 夜雨聆风
夜雨聆风





查资料不用翻文档,QAnything+Ollama+Qwen:7b 构建属于自己的本地知识库
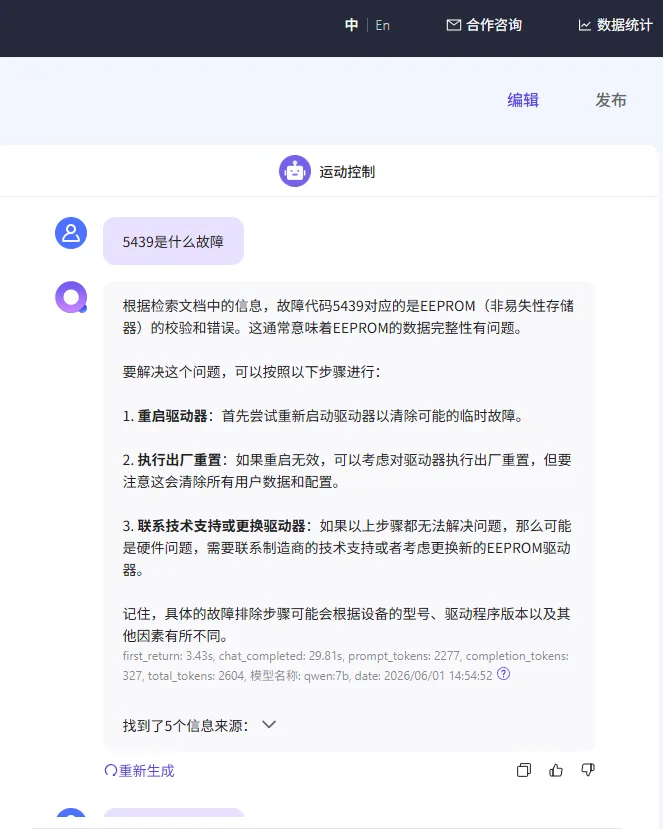
得益于这几年AI的快速发展,依托QAnything、Ollama与Qwen:7b模型搭建Windows本地知识库,就可实现文档离线智能解析、一键问答、精准检索,彻底告别翻找文档的低效模式。
好处:QAnything支持OpenAI和Ollama,使用Ollama无需申请OpenAI的API,直接调用本地模型,完全本地,完全免费!(花钱?花不了一点儿)
而且整套方案轻量化、易部署、零网络依赖,普通电脑也能流畅运行,这对于数据不能上云、对外,自己对技术资料有一定掌握程度的人来说实在是太友好了。
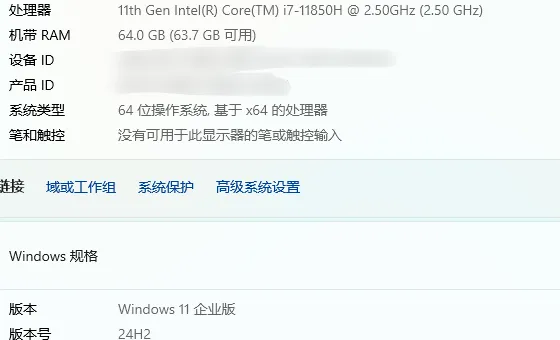
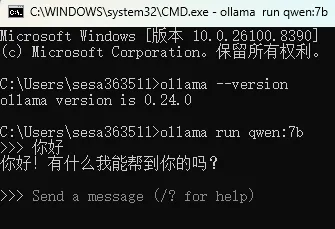
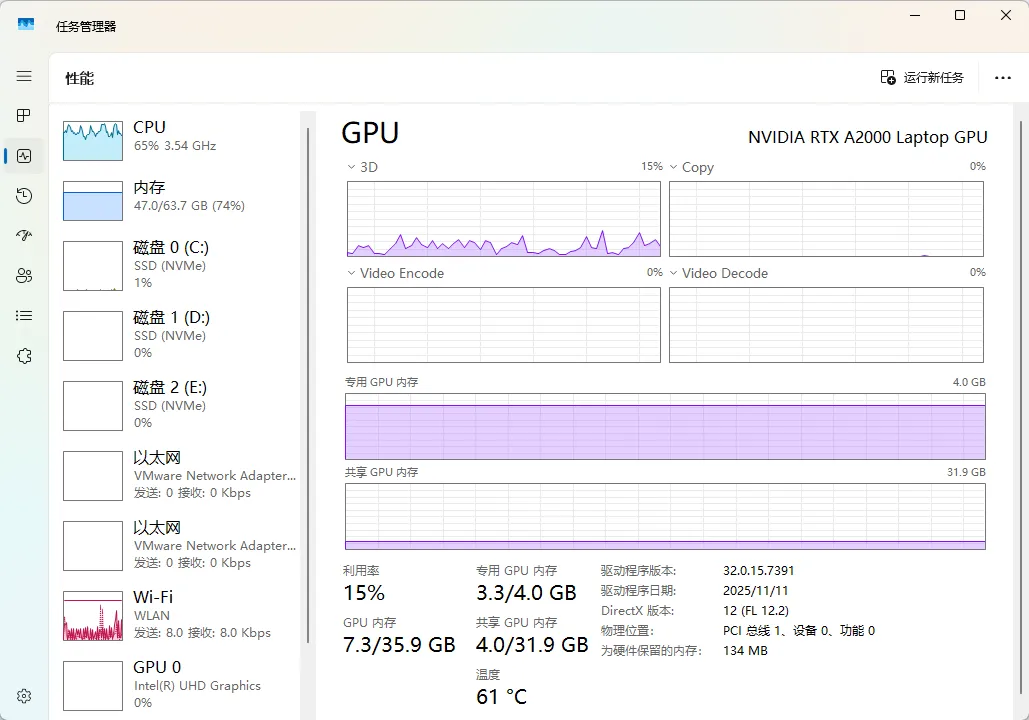
