 夜雨聆风
夜雨聆风





用 OpenClaw + Obsidian + QMD 搭一套真正会积累的记忆系统
适合超级个体、个人创业者和中小企业老板的一套本地化 AI 第二大脑方案

你有没有发现,你的龙虾总是“失忆”?
今天你跟它聊了很多,明天你再问它,它又好像第一次见你一样。
我跟它聊过什么?我有哪些偏好?我曾经有过哪些判断?我有哪些观点?
我保存过什么资料?
它经常接不上。
最开始的时候,我也以为是不是自己缺了一个什么记忆插件。是不是换个模型就好了?是不是装一个记忆工具,AI就能记住我的很多内容?
后来我发现,不是这么回事。
问题不在于AI是不是聪明,真正的问题在于:我有没有一套自己的AI记忆系统。
其实很多人对AI都有误解。以为自己会提问就够了,以为会写Prompt就可以了,以为用了一个更好的模型就可以了。
其实这些都还不够。
真正重要的是,让AI、让龙虾能够记住我们跟它聊过的内容,并且把这些内容变成我们的资产。
这才是最重要的。
这也是为什么我会选择 OpenClaw + Obsidian + 本地知识库 + QMD。 这套组合解决的不是“再多一个 AI 工具”,而是把 AI 从一次性对话,升级成一个可以长期积累的生产系统:OpenClaw 负责执行与调用,Obsidian 负责承载 Markdown 资产,本地 KnowledgeVault 负责沉淀知识,QMD 负责统一检索。
一句话说透:这套系统的价值,不是让 AI 更会聊天,而是让它开始真正替你“记住、找回、复用”。
一、这套系统为什么值得搭
先说结论:值得,而且越早搭,复利越大。
对超级个体、创业者和小团队来说,未来最稀缺的不是信息,而是你自己的长期上下文、自己的知识资产、自己的决策与执行历史。只要这些东西还散落在微信、飞书、浏览器书签和聊天窗口里,你就永远没有真正意义上的“AI 资产”。你只有一堆碎片,没有系统。
这套架构最核心的价值有四个。
-
信息不丢。灵感、洞察、项目动态、长期偏好,都不再只存在会话里,而是会写进文件。
-
知识可复用。内容不是留在一个聊天窗口里,而是进入你自己的 Markdown 知识库。
-
检索可调用。下次提问,AI 不是再听你重讲一遍,而是先从历史沉淀里把相关内容打捞回来。
-
系统可扩展。今天它服务内容创作,明天可以扩展到项目管理、销售 SOP、研究归档、客户洞察。
你如果只是偶尔和 AI 聊两句,这套系统对你太重;但如果你希望 AI 逐步变成你的外脑、研究员和执行助手,这套系统几乎是必修课。
真正有商业价值的,不是“问一次,回一次”的单轮 AI,而是能形成长期记忆、长期检索、长期复用的系统。
二、安装路径:把 OpenClaw、Obsidian、本地KnowledgeVault 和 QMD 接成一套系统
下面这部分,直接按步骤走就行。本文以 Mac 为例,目标是搭出一套可运行、可检索、可沉淀的本地记忆系统。
第 1 步:先把底座搭起来——OpenClaw + Obsidian + Workspace
先装好两个基础软件:
-
OpenClaw
-
Obsidian
然后在 Mac 的“文稿”目录下建立你的工作区,例如:
~/Documents/OpenClaw-Workspace
