 夜雨聆风
夜雨聆风





炸了!Claude Code 记忆系统源码泄露,真相远比想象中精妙!
大家有没有过这种困惑?
用 Claude Code 写代码,它好像能“记住”你的习惯——你说过集成测试不能用 Mock,它再也不会踩坑;你提过项目截止日期,它会主动提醒;甚至你是后端转前端,它都能适配你的技术偏好。
它到底是怎么做到的?难道真的在偷偷“记笔记”?
就在昨天,@himanshustwts 曝光了 Claude Code 记忆系统的核心源码,彻底揭开了这个秘密。不同于市面上大多数“全盘存储”的粗糙设计,Claude Code 的记忆系统,竟然藏着五层架构、三重管控,细节拉满到让人惊叹!
今天就带大家逐字拆解这份泄露源码,看懂 Claude Code 记忆系统的底层逻辑——看完你会发现,它的“聪明”,全是靠严谨的设计堆出来的。
为什么记忆,是A 编程助手的“灵魂”?
很多人觉得,AI 的记忆不就是“存下对话记录”吗?其实不然。
对于 Claude Code 这类编程 Agent 来说,记忆是它的“身份标识”,更是它提升效率的核心。就像我们写代码需要记笔记、存文档,AI 也需要通过记忆,记住你的偏好、项目的细节、外部工具的关联,才能真正做到“懂你”。
而 Claude Code 的厉害之处在于:它不盲目存储,不冗余堆积,而是用一套极其规整的体系,把“该记的”记牢,“没用的”剔除,甚至还会自己“整理记忆”——这也是它比其他编程 AI 更顺手的关键原因。
Claude Code 五层记忆架构
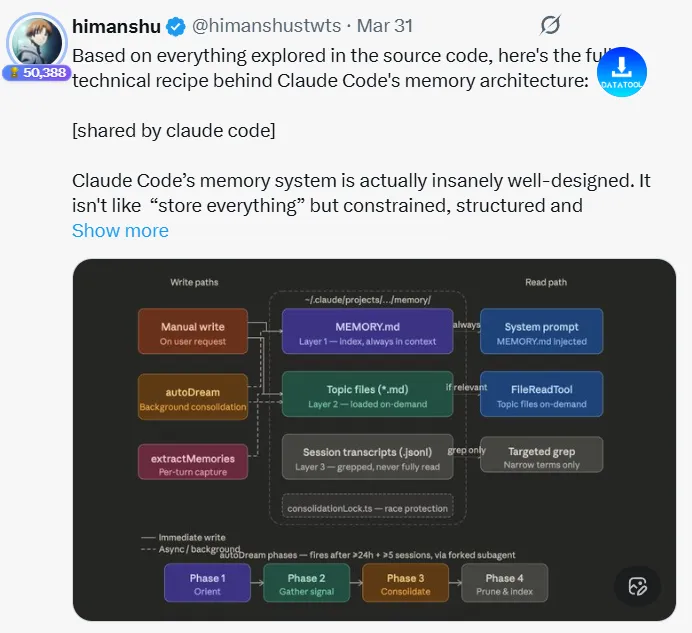
源码显示,Claude Code 根本没有“单一记忆”,而是搭建了五层独立记忆体系,每层各司其职,成本、用途、服务对象完全不同。其中,有两层是我们日常能接触到的,另外三层则藏在后台,默默发力。
1. 对话历史(零成本基础记忆)