接下来我们来看下是如何实现的,首先说下硬件配置,小编使用的是Windows11企业版系统,11代的i7-850H,显卡是NV RTX A2000只有4G的显存,算是比较老的一套硬件了,不过显卡支持CUDA加速,所以跑个Qwen的7b还是比较流程的。


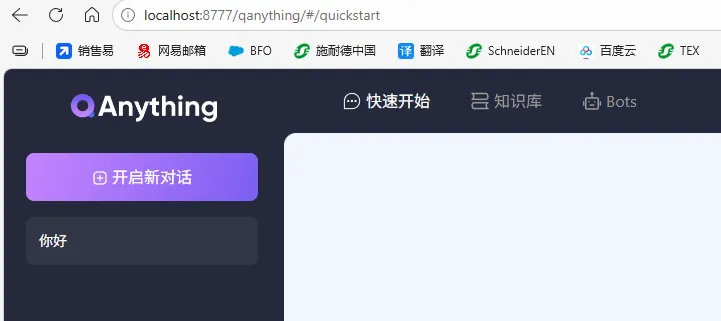
QAnything是网易的一个开源RAG知识库工具,主打多格式文档解析、智能检索与问答交互。网址:https://qanything.ai/

我们选择开源的免费部署版。

建议:
-
WSL2 ✅ -
Ubuntu 20.04 / 22.04 ✅
sudo apt update
sudo apt install -y git python3 python3-pip python3-venv build-essential curl
curl -fsSL https://deb.nodesource.com/setup_18.x | sudo -E bash –
sudo apt install -y nodejs
sudo apt install -y docker.io
sudo service docker start
