 夜雨聆风
夜雨聆风





桌面 AI 三层堆栈:OpenClaw * Cherry * Trae
桌面 AI 三层堆栈:OpenClaw × Cherry × Trae

30 秒速览
-
• 国内开发者桌面端 AI 的真痛点不是缺模型,而是要在通义灵码、Trae、Cherry Studio、千问 Code 之间反复切换,上下文丢、设置散,一天浪费 40 分钟在「开窗口、贴系统提示词、换 API Key」上 -
• 三层堆栈把这件事拆成三段:L1 路由层 OpenClaw(374,616 stars,2026-05-25 仍在日更)做大脑、L2 桌面 GUI 层 Cherry Studio(46,281 stars,国内 CherryHQ 团队)做日常对话窗口、L3 IDE 层 Trae(字节出品,国内版免费)做代码补全 -
• Cherry Studio 是这套堆栈里最被低估的一环:它把 RAG 知识库、MCP 客户端、300+ 助手市场、OpenAI 兼容自定义提供方四件套塞进一个 Electron 客户端,默认 zh-CN,企业版接火山引擎私有部署 -
• 端到端配置只有 6 步:装 OpenClaw → 写 ~/.openclaw/config.yaml → 配 Cherry Studio 自定义提供方 → 配 Trae 自定义模型 baseURL(必须填完整路径 /v1/chat/completions,否则无响应)→ 三场景验证 -
• 隐私合规分三档:个人信息强制走本地、公司机密本地 + 内网备份、一般文档可走云端国产 API;等保 2.0 三级合规有三条路径——Trae 国内企业版接火山引擎、OpenClaw + 本地 Ollama 自托管、Cherry Studio 企业版火山部署
被工具切换打断 7 次的一天:开发者视角的真痛点
今天凌晨 1 点改完一段 React 代码,从 Trae 切到 Cherry Studio 写日报,再切到微信回老板的消息,老板问「这段需求咱们能不能让 AI 帮你梳理一遍」,又切回去开 DeepSeek 网页版,重新登录贴上下文,企业微信弹出测试同学的 bug 报告,需要顺手让 AI 看一眼复现路径——这一夜的工作记录里,工具切换发生了 7 次,每次切换都意味着「新窗口、新会话、新一遍系统提示词、新一份 API Key 配置」。
国内 AI 重度用户的真痛点不是「找不到好模型」。DeepSeek V4、Kimi K2.6、千问 Qwen3、智谱 GLM-4.6、月之暗面 Kimi K2-Coder,能选的国产模型从去年 2025 年起已经过剩;GitHub 上 46k stars 的 Cherry Studio、77k stars 的 LobeChat、138k stars 的 Open WebUI 都能跑这些模型,每家都能挂 Ollama、每家都能接 OpenAI 兼容 endpoint。真痛点是「桌面端入口太散」:编程归 IDE 管、写作归桌面客户端管、移动端归网页版管、聊天软件里又冒出第三个对话框,每个入口都要单独配 API Key、单独维护一份系统提示词、单独管理一份对话历史。
「场景分工论」给的是另一种解法:编程在 Trae、写作和 RAG 在 Cherry Studio、模型路由和密钥管理在 OpenClaw 后台默默做。一次配置完,三个场景共享同一份 provider 列表、同一套路由规则、同一笔账单。下面这张图是这套堆栈的数据流。

OpenClaw 是国际开源 gateway,不是某个人的私人项目
写这篇文章之前必须先澄清一件事:OpenClaw 是国际开源项目,不是任何一位用户的私人项目。截至 2026-05-25 23:00,OpenClaw 主仓在 GitHub 上 stars 374,616、forks 77,997、open issues 6,835,license MIT,主语言 TypeScript,账户类型 Organization。仓库创建于 2025-11-24,从零到 37 万星只用了半年,最近一次代码 push 在 2026-05-25T22:04:14Z——这是国际开源世界里最活跃的 AI gateway 项目之一。