这是最基础、最常见的一层,大家都很熟悉——它以 JSONL 格式,记录了你和 Claude Code 的所有对话,包括你的提问、它的回复。
关键细节(源码重点):
-
• 单个项目最多存 100 条记录,避免冗余; -
• 大段粘贴的代码、文本,会被哈希处理后单独存储,保证日志精简; -
• 支持用 /export指令直接导出,方便备份; -
• 使用成本:零成本,完全不占用额外资源。
2. 会话记忆(后台静默压缩,未正式上线)
这是一个“隐藏功能”,源码里标注为 Session memory,目前被一个神秘开关 tengu_session_memory 控制,暂未确认是否对外开放。
它的核心作用的是“压缩上下文”:常规情况下,当对话内容填满 85% 的上下文窗口时,才会触发摘要压缩;而会话记忆,会由后台 Agent 实时构建、更新,实现“边对话、边压缩”,避免上下文溢出。
3. CLAUDE.md(人工可控的“规矩手册”)
这是开发者最熟悉的一层记忆,也是唯一由我们人工管控的部分。
你可以在 CLAUDE.md 里写任何你想让 Claude Code 记住的“规矩”:编码风格、测试规范、项目禁忌、个人偏好……只要放在项目目录里,启动会话时,Claude 会自动加载所有 CLAUDE.md 文件,甚至会遍历多级文件夹,读取所有配置。
简单说,这就是你给 Claude Code 定的“家规”,它会严格遵守,不会出错。
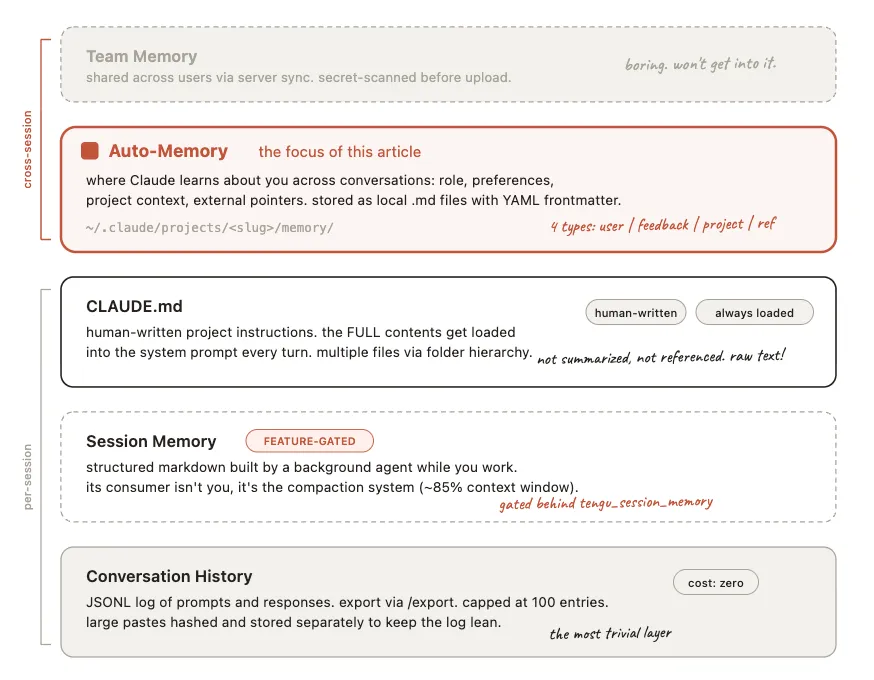
4. 自动记忆(Auto-memory,核心中的核心)
这才是 Claude Code “懂你”的关键——也是我们今天重点拆解的部分。
Auto-memory 会跨多轮对话,主动学习你的信息:你是后端工程师还是前端?熟悉 Python 还是 Java?项目的截止日期是什么时候?缺陷跟踪用 Linear 还是其他工具?
