 夜雨聆风
夜雨聆风





openclaw源码解读:如何新增一个channel
导读: 上一篇拆完消息总线,小编这次不画饼了——直接撸代码,用官方
wecom_aibot_sdk把企业微信机器人接进 nanobot。4 个文件、一条完整消息链路,看完你也能给任何 AI Agent 框架加新 Channel。零基础友好,附完整源码解读。
一、上篇画完饼,这次烙真饼
上一篇讲 Gateway 和消息总线的时候,小编甩了句”19 个平台稳稳接住”,后台就有人追着问:
“道理是懂了,那真要我自己加一个平台,到底要动哪些代码?”
哎,问到点子上了。今天就用 nanobot 里企业微信的官方 SDK——wecom_aibot_sdk——亲手接一个 Channel 给你看。
先说清楚一件事:很多人一看”openclaw 源码解读”以为是剖析openclaw源码,其实不是,我们解读的是nanobot 这个项目。nanobot 是 openclaw 生态里最轻量的一个子项目,5000 行代码,44.8K star,麻雀虽小五脏俱全。
小编自己读源码的初心很实在:强化 Python 能力 + 学优秀的 Agent 设计。所以这篇不光讲”怎么接”,更讲”为什么这么接”。
要解读的就 4 个文件,都在 nanobot/channels/ 目录下:
|
|
|
|
base.py |
|
|
registry.py |
|
|
manager.py |
|
|
wecom.py |
|
|
记住这四个角色的分工,下面的代码读起来就不会迷路。
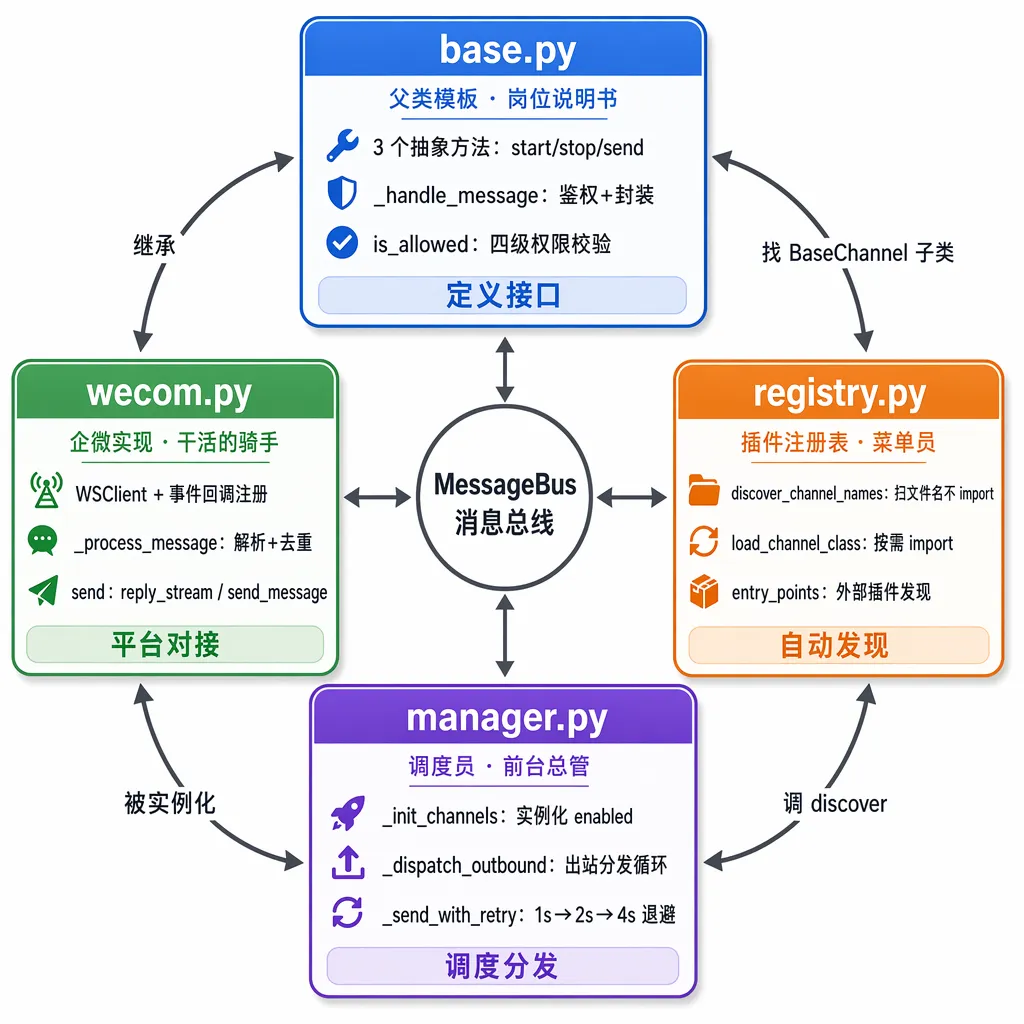
二、BaseChannel:所有 Channel 的”岗位说明书”
2.1 先翻开”岗位说明书”——三个必须实现的方法
源码里 base.py 开头有个类比,小编觉得特别准:
BaseChannel = 「外卖骑手岗位说明书」WecomChannel = 「在企业微信平台干活的骑手」
岗位说明书规定了什么?不管你在哪个平台跑,必须会三件事:
classBaseChannel(ABC): # ABC=抽象基类,不能直接实例化,只能被继承 name: str = "base"# 平台标识,如 "wecom" display_name: str = "Base"# 给人看的名字def__init__(self, config: Any, bus: MessageBus):self.config = config # 本 channel 的配置self.bus = bus # 消息总线,入站/出站队列入口self._running = False @abstractmethod # 装饰器:子类必须实现,否则实例化时报 TypeErrorasyncdefstart(self) -> None:"""连接平台、长期监听消息"""pass @abstractmethodasyncdefstop(self) -> None:"""断开连接、释放资源"""pass @abstractmethodasyncdefsend(self, msg: OutboundMessage) -> None:"""把 AI 的回复发出去,失败应 raise 让 manager 重试"""pass翻译成人话:
-
• start():连平台,开始听消息 -
• stop():断开连接,收工 -
• send():把回复发出去
任何一个平台,只要实现这三个方法,就能接入 nanobot。就这么简单。
💡 基类只规定”必须会什么”,不规定”怎么干”——这就是策略模式的精髓。
2.2 隐藏的”保镖”——_handle_message
base.py 里还有个非抽象方法_handle_message(),所有子类收到平台消息后统一调它。这是父类替子类写好的通用逻辑:
