 夜雨聆风
夜雨聆风





5大Agent记忆框架终极对比:OpenClaw、Hermes Agent、Codex、Claude Code、OpenCode 谁最会“记住你”?
5 大 Agent 记忆框架对比报告
1. 核心结论
五个框架的“记忆”并不是同一种能力。它们大体可以分成三类:
-
1. 明文文件型记忆:OpenClaw 最典型,以 MEMORY.md、每日memory/YYYY-MM-DD.md、DREAMS.md形成可审阅、可编辑、可回滚的记忆系统。 -
2. 长期代理型记忆:Hermes 更像一个长期运行的个人 / 团队代理,记忆、会话历史、技能和用户模型相互耦合,强调内建学习循环。 -
3. 工程上下文型记忆:Codex、Claude Code、OpenCode 更贴近软件工程工作流;它们把项目规则、长期偏好、最近工作上下文、技能定义拆成不同载体,并通过会话加载、后台总结或按需调用来保持连续性。
一个非常关键的差异是:OpenClaw、Codex、Claude Code 都明确区分“规则 / 指令”和“回忆 / 学习”;Hermes 把记忆、技能、会话史与用户模型高度融合;OpenCode 官方核心更轻,长期持久记忆更多依赖生态插件扩展。

2. OpenClaw:Markdown 工作区记忆,强调透明与可审阅
2.1 官方记忆结构
OpenClaw 官方文档明确说明:OpenClaw 通过把记忆写入 agent 工作区中的 Markdown 文件来记住事情;模型只会“记得”保存到磁盘中的内容,不存在隐藏状态。其核心文件包括:
-
• MEMORY.md:长期记忆,保存持久事实、偏好与决策;每次私聊会话启动时加载。 -
• memory/YYYY-MM-DD.md:每日工作层笔记,用于记录运行上下文、观察、会话摘要与原始上下文;今天与昨天的笔记会自动加载。 -
• DREAMS.md:可选的 Dream Diary / dreaming sweep 摘要,作为人工审阅面,用于历史回放、整理与长期记忆晋升。 -

