 夜雨聆风
夜雨聆风





AI编程工具里的 Skill、MCP、Workflow、Rules、Memories 到底有什么区别?

今日话题:AI编程工具
用 Cursor / Windsurf / Claude Code 这些工具时,经常看到 MCP、Workflow、Rules、Memories、Skill 这些概念,感觉功能都差不多,但又各有各的叫法。
这些东西到底有什么区别,分别适合在什么场景下用?

@平凡
新知答主
4 月 23 日发布于知乎
很多人装了 Claude Code,两周后说「感觉跟直接用 Claude 没什么区别」。
这句话说明他们没用对。
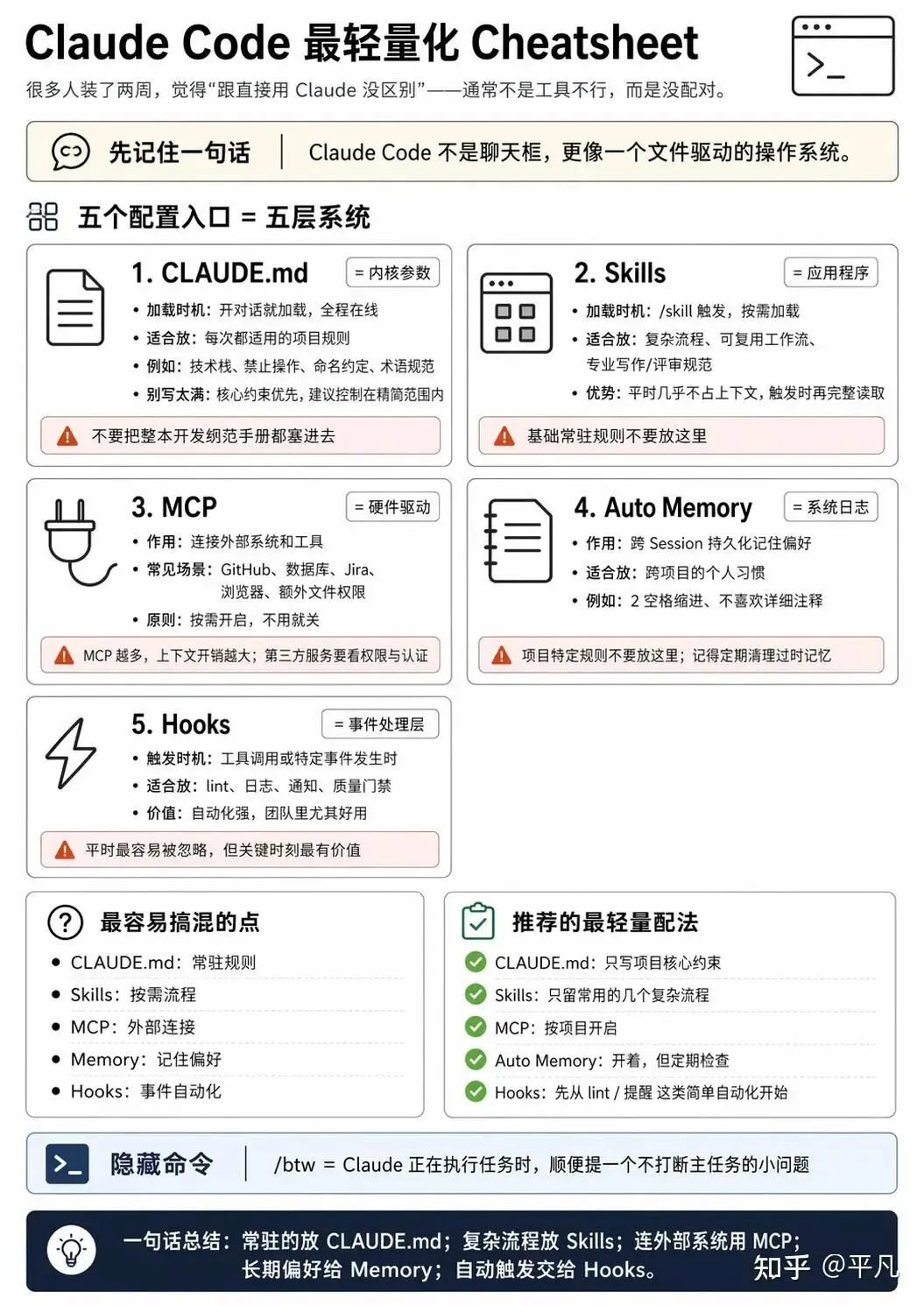
Claude Code 的核心设计不是聊天框,是一个文件驱动的操作系统。你不配置它,它给你的就是返厂状态。你配好了,它跟一个懂你项目的开发搭档差不多。
配置入口有五个,关系搞清楚了,才可能用得顺。
GPT-image-2 生成的 cheatsheet,太强了不得不说
以下是正文
先说这五个东西各是什么
CLAUDE.md、Skills、MCP、Auto Memory、Hooks。
很多人把这五个混在一起,觉得「配配就好了」,然后乱配一通,发现有的规则失效,有的功能触发不了,就放弃了。
用操作系统类比最清晰:
-
CLAUDE.md = 内核参数,开机就加载,全程在线
-
Skills = 应用程序,/skill触发,按需加载
-
MCP = 硬件驱动,连接外部系统
-
Auto Memory = 系统日志,跨Session持久化
-
Hooks = 事件处理层,工具调用时触发
这五层优先级不同,加载时机不同,解决的问题也不同。混在一起配是会出问题的。
CLAUDE.md:规则层,写对了等于给Claude装了项目记忆
CLAUDE.md是Claude Code开对话就读的文件,不需要每次提醒它,它自己会加载。
放在这里的东西,应该是”每次对话都适用”的规则。比如:
-
这个项目用什么技术栈
-
禁止做什么(不要给我加注释,不要自作主张重构)
-
跨文件的命名约定
-
特定的术语规范
然后有一个我用了很长时间才踩到的坑。
CLAUDE.md的有效指令数大约在150条以内。
系统提示词有长度上限,Claude Code会把CLAUDE.md 的内容注入进去,但超过一定长度之后,Claude 处理的注意力会分散,部分规则实际上会被随机忽略。
这个限制官方没有明确说明,用户测试摸出来的数字貌似是 160,据说写进去的规则太多的话不见得生效。
所以 CLAUDE.md 不是写得越多越好,而是要写得精,最重要的约束放前面,其他的移到Skills里按需加载。
写 CLAUDE.md 的结构建议:
-
项目说明(3-5行)
-
核心技术栈(只写非默认项)
-
禁止操作(5条以内,真正重要的)
-
术语规范(如果有行业黑话)
不建议:把整个开发规范手册搬进去,全放进去等于什么都没放。
Skills:应用层,复杂流程封装成可复用指令
Skills 跟 CLAUDE.md 的核心区别是加载时机。
CLAUDE.md 全程在线,但 Skills 只有在你用 /skill-name 触发时才会被完整读取。这意味着Skills 不占用日常对话的上下文预算,触发时完整内容才注入进来。
说白了就是这样:Skills的元数据(名称、用途描述)会常驻,大约 100 token 左右,让 Claude 知道”有这个工具可以用”。完整内容只有在命中匹配时才加载。
这解释了一件事:为什么你可以在 Claude Code 里放几十个 Skills,而它并不会因此变慢。
它在用渐进加载的策略管理上下文。
Skills 适合放什么:
-
复杂的多步骤流程(比如”code review按这套步骤来”)
-