asyncdef_handle_message( self, sender_id, chat_id, content, media=None, metadata=None, session_key=None, is_dm=False,) -> None:"""统一入口:鉴权 → 构造标准消息 → 扔到总线"""# 第一关:权限检查ifnotself.is_allowed(sender_id):if is_dm: # 私聊的陌生人?发配对码 code = generate_code(self.name, str(sender_id))awaitself.send(OutboundMessage( channel=self.name, chat_id=str(chat_id), content=format_pairing_reply(code), ))return# 没权限,到此为止# 第二关:构造标准消息 meta = metadata or {} # None 转成空 dict,避免后面 .get 报错ifself.supports_streaming: meta = {**meta, "_wants_stream": True} # 告诉 agent:此 channel 可收流式回复 msg = InboundMessage( channel=self.name, sender_id=str(sender_id), chat_id=str(chat_id), content=content, media=media or [], metadata=meta, )# 第三关:扔到消息总线awaitself.bus.publish_inbound(msg)逻辑就三步:鉴权 → 封装成统一格式 → 扔到总线。
这一步是整个设计的精髓——不管你从企微、Telegram 还是 Discord 来,进了总线,长得一模一样。子类只管”把平台原始消息翻译成 content + media”,脏活累活在 _handle_message 里统一处理。
2.3 is_allowed:四级权限校验
_handle_message 第一关调的 is_allowed(),源码长这样:
defis_allowed(self, sender_id: str) -> bool:"""通配符 > 白名单 > 配对码 > 拒绝"""# config 可能是 dict(JSON 读进来)也可能是 Pydantic 对象,两种都要兼容ifisinstance(self.config, dict): allow_list = (self.config.get("allow_from") # snake_caseorself.config.get("allowFrom") # 兼容 camelCaseor [] )else: allow_list = getattr(self.config, "allow_from", None) or []if"*"in allow_list: # 1. 全放行returnTrueifstr(sender_id) in allow_list: # 2. 白名单returnTrueif is_approved(self.name, str(sender_id)): # 3. 配对码验证过returnTruereturnFalse# 4. 都没过?拒绝四层递进,很清楚。这里有个细节——is_approved 是从持久化的 pairing store 里查的,意思是你之前用配对码审批通过的用户,下次来直接放行,不用再发码。
小编提示:
str(sender_id)这个转换不能省。有些平台传 int 类型的 user_id,不做转换,白名单里字符串对不上,权限校验就废了。这种 bug 调起来能让你怀疑人生。
三、registry.py:插件是怎么被自动发现的
3.1 零导入扫描
知道了 BaseChannel 长什么样,下一个问题来了:框架怎么知道有哪些 Channel 可用?
