 夜雨聆风
夜雨聆风





详解 epoll:源码之前 了无秘密
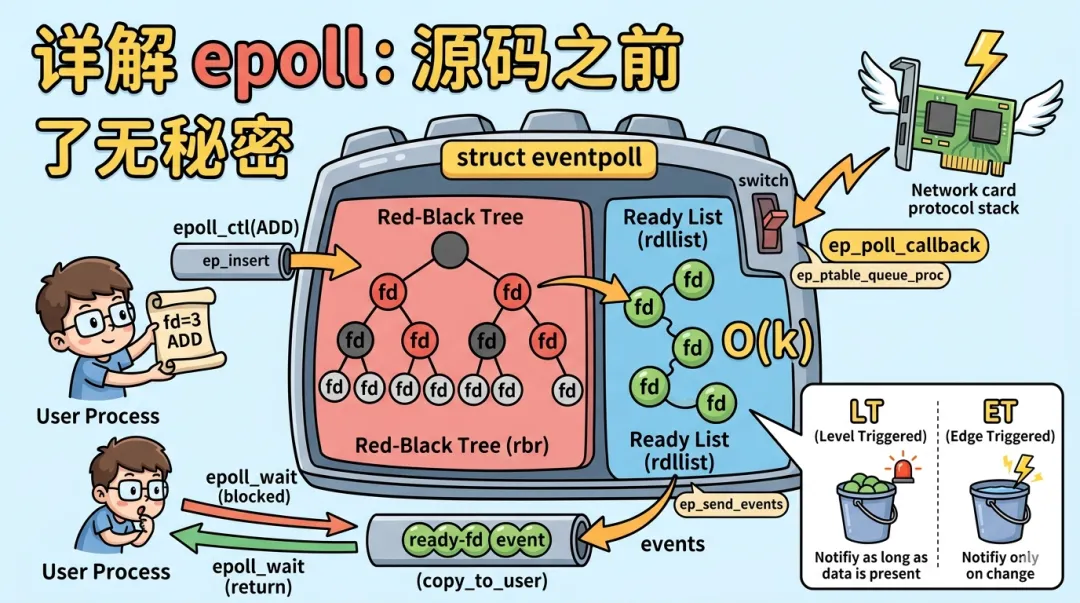
在 Linux 网络编程中,epoll 是每一个开发者绕不开的名字。从早期的 select 和 poll 到如今支撑 C10K 甚至 C10M 并发的 epoll,这不仅仅是 API 的更迭,更是内核 IO 模型的一次革命。
本文将带你从底层数据结构、异步回调机制到边缘触发(ET)的本质,全方位解析 epoll 的高性能密码。源码之前,了无秘密。
一、 epoll 的三板斧:API 背后发生了什么?
epoll 的使用非常简洁,主要由三个系统调用组成:
1. epoll_create / epoll_create1
intepoll_create(int size);intepoll_create1(int flags);
内核会创建一个 struct eventpoll 对象。这是 epoll 的核心数据结构,其内部维护了两大核心数据结构:
-
红黑树 (RB-Tree):存放所有通过
epoll_ctl注册的待监听文件描述符(fd)。具体为struct rb_root_cached rbr,这是一个带缓存的红黑树根节点。 -
就绪链表 (Ready List):存放所有已经发生 IO 事件、待处理的就绪 fd。具体为
struct list_head rdllist。
struct eventpoll 还包含以下关键成员:
struct eventpoll {struct mutex mtx; // 保护epoll实例的互斥锁wait_queue_head_t wq; // epoll_wait的等待队列wait_queue_head_t poll_wait; // 文件poll的等待队列struct list_head rdllist; // 就绪链表spinlock_t lock; // 保护rdllist和ovflist的自旋锁struct rb_root_cached rbr; // 红黑树根节点struct epitem *ovflist; // 溢出链表(事件传输期间临时队列)struct wakeup_source *ws; // wakeup sourcestruct user_struct *user; // 创建该epoll的用户struct file *file; // 对应的文件结构refcount_t refcount; // 引用计数// ...};
值得注意的是,epoll_create(int size) 的 size 参数在现代内核中已被忽略,仅为向后兼容保留。内核会自动按需分配内存,使用时只需保证size大于0即可。epoll_create1(int flags) 支持 EPOLL_CLOEXEC 标志。
2. epoll_ctl
intepoll_ctl(int epfd, int op, int fd, struct epoll_event *event);这是 epoll 最繁忙的阶段。op 可以是EPOLL_CTL_ADD、EPOLL_CTL_MOD 或 EPOLL_CTL_DEL。。
当执行 ADD 操作时,内核会执行以下关键步骤(ep_insert 函数):
-
分配 epitem:从
epi_cacheSlab 缓存中分配一个struct epitem对象。内核使用 Slab 分配器优化大量 epitem 的创建。 -
插入红黑树:调用
ep_rbtree_insert将新节点插入红黑树。红黑树的键值为(file*, fd)组合,确保唯一性。 -
注册回调:通过
ep_ptable_queue_proc在目标文件的等待队列上注册ep_poll_callback回调函数。具体实现为: -
分配一个
struct eppoll_entry(从pwq_cacheSlab 缓存) -
调用
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback)初始化回调 -
调用
