 夜雨聆风
夜雨聆风





在线教程丨32K上下文一次解析数十页文档,百度开源Unlimited OCR,重构长复杂场景

作者:李宝珠
编辑:yudi
转载请联系本公众号获得授权,并标明来源
HyperAI(hyper.ai)的教程版块已上线「Unlimited-OCR:一键部署长文档 OCR 与版面解析」,降低部署门槛,助力快速验证模型
过去几年,OCR 已逐渐从「识别图片里的文字」演变为完整的文档理解(Document Understanding)任务。企业和开发者不仅需要提取文本,还希望模型能够识别复杂版面结构、解析表格与公式、理解多栏排版,并最终输出适合下游 RAG、知识库或办公自动化使用的结构化结果。然而,当处理扫描报告、论文、PPT、合同以及多页 PDF 等长文档时,传统 OCR 流程往往需要逐页推理、再进行后处理拼接,不仅效率较低,也容易造成上下文信息割裂。
以 DeepSeek OCR 为代表的新一代端到端 OCR 模型,通过引入大语言模型作为解码器,充分利用语言先验,显著提升了识别准确率和复杂版面解析能力。但与此同时,一个新的挑战也随之出现:随着输出内容不断增长,模型的 KV Cache 会持续累积,显存占用越来越高,生成速度也会越来越慢。换句话说,模型越接近文档结尾,推理成本越高。