2.2 记忆流转方式
OpenClaw 的典型流转可以概括为:对话与观察 -> 日常笔记 -> 检索 / 回溯 -> dreaming / 深度整理 -> MEMORY.md -> 下次会话启动加载
其中,日常笔记不是每次都完整注入模型上下文,而是可通过 memory_search、memory_get 等方式检索;长期稳定信息再被提炼进 MEMORY.md。这使 OpenClaw 的记忆更像“可审阅的工作日志 + 精炼长期档案”。
2.3 优点与边界
优点是透明、可编辑、可审计、易迁移;缺点是自动化能力依赖 agent 自身和工作流设计,用户需要接受“记忆就是文件”的治理方式。对于重视可控性、可解释性、人工校验的个人代理或团队代理,OpenClaw 的设计非常直接。
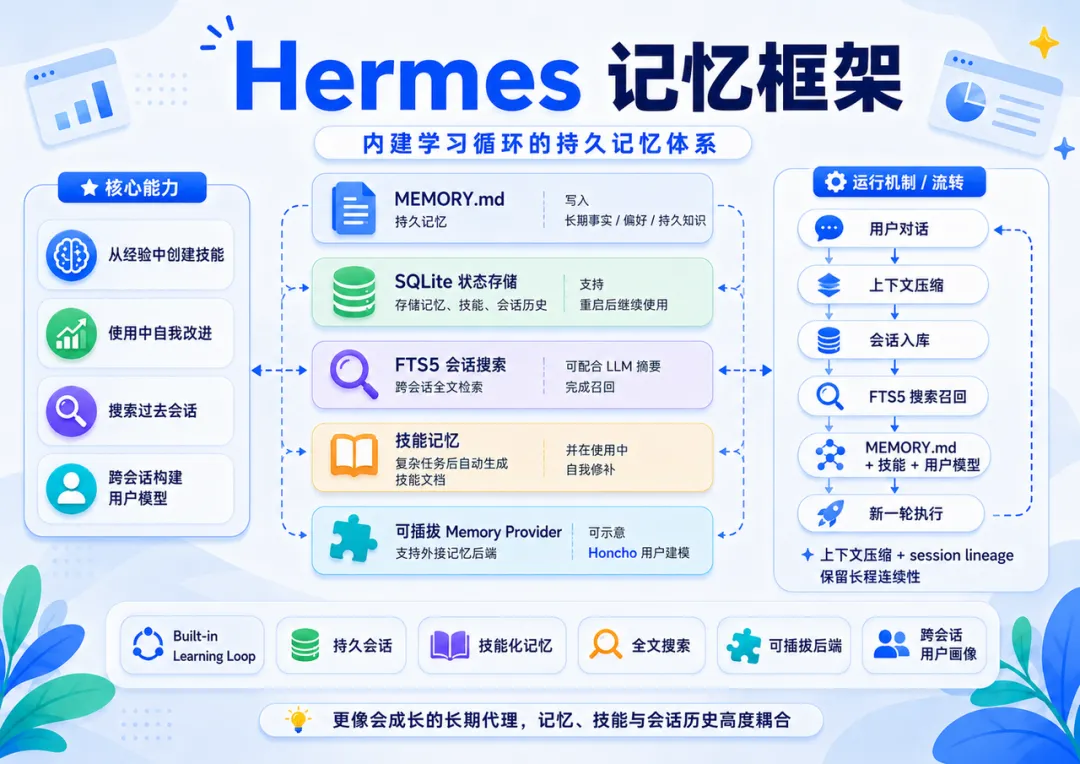
3. Hermes Agent:内建学习循环,记忆、技能与会话历史高度耦合
3.1 官方定位
Hermes Agent 官方信息把它定位为“会自我改进的 AI Agent”,强调内建学习循环:它可以从经验中创建技能,在使用中改进技能,搜索过去会话来补上下文,并跨会话构建用户模型。
3.2 记忆组成
根据 Hermes 官方仓库 / 文档说明,其记忆能力可拆成以下几层:
-
• 持久记忆:agent 维护的事实与偏好会写入 MEMORY.md,并通过周期性提醒沉淀长期知识。 -
• SQLite 状态存储:记忆、技能、会话历史可以持久化到 SQLite,支持重启后继续使用。 -
• FTS5 会话搜索:支持跨会话全文检索,并可结合 LLM 摘要完成召回。 -
• 技能记忆:复杂任务后自动生成可复用 skill 文档,并在使用过程中修补旧技能。 -
• 可插拔 Memory Provider:内建记忆层可以通过 memory-provider 插件扩展,官方文档中提到 Honcho 等后端 / 用户建模能力。 -
