 夜雨聆风
夜雨聆风





47 页 PDF 里的每个数字,都能一键溯源


你让 AI 帮你从一份 PDF 里提数据。它给你一个整整齐齐的列表:公司名、金额、日期、人物。
看起来挺好。但你敢直接用吗?
“$90 billion”——这个数在原文哪一页?是营收还是利润?你不知道。你只能自己翻回去找。
大多数 AI 提取工具,给你答案,但不给出处。
这就像实习生交了份报告,每个数据都没标来源。你要么逐个核对,要么硬着头皮信他。
 |
如果每条数据都能”点回去”呢?
我们做了一个开源工具,叫 Super Extract。它和其他提取工具最大的区别就一个:
你提取出来的每一条信息,都能精确对应到原文的位置。
不是”大概在第几页”,而是精确到第几个字。
比如你扔给它一份巴菲特 2023 年致股东信(47 页),它会:
1. 读完整份文档
2. 提取所有关键信息——人名、公司、金额、日期、投资原则
3. 把每条信息对齐到原文的精确位置
4. 生成一个可以点击、筛选、跳转的可视化页面
整个过程不到一分钟。
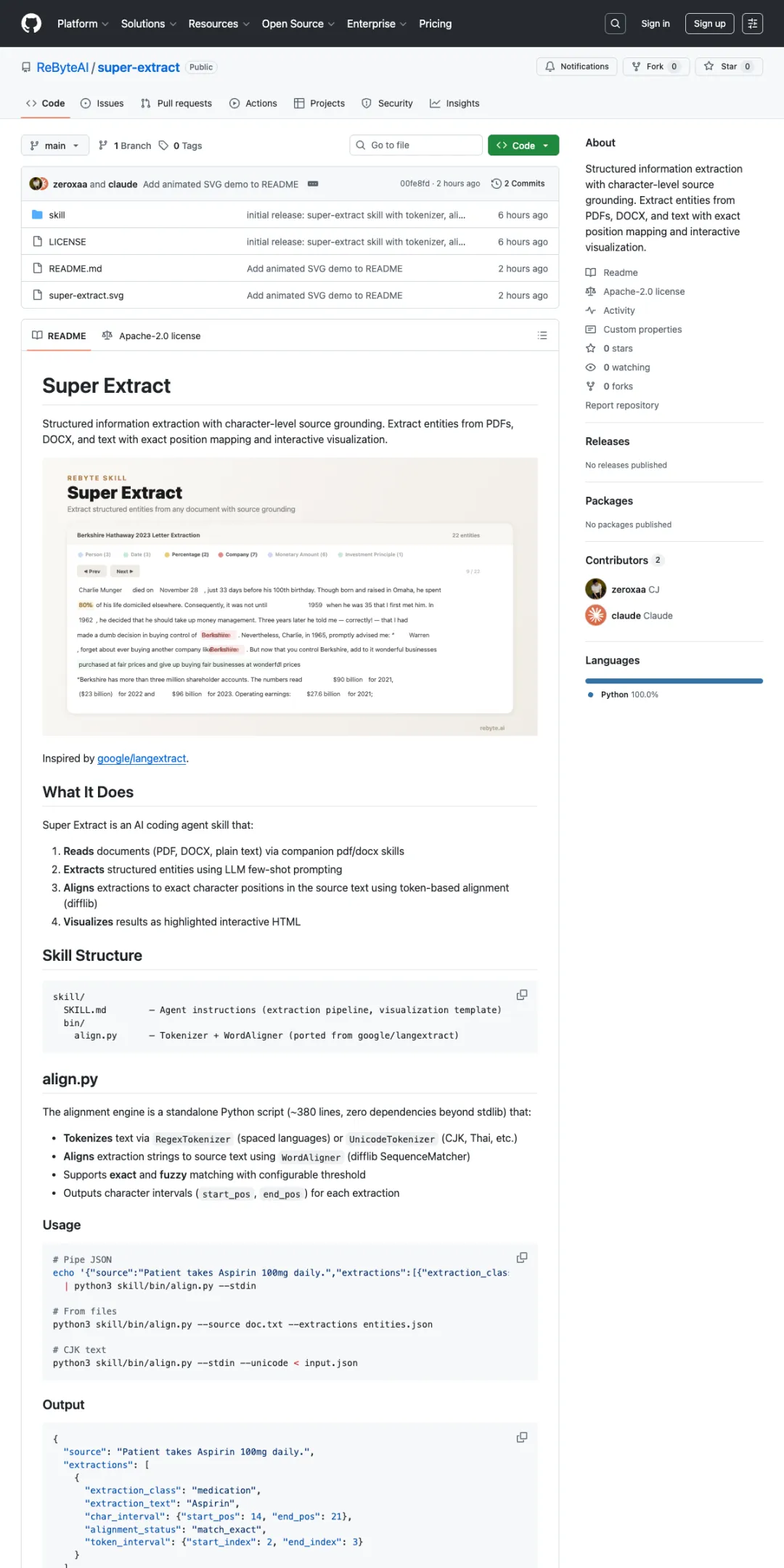
看看实际效果
