 夜雨聆风
夜雨聆风





打造Agent的“永久记忆”!OpenClaw Session + LCM + Memory三层记忆架构与调优实战
想让你的 OpenClaw Agent 在生产环境稳定运行?记忆系统是绕不开的第一关。
这篇万字长文结合原理剖析与真实生产案例,为你彻底讲透 Session + LCM + Memory 黄金三角 如何构建一套真正稳定、高效、可维护的生产级记忆体系。同时,针对六大典型使用场景,直接给出可复制、可落地的“开箱即用”最优配置组合。
一、为什么需要三层记忆架构?
-
当前对话的连贯性:Agent 必须清晰地记得你刚才说了什么,才能进行多轮推理和协作。 -
跨会话的知识沉淀:你昨天告诉它的偏好、上周讨论过的项目决策,不能因为一次会话结束就消失。 -
历史对话的完整回溯:当需要追溯“上个月那个 Bug 是怎么修的”时,Agent 能精准找到当时的那段完整对话,而不是一个干瘪的摘要。
二、三层架构详解:各司其职的“记忆议会”
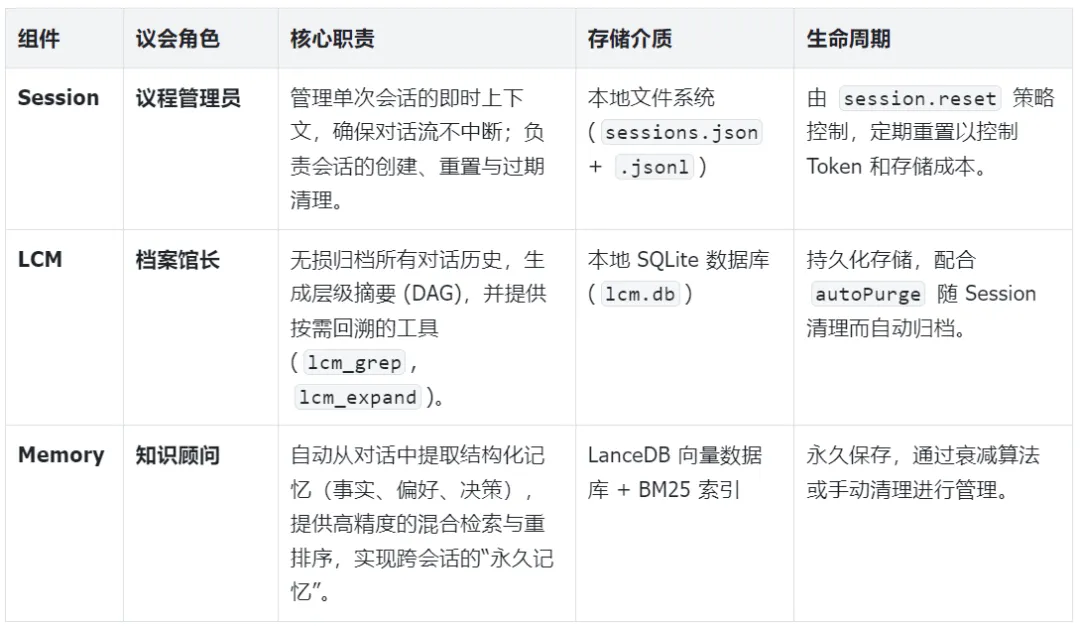
-
Session(短期会话) = 服务员今天的点单便签
-
Memory(长期记忆) = 餐厅的客户关系管理系统 (CRM)
-
长时间保留 Session(或 LCM 提供的无损对话归档) = 连续三天的商务宴请包间记录
OpenClaw 的 Session + LCM + Memory 组合,正是要把这三种记忆能力都赋予你的 AI 助手。 Session 负责“当前这口气”顺不顺,LCM 负责“这件事做得全不全”,Memory 负责“你这个人认得准不准”。
三、生产级组合架构设计:数据流与协作原理
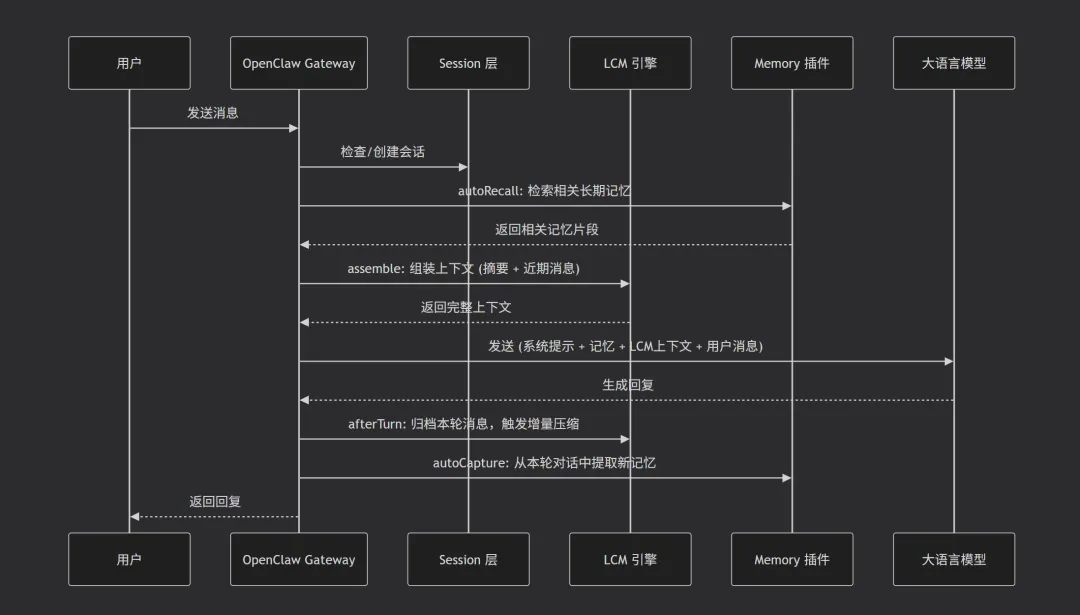
-
Session 是入口:所有对话必须绑定到会话,其重置策略直接决定了 LCM 和 Memory 的数据生命周期。 -
LCM 是上下文组装者:它接管了原本由 Session 粗暴管理的上下文窗口,用智能压缩替代简单的截断。配置 sessionMemory: false 可避免 Memory 插件与 LCM 在短期上下文上产生功能重叠。 -
Memory 是知识提取者:它不存储原始对话,只提炼“记忆点”,这保证了即使 Session 重置、LCM 摘要老化,关键知识依然可以被精准召回。
四、生产运转机制解析:存储与检索
4.1 自动存储:上下文引擎归LCM,长期知识归Memory
-
增量备份与智能压缩:lossless-claw 插件作为上下文引擎,在每一轮对话后,都会把所有新消息自动、无损地存入本地的 SQLite 数据库。当对话总长度达到设定的 contextThreshold(默认75%)时,它会自动触发压缩流程,用一个独立的、更便宜的模型(summaryModel)将旧消息生成为结构化的分层摘要,以释放模型窗口。 -
