 夜雨聆风
夜雨聆风





大模型如何调用工具?揭秘 AI IDE 背后的代码执行机制
当你在 Cursor 里敲下”帮我重构这段代码”,或者在 CodeBuddy 里说”生成一个 HTTP 服务器”,几秒后代码就自动写好了——这背后到底发生了什么?
大模型是怎么”懂”你要干啥的,又是怎么把想法变成真正能跑的代码的?
今天咱们就来拆解一下这套机制。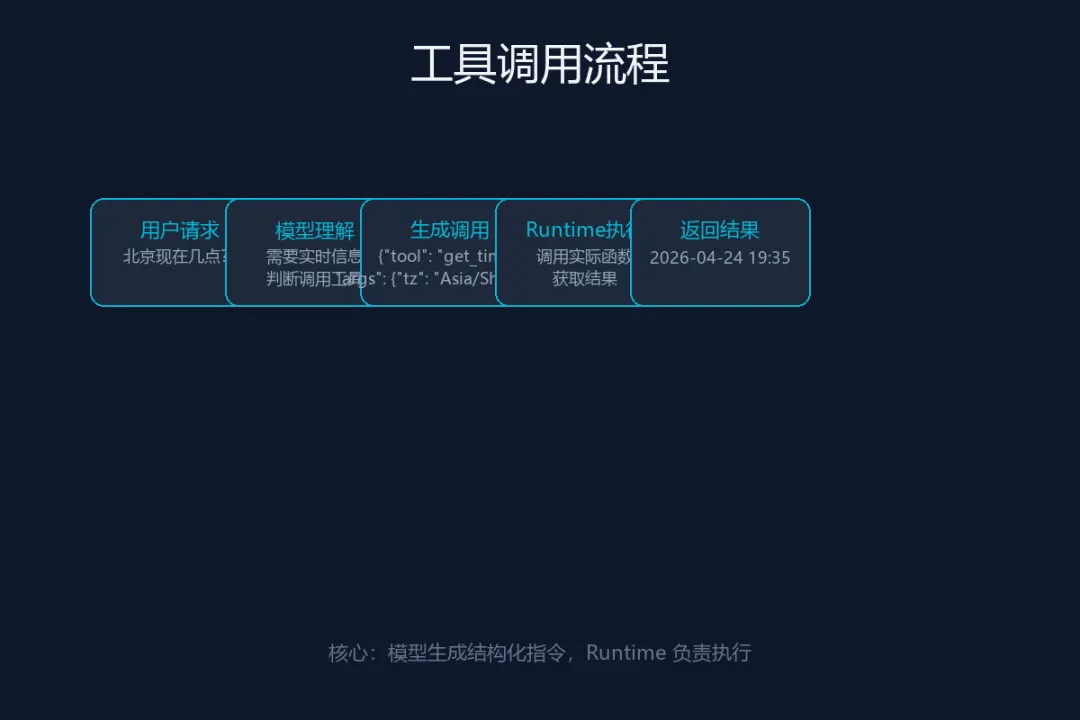
从聊天到行动:工具调用的必要性
早期的 AI 助手只会”说话”——你问它问题,它给你文字回答。
但说实话,光能聊天用处有限。
你问”今天北京天气怎么样?”,它可能告诉你”我不知道,我的知识截止到 2023 年”,这就很尴尬了。
真正让 AI 变得有用的转折点,是让它能调用工具。
想象一下,如果 AI 不仅能理解你的问题,还能:
-
查询实时天气 API -
执行 Python 脚本 -
读写文件系统 -
调用数据库 -
发送网络请求
那它就不只是个聊天机器人,而是个真正的数字助手。
这就是 Function Calling(函数调用)技术要解决的核心问题。
Function Calling:让模型学会”使用工具”
基本原理
Function Calling 的核心思想很简单:在给模型的提示词里,不仅告诉它对话历史,还告诉它”有哪些工具可以用”。
模型收到用户请求后,不是直接生成回答,而是先判断:
-
这个问题需要调用工具吗? -
如果需要,该调用哪个工具? -
工具的参数应该填什么?
然后模型会输出一段结构化的工具调用指令(通常是 JSON 格式),而不是普通文本。
一个简单的例子
用户问:”北京现在几点?”