这个目录,后面会成为整个系统的核心文件夹。你的 OpenClaw 记忆、知识库、skills、配置规则,都会围绕它展开。
建议目录结构至少长这样:
OpenClaw-Workspace/├── AGENTS.md├── MEMORY.md├── memory/├── KnowledgeVault/├── skills/└── 其他你的工作文件
这里面几层含义一定要分清:
-
AGENTS.md:行为规则、工作原则、检索规则
-
MEMORY.md:长期偏好、稳定约束、长期决策
-
memory/:过程记录、临时上下文、项目动态
-
KnowledgeVault/:真正的知识资产库
-
skills/:能力扩展
(不知道怎么写的,可以私我,我把我整理好的发你)
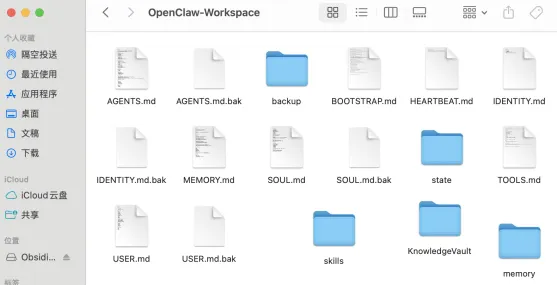
工作区中已有 AGENTS.md、MEMORY.md、KnowledgeVault、memory、skills 等核心结构。
第 2 步:把 Obsidian 指向这个 Workspace
接下来,不要再单独新建一个乱七八糟的 Obsidian 仓库。直接让 Obsidian 打开 OpenClaw-Workspace。
这样做的好处是:
-
OpenClaw 写入的文件,你在 Obsidian 里能直接看到
-
Obsidian 里整理过的内容,OpenClaw 也能继续调用
-
你不会出现“AI 一套文件,我自己又一套文件”的割裂
本质上,Obsidian 在这里不是“AI 工具”,而是你本地 Markdown 知识资产的可视化前端。
第 3 步:把知识沉淀目录建好
在 OpenClaw-Workspace 里建立 KnowledgeVault,然后按你的需求继续细分。比如:
KnowledgeVault/├── 00-inbox/├── 01-articles/├── 02-ideas/├── 03-insights/├── 04-projects/└── 05-assets/
最重要的不是目录有多花,而是你要建立一个原则:
通用知识、灵感、洞察、文章归档、项目资料,优先进入 KnowledgeVault/。
不要把所有东西都塞进 MEMORY.md。MEMORY.md 不是垃圾桶,它只该存真正稳定、长期有效的信息。
第 4 步:先把 OpenClaw 的“写入能力”打通
如果你已经写了一个 skill,能让 OpenClaw 直接写入 KnowledgeVault,那这一层就已经非常有价值了。因为这意味着:以后你在飞书或终端里,不只是“聊过”,而是能直接落盘成文件。
这是这套系统的核心分水岭:
-
没写下来的内容,只是聊天
-
写进文件的内容,才是资产
所以这套系统的第一原则不是“记住”,而是:
不要依赖“记住”,要依赖“写下”。
如何不会写这个skill,私我我发你SKILL.md。
第 5 步:安装 QMD,让 OpenClaw 真正“会找”
到这里,OpenClaw 能写,Obsidian 能看,KnowledgeVault 能存。但还有一个关键问题:
它能不能高效地把历史内容找回来?