add_wait_queue或add_wait_queue_exclusive将其挂载到目标文件的等待队列 -
挂载到文件列表:通过
attach_epitem将 epitem 挂载到struct file的f_ep哈希表中,便于文件关闭时自动清理。
关键细节:ep_poll_callback 的注册发生在 VFS 层面,该回调会在目标文件状态变化时被调用。
3. epoll_wait
intepoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);不同于 select 需要全量轮询,epoll_wait 只是一个”收割者”。其内实现的 ep_poll遵循以下流程:
-
检查就绪队列:首先调用
ep_events_available检查rdllist和ovflist是否有数据。 -
获取事件:如果有可用的 epitem,调用
ep_send_events将其转移到临时链表txlist,然后遍历调用ep_item_poll重新检查事件。 -
复制到用户态:对于每个有效的就绪事件,调用
epoll_put_uevent将其拷贝到用户提供的events数组。 -
挂起等待:如果无数据且 timeout 不为 0,则将当前线程加入
ep->wq等待队列并进入睡眠。 -
唤醒后重试:被唤醒后再次检查就绪队列,重复上述过程。
注意:对于 LT 模式的事件,如果需要保留在就绪队列中,ep_send_events 会将其重新放回 ep->rdllist
epoll_wait 返回的是就绪事件的总数。如果返回 0 表示超时,返回 -1 表示出错(如被信号中断 EINTR)。
二、 核心奥秘:同一个对象的多重面孔
为什么 epoll 能实现 O(1) 的插入和 O(k)(k 为就绪数)的检索?秘密在于内核结构体 struct epitem。
struct epitem {union {struct rb_node rbn; // 红黑树节点struct rcu_head rcu; // 用于RCU释放};struct list_head rdllink; // 就绪链表节点struct epitem *next; // 指向ovflist的下一个节点struct epoll_filefd ffd; // 文件描述符信息bool dying; // 标记即将释放struct eppoll_entry *pwqlist; // poll等待队列条目列表struct eventpoll *ep; // 所属的eventpollstruct hlist_node fllink; // 文件关联链表节点struct wakeup_source *ws; // wakeup sourcestruct epoll_event event; // 用户注册的事件掩码};
在内核中,一个 epitem 同时拥有”多只手”:
-
红黑树:通过
rbn成员挂载在红黑树中,实现快速检索。查找时间复杂度为 O(log N)。 -
链表:通过
rdllink成员挂载在就绪链表中。 -
文件关联:通过
fllink成员挂载到struct file的哈希表中。 -
溢出链表:通过
next成员在ovflist中排队。
关键设计:内核并不会在数据就绪时新建节点,也不会在红黑树和链表之间物理移动节点。它仅仅是修改了指针的指向。同一个 epitem 对象,既在大本营(红黑树)里待命,也在值班表(就绪链表)里干活。
当回调函数 ep_poll_callback 被触发时,它执行 list_add_tail(&epi->rdllink, &ep->rdllist),这只是修改了 rdllink 的前后指针,将 epitem 添加到就绪链表。此时该 epitem 同时存在于两个数据结构中——红黑树中的位置保持不变,同时出现在就绪链表上。
当 epoll_wait 处理完该 epitem 后,对于 LT 模式,会再次调用 list_add_tail 将其放回就绪链表;对于 ET 模式,则不执行此操作,让它仅留在红黑树中。整个过程没有内存分配,没有节点销毁,只有指针的重定向。
三、 异步通知机制:回调是如何触发的?