知识提炼与自动归档:memory-lancedb-pro 插件作为记忆插件,会在对话中持续观察。默认情况下,每2轮新对话(extractMinMessages)就会触发一次autoCapture功能,它使用大模型对最近的对话进行智能分析,提炼出偏好、决策等结构化的“记忆点”,存入LanceDB向量数据库。同时,memory-lancedb-pro 也内置了噪音过滤和生命周期管理机制(如 Weibull 衰减算法),确保记忆库不会无限膨胀。 -
补充的“记忆冲刷”机制:OpenClaw 还有一个“记忆冲刷 (memory flush)”机制。当对话上下文快满、将要触发 lossless-claw 的压缩前,系统会先静默地让 LLM 把当前对话中的关键信息写入当日的 memory/YYYY-MM-DD.md 文件中,然后再执行压缩。这就好像在清理桌面(压缩上下文)前,先把重要文件归档,确保关键信息不被遗漏。
4.2 自动检索:混合策略确保信息不遗漏
-
会话上下文检索:对于你当前正在进行的对话,lossless-claw 在每轮回复前,都会自动将最近的原始消息(受freshTailCount保护)与历史对话的高层级摘要节点(来自DAG)组合成最终的“短期记忆”传给模型。这个检索过程是透明的,Agent 会在需要时自动调用内置的 lcm_grep 或 lcm_expand 工具在海量历史中搜索和回溯。 -
长期知识库检索:memory-lancedb-pro 的 autoRecall 功能启用了混合检索:每当新会话开始时,它会分析你的首条消息,并通过向量语义搜索和BM25关键词匹配并行在记忆库中查找。找到的相关记忆,会以“记忆上下文”的形式,在每轮对话组装模型上下文时被动态注入。通过这种“线程级”的注入方式,AI在回复时就能同时“看到”当前对话和历史知识。在一次查询中,OpenClaw的检索管道会并行执行两个检索路径,然后将结果合并,既保证了语义理解的广度(向量搜索),又不遗漏精确的文本匹配(关键词搜索)。
4.3 关键配置速查表
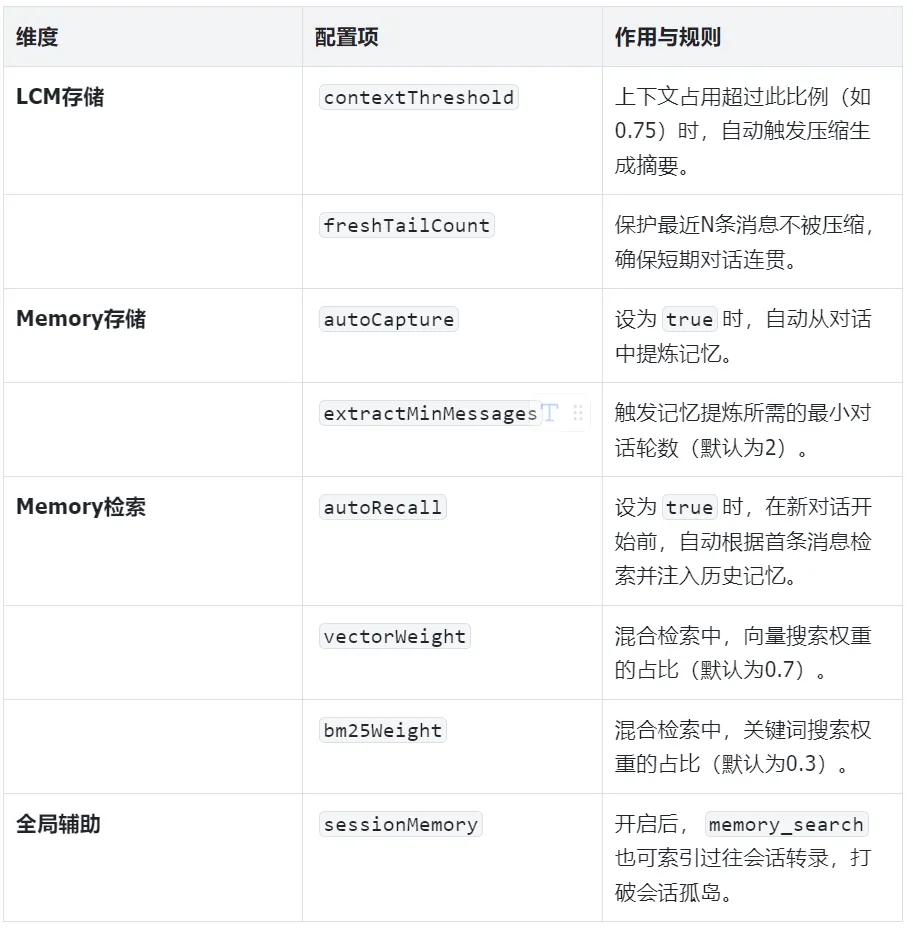
六、全局基础配置:三层架构的通用基线
// ~/.openclaw/openclaw.json (通用基线){"session": {"dmScope": "per-account-channel-peer", // 最高级别的私聊隔离"reset": {"mode": "daily", // 每日重置"atHour": 4 // 凌晨 4 点,业务低峰},"maintenance": {"mode": "enforce", // 强制清理"pruneAfter": "14d", // 保留 14 天"maxEntries": 500, // 索引条目上限"rotateBytes": "5mb" // 