这时候就需要 QMD。
QMD 不是新的知识库。它的作用是:把 OpenClaw 的 memory 和你的 KnowledgeVault 一起建索引,统一检索。
5.1 安装 sqlite
打开终端,先执行:
brew install sqlite
如果中间看到一两行红字,不要慌。重点看最后结果是不是:sqlite … is already installed and up-to-date 或者安装完成并返回命令提示符,那就说明这一步成功了。
5.2 安装 QMD
继续执行:
npm install -g @tobilu/qmd
如果出现类似 npm warn deprecated … 也不用慌。只要没有 ERR!,并且最后出现 added xxx packages in xxs 就说明安装成功了。
5.3 验证 QMD 是否可用
执行:
which qmdqmd –help
如果 which qmd 能输出路径,qmd –help 能打印一大段帮助信息,说明 QMD 已经可用。
第 6 步:让 OpenClaw 切到 QMD
QMD 装好后,还要让 OpenClaw 真正使用它。执行这三行:
openclaw config set memory.backend qmdopenclaw config set env.shellEnv.enabled true –strict-jsonopenclaw gateway restart
这三行分别干了三件事:把记忆后端切到 QMD;让 OpenClaw 能读到 shell 里的 qmd 命令;重启 gateway,让配置生效。
如果重启后出现:Restarted LaunchAgent: gui/… 就说明接入成功。
第 7 步:把 KnowledgeVault 接进 QMD 索引
这是最关键的一步。因为你真正想检索的,不只是 OpenClaw 自己的 MEMORY.md,更是你沉淀在 KnowledgeVault 里的内容。
假设你的路径是:~/Documents/OpenClaw-Workspace/KnowledgeVault
执行:
openclaw config set memory.qmd.paths ‘[{“name”:”knowledge-vault”,”path”:”‘”$HOME”‘/Documents/OpenClaw-Workspace/KnowledgeVault”,”pattern”:”**/*.md”}]’ –strict-jsonopenclaw gateway restart
这一步的意思是:明确告诉 QMD:去索引这个目录里的 Markdown 文件。也就是从现在开始,KnowledgeVault 里的内容,不再只是躺在硬盘里,而是会变成 OpenClaw 可检索、可召回、可回答的知识来源。
第 8 步:首次索引,别着急