百度团队近期开源的 Unlimited OCR 正是针对这一行业痛点提出了解决方案。该模型以 DeepSeek OCR 为基础,引入全新的 Reference Sliding Window Attention(R-SWA) 机制,替换了解码器中的传统 Attention,在降低 Attention 计算成本的同时,将整个解码过程中的 KV Cache 控制为恒定大小。结合 DeepSeek OCR 编码器本身较高的信息压缩能力,Unlimited OCR 能够在默认 32K 上下文长度下,一次前向推理完成数十页文档的 OCR 与版面解析,为长文档处理提供了一种更具工程价值的新思路。更值得关注的是,R-SWA 并不仅适用于 OCR,还具备扩展至自动语音识别(ASR)、机器翻译等长序列解析任务的潜力。
目前,HyperAI(hyper.ai)的教程版块已上线「Unlimited-OCR:一键部署长文档 OCR 与版面解析」,降低部署门槛,助力快速验证模型 ⬇️
在线运行:https://go.hyper.ai/YfaB5
查看相关论文:https://go.hyper.ai/PZsJo
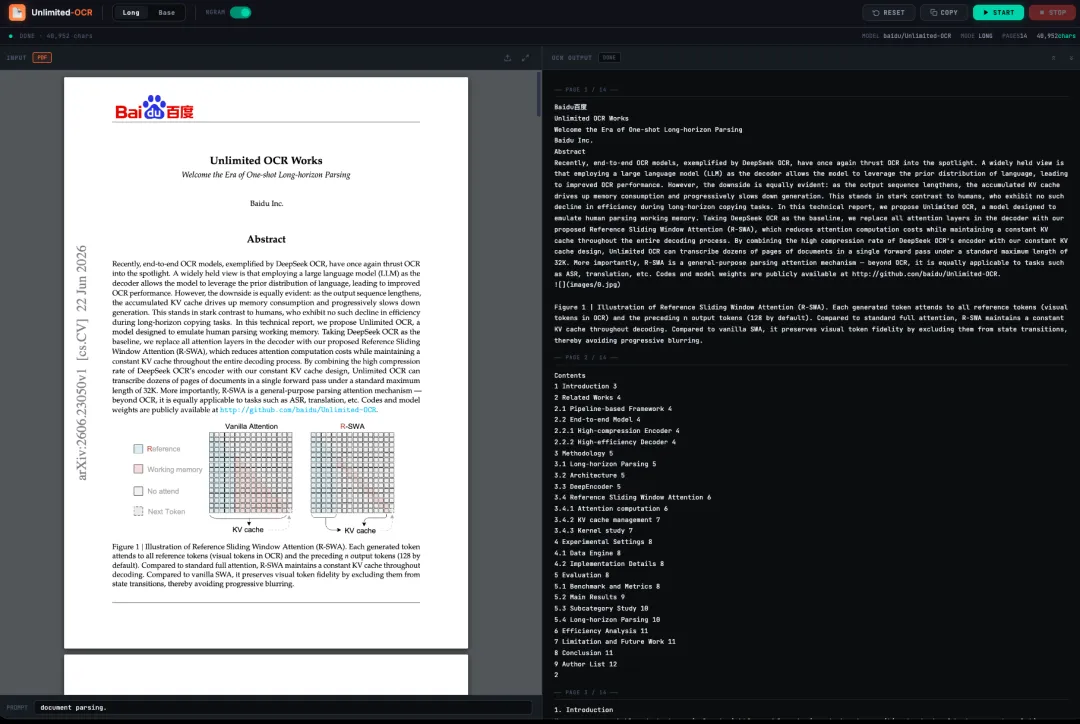
Demo 示例
更多在线教程:
https://hyper.ai/notebooks
Demo 运行
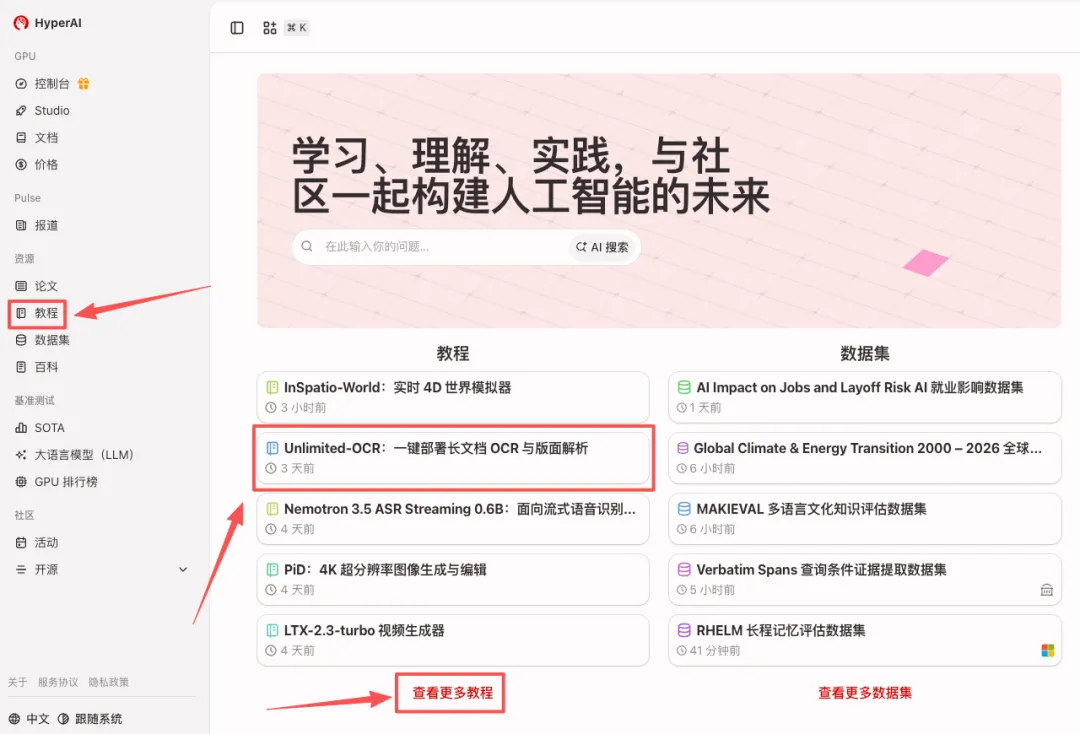