registry.py 的 discover_channel_names() 给出了答案:
_INTERNAL = frozenset({"base", "manager", "registry"}) # 框架文件,不是 channeldefdiscover_channel_names() -> list[str]:"""只扫文件名,不 import 任何 SDK"""import nanobot.channels as pkgreturn [ namefor _, name, ispkg in pkgutil.iter_modules(pkg.__path__)if name notin _INTERNAL andnot ispkg ]这个函数只扫 channels/ 目录下有哪些 .py,一个都不 import。
为什么?因为每个 Channel 依赖不同的三方 SDK——Telegram 用 python-telegram-bot,企微用 wecom_aibot_sdk,Discord 用 discord.py……全部 import 一遍,启动慢得你想砸键盘。
所以策略是:先看菜单(文件名),用户点了哪个才去做(import)。
3.2 按需加载
defload_channel_class(module_name: str) -> type[BaseChannel]:"""import 指定模块,返回其中第一个 BaseChannel 子类""" mod = importlib.import_module(f"nanobot.channels.{module_name}")for attr indir(mod): obj = getattr(mod, attr)# 是类 + 继承 BaseChannel + 不是 BaseChannel 本身ifisinstance(obj, type) andissubclass(obj, BaseChannel) and obj isnot BaseChannel:return obj # 如 WecomChannel 类raise ImportError(f"找不到 BaseChannel 子类")这段代码的聪明之处在于——它不需要你显式注册。你写个 wecom.py,里面定义一个继承 BaseChannel 的类,框架自动就能找到。
这才是真正的懒加载——不是偷懒,是聪明。你只用企微,凭什么要等 Discord SDK 加载完?
3.3 外部插件:entry_points
registry 还支持外部插件,通过 pip 包的 entry_points:
defdiscover_plugins(enabled_names=None):"""从 pip 包的 entry_points 发现第三方 channel""" plugins = {}for ep in entry_points(group="nanobot.channels"):if enabled_names isnotNoneand ep.name notin enabled_names:continuetry: cls = ep.load() # 动态加载插件类 plugins[ep.name] = clsexcept Exception as e: logger.warning("Failed to load channel plugin '{}': {}", ep.name, e)return plugins意思是——第三方开发者可以打包自己的 channel,pip install 后自动被 nanobot 发现。不用改 nanobot 一行代码。
这个扩展性,老实说,比很多商业框架都开放。
四、manager.py:把所有 Channel 跑起来的调度员
4.1 实例化——从配置到对象
ChannelManager 是 gateway 里的”前台调度员”。它一启动,就按 config 把 enabled 的 channel 实例化出来:
def_init_channels(self) -> None:from nanobot.channels.registry import discover_channel_names, discover_enabled# 第1步:列出候选 module 名(只扫文件名) names = discover_channel_names() candidate_names = set(names)# 第2步:从候选里找 enabled=true 的 enabled_names = set()for name in candidate_names: section = getattr(self.config.channels, name, None)if section isNone:continueif section.get("enabled", False): # 配置里开了 enabled enabled_names.add(name)# 第3步:import 类并实例化for name, cls in discover_enabled(enabled_names, _names=names).items(): section = getattr(self.config.channels, name, None)try: channel = cls(section, self.bus) # 关键:cls(...) 创建实例self.channels[name] = channel # 存入字典 logger.info("{} channel enabled", cls.display_name)except Exception as e: logger.warning("{} channel not available: {}", name, e)三步走:列候选 → 筛 enabled → 实例化。