epoll 性能飞跃的核心在于:变”主动轮询”为”被动通知”。
3.1 回调挂载机制
在 epoll_ctl(ADD) 时,内核通过 VFS 的 poll 接口(具体在 ep_insert → ep_item_poll → ep_ptable_queue_proc),将 ep_poll_callback 挂载到该 Socket 的等待队列中:
/*** ep_ptable_queue_proc - 这是一个回调函数,由目标文件的 poll 操作触发。* @file: 正在被监听的目标文件指针。* @whead: 目标文件提供的等待队列头(wait queue head),当事件发生时会唤醒此队列。* @pt: poll_table 结构指针,它是 epoll 在调用 vfs_poll 时传进去的上下文。*/staticvoidep_ptable_queue_proc(structfile *file, wait_queue_head_t *whead,poll_table *pt){// 1. 通过 poll_table 指针,反向找到它所属的 ep_pqueue 结构体// ep_pqueue 包装了 poll_table 和对应的 epitem (epoll 监控项)struct ep_pqueue *epq = container_of(pt, struct ep_pqueue, pt);struct epitem *epi = epq->epi;struct eppoll_entry *pwq;// 2. 从内核缓存中分配一个 eppoll_entry (包装器)// 这个结构体代表了 “一个被监听的文件” 与 “一个等待队列” 之间的关联pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL);if (pwq) {// 3. 初始化等待队列项// 设置回调函数为 ep_poll_callback。// 当目标文件就绪唤醒 whead 时,内核会执行 ep_poll_callback,而不是唤醒一个普通的进程。init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);// 4. 记录相关信息pwq->whead = whead; // 保存目标文件的等待队列头pwq->base = epi; // 指向所属的 epitem,方便回调时找到对应的 epoll 节点// 5. 将初始化好的等待队列项 pwq->wait 加入到目标文件的等待队列中// 使用 exclusive (排他性) 模式,避免“惊群效应”(Thundering Herd)。//当多个线程同时 epoll_wait 同一个 epfd 时,内核只会唤醒其中一个,避免不必要的上下文切换开销add_wait_queue_exclusive(whead, &pwq->wait);// 6. 将这个关联项挂载到 epitem 的双向链表 (pwqlist) 中// 一个文件可能有多个等待队列(如某些驱动),所以用链表管理pwq->next = epi->pwqlist;epi->pwqlist = pwq;}}
3.2 回调触发流程
当网卡收到数据,通过中断机制触发协议栈处理。协议栈完成数据入队后,会调用该 Socket 等待队列上的唤醒函数。此时 ep_poll_callback 被触发:
staticintep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key){int ewake = 0;unsigned long flags;// 1. 通过 wait 指针,反向找到它所属的 epitem (监控项)struct epitem *epi = ep_item_from_wait(wait);// 2. 找到该监控项所属的 eventpoll (epoll 实例根对象)struct eventpoll *ep = epi->ep;// 3. 获取当前实际发生的事件掩码 (比如 POLLIN/POLLOUT)__poll_t pollflags = key_to_poll(key);// 加锁,保证就绪链表操作的原子性spin_lock_irqsave(&ep->lock, flags);// 4. 检查用户是否真的关心这个事件// 如果该 fd 没设置任何有效事件位,直接退出if (!(epi->event.events & ~EP_PRIVATE_BITS))goto out_unlock;// 5. 过滤不匹配的事件// 如果内核传来的事件 (pollflags) 和用户监听的事件没有交集,说明不是我们要的就绪if (pollflags && !(pollflags & epi->event.events))goto out_unlock;/*** 6. 