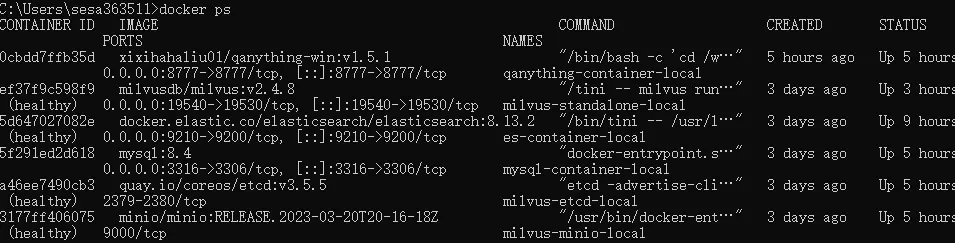
git clone https://github.com/QAnything/QAnything.git
cd QAnything
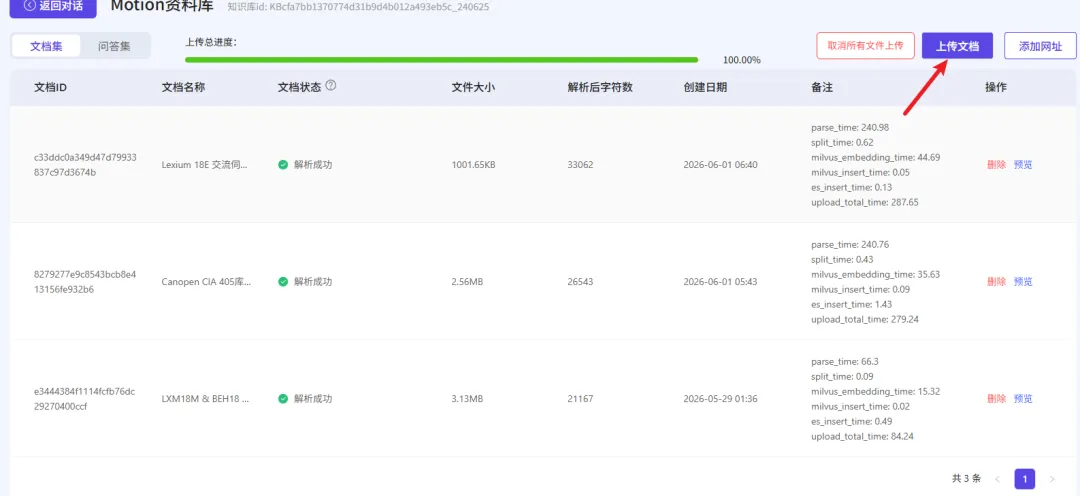
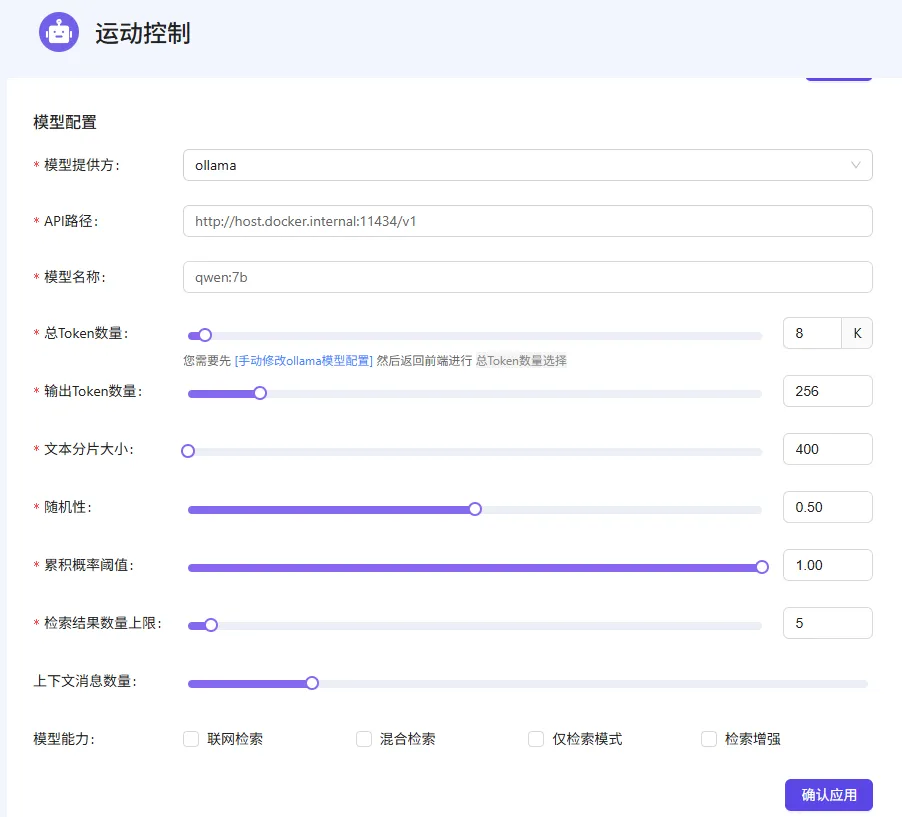

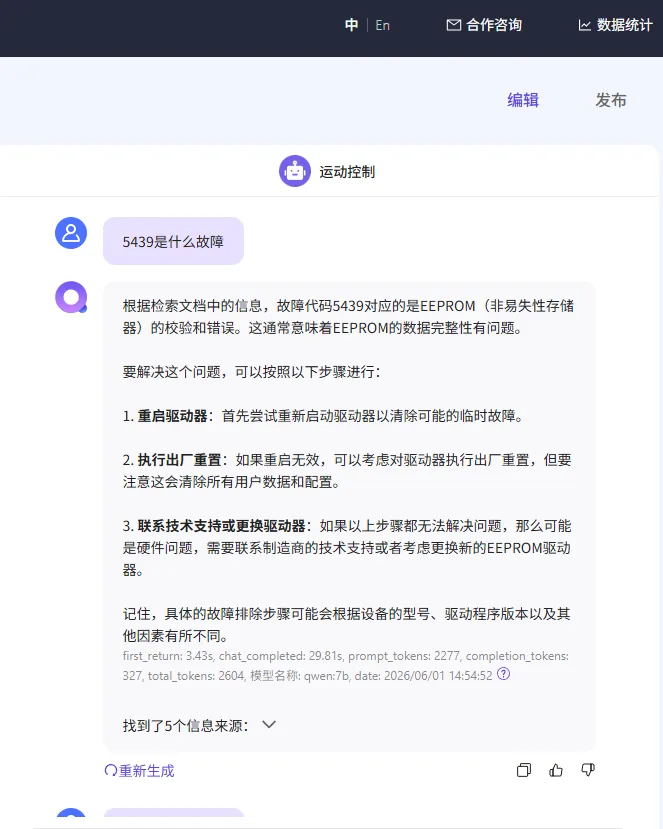
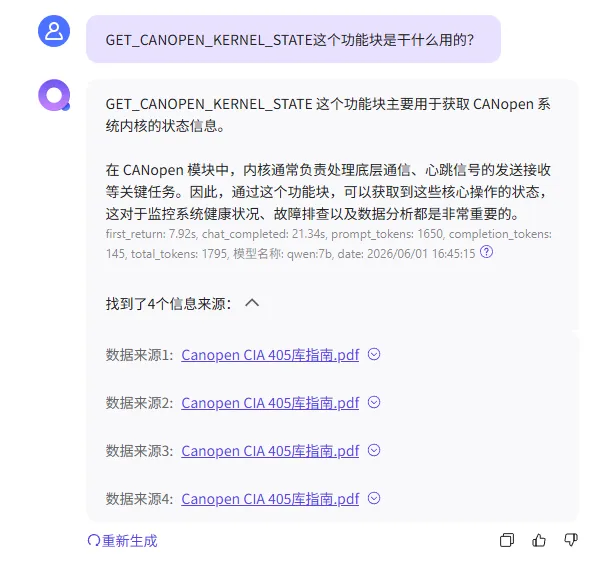
QAnything+Ollama+Qwen:7b组合核心优点
1. 完全离线运行,数据安全可控
整套系统搭建完成后无需任何网络支持,所有文档数据、问答推理均在本地电脑完成,数据不会上传云端,彻底规避办公资料、学习资料泄露风险。相较于在线AI问答工具,无需担心隐私泄露、文件上传留存问题,适合处理涉密办公文档、个人私密学习资料。
2. 轻量化低配置,适配普通电脑
Qwen:7b模型经过优化压缩,搭配Ollama轻量化调度,对硬件要求极低,16G内存、普通集显Windows电脑即可流畅运行,无需高端显卡和专业算力设备。QAnything资源占用少,后台运行不卡顿电脑日常操作,兼顾实用性与兼容性。