注意第 3 步的 cls(section, self.bus)——这就是多态的魔法。cls 可能是 WecomChannel,也可能是 TelegramChannel,但 ChannelManager 不用关心,统一调 cls(...) 就行。
单个 channel 初始化失败(比如没装 SDK)只 warning,不影响其他 channel。这种”容错隔离”的设计,小编个人超爱——企微挂了 Telegram 照常干活,不拖后腿。
4.2 启动——并发跑起来
实例化完了,就该启动了:
asyncdefstart_all(self) -> None:ifnotself.channels: logger.warning("No channels enabled")return# 1. 启动出站分发后台任务self._dispatch_task = asyncio.create_task(self._dispatch_outbound())# 2. 并发启动所有 channel tasks = []for name, channel inself.channels.items(): tasks.append(asyncio.create_task(self._start_channel(name, channel)))await asyncio.gather(*tasks, return_exceptions=True)两件事并发:出站分发循环 + 所有 channel 的 start()。
return_exceptions=True 这个参数很重要——某个 channel 挂了不会拖垮其他 channel。
4.3 出站分发——_dispatch_outbound
这是 manager 里最核心的方法,一个无限循环,专门从 bus 的 outbound 队列取消息,路由到对应 channel:
asyncdef_dispatch_outbound(self) -> None: pending = []whileTrue:try:if pending: msg = pending.pop(0)else: msg = await asyncio.wait_for(self.bus.consume_outbound(), timeout=1.0, # 最多等 1 秒,为了能响应 cancel )# 分支1:模型推理 → 路由到 send_reasoningif msg.metadata.get("_reasoning_delta"): channel = self.channels.get(msg.channel)if channel isnotNoneand channel.show_reasoning:awaitself._send_with_retry(channel, msg)continue# 分支2:进度消息 → 按 send_progress 开关过滤if msg.metadata.get("_progress"):ifnotself._should_send_progress(msg.channel):continue# 分支3:流式 delta → 合并if msg.metadata.get("_stream_delta") andnot msg.metadata.get("_stream_end"): msg, extra_pending = self._coalesce_stream_deltas(msg) pending.extend(extra_pending)# 路由到目标 channel channel = self.channels.get(msg.channel)if channel:awaitself._send_with_retry(channel, msg)except asyncio.TimeoutError:continue# 1s 内无消息,空转一轮except asyncio.CancelledError:break# stop_all 取消 task → 退出上面是三个主要分支:推理 / 进度 / 流式。原码里还有 _retry_wait(内部重试等待)、_runtime_model_updated(WebUI 模型更新)等内部分支,都会被直接 continue 跳过,用户不可见。剩下的普通消息走默认路由,交给对应 channel 的 send。
4.4 失败重试——指数退避
发送失败不是直接丢,而是按 1s → 2s → 4s 退避重试:
_SEND_RETRY_DELAYS = (1, 2, 4) # 重试间隔asyncdef_send_with_retry(self, channel, msg): max_attempts = max(self.config.channels.send_max_retries, 1)for attempt inrange(max_attempts):try:awaitself._send_once(channel, msg)return# 成功except asyncio.CancelledError:raise# 取消必须向上抛except Exception as e:if attempt == max_attempts - 1: logger.exception("Failed after {} attempts", max_attempts)return delay = _SEND_RETRY_DELAYS[min(attempt, len(_SEND_RETRY_DELAYS) - 1)] logger.warning("Send failed, retrying in {}s", delay)await asyncio.sleep(delay)这里有个细节小编特别要夸——except asyncio.CancelledError: raise。说实话,这一行很多教程代码都漏,小编自己第一次写异步重试也漏过。取消信号必须向上抛,否则 shutdown 时任务停不干净,会留一堆僵尸 task——这种 bug 平时不爆,一到生产环境压测就出来作妖。
