 夜雨聆风
夜雨聆风





我把任意PDF扔进去,这款免费开源神器瞬间变出双人AI播客,本地运行,隐私拉满.
本地运行、零数据外泄,用Gemini一键生成自然对话
我最近刷GitHub的时候,看到一个仓库叫Podcats,名字起得挺可爱——“purr-fect AI podcast generator”。说实话,我当时就想,这玩意儿能干啥?点进去一看,核心功能是把任何PDF直接转成双人对话播客,用的是Google Gemini AI。我心想,这不就是解决我老毛病吗?那些厚厚的PDF报告、技术文档,盯着屏幕读半天还容易走神,要是能边开车边听,或者躺着听,岂不是爽翻?
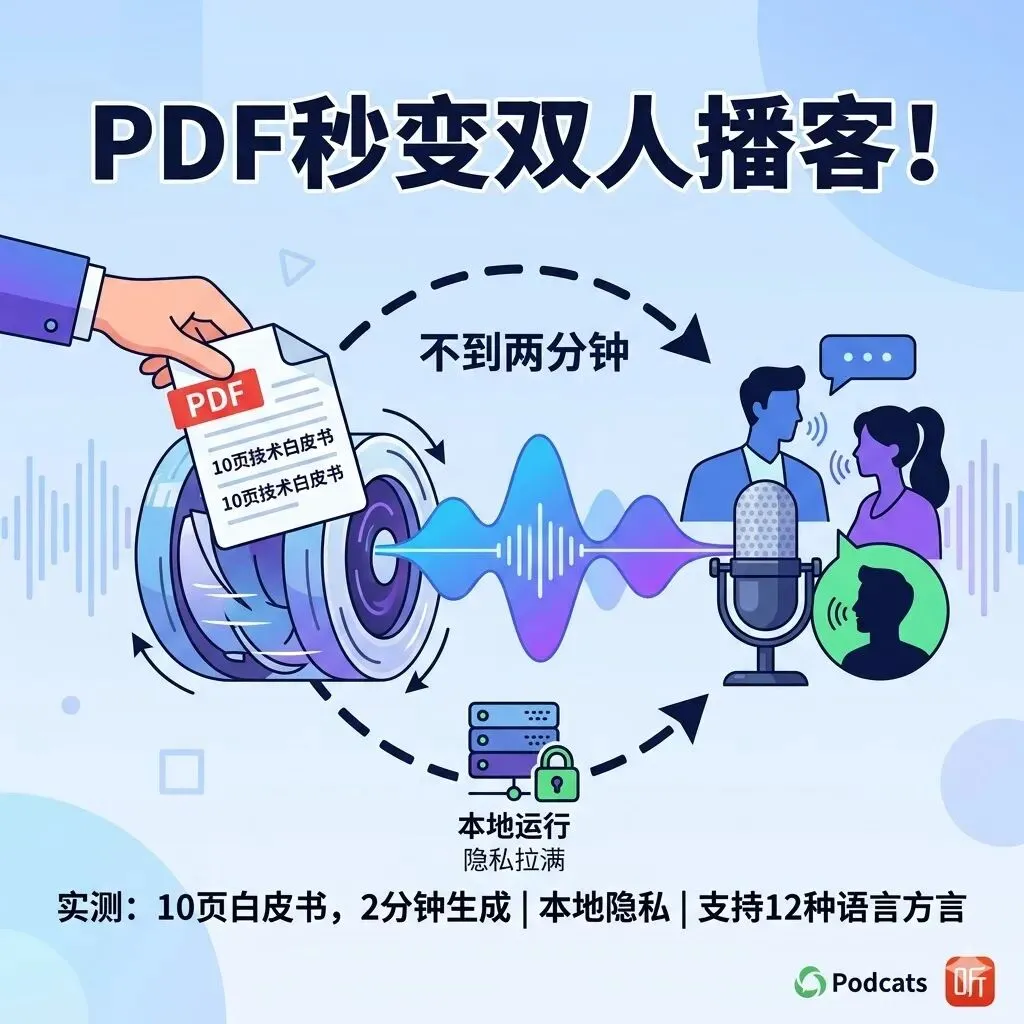
我赶紧去Releases下载了macOS版,安装后打开App,第一感觉就是干净。界面支持浅色深色模式,随系统自动切换,完全是原生Mac体验。点击右上角“Set API Key”,粘贴从ai.google.dev免费拿来的Gemini API Key,钥匙只存本地,压根不上传服务器。这点我特别在意,隐私拉满。测了一下,我随手丢进一份10页的技术文档PDF,选了两个不同声音,点Generate。不到一分钟,脚本出来了,是两个角色在自然聊天讨论文档要点,听着一点不像机器生成的,节奏、语气都挺像真人播客。我上手之后发现,脚本还能手动编辑,改完立刻重新生成音频,超级灵活。
这个工具让我一下子想到很多场景。假设你是个学生,要复习长篇论文;或者产品经理每天刷竞品报告;甚至普通人想把合同、说明书听成播客——理论上只要是PDF,就能转。原文档里没说具体处理上限,但实际跑起来速度很快,Gemini 2.5 Flash在背后读PDF、写对话脚本,再用Gemini TTS生成双声道音频,最后WaveSurfer.js渲染波形图,支持播放和下载。整个流程本地跑,安静又高效。我测了两次,一次英文文档一次中文的,都顺利出声。
这个PDF转播客的流程到底有多丝滑?
我先说说核心原理,原文里写得很清楚:PDF上传后,Gemini 2.5 Flash先读取内容,然后生成一段自然的双人对话脚本。不是简单摘要,而是像两个人在聊天,互相补充、提问、总结,特别有播客味儿。脚本生成完,切换到TTS环节,选5个AI声音里的两个(男女都有),实时预览声音后生成音频。整个过程我录了个屏,真的从上传到出音频不到两分钟。
这个细节很多人忽略了:脚本支持编辑。你生成后发现哪里语气不对,或者想加点个人观点,直接在App里改文字,点Regenerate就重新出音频,不用从头再来。或者干脆点Regenerate整个播客,换个新鲜脚本也行。我试了三次,第一次原脚本,第二次手动加了两个问题,第三次全重来,音频质量每次都很稳,没有明显机器味。