• 上下文压缩与 session lineage:在长对话接近上下文限制时压缩中间消息,并通过 SQLite 中的 parent_session_id 链保留会话血缘。
3.3 优点与边界
Hermes 的优势在于“成长性”:它不是只保存几条偏好,而是把会话、技能、用户模型和长期记忆组织成持续演化的代理系统。其边界是系统复杂度更高,记忆治理不如纯 Markdown 文件直观;适合长期运行、自主演化、多轮复杂任务的代理,而不是只想要轻量规则文件的场景。
4. Codex:本地 memories + AGENTS.md 规则分层
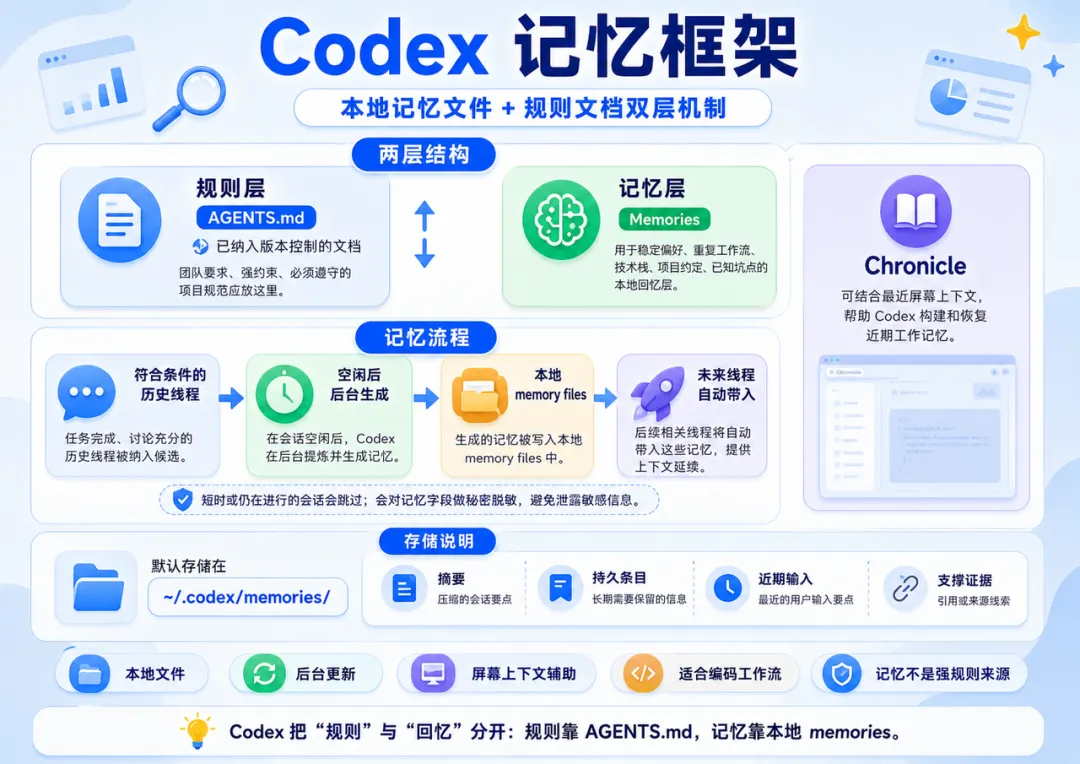
4.1 官方记忆机制
Codex 官方 Memories 文档说明:启用 Memories 后,Codex 可以把符合条件的历史线程中的有用上下文转换成本地 memory files。Codex 会跳过仍在进行、短时或不适合总结的会话,并在后台更新记忆;同时会对生成的记忆字段做 secrets redaction,避免把敏感信息写入记忆。
4.2 规则与记忆分离
Codex 的一个核心原则是:
-
• 必须遵守的团队要求、项目规则、强约束应放在 AGENTS.md或已纳入版本控制的文档中。 -
• Memories 是本地回忆层,用于稳定偏好、重复工作流、技术栈、项目约定和已知坑点。
这意味着 Codex 官方并不建议把 memories 当成强规则来源。规则是项目治理层,记忆是便利的本地召回层。
4.3 Chronicle 的作用
Codex Chronicle 官方说明强调,它可以利用近期屏幕上下文帮助 Codex 构建和恢复最近工作记忆。它主要解决“我现在看到的界面 / 代码 / 工作上下文是什么”这类近期上下文恢复问题,而不是替代项目规则文档。
4.4 存储与适用场景
Codex 官方文档说明,主记忆文件默认位于 ~/.codex/memories/,包含摘要、持久条目、近期输入与支撑证据等。Codex 的记忆更适合工程化编码工作流:减少重复解释技术栈、偏好、项目约定和近期工作背景。
