI研究团队打了个形象的比喻:如果把诊断过程比作解一道数学题,AI的表现是这样的——它可能猜对了最终答案(因为见过太多类似题目),但在解题步骤上漏洞百出。简单来说,AI看病更像是”凭直觉猜”,而不是像医生那样”根据症状一步步推导”。
这种差异在简单病例中可能无关紧要,毕竟最终答案对了就行。但在复杂病例中,这就成了致命问题。
《BMJ Open》的研究给出了更具体的数据:50%的AI医学回答存在不同程度的问题,其中近20%属于”高度有问题”——换句话说,如果你完全相信AI的建议,有五成概率会得到一个需要打个问号的诊断,有两成概率可能得到一个危险的误导性建议。
为什么会这样?顶级期刊的研究指向了AI的一个根本性缺陷:缺乏动态临床推理能力。真实世界的临床诊断是一个动态过程,医生需要根据患者的反馈不断调整假设,需要考虑症状的变化、病史的细节、甚至患者的表情和语气。而AI只能基于你输入的文本做出判断,无法进行真正的”问诊-反馈-修正”循环。
三、讽刺的现实:技术越强,风险越大
一个令人细思极恐的悖论:AI诊断错误率这么高,最终准确率却能达到90%以上。答案藏在哪儿?AI的错误,往往发生在最需要谨慎的环节。
研究显示,AI在以下场景最容易出错:
- 早期症状鉴别
:当患者只有模糊的不适时(如”感觉不太对劲”),AI很难做出有意义的判断 - 罕见病识别
:训练数据中的稀缺性导致AI对罕见病症几乎”视而不见” - 多症状交叉判断
:当患者同时有多种症状时,AI容易顾此失彼 - 病情演变预测
:AI无法像有经验的医生那样”预见”病情的可能发展方向
讽刺的是,这些恰恰是专业医生最能发挥价值的场景。当一个经验丰富的急诊科医生看到你”不太对劲”的就诊状态时,他可能会建议你做更多检查;而AI可能给出一个看似合理但实际上遗漏了关键风险的诊断。
更棘手的是,随着AI技术快速迭代,其”迷惑性”也在不断提升。AI生成的医学回答越来越流畅、越来越专业,越来越像一个”合格的医生”——这反而让普通人更难识别其中的错误。《JAMA Network Open》的研究特别警告:当AI的回答看起来”太专业”时,人们反而更容易盲目信任。
结果就形成了这样一个技术悖论:AI越强大,人们越信任它;越信任它,错误的后果就越严重。
四、谁来”兜底”?中国开出监管”药方”
如果把AI医疗比作一辆正在高速行驶的汽车,技术是油门,监管就是刹车。问题是,这辆车的刹车系统还远远跟不上油门。
这正是观点A的核心所在:AI看病不是”行不行”的问题,是”谁来兜底”的问题。
当AI给出了一个错误的诊断建议,导致患者延误治疗甚至发生更严重的后果,这个责任由谁来承担?是开发AI的科技公司?是使用AI的医疗机构?还是患者本人?目前,全球范围内都没有一个清晰的答案。