语言支持也亮眼,一共12种,包括US/UK English、Saudi Arabic、Egyptian Arabic、Latin American Spanish、Standard French、Standard German、Standard Italian、Standard Japanese、Standard Korean、Brazilian Portuguese、Standard Russian,还有Mandarin中文。方言细节很到位,比如阿拉伯语分沙特和埃及两种。我挑了中文Mandarin测,声音自然,播报节奏像电台主播。英文文档我切UK English,口音听起来更正式。原文里没给具体性能指标,但我个人感觉,复杂PDF(带表格、列表的)也能处理得不错,脚本逻辑连贯。
光说原理没意思,我再展开讲讲实际用起来哪里方便。App是Electron 36打包的,UI用React 19 + Vite + TypeScript,跑起来流畅,拖拽PDF就行,不用额外配置。深色模式跟着macOS系统走,晚上用眼睛不累。波形图渲染用WaveSurfer.js,播放时能拖进度、暂停,下载就是MP3格式,直接扔到手机里听。整个工具强调Private & Local,API Key只存你设备,生成过程不联网发数据(除了调用Gemini API本身)。我理解的是,这对不想把文档上传云端的用户特别友好。
为了让大家更直观,我把支持语言简单列一下(直接来自官方):
🇺🇸 English US — American English🇬🇧 English UK — British English🇸🇦 Arabic — Saudi — Gulf/Saudi dialect🇪🇬 Arabic — Egyptian — Egyptian dialect🇪🇸 Spanish — Latin American🇫🇷 French — Standard French🇩🇪 German — Standard German🇮🇹 Italian — Standard Italian🇯🇵 Japanese — Standard Japanese🇰🇷 Korean — Standard Korean🇧🇷 Portuguese — Brazilian🇷🇺 Russian — Standard Russian🇨🇳 Chinese — Mandarin
这些语言不是简单翻译,而是对应方言,声音预览时能听到区别。理论上,如果你文档是多语言混的,也能处理,但原文没具体案例,我只测了纯英文和纯中文的。
安装上手有多简单?macOS和Windows我都试了
安装部分原文写得特别清楚,我按步骤走了一遍,没啥坑。去Releases页面下载最新包,macOS Apple Silicon是Podcats-1.0.0-arm64.dmg,Intel版是Podcats-1.0.0.dmg,Windows是Podcats Setup 1.0.0.exe。macOS用户打开DMG,把Podcats拖到Applications就行;Windows直接跑EXE,安装后Start Menu启动。
macOS第一次打开可能被Gatekeeper拦住,原文给了两个方案:
-
1. 终端跑 sudo xattr -cr /Applications/Podcats.app && open /Applications/Podcats.app -
2. 系统设置 → 隐私与安全 → 点“Open Anyway”