五、WecomChannel:企微接入实战
前三个文件是”框架的脚手架”,这一节才是真正的”接入实战”。
5.1 配置类——WecomConfig
wecom.py 一上来先定义配置类,描述 config.json 里 wecom 段有哪些字段:
classWecomConfig(Base):"""Pydantic 配置类:描述 config.json 里 wecom 段""" enabled: bool = False bot_id: str = ""# 企微机器人 ID secret: str = ""# 机器人密钥 allow_from: list[str] = Field(default_factory=list) # 白名单 welcome_message: str = ""# 进群欢迎语用 Pydantic 而不是普通 dict 的好处是——类型校验自动做,配置错了启动时就报错,不用等到运行时才发现。
小编踩坑:
allow_from默认值必须用Field(default_factory=list),不能直接写allow_from=[]。Python 里函数默认参数是共享的,多个实例会共用同一个 list,这是个经典坑。
5.2 start()——连平台,注册事件
子类必须实现的第一个方法。WecomChannel 的 start 干了三件事:检查依赖、建 WebSocket、注册事件回调。
asyncdefstart(self) -> None:ifnot WECOM_AVAILABLE: # SDK 没装?优雅退出self.logger.error("SDK not installed. Run: pip install nanobot-ai[wecom]")returnifnotself.config.bot_id ornotself.config.secret:self.logger.error("bot_id and secret not configured")returnfrom wecom_aibot_sdk import WSClient, generate_req_id # 延迟 importself._running = Trueself._loop = asyncio.get_running_loop()self._generate_req_id = generate_req_id# 创建 WebSocket 客户端self._client = WSClient({"bot_id": self.config.bot_id,"secret": self.config.secret,"reconnect_interval": 1000,"max_reconnect_attempts": -1, # -1 = 无限重连"heartbeat_interval": 30000, })# 注册各种事件回调self._client.on("connected", self._on_connected)self._client.on("authenticated", self._on_authenticated)self._client.on("disconnected", self._on_disconnected)self._client.on("error", self._on_error)self._client.on("message.text", self._on_text_message)self._client.on("message.image", self._on_image_message)self._client.on("message.voice", self._on_voice_message)self._client.on("message.file", self._on_file_message)self._client.on("message.mixed", self._on_mixed_message)self._client.on("event.enter_chat", self._on_enter_chat)awaitself._client.connect_async()whileself._running: # 保活循环await asyncio.sleep(1)小编跑通之后,回头又看了几遍 start(),有几个细节值得单独点一下:
-
1. WECOM_AVAILABLE检查——用importlib.util.find_spec探测 SDK 是否安装,没装就优雅退出,不让整个 gateway 崩。 -
2. 延迟 import—— from wecom_aibot_sdk import ...写在函数内部,只有真正要用时才加载。这样没装 SDK 的用户启动 nanobot 也不会报错。 -
3. max_reconnect_attempts: -1——无限重连。企微网络抖动很常见,自动重连救命。 -
4. 事件驱动—— .on(事件名, 回调)注册一堆回调,SDK 触发事件时调我们的 async 方法。
企微这套 WebSocket 接入有个好处小编特别喜欢——不需要公网 IP。Telegram 还得配 webhook 或长轮询,企微直接 WebSocket 长连,内网开发机都能跑。
5.3 接收消息——_process_message
事件回调最终都汇聚到一个统一入口 _process_message。以文本消息为例:
asyncdef_on_text_message(self, frame: Any) -> None:awaitself._process_message(frame, "text") # 统一进处理函数asyncdef_process_message(self, frame: Any, msg_type: str) -> None:try:# 解析 frame.body body = frame.body ifhasattr(frame, 'body') else {}# 取消息 ID(去重用) msg_id = body.get("msgid", "")ifnot msg_id: msg_id = f"{body.get('chatid', '')}_{body.get('sendertime', '')}"# 取发送者 from_info = body.get("from", {}) sender_id = from_info.get("userid", "unknown")# 权限校验ifnotself.is_allowed(sender_id):return# 去重:处理过的 msg_id 直接跳过if msg_id inself._processed_message_ids:returnself._processed_message_ids[msg_id] = None# 限制去重队列长度,防止内存泄漏whilelen(self._processed_message_ids) > 1000:self._processed_message_ids.popitem(last=False) chat_id = body.get("chatid", sender_id)# 按消息类型提取 content content_parts: list[str] = [] media_paths: list[str] = []if msg_type == "text": text = body.get("text", {}).get("content", "")if text: content_parts.append(text)elif msg_type == "image":# 下载图片,存路径 file_path = awaitself._download_and_save_media(...)if file_path: filename = os.path.basename(file_path) content_parts.append(f"[image: {filename}]") media_paths.append(file_path)# ... voice / file / mixed 类似 content = "\n".join(content_parts)ifnot content:return# 保存 frame,send 时要用(reply 需要)self._chat_frames[chat_id] = frame# ★ 调父类的统一入口awaitself._handle_message( sender_id=sender_id, chat_id=chat_id, content=content, media=media_paths orNone, metadata={"message_id": msg_id, "msg_type": msg_type}, )except Exception:self.logger.exception("Error processing message")这段代码有几个细节值得品:
① 去重:企微的 WebSocket 在网络抖动时可能重复投递同一条消息。_processed_message_ids 用 OrderedDict 做 LRU,超过 1000 条删最早的,内存可控。
② frame 暂存:self._chat_frames[chat_id] = frame。企微的 reply 接口需要原始 frame,这里先存起来,send 时能取到。
③ 调父类 _handle_message:注意这一步——子类收到消息后不直接操作 bus,而是调父类的统一入口。父类做鉴权、封装、扔总线。这就是 base.py 注释里说的”子类收到用户消息后,应调用 self._handle_message(…)”。
子类只管”翻译平台消息”,通用逻辑交给父类。这才是继承的正确姿势——共享逻辑下沉,特有逻辑上浮。
5.4 send()——发回复
子类必须实现的第三个方法。WecomChannel 的 send 处理两类内容:媒体和文本。
asyncdefsend(self, msg: OutboundMessage) -> None:ifnotself._client:self.logger.warning("client not initialized")returntry: content = (msg.content or"").strip() is_progress = bool(msg.metadata.get("_progress")) frame = self._chat_frames.get(msg.chat_id) # 取之前存的 frame# 1. 先发媒体文件for file_path in msg.media or []:ifnot os.path.isfile(file_path):continue media_id, media_type = awaitself._upload_media_ws(self._client, file_path)if media_id:if frame:# 有 frame → 用 reply(在原消息上下文回复)awaitself._client.reply(frame, {"msgtype": media_type, media_type: {"media_id": media_id}, })else:# 没 frame → 主动 send_messageawaitself._client.send_message(msg.chat_id, {"msgtype": media_type, media_type: {"media_id": media_id}, })else: content += f"\n[file upload failed: {os.path.basename(file_path)}]"ifnot content:return# 2. 