 夜雨聆风
夜雨聆风





OpenAI深夜开源王炸!几十行代码开发贾维斯,网页光标竟自己动起来
OpenAI刚刚开源了一个重磅项目realtime-voice-component。
可以帮助咱们用GPT-Realtime-1.5更好地开发语音交互应用。
开源地址:https://github.com/openai/realtime-voice-component/
如果你最近一直在关注语音交互这块的发展,一定会有这样体会,每次看到OpenAI Realtime API那套东西就头疼。
不是说它不好,而是从那堆底层协议、音频流处理到最终做出一个能用的语音界面,中间要踩的坑实在是太多了。
你要是自己从头写,光是管理连接生命周期、处理工具调用、把实时语音和UI状态同步起来,就够喝一壶了。
而realtime-voice-component就是专门用来解决这个大难题的。
其实它就是一个专门给React浏览器应用做语音控制的开源组件库,它的底层跑在OpenAI的RealtimeAPI上面。
你可以把它理解成一层中间件,一头连着OpenAI的实时语音能力,另一头连着你自己写的Web应用。
打个比方吧。你平时用手机语音助手,说一句切换深色模式,屏幕就黑了。但如果你是一个前端开发者,想在自己的网站里也实现类似的功能,你会发现这个事情远比想象中复杂。
你要管麦克风权限、音频编解码、和云端模型的实时通信、还要把模型的理解结果转化成具体的UI操作。
OpenAI的RealtimeAPI虽然提供了基础能力,但它给的是底层传输层,不是现成的用户界面组件。
realtime-voice-component就是来填补这个空白的。它把上面那些脏活累活都包了,你只需要告诉它你的应用能做什么操作,它就能帮你把语音和这些操作串联起来。
下面再唠唠它的几个特色功能:第一个是工具定义机制。你用一个叫defineVoiceTool的函数,把自己应用里某个操作包装成一个语音工具。
比如你的网站有个切换主题的功能,你就写一个setThemeTool,把名字、描述、参数格式和执行函数都配好。
这样一来用户说切换深色模式的时候,组件库就能自动匹配到这个工具并执行。你完全不用操心语音识别和意图理解那些复杂的逻辑,只要把已有的业务功能暴露出去就行了。
紧跟着这个东西的是控制器createVoice Control Controller,它是整个组件库的大脑。
连接建立和断开、工具调用分发、对话记录组装、传输层管理,全归它管。创建控制器的时候你需要配置认证方式、系统指令、输出模式、激活方式和工具列表。