执行:
openclaw memory status –deep –index –verbose
第一次跑的时候,可能会显示:Updating QMD index… 0% 这很正常。说明它正在做首次索引。文件少,几分钟。文件多,十几分钟也正常。第一次慢,不代表出错。
如果最后出现类似:Indexed: … files, Dirty: no, Workspace: ~/Documents/OpenClaw-Workspace 就说明索引已经建起来了。
第 9 步:做真实搜索测试
不要只看“状态正常”。真正关键的是:搜不搜得到。
比如直接测一个你知识库里明确存在的词:
openclaw memory search “财富分配”
如果输出里命中了类似:KnowledgeVault/03-insights/xxxxxx.md 并且还能显示文件头部内容,那就说明整条链路已经通了。
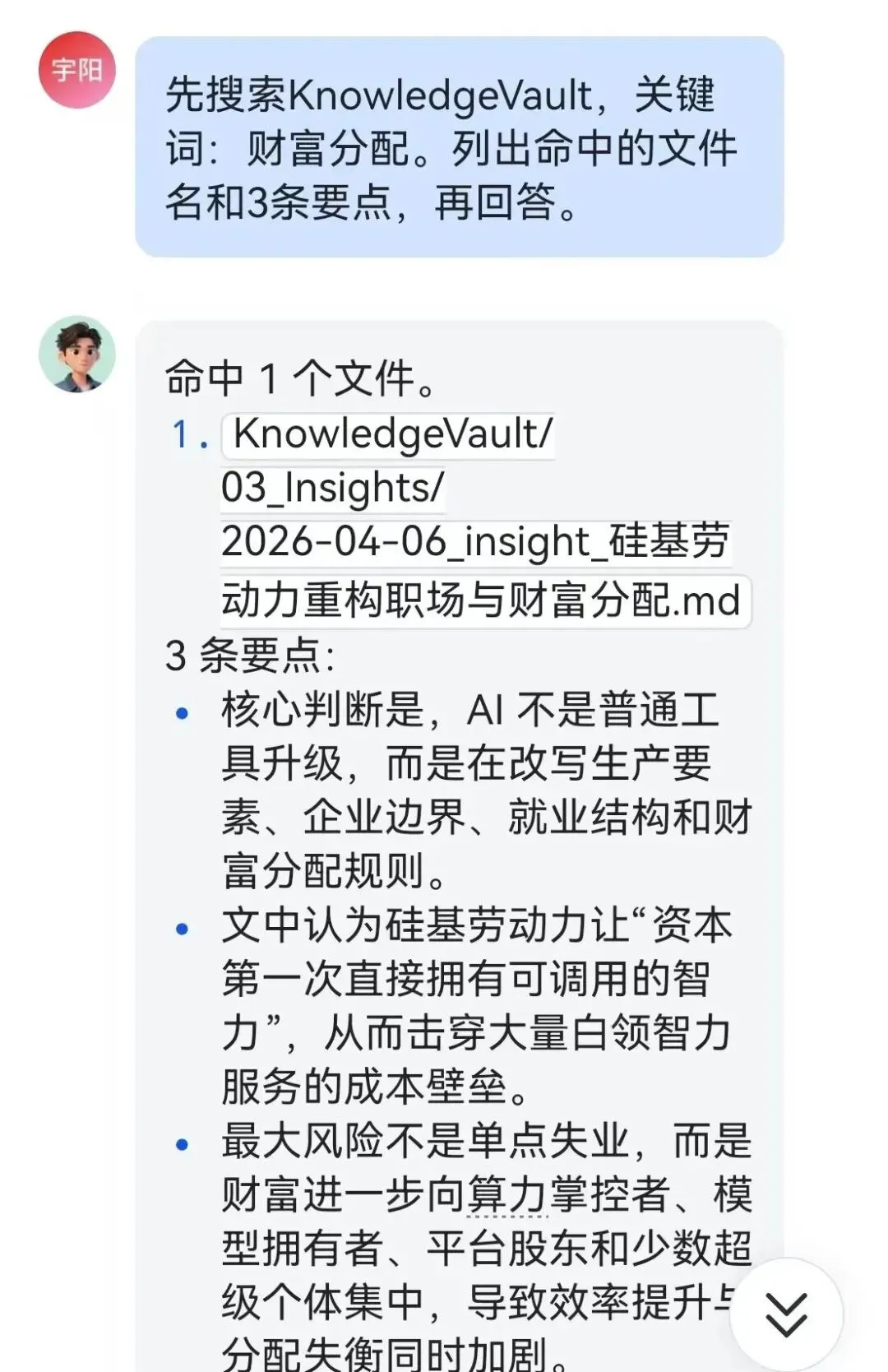
第 10 步:解决一个常见坑——“终端能搜到,聊天却说没有”
这是很多人搭完之后最容易懵的一步。你在终端里明明能搜到,但在飞书里问:“我知识库里以前记过哪些关于财富分配的内容?”它却回你:“没有检到知识库里有明确提过……”
这不代表系统坏了。而是说明:检索层是通的,但行为层没有稳定形成“先搜再答”的习惯。
怎么解?最简单的方法不是继续折腾 QMD,而是把规则写进 AGENTS.md。建议加一句最简版:
提到“知识库”时,先搜 `KnowledgeVault`,再回答。未检索前,不要直接说“没有”。
这句话看起来很小,但非常关键。它解决的不是“搜哪里”,而是“先不先搜”。因为很多 AI 系统的问题,从来不是“没有能力”,而是没有形成稳定行为规则。
第 11 步:验证聊天侧是否真正打通
加完规则之后,再去飞书或你的聊天入口测试:
-
我知识库里以前记过哪些关于财富分配的内容?
-
搜索知识库:财富分配
-
搜知识库:AI 商业化
如果能正常返回:命中文件、要点摘要,再给出回答,那这套系统就算真正跑通了。
最后:这不是“装了一个插件”,而是在搭你的长期复利系统
很多人以为,OpenClaw、Obsidian、QMD、KnowledgeVault,只是工具堆叠。不是。
它们拼起来,真正构成的是一套个人长期复利系统:
-
OpenClaw:负责调度、执行、写入、调用
-
Obsidian:负责可视化、整理和回看
-
KnowledgeVault:负责沉淀你的知识资产
-
QMD:负责把过去的内容重新变成当下可调用的上下文
这意味着什么?意味着你以后不是每次和 AI “重新开始”,而是在一个不断增长、不断变厚、不断变聪明的系统上继续往前走。
这就是这套系统真正的价值。不是更像“第二大脑”这种空泛说法,而是:它开始帮你积累,而不只是陪你聊天。