 夜雨聆风
夜雨聆风





别再部署本地大模型了!OpenClaw、Hermes完全免费使用大模型指南

说个真实感受,两年前我也跟着折腾本地部署,Qwen3.6-35B、Gemma 4 26B,一个个往机器上装。显卡跑得呼呼转,电费账单肉眼可见地涨,最怕的是来个任务,风扇狂转吵得睡不着。
后来发现OpenRouter这玩意儿,真后悔没早用。
OpenRouter是什么?简单说就是一个大模型API聚合平台,一个API Key,就能调用OpenAI、Anthropic、Google、Meta、DeepSeek等几乎所有主流模型。关键是——它有30多个完全免费的模型,不用绑卡,不用花钱,注个册就能用。
下面以OpenClaw(龙虾)为例,手把手教你配置(相信会openclaw的都会Hermes,我就不多说了)
一、怎么安装OpenClaw
我实在不想讲,但还是说一下吧
一键脚本,终端里一行命令搞定:
macOS/Linux用户:
curl -fsSL https://openclaw.ai/install.sh | bash
Windows用户(PowerShell):
iwr -useb https://openclaw.ai/install.ps1 | iex
脚本会自动检测环境、安装Node.js、完成配置。看到引导界面后选Yes继续。
二、接入OpenRouter
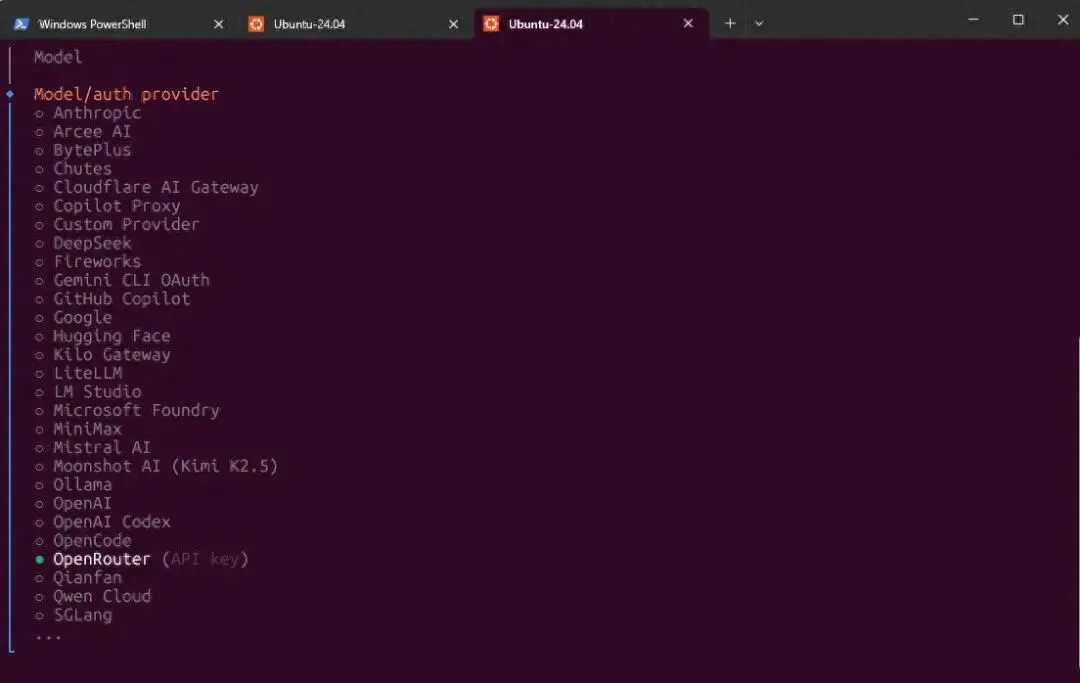
安装完成后,关键一步是配置模型提供商。
在引导流程中,选择OpenRouter作为模型提供商。然后去openroader.ai注册账号,完全免费的获取一个API Key,把它粘贴进去就行。
三、免费模型的选择
OpenRouter的免费模型池子很大,重点推荐这些免费模型
1.MiniMax M2.5(MiniMax)
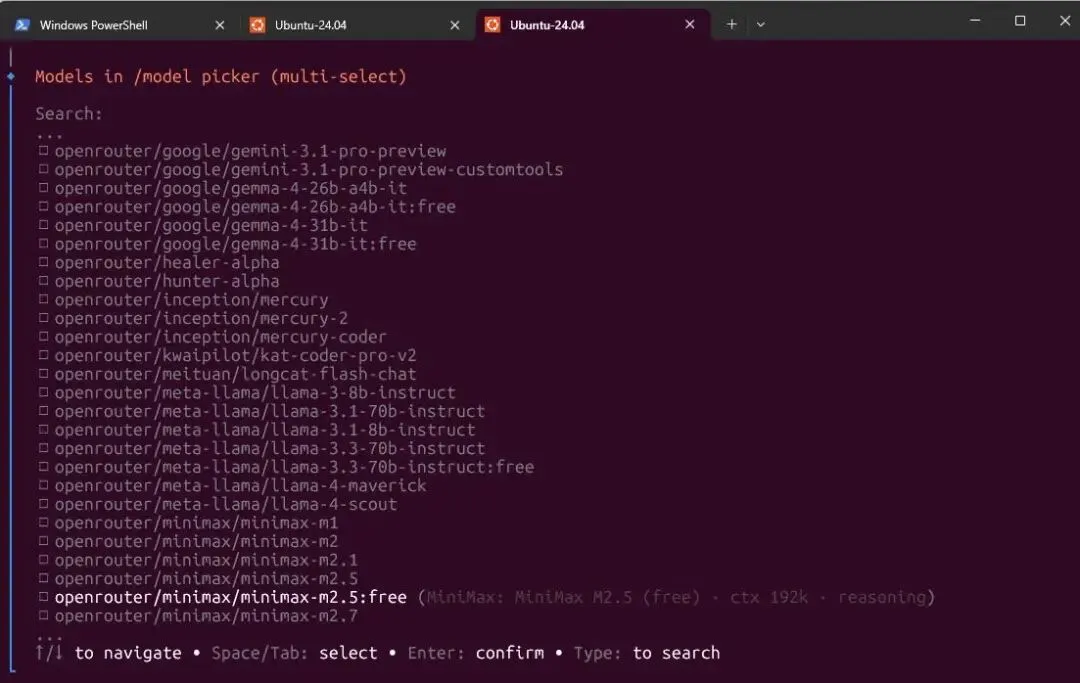
这个都知道吧,给你免费用,197K上下文,支持中文优化。国内团队做的,中文对话体验自然很多。日常聊天、写文章、翻译这些场景,用着很舒服。适合:中文内容创作、日常对话、翻译。
2.OWL-Alpha
这是个没人认领的大模型,实际强到离谱,我的最爱。据说有可能是家中国公司做的,也有人说是OpenRouter自家的旗舰免费模型,也有说是ZOO研发。先不管谁家的吧,反正免费,MoE架构,上下文窗口1M(是1兆啊朋友),工具调用强到离谱、结构化输出、图文理解。日常聊天、写代码、处理长文档都没问题。最大的优势是免费层速率还不错,轻度使用基本够用,如果舍得花10美刀则每日可以1000次调用,普通人根本用不完。适合:日常对话、代码辅助、文档处理。