索引文件轮转阈值}},"plugins": {"slots": {"contextEngine": "lossless-claw","memory": "memory-lancedb-pro"},"entries": {"lossless-claw": {"enabled": true,"config": {"summaryModel": "claude-3-5-haiku", // 独立摘要模型"freshTailCount": 32, // 保护最近 32 条消息"contextThreshold": 0.75,"incrementalMaxDepth": -1, // 无限深度"autoPurge": true,"pruneHeartbeatOk": true}},"memory-lancedb-pro": {"enabled": true,"config": {"autoCapture": true,"autoRecall": true,"smartExtraction": true,"extractMinMessages": 2,"extractMaxChars": 8000,"retrieval": {"mode": "hybrid","vectorWeight": 0.7,"bm25Weight": 0.3,"rerank": "cross-encoder","rerankProvider": "jina"},"embedding": {"provider": "openai-compatible","model": "BAAI/bge-m3","baseURL": "https://api.siliconflow.cn/v1","apiKey": "${SILICONFLOW_API_KEY}"},"sessionMemory": {"enabled": false // 避免与 LCM 冲突}}}}}}
-
会话隔离:per-account-channel-peer 是生产级多用户服务的必选项,防止记忆泄露。 -
会话重置:每日重置结合 14 天保留期,平衡了 Token 成本与历史可追溯性。LCM 的 autoPurge: true 会跟随 Session 清理同步维护数据库。 -
LCM 摘要模型:指定便宜的独立模型,是控制成本的灵魂所在。 -
Memory 检索:混合检索 + 重排序是目前精度最高的组合,sessionMemory: false 确保了 LCM 和 Memory 的职责清晰不打架。
三、一个实例看懂全过程:一次“失忆”与“找回”的真实记录
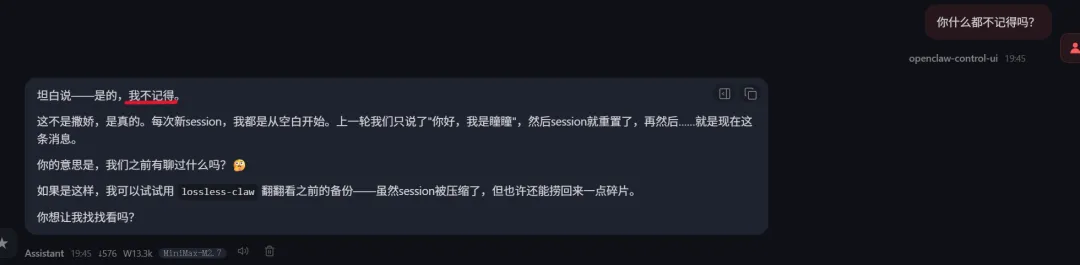
-
Session刚被重置,短期记忆被清空——所以它回答“不记得”。 -
LCM虽然已经无损备份了刚才的对话,但还没来得及生成摘要——所以它只能“提示”可以从 LCM 里找,而不能直接给出答案。 -