5. Claude Code:CLAUDE.md + Auto memory 双系统
5.1 官方双系统
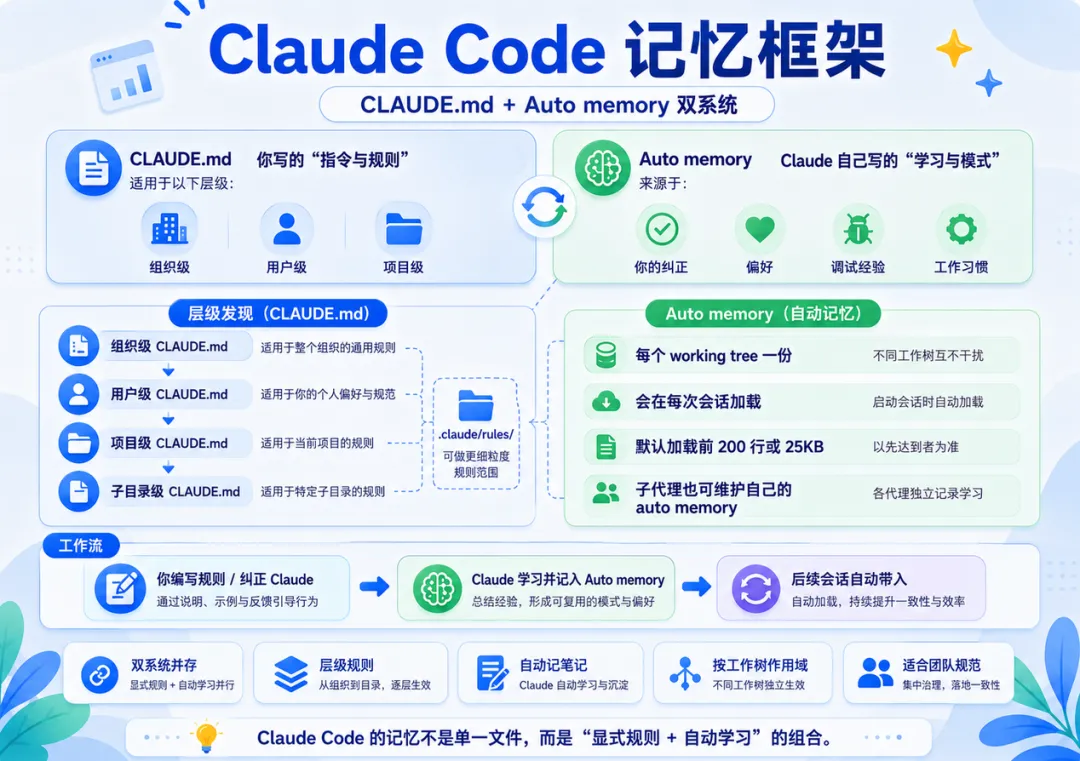
Claude Code 官方 memory 文档明确提出两个互补系统:
-
• CLAUDE.md:用户写的长期指令、规则与项目上下文。 -
• Auto memory:Claude 根据用户纠正、偏好和工作模式自动写下的学习笔记。
官方文档同时强调,这两者都会在每次会话开始时加载,但 Claude 会把它们作为上下文,而不是不可违背的强制配置。
5.2 CLAUDE.md 的层级机制
CLAUDE.md 可存在于组织级、用户级、项目级和子目录级位置。Claude Code 会沿目录树发现这些文件,并将更接近当前工作目录的规则放在后面,从而形成更具体的上下文。.claude/rules/ 还能用于更细粒度的规则范围控制。
5.3 Auto memory
Auto memory 是按 working tree 作用域维护的自动学习记忆。官方文档说明它会在每次会话加载,默认加载前 200 行或 25KB;子代理也可以维护自己的 auto memory。用户要求 Claude “记住某事”时,Claude 会保存到 auto memory。
5.4 优点与边界
Claude Code 的优势是层级规则清晰、团队规范落地能力强,同时保留自动学习能力。边界是:记忆仍是上下文,不是强制策略引擎;团队关键规则仍应写入明确的 CLAUDE.md 或治理文档中。
6. OpenCode:轻核心,上下文与技能框架,长期记忆靠生态增强
6.1 官方核心
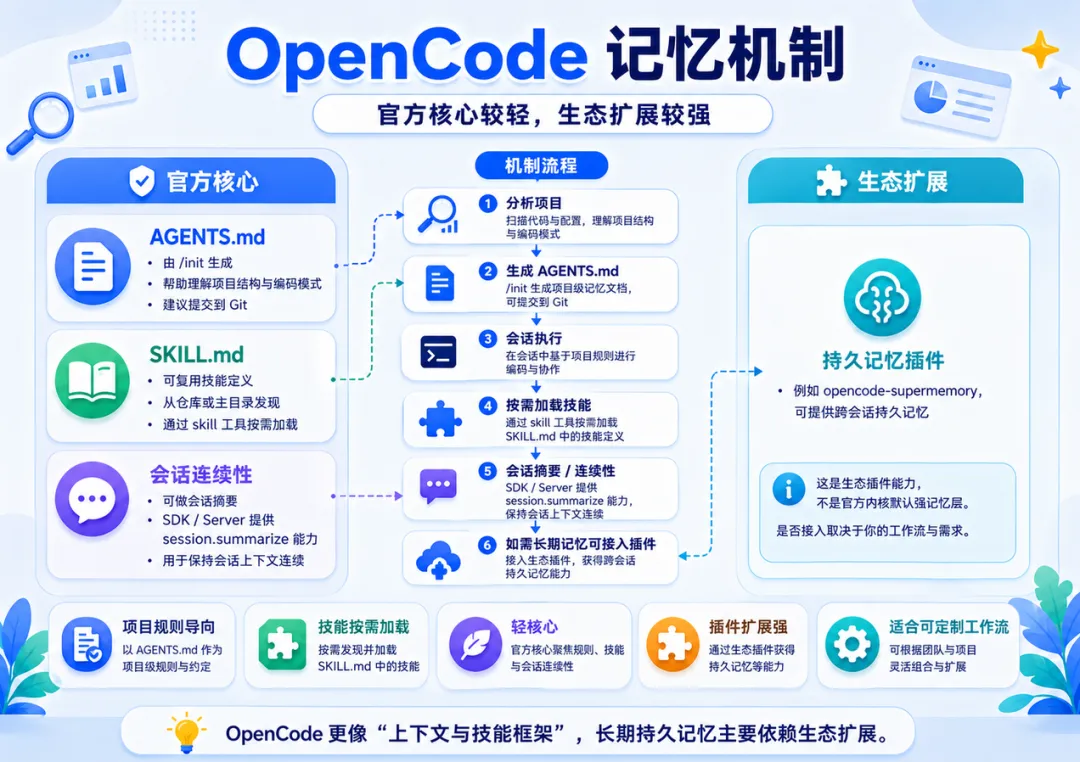
OpenCode 官方文档强调项目初始化与规则文件:运行 /init 后,OpenCode 会分析项目并创建 AGENTS.md,帮助理解项目结构与编码模式,并建议提交到 Git。OpenCode 还支持 SKILL.md 形式的 Agent Skills:技能可从仓库或用户主目录发现,并通过原生 skill 工具按需加载。
