 夜雨聆风
夜雨聆风





警惕!你的AI助手,正在把你的简历"递"给陌生人
当我们在用AI处理工作的时候,AI在怎么处理我们的数据?
一场数据泄露事件背后的技术真相与安全防线
一个普通用户的“意外收获”
最近发生了一件让人细思极恐的事。某社交媒体爆料,一位用户像往常一样打开AI助手,上传了一份PPT让它帮忙翻译。这再普通不过了——你可能今天也做过类似的事。但这次,AI给他的回复里,除了翻译结果,还多了一些”额外内容”:另一位真实用户的完整简历。姓名、手机号、工作履历,清清楚楚。

他没做任何非法操作,没入侵任何系统,只是正常使用了一个AI产品。
“AI幻觉”?别被这个词骗了
事件曝光后,最先出现的官方解释是”AI幻觉”——模型自己编造了这些信息。但这解释站不住。幻觉编出来的是假人假事,而这份简历是真实的,来自另一位真实用户上传的文件。模型不可能凭空”编”出一个精确到手机号的真实身份。
真正的原因更让人不安:AI系统的数据管道出了问题,把别人的数据混进了你的对话里。
这意味着,当你在AI里上传合同、粘贴报表、输入客户信息的时候,这些数据有可能——在某个系统故障的瞬间——出现在另一个陌生人的屏幕上。
你信得过的AI,未必守得住你的数据。
你的数据在AI里经历了什么?
大多数人使用AI的方式是:输入问题,得到回答。看起来很简单。但在你看不到的地方,一次AI对话背后可能涉及这些环节:
六个环节,每一步都有你的数据。每一步,也都有出错的可能。
在这次事件中,问题大概率出在中间某处:
无论哪一种,核心问题都是同一个:系统没有严格区分“这是谁的数据”。
为什么传统安全防线防不住?
很多企业会困惑:我们不是已经有防火墙、DLP、权限系统了吗?但这里有一个关键区别——传统安全保护的是访问权限(谁能打开这个文件),而AI场景下需要保护的是生成内容(模型输出里该不该包含这段信息)。
传统DLP能看到”张三下载了一份合同”,但看不到”模型在回答李四的问题时,引用了张三上传的合同内容”。传统权限系统能控制”谁能访问知识库”,但控制不了”检索系统在向量空间中召回结果时,是否混淆了不同用户的数据边界”。
这不是传统安全做得不好,而是AI创造了一种全新的数据泄露路径——数据不是被”偷走”的,而是被系统自己”递出去”的。
作为企业用户,我们该怎么办?
与其恐慌,不如理性地搞清楚:哪些事是现在就能做的,哪些需要推动AI厂商去改。
这是最务实、见效最快的一步。不管AI应用内部多复杂,最终到用户手里的都是文本。如果我们在模型输出到达用户之前,加上一层独立的内容检测——看到输出里出现了完整的个人简历、合同条款、财务数据,而当前对话的主题只是“PPT翻译”——那就应该拦住它。这不需要改AI应用的代码,只需要在调用大模型的通路上部署一个独立的检测层。
🛡️ 目前市面上已有这类安全网关产品,奇安信发布的大模型卫士就是其中的代表。
它集成了大模型安全网关(GPT-Guard)、安全风险AI鉴定平台、监测审计平台三大核心组件,构建了“检测-管控-审计”一体化防护闭环,具备提问/回复内容审计、风险行为管控、访问异常检测、敏感数据过滤等全流程安全能力。
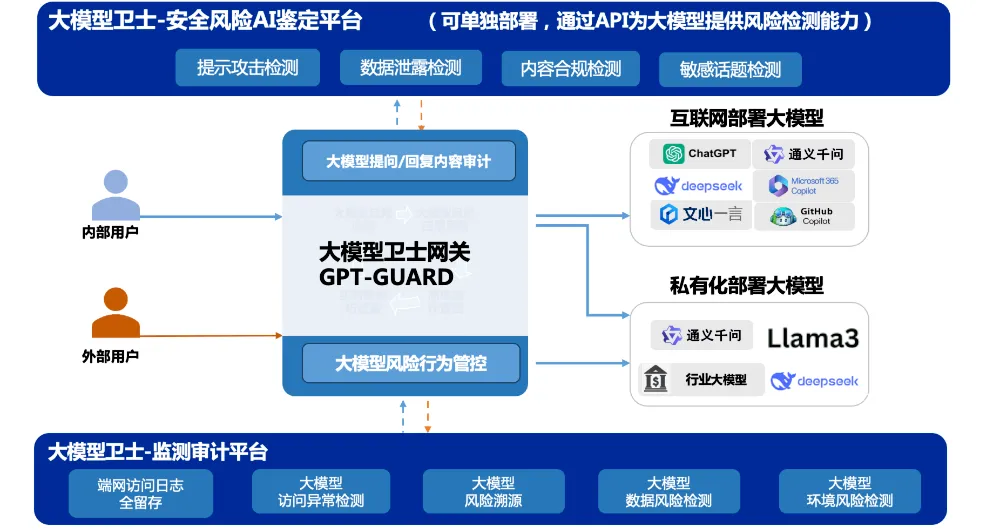
如果你是企业IT或安全负责人,在选择AI产品时,建议直接向供应商问清楚:RAG检索是怎么做的用户隔离?用户上传的文件存在哪?怎么隔离的?后台的异步任务怎么传递用户身份?会话状态怎么管理的?如果供应商答不清楚,或者给出笼统的回答,那就要警惕了。
不要在公共AI平台上处理敏感业务数据;如果必须用AI处理敏感数据,确保使用的是企业私有部署或可信的企业版;在企业内部建立AI使用规范。大模型卫士提供了风险行为管控、访问异常检测等功能,可从技术层面拦截这些高风险行为。
万一真的发生了数据泄露,传统安全事件有成熟的应急流程,但AI数据泄露事件需要额外考虑:如何快速定位是RAG检索出错还是会话串接?如何判断泄露范围?建议提前建立专项预案,定期演练。
网络安全领域没有一招制敌的”银弹”,AI安全更是如此。AI数据隔离是一个行业性的技术难题,没有任何单一产品能包打天下。
作为用户和企业,最现实的做法是分两步走:
短期:在输出侧加一道独立的检测和拦截。这不需要动AI应用的内部架构,部署快、见效快。大模型卫士的核心优势之一就是”零改造嵌入,即刻生效”。
长期:推动AI应用从内部做好数据隔离。这需要AI厂商的配合和改造,也需要用户在选择产品时用脚投票——优先选择能说清楚数据隔离机制的供应商。
两步都做了,才算真正安全。只做第一步是治标,只指望第二步是赌博。
写在最后
AI是很好的工具,我们不应该因为恐惧而放弃它。但我们也该清醒地知道:今天你喂给AI的每一个字,都有可能出现在别人的屏幕上。在AI变得完全可靠之前,多一道安全防护,不是多此一举,是对自己和用户的基本负责。