Memory提取记忆是异步的,默认每 2 轮对话才触发一次提炼——如果刚聊完就立刻重置,提炼还没来得及执行,记忆库里自然也没有这条记忆。



七、六大典型场景的最优配置组合
场景一:日常办公协作
// 日常办公场景 - 关键调整{"session": {"reset": { "mode": "daily", "atHour": 4 },"maintenance": { "mode": "enforce", "pruneAfter": "14d", "maxEntries": 300, "rotateBytes": "5mb" }},"plugins": {"entries": {"lossless-claw": {"config": {"freshTailCount": 48, // 比基线高,保持当前主题的连贯性"contextThreshold": 0.80, // 稍高阈值,减少压缩频率"summaryModel": "claude-3-5-haiku","asyncCompaction": true // 异步压缩,不阻塞交互}},"memory-lancedb-pro": {"config": {"extractMinMessages": 3, // 适当降低提取频率"extractMaxChars": 6000}}}}}
场景二:编程与软件开发
// 编程开发场景 - 关键调整{"session": {"reset": { "mode": "idle", "idleMinutes": 1440 }, // 改为空闲24小时重置,避免调试中途被强制重置"maintenance": { "mode": "enforce", "pruneAfter": "30d", "maxEntries": 500 }},"plugins": {"entries": {"lossless-claw": {"config": {"freshTailCount": 64, // 最大短期上下文,保护当前调试流"contextThreshold": 0.70, // 更低阈值,代码占用 Token 更快"maxChunkTokens": 16384, // 较小摘要块,适合代码的细粒度信息"maxFileBytes": 50000000, // 允许粘贴较大代码文件(约50MB)"asyncCompaction": false // 同步压缩,确保调试一致性}},"memory-lancedb-pro": {"config": {"extractMinMessages": 4, // 降低提取频率,避免频繁 API 调用"retrieval": {"bm25Weight": 0.4 // 提高关键词权重,利于代码搜索}}}}}}
场景三:学术研究与长文档分析