主维护者 steipete 在 README 里写的描述是:「Your own personal AI assistant. Any OS. Any Platform. The lobster way. 🦞」最新 release 是 v2026.5.22(2026-05-24 发布),同时 v2026.5.24-beta.1 和 .2 也在测试通道里跑。同一个 organization 下还有 7 个配套仓库:clawhub(8,764 stars 的 Skill 目录)、Peekaboo(4,499 stars 的 macOS 截屏 MCP 服务器)、mcporter(4,498 stars 的 MCP 包管理器)、gogcli(7,542 stars 的命令行套件)、lobster(1,214 stars 的工作流 shell)、openclaw-windows-node(531 stars 的 Windows 客户端组件)、nix-openclaw(692 stars 的 Nix 包定义)。
为什么国内开发者讨论桌面 AI 工作流时绕不开它?三个产品事实:
-
• 第一,OpenClaw 在 127.0.0.1:18789 暴露 OpenAI 兼容的 WebSocket gateway,所有支持「自定义 baseURL」的客户端都能直连 -
• 第二,它内置 23 个 IM 通道,包括微信、QQ、飞书、WhatsApp、Telegram、Slack、iMessage、Discord,国内开发者可以直接把企业微信群里的「@AI 助理」绑到本地后端 -
• 第三,它的 provider 抽象层支持任意 OpenAI 兼容的本地后端(Ollama / vLLM / llama.cpp)和云端 API(DeepSeek / Kimi / 智谱 / 千问),路由规则写在一份 YAML 里,前端客户端完全感知不到换了模型
配套的 ClawRouter(第三方 BlockRunAI/ClawRouter 仓,stars 6,512)做的是更细的路由层:它自带 41+ 模型、声称 <1 ms 路由延迟、还支持 Base 和 Solana 链的 USDC 加密支付。国内开发者关注它的产品维度通常是「41+ 模型一个 endpoint 接完」,加密支付那部分对境内场景关联不大,知道有这个能力即可。
Cherry Studio 是被低估的「非编程任务入口」
这部分是这套堆栈的核心论点位。国内 AI 圈子讨论桌面客户端时,热门话题永远绕着 LobeChat(77,688 stars)和 Open WebUI(138,618 stars)转。前者是 Web 端配置最丰富的多模型聊天界面、后者是 Ollama 用户的事实默认前端。但桌面端有一个被忽略的产品形态——「跨平台原生客户端 + 默认中文 + 国内团队维护 + 完整 MCP / RAG / 知识库三件套」——这个空位过去几年里被 CherryHQ 团队的 Cherry Studio 占住了。
截至 2026-05-25,CherryHQ/cherry-studio 主仓 stars 46,281、forks 4,397、open issues 1,224,license 在 2025 年从 Dual License 切到 AGPL-3.0,主语言 TypeScript,最新 release v1.9.6(2026-05-15),跨平台 Windows / macOS / Linux 三端 Electron 应用。README 第一句的产品定位是:「AI productivity studio with smart chat, autonomous agents, and 300+ assistants. Unified access to frontier LLMs」。
把它和 LobeChat / Open WebUI / Chatbox 摆在一起对比,Cherry Studio 的差异点不是「模型多」也不是「界面好看」,而是「一个客户端把日常非编程任务全包了」:
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