1.进入 hyper.ai 首页后,选择「教程」页面,或点击「查看更多教程」,选择「Unlimited-OCR:一键部署长文档 OCR 与版面解析」,点击「运行此教程」。
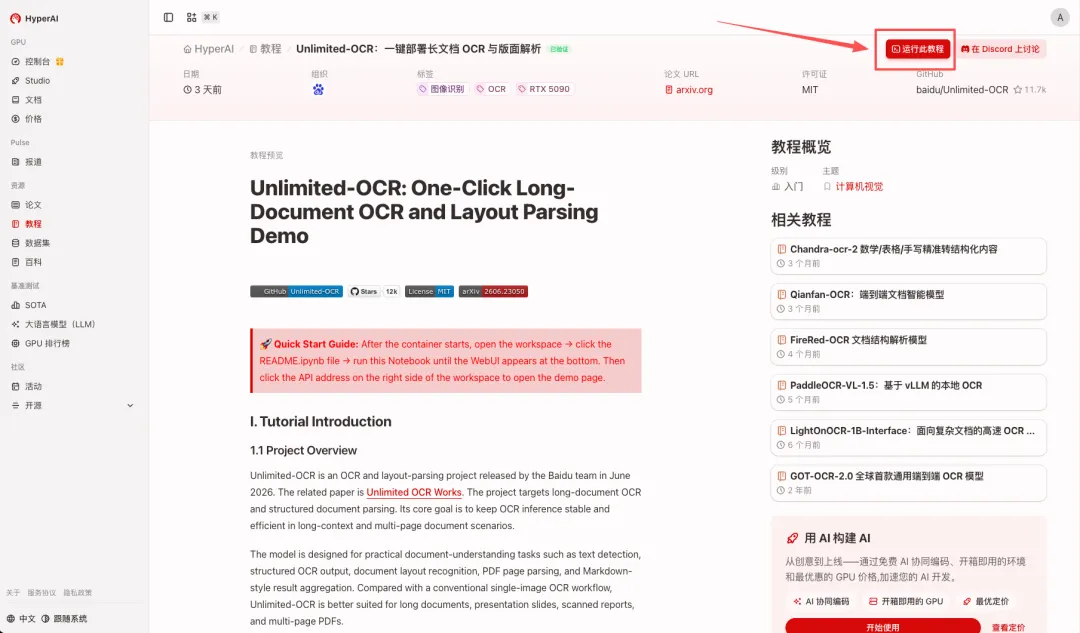
2.页面跳转后,点击右上角「Clone」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
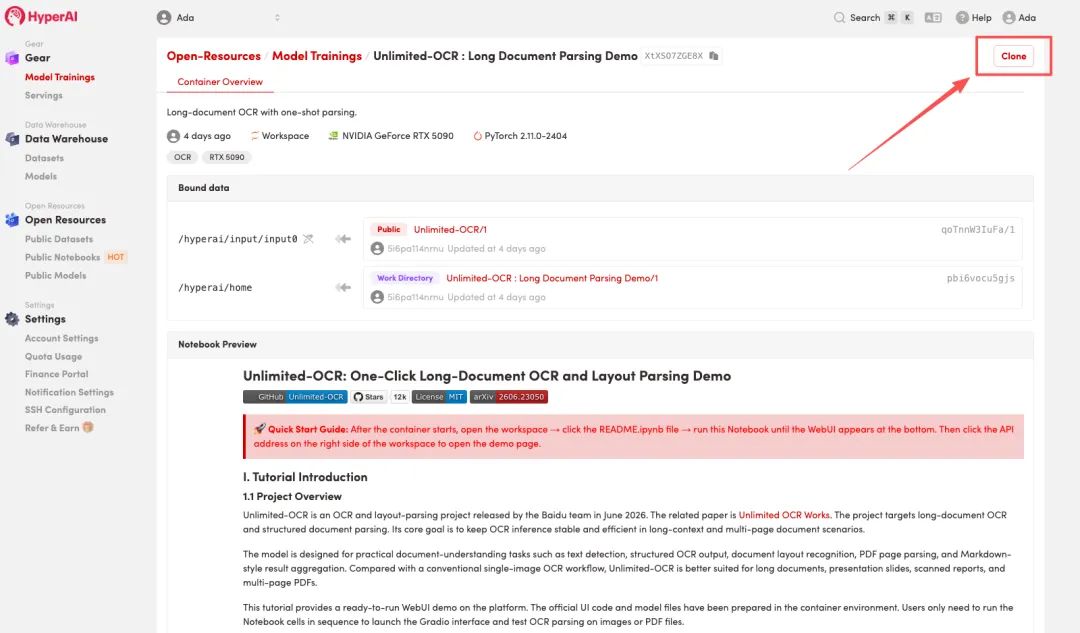
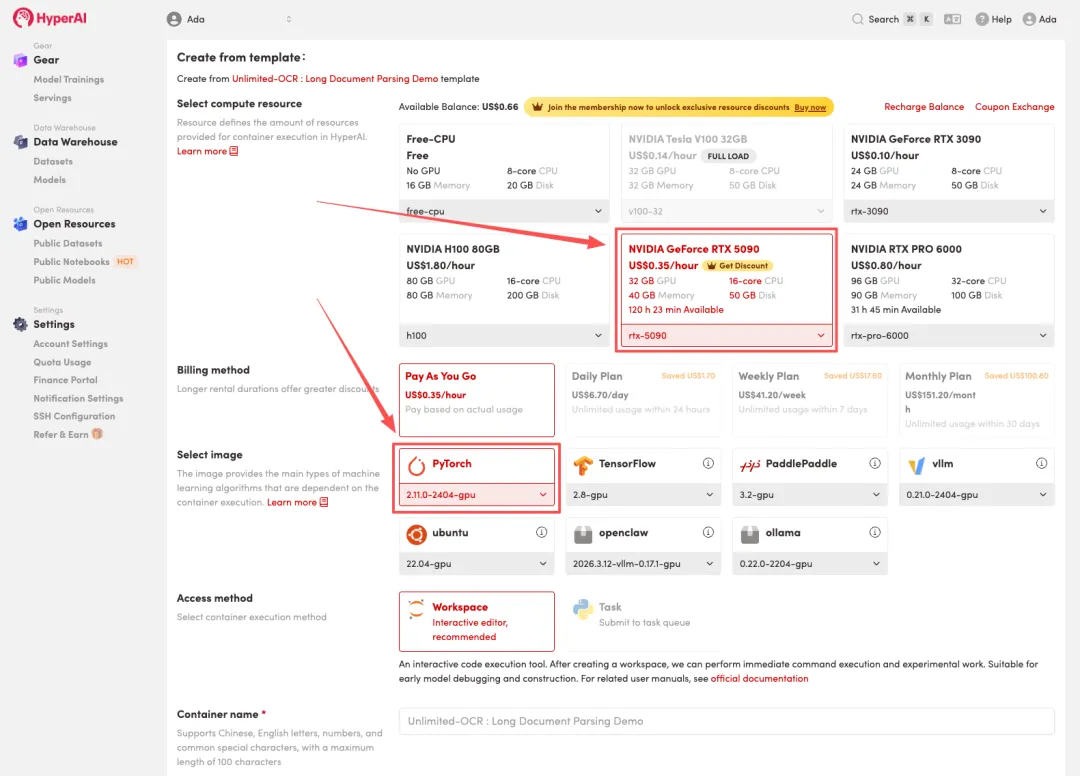
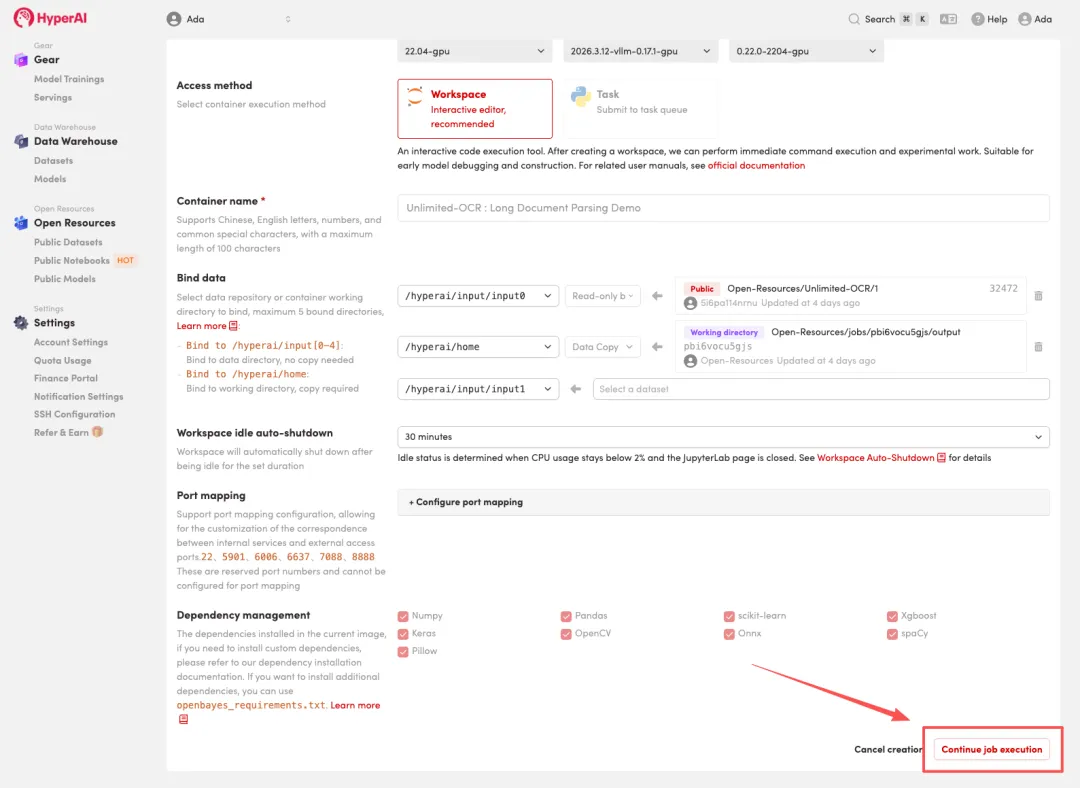