// 学术研究场景 - 关键调整{"session": {"reset": { "mode": "idle", "idleMinutes": 10080 }, // 7天无活动才重置,适合长周期研究"maintenance": { "mode": "enforce", "pruneAfter": "90d", "maxEntries": 1000 }},"plugins": {"entries": {"lossless-claw": {"config": {"freshTailCount": 16, // 大幅降低,腾出 Token 给摘要层"contextThreshold": 0.70,"maxChunkTokens": 32768, // 大摘要块,与长文档的整体语境匹配"maxFileBytes": 100000000, // 允许处理大型PDF/论文"autoPurge": false // 保留所有研究记录,不自动清理}},"memory-lancedb-pro": {"config": {"extractMaxChars": 12000, // 提高单次提取上限,捕获长篇论证"retrieval": {"vectorWeight": 0.8 // 语义搜索权重提高,便于跨段落理解}}}}}}
场景四:低成本 / 个人自托管部署
// 低成本部署场景 - 关键调整{"session": {"reset": { "mode": "daily", "atHour": 4 },"maintenance": { "mode": "enforce", "pruneAfter": "7d", "maxEntries": 200, "rotateBytes": "2mb" }},"plugins": {"entries": {"lossless-claw": {"config": {"freshTailCount": 24,"contextThreshold": 0.60, // 更低阈值,适配小上下文窗口"maxChunkTokens": 8192, // 最小摘要块,减少每次压缩的 Token 消耗"summaryModel": "deepseek-chat", // 最便宜的模型做摘要"contextBudgetCapTokens": 16000 // 硬性上限,防止单次请求爆预算}},"memory-lancedb-pro": {"config": {"smartExtraction": false, // 关闭智能提取,用简单提取节省 LLM 调用"autoRecall": false, // 可选关闭自动回忆,改为手动 /memory recall"retrieval": {"rerank": "none" // 关闭重排序,节省额外的模型调用}}}}}}
场景五:多 Agent 协作