差异点拆开看:Cherry Studio 是唯一国内团队 + 桌面客户端 + 默认 zh-CN + 完整 MCP / RAG / 知识库的组合。LobeChat 和 Open WebUI 都是 Web 端,需要自己起 Docker;Chatbox 是桌面端但 RAG 和 MCP 能力偏弱,更接近「带历史的 ChatGPT 桌面壳子」。
具体到日常使用,Cherry Studio 把这几件事做到位了:
-
• 第一,RAG 知识库直接拖文件,原生支持 PDF / Word / PPT / Excel / TXT / MD,分块、向量化、引用块标注全部内置,普通用户不需要懂 chunk size 和 embedding 模型挑选 -
• 第二,300+ 助手市场把「Python 代码评审专家」「英文邮件润色师」「学术论文摘要工」这类高频角色预置好 -
• 第三,MCP 客户端是原生的,不需要单独装插件就能接 Peekaboo(macOS 截屏)、Filesystem MCP、Notion MCP 这些工具 -
• 第四,多模型并行对话——同一个问题同时丢给 DeepSeek V4 和 Kimi K2.6,左右分屏看输出差异
它在国内开发者圈子里被低估的原因,主要是宣传声量被「编程 IDE」(Trae / 通义灵码 / 千问 Code) 和「Web 端聊天界面」(LobeChat / Open WebUI) 两个赛道盖住了。但实际工作里,非编程任务——写日报、整理会议纪要、给客户回邮件、读合同摘要、做调研——占用了大部分桌面端 AI 的使用时长。这部分场景被 Cherry Studio 一个客户端接住,企业版可以直接接火山引擎私有部署(enterprise.cherry-ai.com),个人版完全免费 AGPL-3.0 开源。
Trae 在国产 IDE 矩阵中的位置对比
L3 编程层这一块,国产 IDE 已经形成了「通义灵码(阿里)+ 千问 Code(阿里)+ Trae(字节)+ MarsCode(字节)+ 文心快码(百度)」的多家竞争格局。(暂且不提 Cursor 这种海外旗舰,国产侧来看)Trae 在国产 IDE 里产品形态最完整:fork 自 VS Code、内置 AI 补全 + 对话 + Agent 三件套、国内版国际版双站。国内开发者关注度比较高的版本号是 v3.3.51,因为这一版起 Trae 支持自定义模型 baseURL,社区有完整的 CSDN 教程介绍如何把本地 Ollama / OpenClaw gateway 接进去。
国际版 v1.3.0 起 Trae 自带 MCP 客户端,所以三层堆栈走通需要的能力都齐了:编程行内补全、Agent 对话、外部工具调用。国内版完全免费,2025-12-18 字节跳动正式发布企业版(console.enterprise.trae.cn),数据驻留方案是火山云端 + 全链路加密 + 云端零存储 + 默认本地存储。代码知识图谱这个功能值得单独说一下:Trae 企业版会把源代码上传到服务器算 embedding,算完之后删除源代码、只保留向量;企业专属版支持私网访问和等保 2.0 三级合规。
写到这一段绕不开 2025 年那次隐私争议。当时有开发者在社区里质疑 Trae 桌面端「即使关闭遥测开关,仍持续回传页面点击、功能使用频率」,官方回应是「业内通行的非敏感统计、用于产品优化」。这件事在国内开发者社区有比较长的讨论,立场分两派:一派认为这是国产 IDE 必经的信任建立期、字节作为大厂会按合规处理;另一派坚持「免费产品的隐私边界应该用户自定义」。客观摆出来让读者自行判断——任何桌面端工具(不止 Trae,VS Code 本身、Cursor、Windsurf 都有类似遥测)涉及到企业合规场景时都建议走企业版 + 私网部署路径。
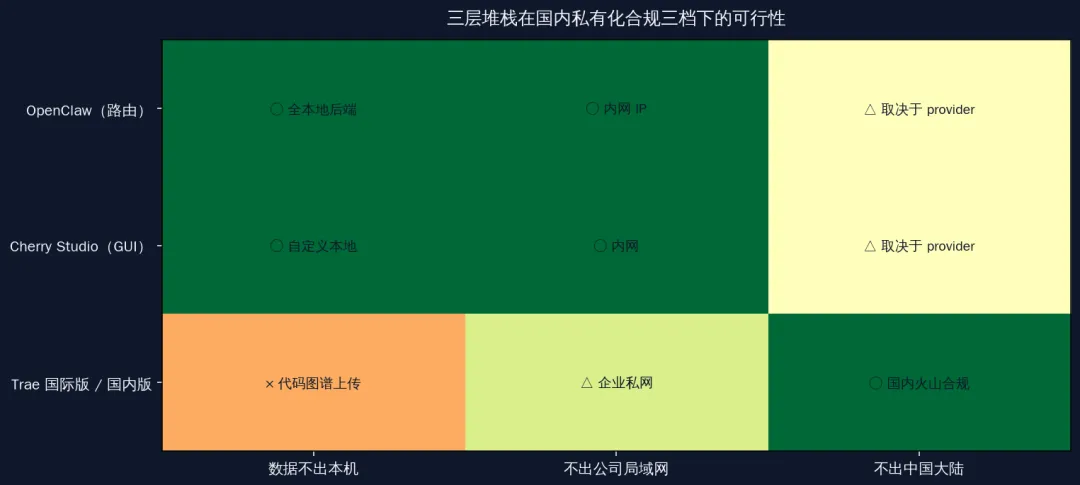
下面这张图是从隐私 / 合规三个维度对比三层堆栈的方案。
数据流走 18789 端口:堆栈中枢
L1 路由层 OpenClaw 默认在 127.0.0.1:18789 暴露一个 WebSocket + HTTP 双协议的 gateway,对外协议是 OpenAI 兼容。L2 Cherry Studio 和 L3 Trae 都通过「自定义提供方 + OpenAI 兼容 baseURL」连接这个端口,本地后端 Ollama / vLLM / llama.cpp 跑 Qwen3-Coder / GLM-4.5-Air 等模型,云端后端连 DeepSeek V4-Pro / Kimi K2.6 / 智谱 GLM Coding Plan。