3.选择「NVIDIA RTX 5090」以及「PyTorch」镜像,点击「Continue job execution(继续执行)」。
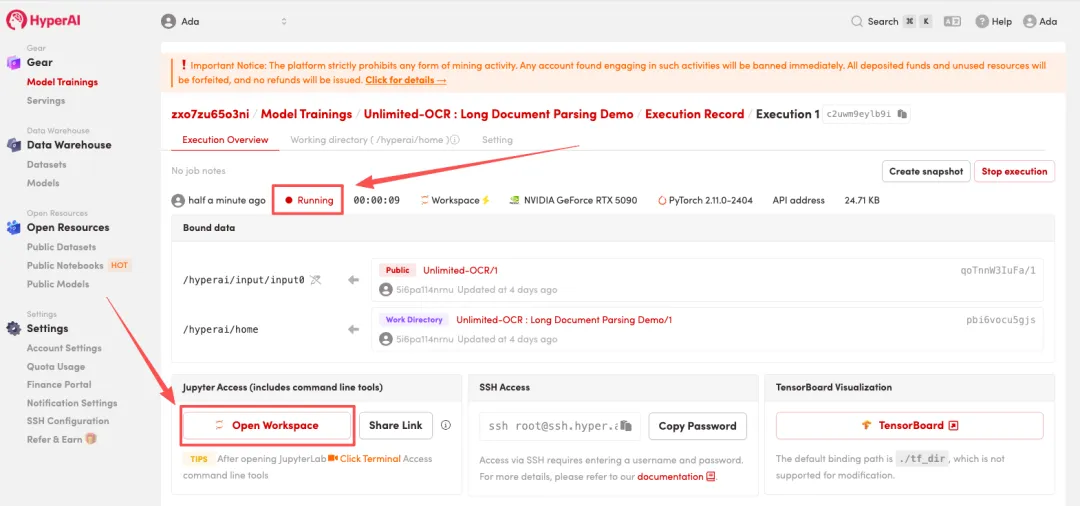
4.等待分配资源,当状态变为「Running(运行中)」后,点击「Open Workspace」进入 Jupyter Workspace。
效果展示
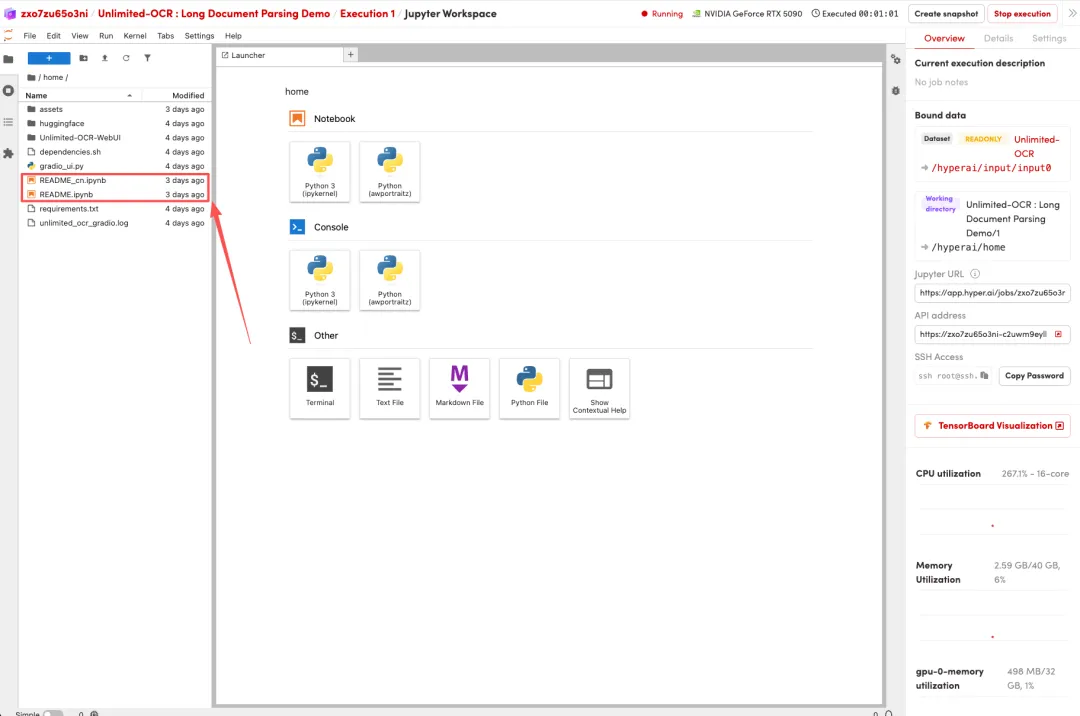
1.页面跳转后,点击左侧 README 文件,进入后点击上方 Run(运行)。
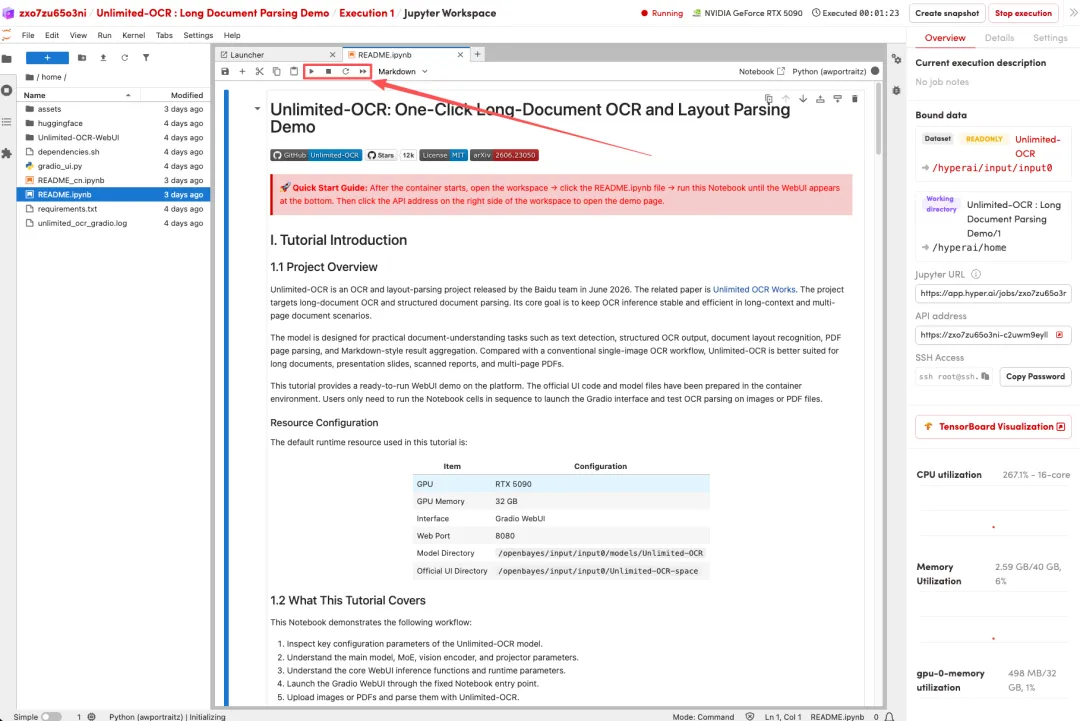