好处很直接,你不需要在每个组件里重复写连接逻辑,一个控制器实例就能管住一整套语音交互流程。
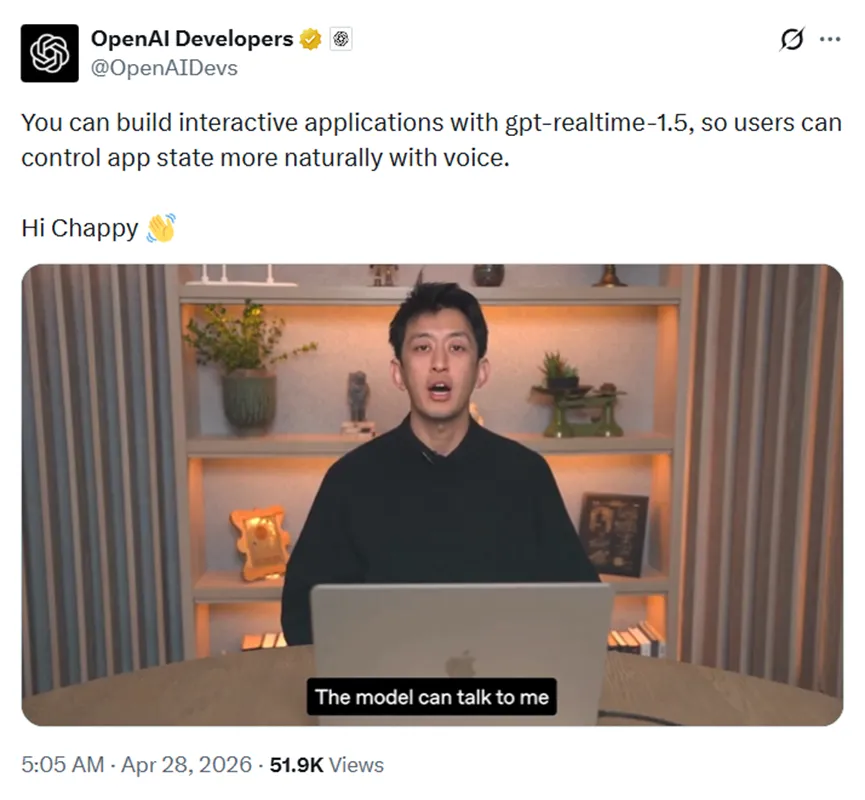
有了控制器之后,useVoiceControl这个Hook把它和你的React组件绑在一起。你可以自己在外面创建好控制器传进来,也可以让Hook内部自动帮你创建。
对于React开发者来说这手感很熟悉,状态管理、组件生命周期都用老一套方式处理就行了,不用再去学什么新的响应式范式。
然后是最省心的部分,Voice Control Widget,一个开箱即用的语音控制UI组件。
把它丢到页面里就能干活,用户点按钮或语音唤醒都能触发。麦克风权限请求、连接状态展示、录音指示这些细碎的UI逻辑它全帮你搞定了。
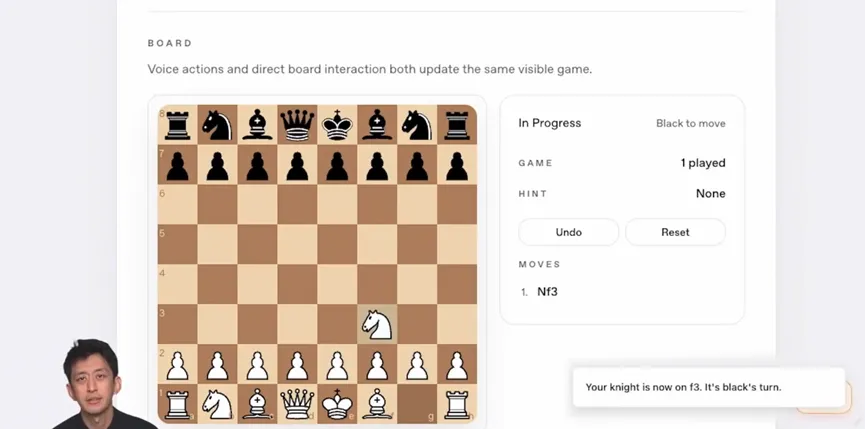
不过说到最让我觉得有意思的部分,其实是那个幽灵光标。
useGhostCursor和GhostCursorOverlay会在语音操作执行的时候,在屏幕上显示一个半透明的光标移动动画,让你肉眼看到AI正在操作哪个界面元素。
这个功能虽然是可选的,但它解决了一个非常实际的心理问题:用户看不见操作过程就会慌,会担心AI到底在背后搞什么鬼。有了这个视觉反馈,信任感是实打实地上去了。
在语音活动检测这块,组件库也做了不少讲究。它默认走服务端的VAD来判断用户什么时候开口、什么时候说完,而不是靠浏览器端那套不太靠谱的实现。
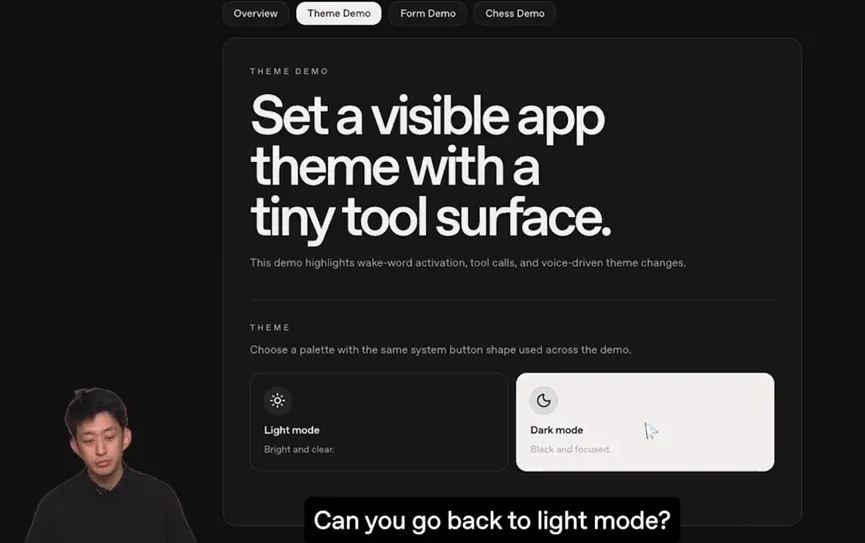
精度高是一方面,更细心的是,对纯文本和工具调用类的场景,它额外设了一个中断响应关闭的选项。
什么意思呢,就是当AI正在执行一个操作或者回复文本的时候,用户如果突然又插嘴,不会把正在跑的任务直接打断。
这个细节乍一看不起眼,但真用起来你会发现它避免了非常多让人抓狂的体验断裂。
我觉得这个开源特别适合几类人。正在做AI驱动产品原型的前端开发者,想快速验证语音交互到底行不行得通。
想搞清楚OpenAI Realtime API怎么跟Web前端配合的技术同学,直接看源码和demo比啃文档强太多了。
已经在用React做产品、想给现有功能加一层语音入口的团队,这个库的接入成本确实很低。
想系统掌握AI核心技能、获取行业认可资质?
CAIE注册人工智能工程师认证
助你拓宽职业赛道,成为AI领域持证实力派
企业、高校及渠道合作
请联系微信:FYLlaoshi