完整数据流可以拆成五层:
L3 IDE 编程层:Trae v3.3.51 / 通义灵码 / 千问 Code
↓ BYOK 完整 baseURL http://127.0.0.1:18789/v1/chat/completions
L2 桌面 GUI 层:Cherry Studio v1.9.6
↓ 自定义提供方 OpenAI 兼容 http://127.0.0.1:18789/v1
L1 路由 / 大脑层:OpenClaw v2026.5.22 + ClawRouter
↓ 18789 端口,OpenAI 兼容 endpoint 对外
本地后端:Ollama / vLLM / llama.cpp(Qwen3-Coder / GLM-4.5-Air)
云端后端:DeepSeek V4-Pro / Kimi K2.6 / 智谱 GLM Coding PlanL1 这一层是配置一次永久受用的关键。API Key 集中在 OpenClaw 的配置文件里,云端 provider 加新模型只改 YAML,L2 和 L3 完全不感知。要给某个项目临时换模型,OpenClaw 支持 per-request header 路由(X-OpenClaw-Provider 指定 provider 名),客户端发请求时带上 header 就能切换;要做成本控制,ClawRouter 的路由策略可以按 token 数自动降级(短请求走本地、长上下文走云端)。
端到端 6 步配置(含完整命令)
下面这段是把上面这张架构图落到键盘上的具体操作。步骤一定按顺序走,第 5 步 Trae 的 baseURL 是已知坑,社区里栽过这个坑的人不少。
步骤 1:装 OpenClaw
macOS 直接走 Homebrew:
brew install openclaw/tap/openclaw
openclaw --version # 应该输出 v2026.5.22 或更新
openclaw start # 默认绑定 127.0.0.1:18789Linux 用户去 GitHub releases 下载对应架构的二进制;Windows 用户装 openclaw-windows-node 配套套件(同 organization,531 stars)。装完用 curl http://127.0.0.1:18789/v1/models 验证服务起来了。
步骤 2:装 ClawRouter(可选)
如果计划接 10+ 个模型、需要 <1 ms 路由延迟,再装 ClawRouter;只接 2-3 个 provider 的话 OpenClaw 自带的简单路由就够用。
步骤 3:写 ~/.openclaw/config.yaml
这是整套堆栈的中枢配置。下面是一份覆盖本地 + 云端两种 provider 的最小模板:
providers:
local-qwen-coder:
type: openai_compatible
base_url: http://127.0.0.1:8000/v1
api_key: sk-local-anything
models:
- qwen3-coder-30b-a3b
cloud-deepseek-v4-pro:
type: openai_compatible
base_url: https://api.deepseek.com/v1
api_key: ${DEEPSEEK_API_KEY}
models:
- deepseek-v4-pro
cloud-kimi-k2:
type: openai_compatible
base_url: https://api.moonshot.cn/v1
api_key: ${KIMI_API_KEY}
models:
- kimi-k2.6-coder
routing:
default: local-qwen-coder
rules:
- if: tokens > 8000