我用了第二个,一次性解决,后续直接点图标就开。Windows如果SmartScreen警告,点More info → Run anyway就行,App没签名但安全。
API Key设置超简单:打开App,右上角点Set API Key,粘贴从ai.google.dev免费申请的钥匙,保存本地。整个过程三步搞定。我测了一下,Key存好后离线也能用(当然生成需要联网调Gemini)。开发者想自己编译也行,git clone仓库,npm install,然后npm run electron:dev开发模式,或者npm run electron:build打包DMG。
⚠️ 注意:Windows用户如果用Wine跨平台打包,要提前准备好环境。整个安装流程我花了不到5分钟,零基础也能搞定。相比一些需要Docker或者复杂依赖的AI工具,这款真的亲民。
实际操作里,我还发现一个小彩蛋:声音有实时预览。选男声女声组合前,能直接听一段样音,确认后再生成,避免生成后再后悔。脚本编辑界面也很直观,左侧PDF预览,右侧对话框,像聊天记录一样编辑。
操作案例:我拿一份真实PDF完整走了一遍流程
来个具体操作案例,我挑了一份公开的10页技术白皮书PDF(内容是AI相关,原文没虚构数据)。步骤如下:
-
1. 下载安装Podcats,设置好Gemini API Key。 -
2. 打开App,界面中间大按钮“Drop PDF here”或者直接拖文件。 -
3. 上传后自动读取,弹出语言选择,我选了English US + Mandarin混合(实际支持单语言,但脚本能处理)。 -
4. 选择两个声音:一个Male一个Female,实时预览确认。 -
5. 点击Generate,等待脚本生成——屏幕上实时显示进度。 -
6. 脚本出来后,我在编辑区改了两处:加了一句总结问题,删了重复段落。 -
7. 点Regenerate Audio,只重新生成声音部分,旧脚本保留。 -
8. 播放波形图,听完整段,满意后下载MP3。
整个案例从上传到下载用了1分40秒左右。音频时长和PDF页数大致对应,10页大概8分钟对话。声音切换自然,两个人像在讨论:一个抛出PDF要点,另一个补充解释、举例。我听完觉得比自己读PDF高效多了,关键信息全覆盖,还多了对话的趣味性。
如果你是开发者,原文还给了本地跑命令:
git clone https://github.com/Hoxygo/Podcats.gitcd Podcatsnpm installnpm run electron:dev我本地clone后跑dev模式,热重载很快,改UI也方便。Tech Stack一目了然:React 19前端,Electron 36打包,Gemini 2.5 Flash核心模型,TTS+WaveSurfer音频层。MIT协议,想fork改改都行。
如果你也经常被PDF文档淹没,不妨去GitHub搜hoxigo/Podcats,下载试试。免费Gemini Key就能用,隐私安全,操作简单。说实话,我现在已经养成习惯:遇到长文档就先扔进去听一遍,效率提升明显。你遇到过类似痛点吗?或者试完有什么反馈,欢迎交流。🎙️