核心逻辑:将就绪节点放入就绪链表*/// [特殊情况]:如果当前正在执行 epoll_wait 拷贝数据到用户空间,// 为了不破坏正在遍历的 rdllist,epoll 会开启一个“影子链表” ovflist。if (READ_ONCE(ep->ovflist) != EP_UNACTIVE_PTR) {if (epi->next == EP_UNACTIVE_PTR) {// 此时不操作 rdllist,而是挂载到 ovflist 这个临时溢出链表上epi->next = READ_ONCE(ep->ovflist);WRITE_ONCE(ep->ovflist, epi);}} else if (!ep_is_linked(epi)) {// [正常情况]:如果 epi 不在就绪链表中,直接将其加入到 rdllist 尾部list_add_tail(&epi->rdllink, &ep->rdllist);}/*** 7. 唤醒等待者*/// 如果有进程正在 epoll_wait() 阻塞等待,此时 ep->wq 队列不为空if (waitqueue_active(&ep->wq))// 唤醒进程wake_up(&ep->wq);//释放锁spin_unlock_irqrestore(&ep->lock, flags);}
3.3 ovflist 的作用
注意源码中有一个 ovflist(溢出链表)。这是 epoll 的精巧设计:在 ep_send_events 将事件拷贝到用户空间的过程中,ep->mtx 互斥锁被持有,在此期间发生的新的回调事件不能直接加入 rdllist(需要 ep->lock 保护),于是被临时加入 ovflist。ep_done_scan 会在释放锁后将这些溢出事件合并回 rdllist。
整个过程不需要扫描红黑树,也不需要遍历 fd,效率极高。
四、 深度剖析:epoll_wait 的”二次检查”逻辑
既然回调函数已经把 fd 放进链表了,epoll_wait 直接拿走不就行了?为什么还要进行所谓的”二次检查”?
在 epoll_wait 返回给用户前,它会遍历就绪链表,并再次调用 ep_item_poll(底层调用 vfs_poll)确认状态:
static __poll_t ep_item_poll(conststruct epitem *epi, poll_table *pt, int depth){struct file *file = epi_fget(epi);__poll_t res;if (!file)return 0;pt->_key = epi->event.events;res = vfs_poll(file, pt); // 再次调用底层poll检查fput(file);return res & epi->event.events;}
确认实时性:回调触发是”过去时”,此时此刻缓冲区可能已经被其他线程读空了。这次检查确保只返回当前仍然就绪的事件。
过滤事件掩码:确认发生的事件是否真的是用户通过 events 掩码监听的那几个。只有 revents & epi->event.events 非零的事件才会被返回。
LT 模式支持:对于水平触发(LT),如果此次检查发现数据没读完,内核会将该节点重新放回就绪链表,确保下次还能通知:
if (!(epi->event.events & EPOLLET)) {// Level Triggered: 重新放回就绪链表list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);}
五、 水平触发 (LT) vs 边缘触发 (ET)
5.1 基本概念
-
LT (Level Triggered):只要缓冲区有数据,就会不断触发。它是 epoll 的默认模式,逻辑简单,类似 select。只要有未处理的数据,
epoll_wait就会返回。 -
ET (Edge Triggered):状态变化(从无到有,或从有到更多)时仅触发一次。只有新建的事件或用户修改监听事件掩码(MOD)才会触发回调,已存在但未读尽的数据不会重复通知。
当你调用
epoll_ctl(MOD)时,内核会执行ep_modify函数。其内部逻辑如下:这意味着:如果你在 ET 模式下因为某种 Bug 没读完数据,又不想等下一次数据到达,可以通过
EPOLL_CTL_MOD重新激活这个 fd。 -
重新扫描状态:内核会主动调用一次
ep_item_poll(即vfs_poll),立即检查该 fd 当前的真实状态。 -
强制入队:如果此时 fd 确实处于就绪状态(比如缓冲区还有没读完的数据),且符合新的事件掩码,内核会直接将该节点挂入就绪链表。
-
唤醒进程:随后唤醒阻塞在
epoll_wait的进程。
5.2 源码实现
在 ep_send_events 中,二者的区别一目了然:
if (epi->event.events & EPOLLONESHOT)epi->event.events &= EP_PRIVATE_BITS; // 禁用,等待下次MODelse if (!(epi->event.events & EPOLLET)) {// LT: 重新放回就绪链表list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);}// ET: 不重新放回,就此脱链
5.3 ET 的高性能代价
ET 模式极大地减少了内核与用户态的交互频次,单次事件通知的复杂度更低。但要求开发者必须使用非阻塞 IO,并用 while 循环读尽所有数据(直到返回 EAGAIN),否则会导致事件”丢失”——因为该 fd 不会再次出现在就绪链表中,直到新数据到来。
正确的 ET 模式用法:
while (true) {int n = read(fd, buf, sizeof(buf));if (n == -1) {if (errno == EAGAIN || errno == EWOULDBLOCK) {// 数据已读尽,等待下次边缘触发break;}// 错误处理}// 处理数据}
5.4 EPOLLONESHOT
还有一个重要的标志 EPOLLONESHOT:事件触发一次后自动禁用,必须等待 epoll_ctl(fd, EPOLL_CTL_MOD, ...) 重新启用。这在高并发场景中用于防止一个 fd 上的事件被多个工作线程同时处理。
六、 锁机制与并发安全
epoll 的高性能离不开其精细的锁设计:
6.1 三层锁
-
epnested_mutex(全局互斥锁):防止嵌套的 epoll fd 形成循环。用于确保 A 加入 B、B 加入 A 的操作不会产生死锁。
-
ep->mtx(实例互斥锁):保护 epoll 实例的主要数据结构。在事件传输、epoll_ctl、DEL 操作时持有。
-
ep->lock(自旋锁):保护
rdllist和ovflist。因为可能在中断上下文中被持有,不能使用阻塞锁。
6.2 加锁顺序
获取顺序必须严格遵循:epnested_mutex → ep->mtx → ep->lock。
ep->mtx 在事件传输循环中必须被持有(因为 copy_to_user 可能睡眠),同时 epoll_ctl 操作也需要它来防止竞争。而 ep->lock 用于在 poll callback(可能运行在中断上下文)中快速修改就绪链表。
七、 进阶技巧:fd 还是 ptr?
在 epoll_event 结构体中,data 是一个联合体。很多人习惯只存 fd,但在高性能服务器(如 Nginx)中,更多使用 data.ptr。
struct Connection {int fd;char buf[1024];// 业务逻辑上下文...};// 注册时ev.data.ptr = new Connection(client_fd);epoll_ctl(epfd, EPOLL_CTL_ADD, client_fd, &ev);
优势:当 epoll_wait 返回时,通过 data.ptr 可以直接拿回业务对象的指针,省去了再次通过 fd 查找哈希表或数组的开销,真正实现从内核到业务层的全链路高性能。
这在 C10M 并发场景中意义重大——每减少一次哈希查找,每省去一次内存访问,都意味着性能的提升。
八、 嵌套 epoll 的环路检测
当一个 epoll fd 被添加到另一个 epoll fd 时,内核需要进行环路检测(源码约第2067-2151行的 ep_loop_check 函数族)。
8.1 问题
考虑以下情况:
epfd1 = epoll_create();epfd2 = epoll_create();epoll_ctl(epfd1, EPOLL_CTL_ADD, epfd2, ...);epoll_ctl(epfd2, EPOLL_CTL_ADD, epfd1, ...);
如果不加限制,两个 epoll 会形成死锁等待。
8.2 检测机制
reverse_path_check 函数通过 tfile_check_list 追踪新添加的 epoll 链接,递归检查是否会形成环路或过深的嵌套。最大嵌套深度限制为 EP_MAX_NESTS = 4。
同时,epnested_mutex 确保多个并发的 epoll_ctl 添加操作不会竞态形成环路。
九、 总结
epoll 的强大在于其对 Linux 内核特性的极致压榨:
红黑树:解决了高并发下 fd 管理的 O(log N) 查找问题。使用 rb_root_cached 优化了最左节点的缓存。
就绪链表与回调机制:彻底告别了 O(N) 的无效遍历。变轮询为回调,这是性能飞跃的关键。
双向引用节点设计:规避了频繁申请内存的开销。epitem 在红黑树和就绪链表之间”一身二用”。
ovflist 精巧设计:在事件传输期间临时保存新到事件,保证不丢失。
三层锁机制:在保证线程安全的同时,最小化锁竞争。
理解了这些底层细节,你才能在面对高并发系统的诡异 Bug(如 ET 模式下的死锁或数据残留)时,做到游刃有余。