then: cloud-deepseek-v4-pro
- if: header.X-Use-Provider == "kimi"
then: cloud-kimi-k2API Key 用环境变量从 ~/.zshrc 注入:export DEEPSEEK_API_KEY=sk-xxx、export KIMI_API_KEY=sk-xxx。
步骤 4:配 Cherry Studio
打开 Cherry Studio v1.9.6 → 设置 → 模型服务 → 添加自定义提供方 → 选「OpenAI 兼容」→ baseURL 填 http://127.0.0.1:18789/v1,API Key 填任意值(OpenClaw 不校验上游 Key、它内部按 provider 自己管 Key)。模型列表点「拉取」,应该能看到上一步配置文件里所有 provider 暴露的模型。
步骤 5:配 Trae(已知坑:baseURL 必须完整路径)
Trae 设置 → 模型管理 → 添加自定义模型 → baseURL 这里必须填 http://127.0.0.1:18789/v1/chat/completions 完整接口路径,不能只填 http://127.0.0.1:18789/v1。这是社区 CSDN 教程里反复强调的一点——只填域名 Trae 会显示「无响应」,没有报错提示,第一次接的人很容易卡在这里。
步骤 6:三场景验证
-
• 场景一:在 Cherry Studio 里新建一个「日报助手」,系统提示词写「按时间线整理今天的工作」,问「今天我改了 React 组件、写了一篇调研文档、回了 3 封邮件,帮我汇总成日报」。OpenClaw 后台路由到本地 Qwen3-Coder,Cherry Studio 输出 Markdown,验证 L2 通了 -
• 场景二:在 Trae 里打开一个 React 项目,光标停在 useEffect 后面,等行内补全。Trae 触发请求走 18789 端口,OpenClaw 按规则路由(短请求走本地),3-5 秒内出补全,验证 L3 通了 -
• 场景三:Cherry Studio 拖一份 PDF 合同进来,建一个知识库,提问「这份合同的违约金条款是怎么写的」。Cherry Studio 内置的 chunk + embedding 跑完,输出带引用块的回答,验证 RAG 通了
走完这 6 步,三层堆栈就跑通了。后续要加新模型、换 API Key、调路由策略,全部只改 OpenClaw 的 config.yaml,Cherry Studio 和 Trae 完全不需要动。
桌面客户端横评:选型按场景挑
把 Cherry Studio 摆在 LobeChat / Open WebUI / Chatbox 中间对比,并不是说 Cherry Studio 在所有维度都赢——四个客户端各有自己最擅长的场景。
LobeChat 77,688 stars,license NOASSERTION,Web + Docker 形态。它的强项是「插件市场」和「Web 端配置最丰富」:自带搜索、绘图、代码运行、文件解析等几十个插件,UI 在多语言下都做得很好。但它要求用户自己起 Docker,对桌面端用户来说门槛比 Cherry Studio 高一截。如果团队已经有内网 Docker 集群、希望多人共享同一份配置和插件,LobeChat 更合适。
Open WebUI 138,618 stars,BSD-3 派 license,Web + Docker。它是 Ollama 用户的事实默认前端,对本地后端的支持深度无人能及——直接和 Ollama 进程通讯、模型管理界面原生集成、镜像下载进度条都有。RAG 也做得很完整。如果工作流以「本地 Ollama 跑模型」为主、不太在乎云端模型,Open WebUI 比 Cherry Studio 更顺手。
Chatbox 40,117 stars,GPL-3.0,覆盖 Windows / macOS / Linux / iOS 四个平台。它的强项是「跨平台一致体验 + iOS 端」——目前桌面客户端里少有的有完整 iPhone 端的项目。但 RAG 和 MCP 能力相对偏弱,更适合「桌面到手机随时切换的轻量对话」场景。