专业领域的写作规范(比如”技术文档按这个格式”)
-
项目特定的工作方式(比如”这个项目的PR流程是这样的”)
不适合放 Skills 里的:每次对话都要用的基础规则,那个放 CLAUDE.md。
MCP:驱动层,让Claude能操作外部系统
MCP(Model Context Protocol)是 Anthropic 发布的开放协议,解决的是”Claude怎么跟外部世界交互”的问题。
最常见的用法:连接数据库、调用 GitHub/Jira 等API、操作浏览器、读写超出默认权限的本地文件。
有一个实际成本值得知道:40 个 MCP 工具的schema大约消耗 55,000 token 的上下文空间。这不是用了才算,是定义了就要算。所以不是MCP越多越好,按需开启,不用的关掉。
另外一个现实问题:目前公开 MCP 服务器中,38.7% 没有认证机制。如果你在使用第三方 MCP服务,检查一下它的权限范围,特别是涉及代码仓库或数据库的。
Auto Memory:日志层,让Claude跨对话记住你
这个功能争议最大,因为同类产品的决策相反。
Cursor 在 2025年 删掉了类似的Memory功能,理由是「AI自动记忆不可靠,会累积错误」,他们更相信显式配置。
Claude Code 的 Auto Memory 选择了另一条路:它把学到的用户偏好写成 markdown 文件存在本地,你可以直接查看和编辑。透明度比较高的实现方式。
适合放 Memory 里的:跨项目的个人偏好(偏好2空格缩进、不喜欢详细注释)。
不适合放 Memory 里的:项目特定的规则,那个放CLAUDE.md。定期检查 Memory 文件,清理过时或不准确的条目。
Hooks:事件层,工具调用时的自动化触发
Hooks 是五层里最少被用到,但有时候最有价值的一层。
逻辑是:当 Claude Code 执行特定操作时,自动触发一个shell命令。
比如:
-
每次Claude写完代码,自动跑lint检查
-
每次Claude调用某个MCP工具前,先打一条日志
-
Claude读某个文件之后,触发一个通知
Hooks 特别适合团队场景,你可以把质量门禁自动化,Claude Code 无法绕过它们。
所有配置都是文本文件,可以进 git 仓库,可以被团队共享和版本控制。这是图形界面工具做不到的一点。
一个有意思的隐藏命令
/btw:在 Claude 正在执行任务时,如果你有一个不相关的问题想顺便问,可以用 /btw 你的问题,它不会打断当前任务,而是在任务完成后同时回答这个平行问题。
这类细节说明 Claude Code 的设计哲学:terminal-first,文件驱动,每个功能都可以被git追踪、审查、版本控制。
我自己现在的配置方式
CLAUDE.md:80条以内,只写项目核心约束,不写可以推断出来的东西。
Skills:≦10,分别对应我常用的几个复杂流程(superpower和AK的几个)。触发用 /skill 名称,平时不占上下文。
MCP:按项目开启,目前常用 GitHub MCP 和数据库 MCP,还有几个联网搜索的 MCP,不用的时候关掉。
Auto Memory:开着,内存足够大,多了总比少的好。
Hooks:用得不算多,主要是提醒我完成某个任务滴一声。
阅读更多
🚀 AI 产品扶持计划:
知乎为 AI 产品提供定制宣发支持,了解/报名请戳:知乎「AI 新品非正式发布现场」扶持计划
🚀 知乎 AI 社群:
如果你是泛 AI 爱好者,对 AI 资讯感兴趣,欢迎扫码加入知乎 AI 社群↓,我们将每周送上 AI 周报,不定时发布 AI 线上线下活动与 AI 产品测试尝鲜。

知乎AI交流群
让一部分开发者先走起来
🚀 知乎科技账号正式登陆 X:
👉 https://x.com/ZhihuFrontier,聚焦「技术 × 观点」的跨语境对话