3. 全格式解析,检索效率翻倍
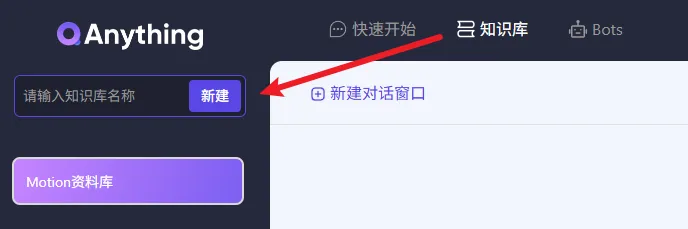
传统文档检索仅支持关键词匹配,易出现漏检、错检问题。该组合依托大模型语义理解能力,可深度解析文档语义、逻辑框架,支持模糊提问、总结归纳、细节检索。无论是上千页手册、零散笔记,还是多表格数据文档,均可一键汇总解析,快速提炼核心信息,告别手动翻找、逐页阅读的低效模式。
4. 免费开源无门槛,使用零成本
Ollama、QAnything均为开源免费工具,Qwen:7b模型可免费本地部署,无会员充值、次数限制、广告弹窗等问题。一次搭建永久使用,可随时新增、删除、更新本地文档,自主迭代专属知识库,适配长期学习、办公资料管理需求。
5. 智能交互性强,适配多场景
不同于传统检索工具的机械反馈,该本地知识库可智能理解自然语言提问,支持文档总结、要点提取、问题解答、内容对比等功能。学生可收纳课程资料、论文素材,职场人可整理方案模板、行业规范、办公手册,全方位适配个人学习、职场办公、资料归档等各类场景。