所有这些信息,都会被存在本地目录 ~/.claude/projects/<slug>/memory/ 里,全程可见、可编辑,不用担心隐私泄露。
5. 团队记忆(协作专用,略过不展开)
主要用于团队协作场景,逻辑比较常规,源码里也没有太多复杂设计,这里就不详细拆解了,重点放在我们最常用的 Auto-memory 上。
深扒 Auto-memory:Claude 是怎么“记东西”的
很多人以为,AI 记东西就是“随手追加”,但 Claude Code 完全不一样——它的 Auto-memory 有严格的“写入-整合-删除”流程,全程三个阶段,丝毫不乱。
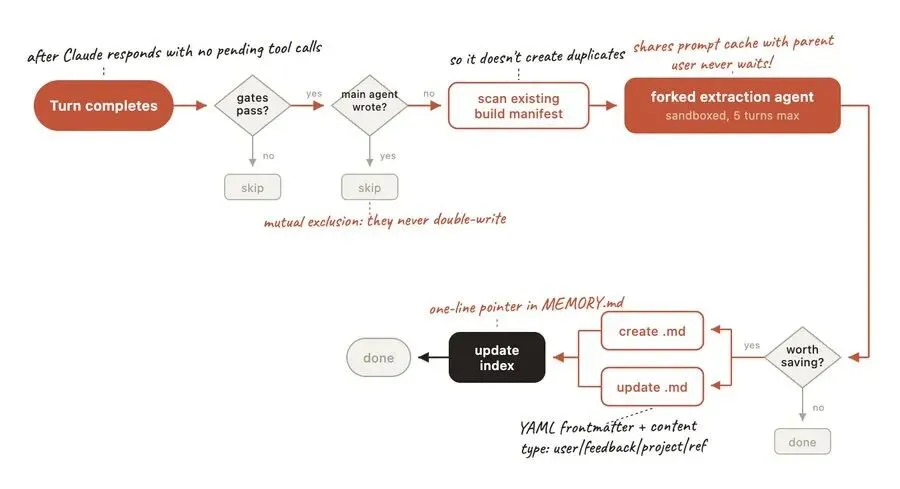
第一阶段:逐轮提取(不重复、不冗余)
每当你和 Claude Code 完成一轮对话,后台会启动一个“分支子 Agent”,扫描最新的 N 条消息,筛选出值得记住的关键信息——比如你说的“集成测试不用 Mock”“权限重构截止到 2026-04-15”。
关键设计(避免冗余):
-
• 提取前,会先读取所有历史记忆,避免创建重复文件; -
• 每条记忆会生成一个独立的 Markdown 文件,同时在 MEMORY.md里记录索引,方便后续查找; -
• 记忆被分为 4 种固定类型,标签化管理,不会混乱。
给大家看一段源码里的真实示例,一看就懂:
MEMORY.md(记忆索引,相当于“目录”)
- [User Profile](user_profile.md) — 后端工程师,5 years Python,new to this repo's React frontend- [Testing Policy](feedback_testing.md) — never mock the database in integration tests- [Auth Rewrite](project_auth_rewrite.md) — driven by compliance, not tech debt, deadline 2026-04-15- [Bug Tracker](reference_linear.md) — pipeline bugs tracked in Linear project INGESTfeedback_testing.md(单条记忆文件)
---name: Testing policydescription: Integration tests must use real database connections, never mockstype: feedback---四种记忆类型(源码固定,不可修改):
-
• user:你的身份、技术栈、偏好(比如“后端工程师,5年Python经验”); -
• feedback:你给 Claude 定的规则(比如“集成测试不用 Mock”); -
• project:项目细节(代码、Git 记不住的工期、决策、动机); -
• reference:外部工具指引(比如“缺陷跟踪用 Linear”)。
还有一个细节特别贴心:这个分支子 Agent 是“ sandbox 沙箱隔离”的——只能读取本地文件,只能写入记忆目录,不能调用其他工具,也不能执行危险指令,避免误操作。而且它会共享主对话的缓存,不会拖慢响应速度,你完全感觉不到它在后台工作。
第二阶段:定期整合(AutoDream,自动“整理记忆”)
如果只提取不整理,记忆文件会越来越乱,甚至出现矛盾——比如你后来修改了测试规范,旧的记忆还在,就会导致 Claude 出错。