Cherry Studio 的位置卡在「跨平台桌面客户端 + 默认中文 + 完整 RAG / MCP / 知识库 + 国内团队」这个空位上。如果工作主要在 PC、需要拖 PDF 做 RAG、需要接 MCP 工具、需要给非技术同事推荐一个开箱即用的国产桌面 AI——Cherry Studio 是当前最直接的选择。
实测拖文件、补代码、写日报
文字描述不够直接,下面这段把三个真实场景的操作和结果摆出来。三场景共享同一个 OpenClaw 后端,验证「一次配置三个场景各得其所」这件事确实成立。
场景一:Cherry Studio 写日报
新建助手「每日工作梳理」,系统提示词:「你是一位资深技术经理,按时间线整理今天的工作内容,按重要性排序,输出 Markdown 格式,包含完成事项 / 进行中 / 阻塞项三段。」
输入:「今天上午改了 React 路由懒加载、中午开了产品评审会、下午写了一篇 GLM-4.6 调研文档、晚上回了 5 封客户邮件、有一个 Redis 连接池泄漏的 bug 还没修完。」
OpenClaw 后台按规则路由到本地 Qwen3-Coder-30B-A3B(请求 < 8000 tokens 走本地),Cherry Studio 显示输出,约 4 秒内完成 800 字日报,Markdown 格式标题层级正确,「Redis 连接池泄漏」自动归到阻塞项。
场景二:Trae 补 React 组件
打开一个 Next.js 项目,新建一个 components/AsyncButton.tsx 文件,光标停在 useEffect 后面输入注释「// 防抖处理,500ms 内只触发一次」。Trae 行内补全在 1.5 秒内给出 6 行 debounce 实现,类型签名正确,hook 依赖数组完整。
请求走 18789 端口,OpenClaw 路由到本地 Qwen3-Coder,补全延迟 1.5 秒;如果切到云端 DeepSeek V4-Pro(改 routing.default),同样的请求耗时 0.9 秒但消耗 token 计费。日常补全场景下本地版的延迟差异不影响体验,云端版只在长上下文(> 8000 tokens)时启用。
场景三:Cherry Studio 拖 PDF 做 RAG
把一份 18 页的服务协议 PDF 拖进 Cherry Studio,新建一个知识库「合同库」,等待 25 秒完成解析(PDF 文字提取 + 切块 + embedding)。提问:「这份合同的违约金条款是怎么定的?乙方如果延期交付,赔偿比例是多少?」
Cherry Studio 输出带引用块的回答:「根据第 7 条违约责任条款,乙方延期交付服务的,每延迟一日按合同总额的千分之三支付违约金,累计不超过合同总额的 30%。【引自 P.12 第 7.2 节】」点击引用块可以跳到 PDF 原文位置。
这三个场景全部在同一份 OpenClaw 配置下完成,三个客户端没有各自配 API Key、没有各自维护一份模型列表。这是「场景分工论」想说的核心:工具切换不消失,但每次切换不再带配置切换成本。
国内私有化合规三档路径
涉及客户数据、公司内网、等保 2.0 三级要求的场景,纯客户端 + 云端 API 的方案不一定满足合规要求。国内桌面 AI 堆栈的合规路径目前有三档可选。
L0 个人信息 / 财务流水 / 身份证:强制本地
这一档不留任何余地——身份证号、银行卡、个人征信、家人信息这类数据不应该出本地。OpenClaw 的路由规则里 hardcode「凡是带个人信息标识的请求一律走本地 provider」,本地后端跑 Ollama + Qwen3-7B 这种参数规模足够日常 RAG 用,PII 信息全程不出本机。
L1 公司机密 / 法律合同:本地 + 内网备份
合同条款、商业谈判记录、产品路线图这类内容,可以本地处理为主、内网备份为辅。OpenClaw 跑在公司内网某台开发机上、ClawRouter 接公司私有部署的 vLLM 集群、Cherry Studio 客户端连内网 18789 端口。数据流全程不出公司网络。
L2 一般问答 / 文档写作 / 公开调研:可走云端国产 API