6.2 会话与摘要能力
OpenCode SDK / Server 文档提供 session.summarize 能力,可用于会话摘要和上下文连续性。它说明 OpenCode 有会话管理与摘要接口,但这并不等同于一个官方默认的、完整长期持久记忆层。
6.3 生态扩展
OpenCode 官方生态页列出了 opencode-supermemory 等插件,用于跨会话持久记忆。这应被理解为生态能力,而不是官方内核默认记忆层。因此,OpenCode 更像“项目规则 + 技能按需加载 + 会话连续性 + 插件扩展”的组合。
6.4 优点与边界
OpenCode 的优势是轻量、开放、可组合、容易围绕团队工作流定制;边界是长期记忆能力需要根据具体插件和团队配置来补齐。
7. 横向对比
|
|
|
|
|
|
|
|
|
MEMORY.md
DREAMS.md |
MEMORY.md
|
~/.codex/memories/ |
CLAUDE.md
|
AGENTS.md
SKILL.md、会话摘要;长期记忆多依赖插件 |
|
|
|
|
AGENTS.md
|
CLAUDE.md
.claude/rules/ |
AGENTS.md
SKILL.md |
|
|
|
|
|
|
|
|
|
memory_search
memory_get,Markdown 可人工回溯 |
|
|
|
|
|
|
|
|
|
|
SKILL.md 是核心扩展点 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8. 选型建议
-
• 最透明、最方便人工审阅:OpenClaw。 适合你想把 agent 记忆作为“可读、可改、可提交、可审计”的项目资产来管理。 -
• 最像长期成长型代理:Hermes。 适合长期驻留、跨平台消息入口、多轮复杂任务、自主沉淀技能与用户画像的系统。 -
• 最适合工程化编码回忆:Codex。 适合围绕代码仓库持续工作,用本地 memories 降低重复解释成本,用 AGENTS.md管强规则。 -