再发文本if frame: stream_id = self._generate_req_id("stream")awaitself._client.reply_stream( frame, stream_id, content, finish=not is_progress, # 进度消息不 finish )else:awaitself._client.send_message(msg.chat_id, {"msgtype": "markdown","markdown": {"content": content}, })except Exception:self.logger.exception("Error sending message")这里有个双路径设计很关键:
-
• 有 frame(用户刚发过消息)→ 用 reply_stream,在原消息上下文回复,支持流式 -
• 没 frame(AI 主动推送)→ 用 send_message,发 markdown
为什么这么分?因为企微的 reply 接口有”会话上下文”——能在用户消息上方显示”正在输入”,体验更好。但主动推送时没有上下文,只能用普通 send。
小编自己跑的时候发现:
finish=not is_progress这个参数控制流是否结束。进度消息_progress=True时finish=False,告诉企微”后面还有”,UI 上显示成”正在思考”。AI 最终回复时finish=True,UI 收尾。细节拉满。
5.5 媒体上传——分块 + MD5 校验
最后看一个稍微复杂的——_upload_media_ws。企微的媒体上传不是一次 HTTP POST,而是分块走 WebSocket:
asyncdef_upload_media_ws(self, client, file_path):from wecom_aibot_sdk.utils import generate_req_id as _gen_req_id fname = os.path.basename(file_path) media_type = _guess_wecom_media_type(fname) # 按后缀猜类型# 1. 读文件 + MD5def_read_file(): file_size = os.path.getsize(file_path)if file_size > WECOM_UPLOAD_MAX_BYTES: # 200MB 上限raise ValueError(f"File too large: {file_size} bytes")withopen(file_path, "rb") as f:return file_size, f.read() file_size, data = await asyncio.to_thread(_read_file) md5_hash = hashlib.md5(data).hexdigest()# 2. 切块(每块 512KB);memoryview 零拷贝切片,省内存 chunk_size = 512 * 1024 mv = memoryview(data) chunk_list = [bytes(mv[i : i + chunk_size])for i inrange(0, file_size, chunk_size)]del mv, data # 释放引用,帮 GC# 3. 发 init 请求,拿 upload_id req_id = _gen_req_id("upload_init") # 每个请求一个独立 req_id resp = await client._ws_manager.send_reply(req_id, {"type": media_type, "filename": fname,"total_size": file_size, "total_chunks": len(chunk_list),"md5": md5_hash, }, "aibot_upload_media_init")if resp.errcode != 0:returnNone, None upload_id = resp.body.get("upload_id") if resp.body elseNoneifnot upload_id:returnNone, None# 4. 逐块上传for i, chunk inenumerate(chunk_list): req_id = _gen_req_id("upload_chunk") resp = await client._ws_manager.send_reply(req_id, {"upload_id": upload_id,"chunk_index": i,"base64_data": base64.b64encode(chunk).decode(), }, "aibot_upload_media_chunk")if resp.errcode != 0:returnNone, None# 5. 发 finish 请求,拿 media_id req_id = _gen_req_id("upload_finish") resp = await client._ws_manager.send_reply(req_id, {"upload_id": upload_id, }, "aibot_upload_media_finish")if resp.errcode != 0:returnNone, None media_id = resp.body.get("media_id") if resp.body elseNoneifnot media_id: # 没拿到 media_id 也算失败returnNone, Nonereturn media_id, media_type三步握手:init(拿 upload_id) → chunk × N(逐块上传) → finish(拿 media_id)。
