 夜雨聆风
夜雨聆风





AI模型可剪掉90%参数而不损失精度
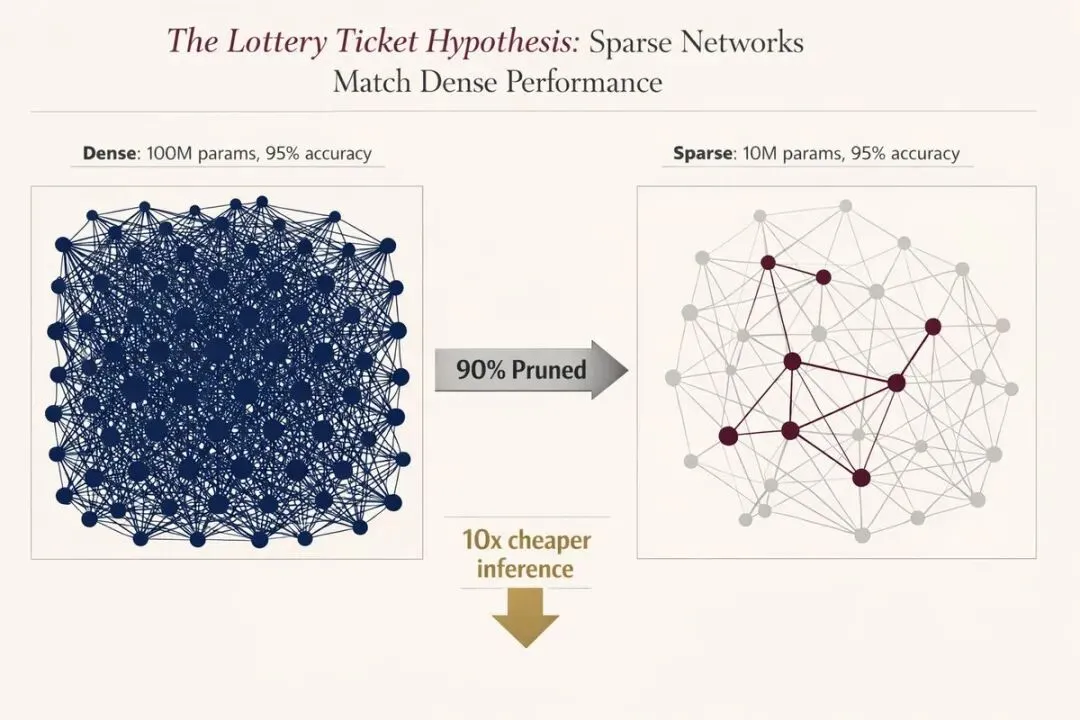
2018年,MIT的研究人员证明,每个大型神经网络内部都藏着一个“中奖彩票”——一个只需原始模型10%参数量就能达到相同性能的稀疏子网络。但当时存在一个致命缺陷:你必须先训练大模型才能找到这张“彩票”。八年后,硬件与算法的双重突破终于让这一理论走向生产实践。
🎫 彩票假说:每个大模型里都藏着一个“冠军”
MIT团队在2018年提出的彩票假说(Lottery Ticket Hypothesis)揭示了一个反直觉的事实:
一个随机初始化的密集神经网络包含一个子网络(“中奖彩票”),当独立训练时,该子网络能够在相同迭代次数内达到与原始网络相当的准确率。
图中的数据清晰地展示了这一潜力:
-
密集模型:1亿参数,95%准确率 -
稀疏模型:1000万参数,95%准确率 -
剪枝比例:90% -
推理成本:仅为原来的1/10
❌ 致命的“先有鸡还是蛋”问题
然而,彩票假说在提出后的数年内未能广泛落地,原因是一个根本性的工程障碍:
你必须先完整训练一个巨大的模型,才能找到“中奖彩票”,然后用原始初始化权重重新训练这个稀疏子网络。
这意味着:
-
训练大模型(昂贵) -
找到中奖彩票(剪枝) -
重新训练稀疏子网络(再次昂贵)
没有人愿意为了部署一个模型而训练两次。彩票假说因此被束之高阁——“一个很酷的学术展示,但在生产中毫无用处”。
🚀 八年后:硬件突破让理论照进现实
2026年,局面发生了根本性变化。结构化稀疏(Structured Sparsity)在硬件层面实现了突破。
现代GPU的原生稀疏支持
从NVIDIA Ampere架构开始,GPU不再仅仅是“模拟”剪枝,而是在硬件层面原生支持块稀疏(如2:4稀疏模式):
-
2:4稀疏:每4个连续的权重值中,有2个被强制为零 -
硬件原生加速:无需模拟,直接跳过零权重的计算
惊人的性能收益
对于一个90%稀疏的网络:
|
|
|
|---|---|
| 内存带宽 |
|
| 计算吞吐量 |
|
| 准确率损失 | 0% |
🛠️ 2026年:三股力量推动稀疏模型走向生产
-
剪枝感知训练:从第一天起就训练稀疏模型,不再需要“训练两次” -
框架原生支持:PyTorch 2.0 和 Apple Neural Engine 已原生支持结构化稀疏 -
设计冗余的认知:学界意识到,AI模型本质上是过度参数化的——90%的权重是冗余的,可以被安全移除
📌 结语
进化为一切事物过度参数化。我们终于学会了如何剪枝。
臃肿、低效的AI模型时代正在终结。工具终于追赶上了理论。未来的赢家将是那些不再为90%根本不需要的权重买单的人。
AI的未来是更小、更快、更智能。