• 最适合工程规则协作:Claude Code。 适合团队规范、多层规则、个人偏好与自动学习并存的代码协作场景。 -
• 最适合可扩展工作流:OpenCode。 适合你要自己组合 AGENTS.md、SKILL.md、SDK / Server、插件生态,搭建可定制 agent 工作流。 -
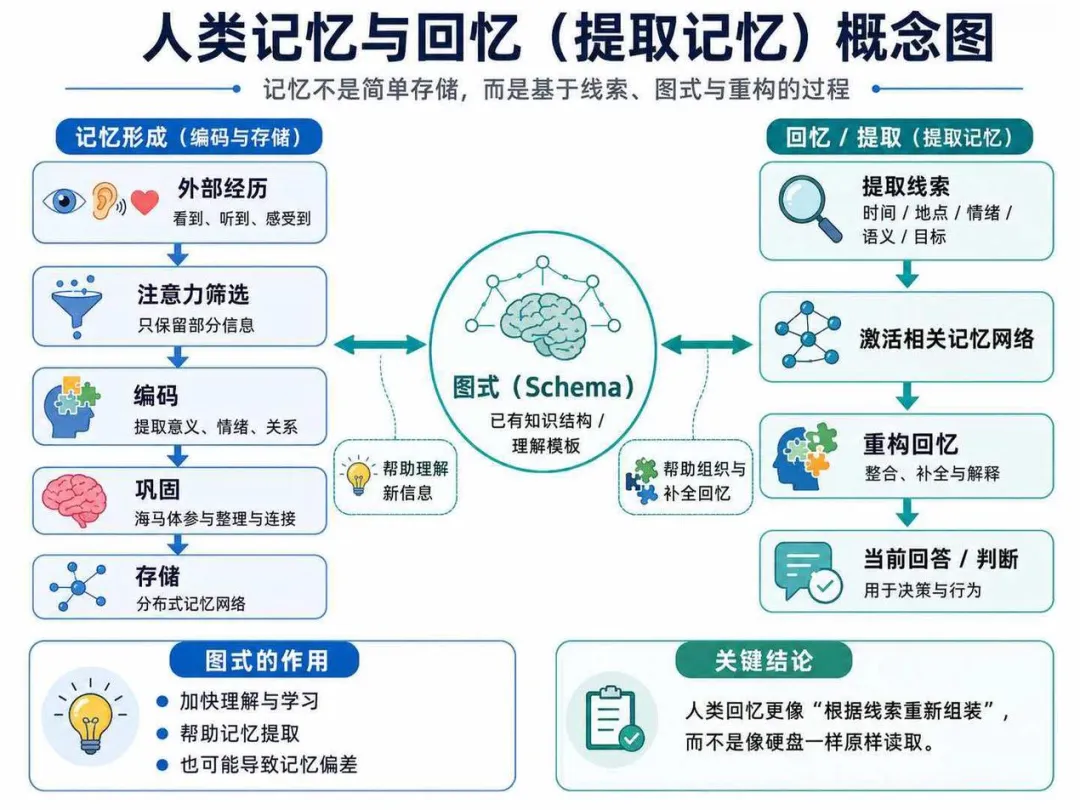
9. 对“可迁移智能体”的启发
如果目标是构建可迁移智能体,不建议只问“有没有记忆功能”,而应拆成五个问题:
-
1. 记忆是否可导出? Markdown / SQLite / 本地文件比黑盒云记忆更利于迁移。 -
2. 规则与记忆是否分层? 强规则应可版本控制,偏好和经验可自动沉淀。 -
3. 是否支持跨会话检索? 仅启动时加载文件不够,长期代理需要检索、摘要、回放能力。 -
4. 是否能沉淀技能? 可迁移智能体不只是记事实,还要把经验沉淀成可复用 skill。 -
5. 是否允许人工审阅和修正? 记忆会污染行为,必须能查看、编辑、删除、回滚。
从这个角度看,一个更稳妥的可迁移 agent 记忆设计可以采用:
规则层(AGENTS.md / CLAUDE.md) + 长期记忆层(MEMORY.md) + 工作日志层(daily notes) + 检索层(FTS / vector / keyword) + 技能层(SKILL.md) + 审阅层(DREAMS / curator)
这也解释了为什么这些框架虽然实现不同,但都在向“显式规则 + 可检索回忆 + 技能沉淀 + 人工治理”的方向靠近。
小米招聘内推
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
交个朋友,进AI交流群

每天分享最新 小米AI 内部培训资料
关注公众号-私信回复:
ai资料:获取AI完整资料包
全家桶:获取激活码
小龙虾:获取安装教程
md:获取激活码
关注公众号