为什么要这么麻烦?因为 WebSocket 长连接里塞大文件,不分块一旦中断就要从头来。分块后断点续传成本可控。MD5 校验防止传输过程中数据被改。
这个设计在文件上传场景里几乎是标配,但很多教程不会讲——小编自己第一次写文件上传也是直接 POST,被生产环境的网络抖动教做人。
六、消息流转全景——以 WeCom 为例
讲了四个文件,现在把它们串起来,看一条消息从用户手里到 AI 回复的全过程。
入站流程(用户 → AI):
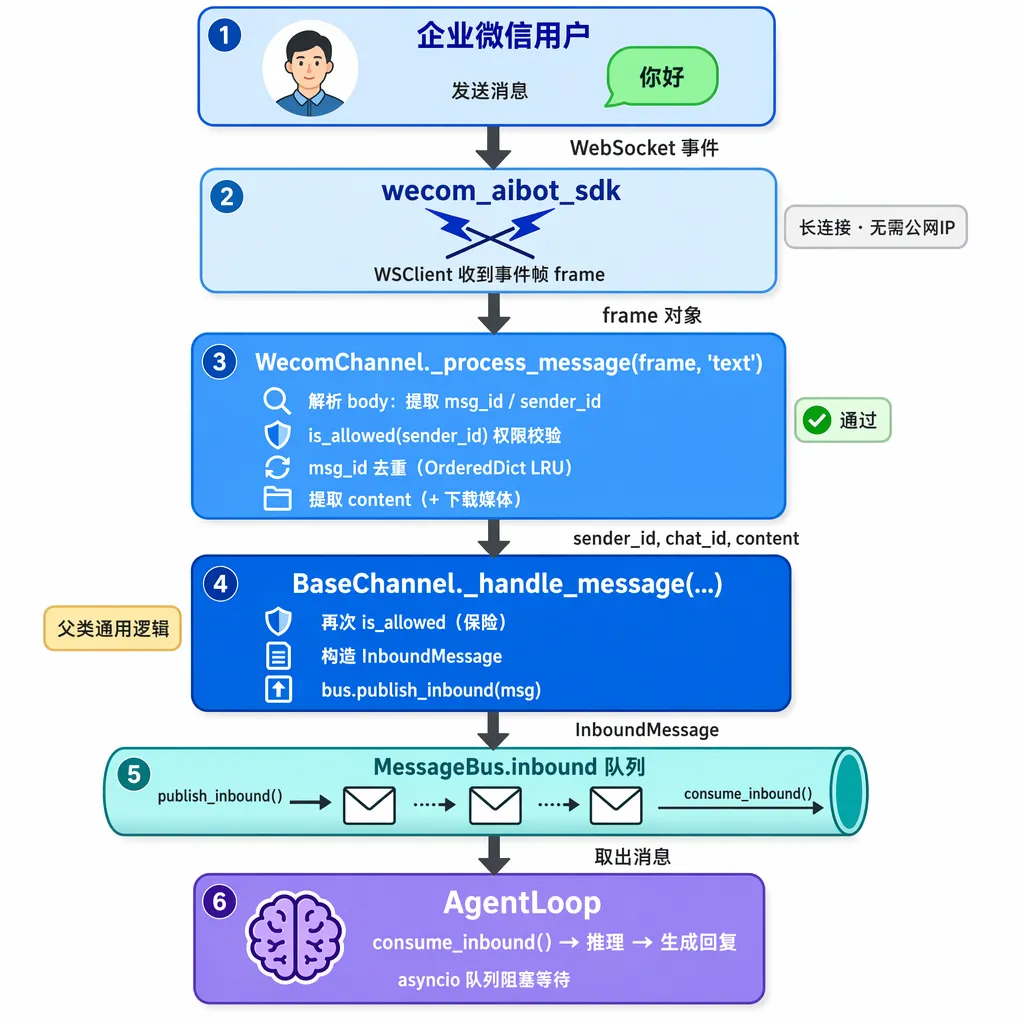
入站流程图:6 个节点垂直流转,蓝色系渐变表现”流入”。完整 Prompt 见配图方案文件
文字版对照(方便复制引用):
用户在企微发"你好" ↓wecom_aibot_sdk WebSocket 收到事件 ↓WecomChannel._on_text_message(frame) ← SDK 事件回调 ↓WecomChannel._process_message(frame, "text") ├─ 解析 body,提取 msg_id / sender_id ├─ is_allowed(sender_id) 权限校验 ├─ msg_id 去重 └─ 提取 content(+ 下载媒体) ↓BaseChannel._handle_message(sender_id, chat_id, content, ...) ├─ 再次 is_allowed(保险) ├─ 构造 InboundMessage └─ bus.publish_inbound(msg) ↓MessageBus.inbound 队列 ↓AgentLoop.consume_inbound() → 推理 → 生成回复出站流程(AI → 用户):
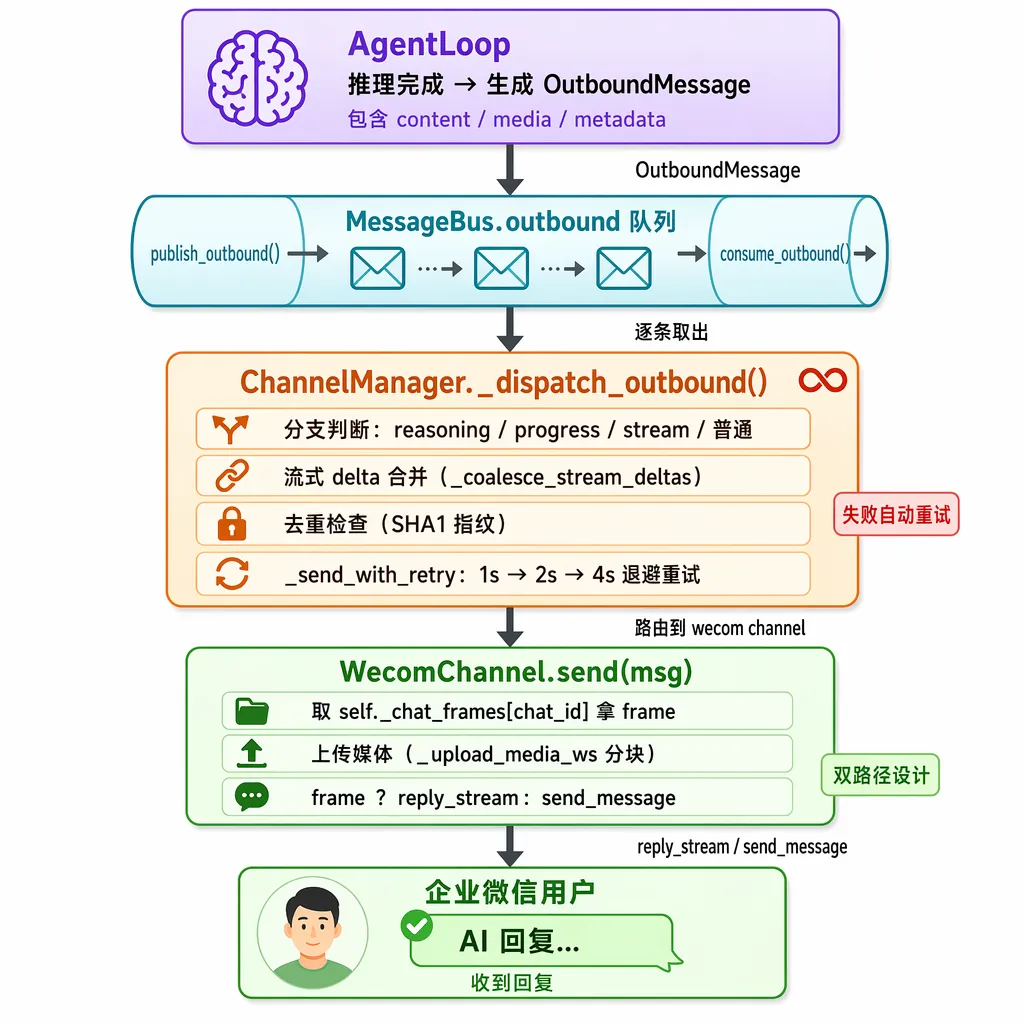
出站流程图:5 个节点垂直流转,紫→绿渐变表现”流出”。完整 Prompt 见配图方案文件
文字版对照(方便复制引用):
Agent 生成回复 OutboundMessage ↓bus.publish_outbound(msg) ↓MessageBus.outbound 队列 ↓ChannelManager._dispatch_outbound() ← 后台无限循环 ├─ 分支判断(_reasoning / _progress / _stream_delta / 普通) ├─ 流式 delta 合并 ├─ 去重检查 └─ _send_with_retry(channel, msg) ↓WecomChannel.send(msg) ├─ 取 self._chat_frames[chat_id] 拿 frame ├─ 上传媒体(_upload_media_ws 分块) └─ frame ? reply_stream(content) : send_message(markdown) ↓用户在企微看到 AI 回复两张图对着看,能发现一个有意思的事——入站和出站走的是两套完全独立的路径,唯一的交汇点在 MessageBus 的那两条队列。这也是为什么上一篇小编要把 Bus 单独拎出来讲:它一断,整条链路就两头都摸不着对方。
整个链路:用户消息 → WecomChannel 解析 → BaseChannel 鉴权+封装 → Bus → Agent → Bus → ChannelManager 调度 → WecomChannel 发送 → 用户。
一条消息走完,跨越 4 个文件、3 个异步队列、2 次权限校验、1 次去重、可能 N 次重试。
4 个文件各司其职,消息在其中像流水一样自然流转——这就是好架构的样子。
七、写在最后
读完这四个文件,小编最大的感受是——好的框架设计,复杂度是”分摊”的,不是”堆叠”的。
每个文件只干一件事:
-
• base.py定义接口,把”必须会什么”和”通用逻辑”分开 -
• registry.py只管发现,按需 import 不浪费 -
• manager.py只管调度,容错隔离不拖垮 -
• wecom.py只管企微,脏活累活自己消化
你想加个新 Channel?照着 wecom.py 写一个,继承 BaseChannel,实现三个方法,扔到 channels/ 目录——框架自动发现、自动实例化、自动调度。一行注册代码都不用写。
这就是分摊的力量——没有任何一个文件背负所有复杂度。base 只管接口,bus 只管队列,registry 只管扫描,wecom 只管企微。每个模块单看都简单到像玩具,组合起来 19 个平台稳稳接住。
反过来想,如果把这四件事塞进一个”超级 Channel 类”里?大概率会变成那种谁也不敢动的祖传代码。
如果你正在做 AI Agent 框架、或者任何需要多端接入的系统,这套”抽象基类 + 注册表 + 调度员 + 消息总线”的四件套,可以直接抄作业。
下一篇你想看什么?Agent 核心的推理循环怎么跑的?还是 Session 会话管理怎么维护上下文?评论区告诉我,点赞高的先拆。
觉得有用就点个关注在看——下期见 👋