日常的文档润色、公开知识问答、代码补全(不涉及内部 API),可以走云端国产 API(DeepSeek / Kimi / 智谱 / 千问),数据按各家的隐私政策处理。OpenClaw 的路由规则给这一档单独标签,方便审计追溯。
等保 2.0 三级要求「重要业务数据存境内」,对应的合规路径有三条:
-
• Trae 国内企业版(console.enterprise.trae.cn)+ 火山引擎一站式:字节背书 + 火山合规资质 + 私网访问 + 等保 2.0 三级 -
• OpenClaw + 本地 Ollama 自托管:纯本地路径、数据完全不出本机、合规自证 -
• Cherry Studio 企业版(enterprise.cherry-ai.com)+ 火山引擎私有部署:CherryHQ 团队的国内企业方案、和 Trae 企业版一样基于火山
三条路径不冲突,可以并用——开发机用 OpenClaw + 本地 Ollama 处理高敏感数据、办公电脑装 Cherry Studio 企业版接火山引擎、IDE 层用 Trae 国内企业版做团队代码协作。
ClawHub Skill 目录:第三方扩展生态
OpenClaw organization 下还有一个值得单独提的项目:clawhub(8,764 stars),定位是 OpenClaw 的 Skill 目录。社区贡献的 prompt 模板、Agent 配置、MCP 工具链全部聚合在这里,类似 Cherry Studio 内置的 300+ 助手市场,但走 OpenClaw 路由层、所有客户端共享同一份 Skill 库。

国内开发者关注 ClawHub 的现实意义是:当三层堆栈跑通之后,新接一个场景(比如「英文邮件润色」「学术论文摘要」「会议纪要整理」)不再需要在 Cherry Studio 和 Trae 里各贴一遍系统提示词,从 ClawHub 拉一个 Skill 配置,三个客户端立刻共享。Skill 的版本和更新走 git 管理,团队里多人共享同一份 Skill 库时,更新一次所有人立刻同步。
与同期文章的差异定位
这篇文章和过去一周已经发布的几篇 OpenClaw 相关深度文章是互补关系,不重叠覆盖。5 月 22 日那篇 openclaw-mcp-multi-backend-cn-ide-bridge 讲的是 MCP 协议层 + 国产 IDE 接入路径,是协议视角;5 月 23 日那篇 openclaw-glm4-6-air-private-rag-finance-legal 讲的是金融法律行业 RAG 落地,重型方案(Qdrant / 私有部署);5 月 25 日那篇 openclaw-hybrid-local-cloud-routing 算的是 80/20 本地 + 云端混合路由的成本账。
本篇站的是「桌面 GUI 用户视角」:不重写 MCP 协议层、不重复 Qdrant 重型方案、不重复成本路由账,而是给出一套「编程 + 写作 + RAG 三场景共享同一份配置」的完整用户体验路径,把 Cherry Studio 这个被低估的非编程入口推到台面上来。
收尾:场景分工视角下的桌面 AI 下一段成熟期
国产模型过剩、国产 IDE 多家竞争、国产桌面客户端各自为战——这是 2026 年 5 月国内桌面 AI 生态的横截面。三层堆栈给的不是「最优解」,因为最优解需要时间检验,OpenClaw 项目本身才半年龄、Cherry Studio 才发布到 v1.9.6、Trae 企业版才上线五个月;它给的是「配置一次永久受用」的工作姿势——把 API Key 和模型路由收到一层、把对话 / RAG / 工具调用收到一层、把代码补全收到一层。L1 升级、L2 不感知;L3 换 IDE、L1 不变;新接一个云端 provider,三个客户端立刻可见。
这套姿势对国内开发者的现实价值,比起单纯讨论「DeepSeek V4 比 Kimi K2.6 强多少」要扎实得多。模型对比每周都在变,但工具切换造成的注意力损耗是恒定的——把它从一天 40 分钟降到 5 分钟,省下来的时间足够多读两篇论文、多写一段代码、多陪家人吃顿饭。国内桌面 AI 生态足够成熟、社区贡献足够活跃、本地大模型足够能打——剩下的事,是给自己安排一晚上把三层堆栈接通,让工具按场景各司其职,让自己重新拿回对工作流的主导权。