3. Nemotron 3 Super 120B(英伟达)
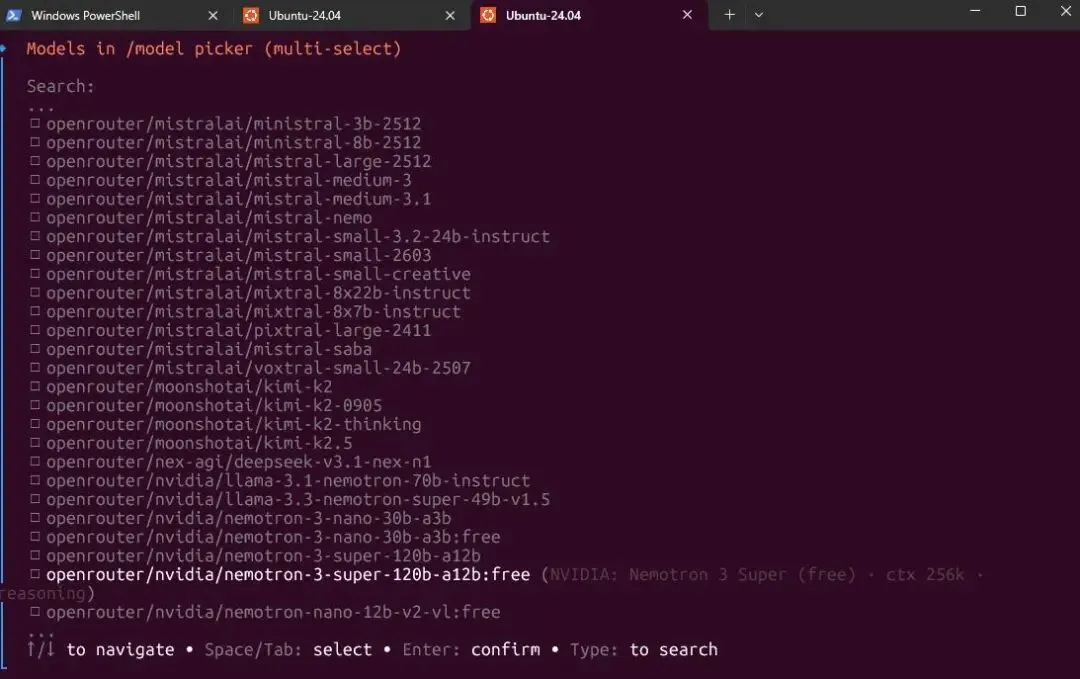
120B参数但只激活12B(MoE),262K上下文窗口,支持工具调用。AIME2026数学基准表现不错,代码和推理能力在免费模型里属于第一梯队。适合:数学推理、编程、agent工作流。
4.Gemma 4-31B
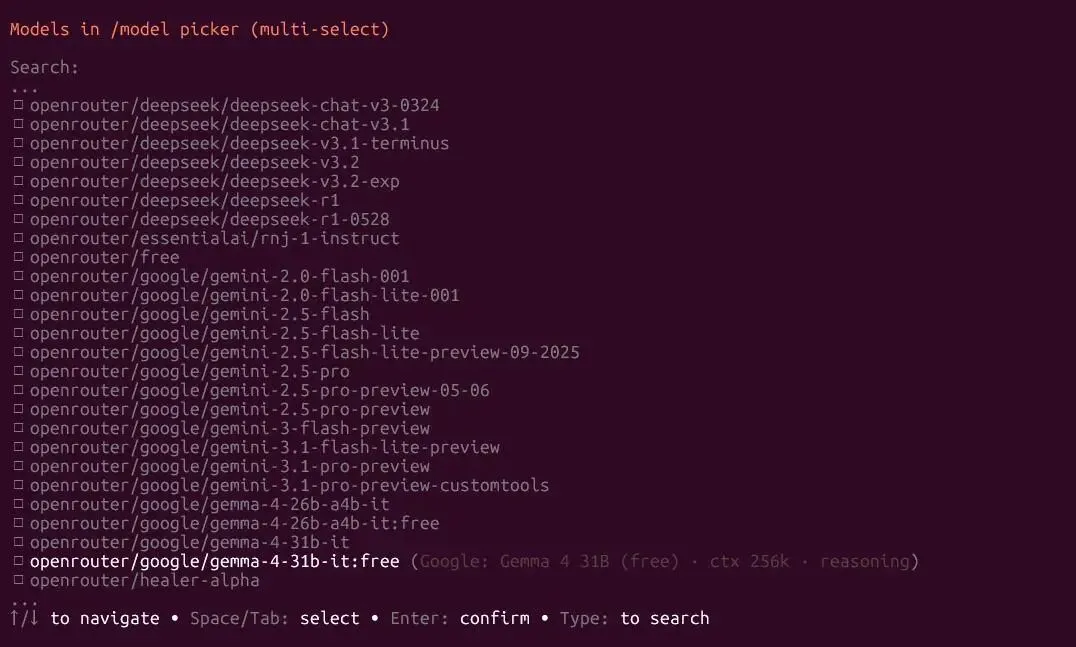
Google DeepMind 于 2026 年 4 月 2 日发布的开源旗舰稠密大模型,主打超强推理、256K 超长上下文、原生多模态,被称为 “同参数最强开源模型”,Apache 2.0 可商用,推理能力拉满(Thinking Mode),原生多模态(文本 + 图像)
-
任意顺序混合图文输入,支持高分辨率 / 不规则比例图像 -
视觉理解比肩闭源模型,文档 OCR、图表解析、多图对比能力强
5. 智能路由:openrouter/free
这个最省心。不用自己选模型,系统自动从可用免费模型中挑选最合适的。支持图片理解、工具调用、结构化输出。相当于你付一份时间,享受几十个模型的轮询服务。
适合:不想折腾、想开箱即用的用户。
四、和本地部署模型的对比
我知道有人会问:免费云端的,能跟本地部署的比吗?
