 夜雨聆风
夜雨聆风





昨天我的OpenClaw花了64.34元,很超出我的意料,但不是设置不对,是贵有贵的道理
昨晚8:42收到深度求索的短信,告知我的开放平台账户余额已低于预警阙值。随后不到十分钟我登录开放平台一看,居然欠费一块多钱了。当时多少有点纳闷,不是十分钟前说还有9.82元吗,怎么一会功夫我还倒差一块多了呢。但这种事似乎无法查询更多细节,心想大概是短信来得晚了一点吧。于是接着再充值100元。
昨天晚上弄的有点晚,到12点多才关电脑睡觉。
今天早上起来一看,昨晚消费金额64.34元。这可大大超出了我的预料,玩了快一个月的OpenClaw和Hermes了,一般的时候消耗也就十几、二十块吧。不是很多人都说Token费用不高吗,平常用的话,一个月300元差不多了。
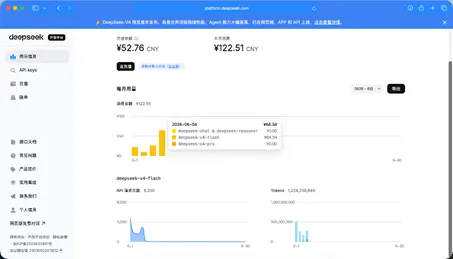
进一步细节显示,deepseek-v4-flash API请求次数:8,341,Tokens:1,224,289,370——你没有看错,大概是12.24亿,这个数据应该是6月总的Tokens吧。
仔细分析了一下问题,昨天我主要是在windows电脑上用的OpenClaw,这台电脑新装的,本来是想着不用每次都看MacBook小屏幕吧,也没有多留意OpenClaw的具体配置。但问题就出在这里——
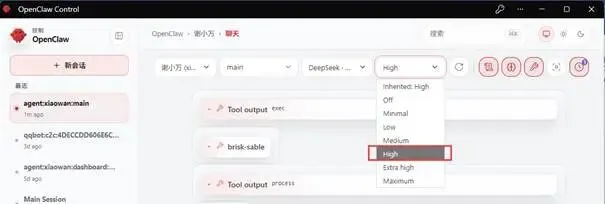
上图圈出来的方框,是 OpenClaw的“思考级别”(Thinking Level)设置。简单来说,它控制着AI在回答前“思考”得多仔细。
这些选项包括:Low、Off、Minimal、Medium、High、Extra high、Maximum。其实是从最低到最高的,这些级别的思考深度依次递增:
Off:不启用。AI几乎不进行额外思考,直接给出最直接的回应。
Minimal / Low:“思考”/“深度思考”。非常轻量的内部推理,适合简单任务和快速响应。
Medium:“更深度思考”。常规任务,平衡性能与成本的最佳起点。
High / Maximum (Max):“ultrathink”(最大预算)。AI会投入大量计算资源,进行极为详尽和严谨的推理,适合解决复杂问题。
Extra High (Xhigh):“ultrathink+”。这是最顶级的思考强度,目前主要支持GPT-5.2、Codex、Anthropic Claude Opus 4.7等最先进的模型。
Adaptive:自适应模式。让AI根据任务难度动态决定需要多少“思考”,属于较高级的玩法。
Token 消耗:等级越高,消耗越快
是的,结论非常明确:选择High或Maximum会消耗明显更多的Token,速度也更快。
Token 消耗量直接与思考深度挂钩:AI 的每一次“推理”,都会生成内部的推理 Token。思考级别越高,生成的内部推理内容就越长,消耗的 Token 就越多。
成本呈倍数级增长:有开发者的经验表明,仅因非必要地开启了高级思考模式,Token消耗就可能翻倍。长此以往,这会是一笔不小的成本。
简单来说,可以把Medium作为默认思考等级,仅在遇到复杂难题时临时切换至High或Max。这是一种兼顾效率与成本的有效策略。
使用AI最基本的窍门:相信贵有贵的道理
小龙虾火起来以后,跟风的小伙伴千千万万,但只有真正持续投入使用的人才觉得它是真的好用。但这期间,不少人反复折腾Ollama,希望搭建本地大模型,永久免费;也有人广泛宣扬NVIDIA免费算力等。但实际上谁用谁知道,免费的从来都不是好用的。与其总在纠结于免费,倒不如用更高端的版本把工作效率提升起来,毕竟这年头,时间才是最大的成本!
我个人的切身体会,之前在MacBook里,始终用的是deepseek-v4-flash,思考级别也是默认的Minimal,结果经常错误百出,往往一个稍微复杂的问题绕来绕去始终摆不明白。但是可气的是,中间很多过程又让你坚信它其实是有那个能力解决问题的。所以我们总在其中反反复复,浪费了大量的时间,还解决不了根本问题。
昨天不经意用了high(思考级别),以前反复没搞定的问题,居然一次性成功了。
所以,这个64.34元花的是相当值得的。贵真的有贵的道理!