2.待运行完毕后,点击右侧 API 地址即可打开 Demo 界面。
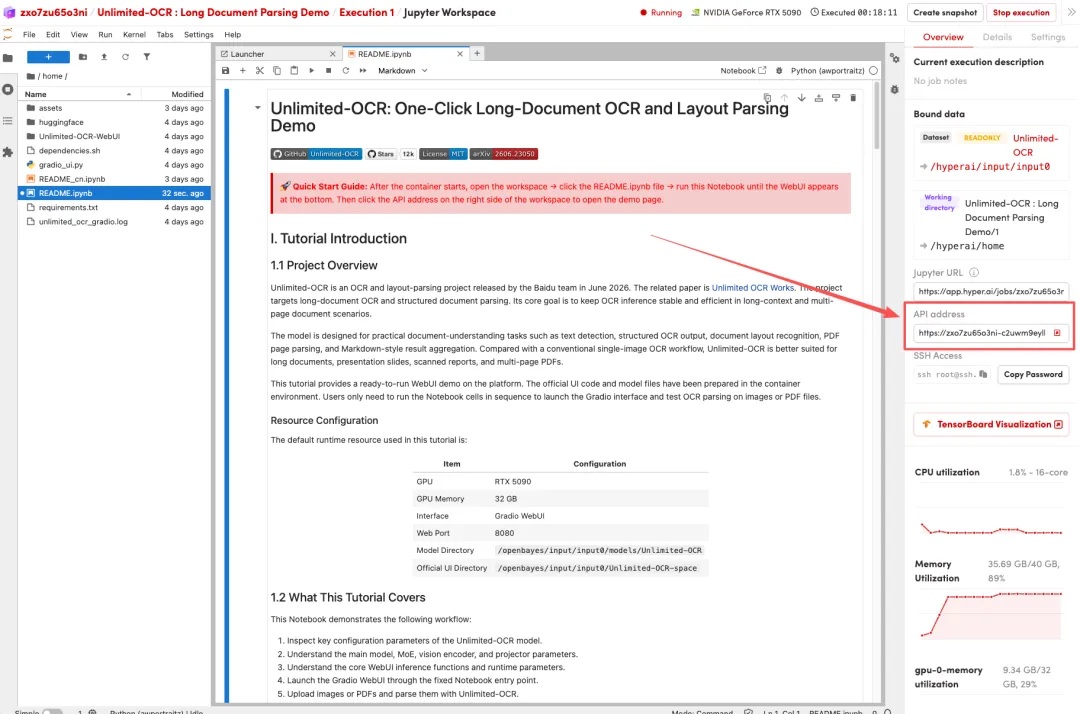
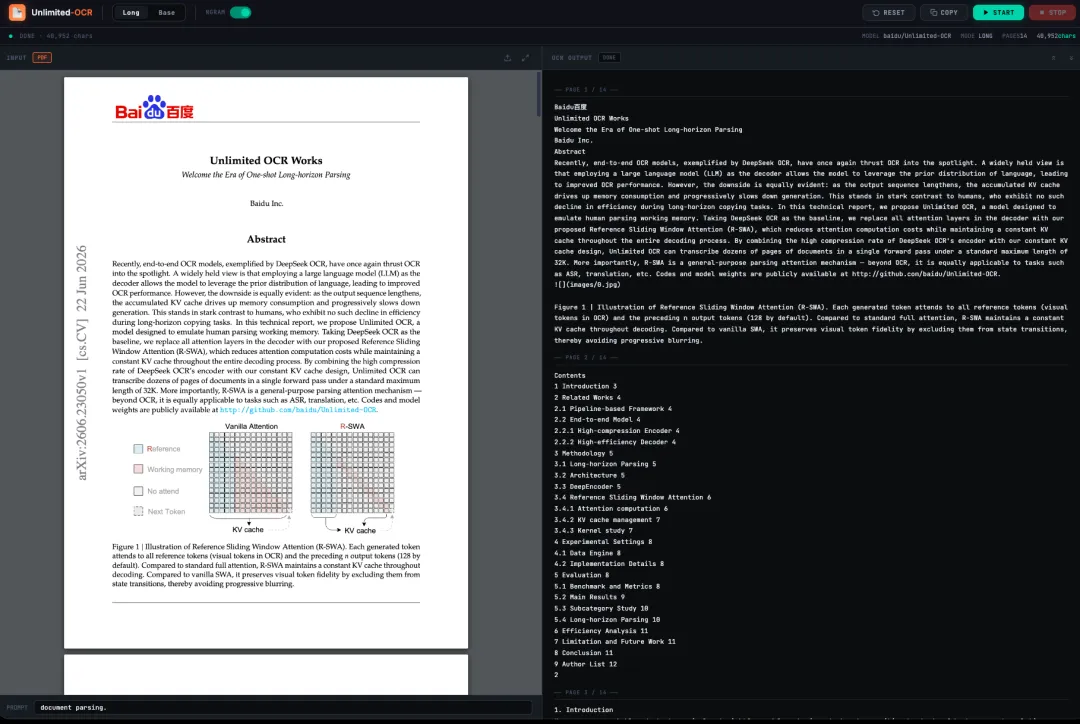
Demo 示例
抽奖赠书

HyperAI超神经联合该书作者韩泽耀为大家带来了赠书福利!我们准备了 15 本超干货技术实战图书「AIGC 与智能体开发实战」,快来参与抽奖吧~
● 参与方式
关注 HyperAI 超神经公众号,并在后台回复「AIGC赠书」,点击抽奖页面参与抽奖,我们共为大家准备了 15 本图书(本次赠书共有 2 个封面版本,书籍内容均一致,随机发货),快递包邮送到您手中,快来参与吧!
● 图书简介AI 时代,如何从零开始掌握大模型应用开发?「AIGC与智能体开发实战」一书专为所有希望进入 AI 领域的开发者量身打造,带你从入门到驾驭 AIGC 智能体开发!
本书以开源大模型为底座,系统讲解了从环境搭建、API 调用到多模态能力编排的关键路径。书中涵盖了文本、图像、语音、视频等智能应用实战,并深入探讨了 Agent 智能体及 RAG 架构。全书结合大量可直接运行的 Python 代码与企业级案例,提供清晰的实战路径,帮助开发者高效上手,实现从「使用者」到「创造者」的转变。
* 点击直接购买↓
往期推荐





戳“阅读原文”,免费获取海量数据集资源!