拿最受欢迎的两个本地部署模型对比一下
Qwen3.6-35b vs Nemotron 3 Super 120B
Qwen3.6-35B是本地部署的热门选择,35B参数MoE架构,实际激活3B,262K上下文,4090上能跑140+ tokens/秒。部署门槛至少一张5060TI 16G才能勉强跑个Q4量化版,模型文件70G(量化后20GB左右)。
Nemotron 3 Super则是AIME2026数学基准在免费模型里排第一梯队,120B激活12B的MoE,上下文同样262K,支持工具调用。关键差异在于:你不需要买显卡,还不要电费。我的实际体验,写代码、跑推理任务,Nemotron 3 Super响应质量完全超越本地Qwen3.6-35B
单纯看参数和benchmark,这些免费模型就比本地热门型号强太多。
Qwen3.6 27b vs MiniMax M2.5
2026 年 4 月 22 日 阿里开源的一款 27B 稠密(Dense)多模态大模型,主打小参数、旗舰级智能体编程、本地可部署
MiniMax M2.5这个大模型都知道,国内团队做的,中文对话自然度很好。写头条号文章、微信朋友圈文案、日常聊天,内容创作场景完美,代码能力弱也很能打。
再看其它的
速度方面,本地部署Qwen3.6-35B在4090上能跑到140+ tokens/秒。OpenRouter免费模型取决于服务器负载,高峰期可能慢一些。不过平心而论,如果不是跑批量任务,日常聊天写文章的速度也非常快。
隐私方面,本地确有优势,数据不出机器,敏感场景更安心。但如果只是日常使用、写写文章、撸撸代码,OpenRouter作为老牌聚合平台,数据政策还算透明,何况咱一个平头老百姓早也没啥隐私了,但银行卡密码啥的可别乱说。
成本方面,这就是关键了
本地部署35B级别模型,硬件门槛至少一张5060TI 16G或4090 24G。光是显卡就上万了,不少朋友为了本地部署大模型还买了苹果电脑,搞得苹果卖断货,加上电费、维护成本、折腾的时间精力……
OpenRouter免费模型:零硬件成本,零电费,注册即用不折腾。
我个人现在的做法是:主力用OpenRouter免费的owl-alpha、MiniMax M2.5模型做日常工作,只有涉及敏感数据时才切本地大模型。
五、几个注意事项
免费模型有速率限制,OpenRouter免费层目前是每分钟20次请求、每天50次调用的上限。日常对话完全够用,但如果跑批量任务可能不够,如果你舍得充值10美元则可以提升到每天1000次调用,没有焦虑了。
偶尔会遇到高峰期排队。免费模型的服务器资源是共享的,用的人多了响应会慢一点。换个时间段或者换一个免费模型轮换着用,体验会好很多。
注意免费模型的版本更新。OpenRouter上的:free后缀模型会不定期更新版本,有时候模型能力会有波动。如果发现某个模型突然变菜了,试试免费的智能路由(openrouter/free),或者换个免费模型。
别把鸡蛋放一个篮子里。我一般配置两到三个免费模型,主模型排队了自动切备用。OpenClaw支持多provider配置,设置起来不复杂,hermes模型切换就更简单。
说到底,大模型这东西,够用就行。除非你对隐私有极致要求,或者网络环境不稳定,否则真没必要每个人都在家养一张4090当暖气。
OpenRouter免费模型 + OpenClaw/Hermes这套组合,零成本体验120B级别的大模型能力。折腾本地部署的时间,不如多写两篇文章、多剪两个视频。
当然,本地部署的魅力在于折腾本身。如果你是我这种享受装机乐趣的人,那另说。但如果你的目标是让AI帮你干活,而不是成为电脑维护师傅——
先试免费的吧,注册两分钟的事。