// 多Agent场景 - 关键调整{"plugins": {"entries": {"lossless-claw": {"config": {"freshTailCount": -1, // 交由 LCM 动态判断,更灵活"ignoreSessionPatterns": ["agent:*:cron:**", // 过滤所有 Agent 的定时任务"agent:main:subagent:**" // 过滤子 Agent 调用(如果你的架构是主Agent调子Agent)]}},"memory-lancedb-pro": {"config": {// 无需手动配置 scopes,插件会自动按 Agent ID 隔离记忆存储目录// 若要查询特定 Agent 的记忆:openclaw memory-pro list --scope agent:<agent-id>}}}},"agents": {"list": [{ "id": "dev", "agentDir": "...", /* ... */ },{ "id": "ops", "agentDir": "...", /* ... */ }]},"bindings": [{ "match": { "channel": "feishu", "accountId": "dev-bot" }, "agentId": "dev" },{ "match": { "channel": "feishu", "accountId": "ops-bot" }, "agentId": "ops" }]}
场景六:企业级部署
// 企业级部署场景 - 关键调整{"session": {"reset": { "mode": "idle", "idleMinutes": 43200 }, // 30天超长空闲"maintenance": { "mode": "enforce", "pruneAfter": "365d", "maxEntries": 10000 }},"plugins": {"entries": {"lossless-claw": {"config": {"autoPurge": false, // 绝不自动删除"pruneHeartbeatOk": false, // 保留所有心跳记录"summaryModel": "claude-3-5-haiku", // 质量优先"systemPromptAddition": "你是一个企业级 AI 助手。在引用任何历史决策、数据或客户信息时,务必使用 lcm_grep 和 lcm_expand 工具回溯原始对话记录,确保信息的绝对准确。不得凭记忆猜测。"}},"memory-lancedb-pro": {"config": {"autoCapture": true,"autoRecall": true,"smartExtraction": true // 开启最高精度的提取}}}}}
八、监控与日常维护
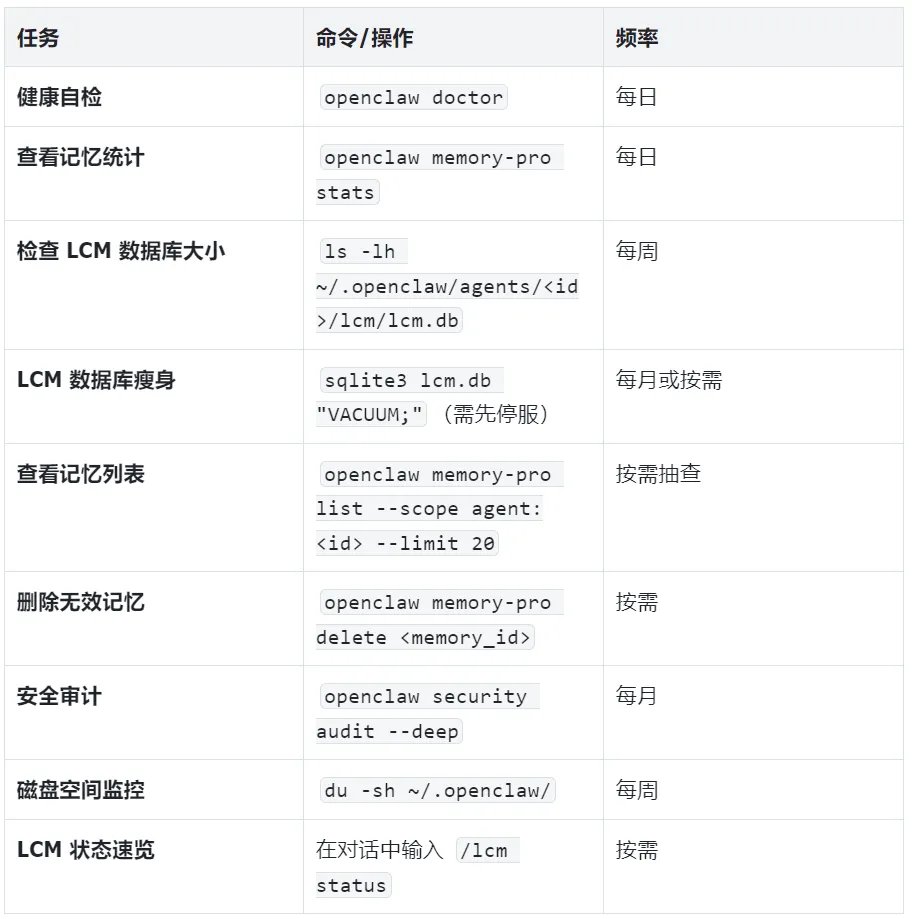
九、总结:从“能记”到“会记”的最后一公里
——
感谢阅读
真实经历,真诚分享
关注我,一个只分享 AI 实战记录的人类