源码里有一个叫 autoDream 的后台进程,专门解决这个问题,它会在两个条件满足时自动启动:
-
• 距离上次整合满 24 小时; -
• 累计新增 5 次会话。
启动后,它会做四件事,相当于“给记忆做大扫除”:
-
1. 读取 MEMORY.md索引,浏览所有记忆文件; -
2. 检索近期对话日志,提取新的关键信息; -
3. 合并新信息到旧文件,把“昨天”“明天”这类相对时间,改成绝对日期(比如“2026-04-15”),删除和当前代码冲突的内容; -
4. 精简记忆:删除过期链接、缩短冗长描述,解决文件间的矛盾(源码提示词明确:“如果两个文件 disagree,fix the wrong one”)。
第三阶段:记忆删除(不自动清理,杜绝误删)
最让人放心的一点:Claude Code 不会自动删除任何记忆,也没有过期机制。
只有一种情况会删除记忆:后台 Agent 主动判断,这条记忆已经过时、和当前项目冲突,或者没有任何价值——简单说,记忆只会“被优化”,不会“被静默删除”,不用担心辛苦设置的规则突然消失。
Claude 会“筛选记忆”,不浪费上下文
很多 AI 会把所有记忆都加载到上下文,导致上下文溢出、响应变慢,但 Claude Code 不会——它有一套极其高效的“记忆调取逻辑”,只加载有用的,杜绝冗余。
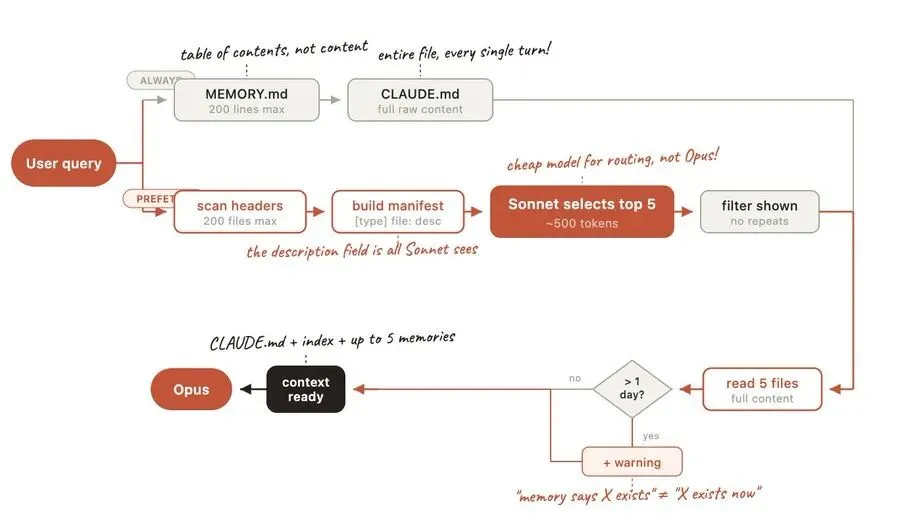
源码揭秘调取流程,全程不浪费一丝资源:
-
1. 第一步: MEMORY.md索引(最多 200 行、25KB)会常驻系统提示词,但单个记忆文件不会; -
2. 第二步:不管你用的是 Opus 还是其他模型,调取记忆时,都会切换到更轻量化的 Sonnet 模型,做“相关性筛选”(更快、更省资源); -
3. 第三步:Sonnet 会扫描所有记忆文件的头部说明,生成清单,结合你的提问,筛选出最相关的 5 个文件; -
4. 第四步:只把这 5 个文件加载到上下文,多余的一律不加载。
而且有两个特别贴心的设计:
-
• 老旧记忆会加“预警”:超过 1 天的记忆,加载时会自动提示“本条记忆距今XX天,可能已过时,务必核对当前代码”,避免你踩坑; -
• 不重复加载:已经在之前对话中展示过的记忆,会自动排除,把 5 个名额留给新的关键信息。
防止恶意攻击,保护本地文件
源码里还有一个容易被忽略,但特别重要的点——记忆路径的安全防护。
虽然你可以通过 autoMemoryDirectory 自定义记忆存储目录,但有一个严格限制:只能在全局配置 ~/.claude/settings.json 里修改,不能在项目本地配置。
原因很简单:防止恶意仓库篡改路径,把记忆目录指向 ~/.ssh 等敏感文件夹,导致隐私泄露。同时,系统会自动拦截路径穿越攻击(比如 .. 跳转),加上沙箱隔离,双重保障安全。
核心总结
看完这份泄露的源码,最大的感受是:Claude Code 的记忆系统,赢在“克制”和“严谨”。
它没有靠 Opus 模型的强大算力“野蛮生长”,而是给记忆系统套上了层层约束:
-
• 格式强制标准化,不任由模型自由发挥; -
• 调取用轻量化模型筛选,不浪费资源; -
• 删除需人工+Agent 双重判定,不静默误删; -
• 沙箱隔离+路径防护,杜绝安全风险。
这也解释了为什么很多人觉得 Claude Code 比其他编程 AI 更“顺手”——它的“懂你”,不是靠运气,而是靠一套极其规整、细节拉满的记忆体系。
最后想问大家:你用 Claude Code 时,有没有发现它“记住”你的小习惯?欢迎在评论区留言,聊聊你和 Claude Code 的使用体验~