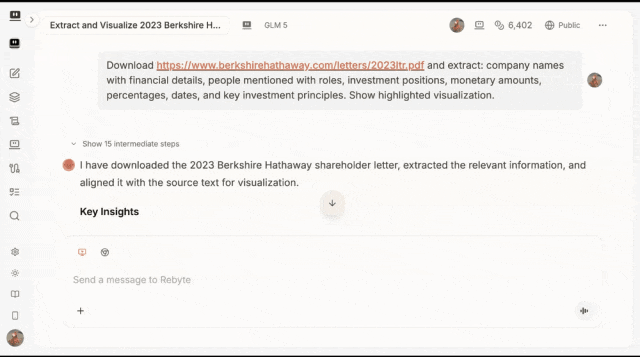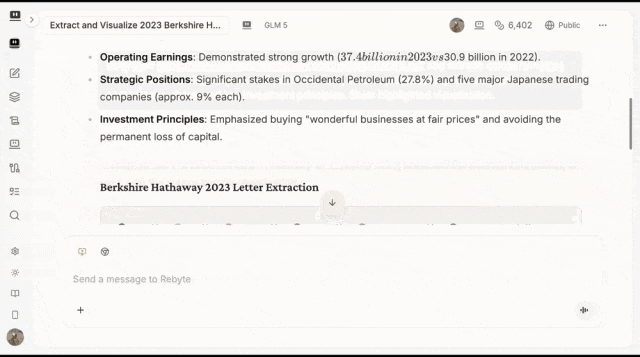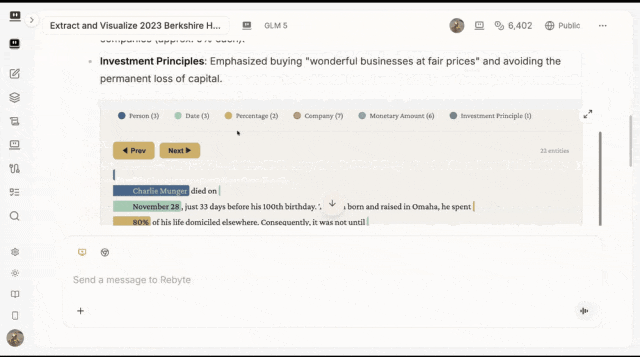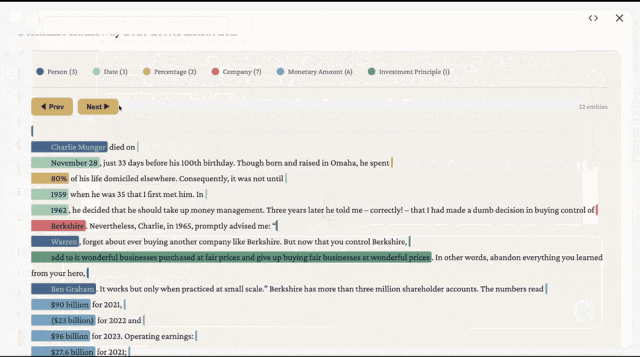
下面是提取后生成的页面。不同颜色代表不同类型:人物、日期、公司、金额。
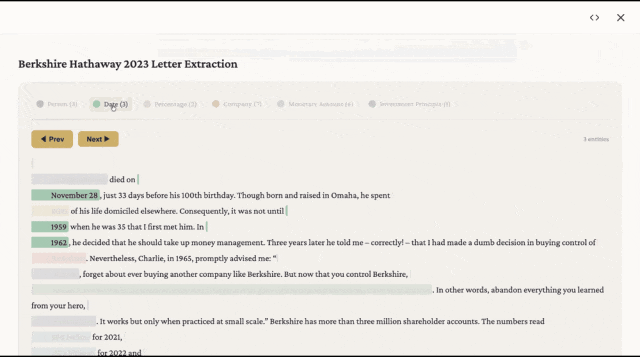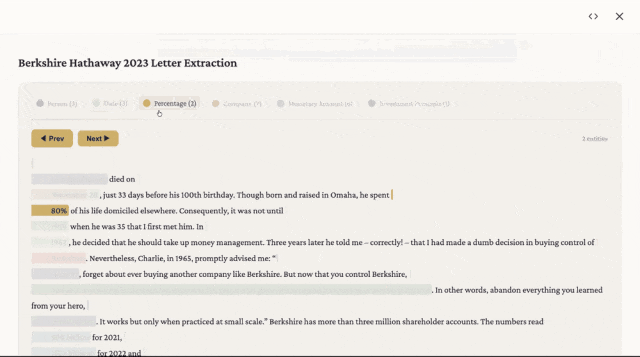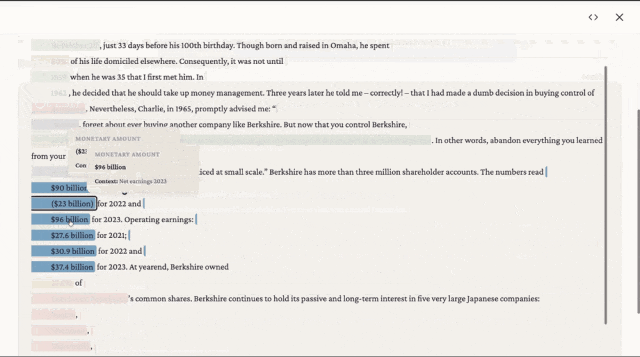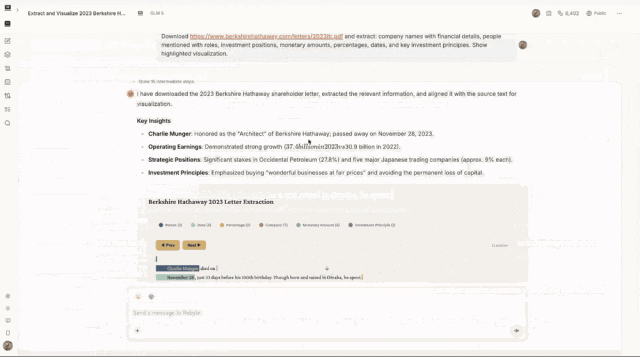
点击任意一条信息,弹窗会告诉你:它是什么类型,在原文的什么上下文里出现。
比如你点 “$96 billion”,它会显示:类型是金额,上下文是”2023年净利润”。不用翻 PDF,不用猜,点一下就能验证。
怎么做到的?
核心就三步:提取 → 对齐 → 可视化。
第一步,AI 读文档,把关键信息提取出来。这一步有个硬性要求:提取出来的文字必须是原文里有的,不允许改写、不允许概括。这就从源头杜绝了”AI 编答案”的问题。
第二步是关键——对齐。一个不到 400 行的脚本,把提取出来的每条信息和原文做精确匹配,定位到它在原文中的起止位置。中文、日文这类没有空格的语言也支持。