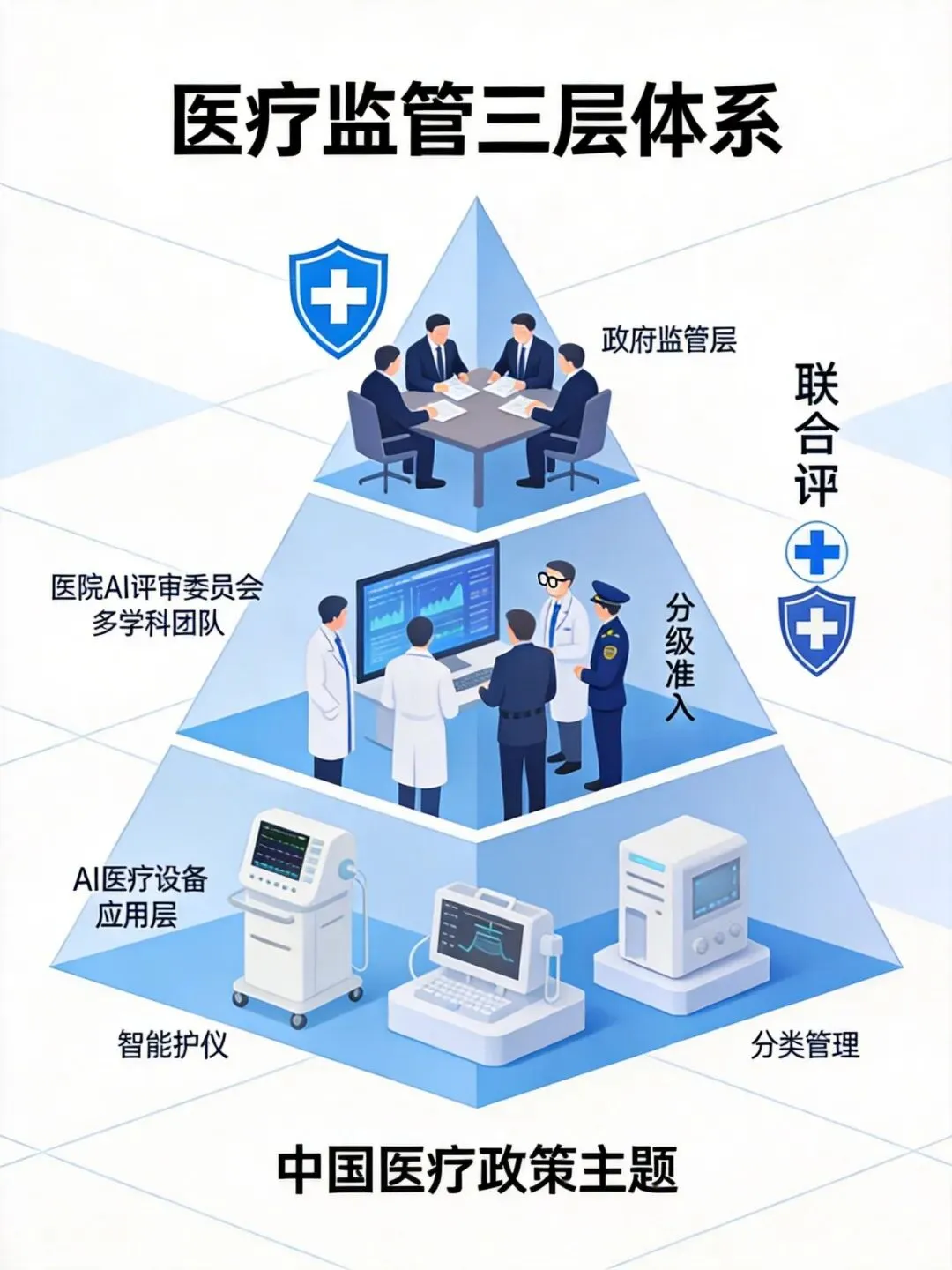
2026年4月,中国率先迈出了一步:《医疗机构人工智能应用与治理专家共识(2026版)》正式发布。这份由顶级医疗机构和监管部门联合制定的共识,提出了一个核心框架:分类管理、分级准入 + 多学科联合审查。
具体来说,这套机制有几个关键点:
- 分类管理
:根据AI医疗应用的风险等级进行分类,高风险应用必须经过更严格的审批 - 分级准入
:不同级别的医疗机构可以使用不同等级的AI医疗工具,不是所有医院都能用所有AI - 多学科联合审查
:AI医疗产品上线前,必须经过临床医学、伦理、法律等多学科专家的联合评审
与此同时,在临床一线,AI医疗正在以更务实的姿态落地。北京天坛医院发布的”小君医生2.0″系统,就是一个典型案例:它专注于影像诊断领域——1分钟完成脑CT分析,覆盖94种疾病,80%的常规病例无需修改直接使用。关键在于,这个系统被定位为“医生的助手”,而非”替代者”——所有AI出具的报告,最终都需要主治医师审核签字。
截至2026年初,中国已有207款AI医疗器械获得三类注册证,80%的县级行政区建成了影像中心,2025年县域远程医学影像诊断服务量超过6800万人次。这些数字说明AI医疗已经实实在在地进入了中国的医疗服务体系——正因如此,”谁来兜底”的问题才变得更加紧迫。
结语:给AI医疗浇一盆冷水,不是为了否定它
80%的早期诊断错误率听起来吓人,但不得不承认:在很多场景下,AI确实能提供有价值的辅助——速度快、成本低、覆盖面广,可以填补基层医疗资源不足的空白。
问题从来不是AI”能不能”看病,而是AI”怎么看病”以及”谁来负责”。每周2亿人向AI询问健康问题,我们需要的不仅是更准确的技术,更需要一套清晰的责任框架、有效的监管机制,以及让普通人能够理性使用AI的健康教育。
AI医疗的真正风险,不是技术不行,而是当技术走在监管前面太久之后,所有人都成了摸着石头过河的”试验品”。
浇这盆冷水,是为了让这辆车开得更稳。
信息来源
-
《自然·医学》(Nature Medicine) — AI早期鉴别诊断错误率研究 -
《JAMA Network Open》— AI医学回答质量评估研究 -
《BMJ Open》— AI健康咨询用户行为研究 -
哈佛大学医学院团队 — AI诊断准确性对比研究 -
麻省总医院 — AI问诊临床影响研究 -
牛津大学 — AI医疗安全评估研究 -
OECD(经济合作与发展组织)— 38个成员国AI医疗应用报告 -
北京天坛医院 — “小君医生2.0″发布(2026年4月) -
中国《医疗机构人工智能应用与治理专家共识(2026版)》 -
经济日报 — 中国AI医疗器械审批数据报道 -
Artificial Analysis — GPT-5.5第三方评测数据