第三步,根据定位结果生成交互页面:高亮原文、颜色编码、点击弹详情、前后导航。
| 普通提取工具 | Super Extract |
|---|---|
| 给你一个列表 | 每条信息都标注原文位置 |
| 无法验证来源 | 点击即可跳转原文 |
| 不知道 AI 有没有编 | 对不上的会明确标出 |
| 需要自己翻文档 | 交互式可视化,直接看 |
不只是提取人名和金额
演示用的是财报,但 Super Extract 能提取的东西完全由你决定。
你可以让它从合同里提所有义务条款,从论文里提实验方法和结论,从招股书里提风险因素——只要你能描述想提什么,它就能提取并对齐到原文。
给你的 AI 加一个”标注出处”的能力
Super Extract 已经开源。它是 AI 编程助手的一个 Skill——装上之后,你的 AI 助手就多了一项能力:提取信息的同时,自动标注出处。
不需要配环境,不需要申请账号。AI 本身就是引擎,文档进去,带出处的结构化数据出来。
以前,”AI 说的对不对”只能靠人肉核查。现在,每个答案自己就能证明自己。
仓库地址:github.com/ReByteAI/super-extract
—END—
推荐阅读
点击下方名片 关注我们的公众号
⬇⬇⬇
REBYTE.AI
Agent Computer that works for you

扫码访问 rebyte.ai