模型内部的判断过程:
-
需要实时信息 → 不能直接回答 -
有个 get_current_time工具可以用 -
参数需要 timezone,北京是Asia/Shanghai
于是模型输出:
{"tool_name": "get_current_time","parameters": {"timezone": "Asia/Shanghai" }}注意,这时候模型并没有执行工具,它只是告诉系统”我要调这个函数,参数是这些”。
真正执行工具的是背后的 Runtime(运行时环境)。
AI IDE 的工具链:从意图到执行
现在咱们把视角拉到 Cursor、CodeBuddy、Windsurf、Codex 这类 AI IDE 上。
它们的工具调用比简单的天气查询复杂得多,因为涉及到代码生成、文件读写、终端命令执行等高危操作。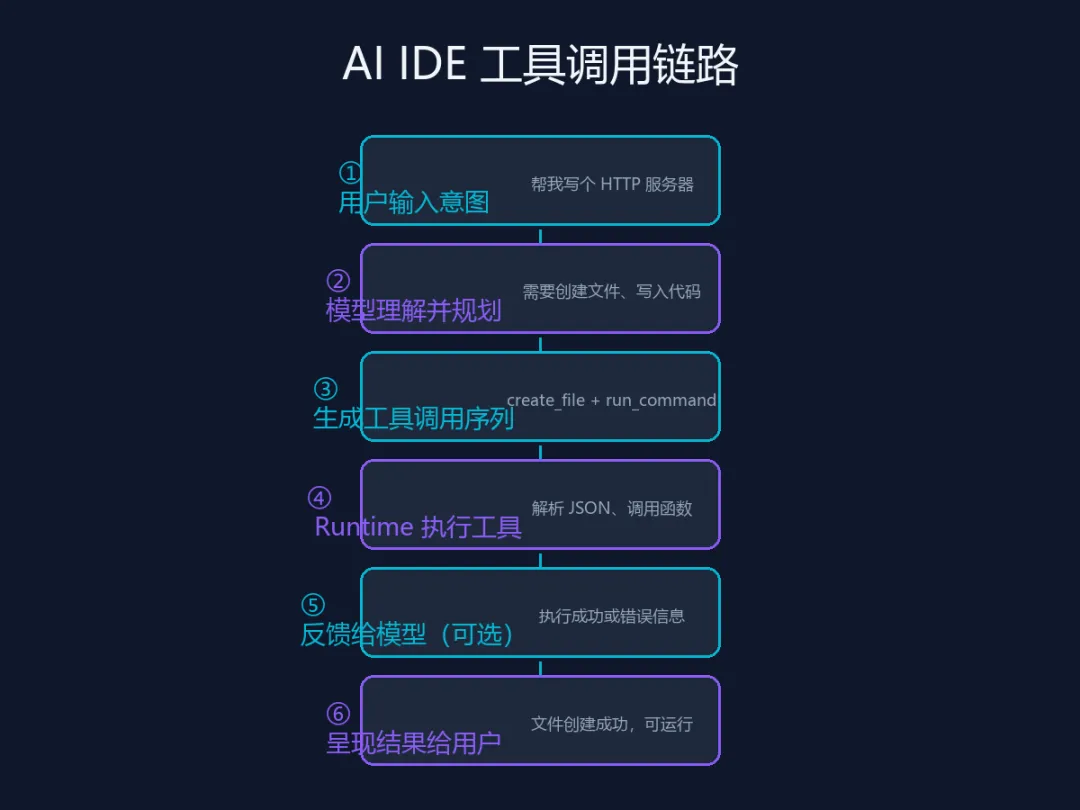
完整的调用链路
一个典型的流程是这样的:
1. 用户输入意图
用户:”帮我写个 HTTP 服务器,监听 8080 端口”
2. 模型理解并规划
模型分析后认为需要:
-
创建一个 Go 文件 -
写入服务器代码 -
可能需要运行 go mod init
3. 生成工具调用序列
模型输出类似这样的指令(伪代码):
[ {"tool": "create_file","args": {"path": "main.go","content": "package main\n\nimport ..." } }, {"tool": "run_command","args": {"command": "go mod init example" } }]4. Runtime 执行工具
这是关键部分。IDE 的 Runtime 会:
-
解析模型输出的 JSON -
逐个调用对应的工具函数 -
收集执行结果(成功/失败、输出内容)
5. 反馈给模型(可选)
如果执行出错(比如文件已存在),Runtime 会把错误信息返回给模型,模型再调整策略重试。
6. 呈现结果给用户
最终用户看到的是:文件创建成功,代码已写入,可以直接运行了。
整个链路可以简化为:用户意图 → 模型规划 → 工具调用序列 → Runtime 执行 → 反馈调整 → 结果呈现。
代码示例:一个简易的工具调用实现
来看看如果自己实现,代码大概是什么样。
这里用 Go 写个极简版本。
package mainimport ("encoding/json""fmt""os""os/exec")// 工具调用的结构type ToolCall struct { Tool string`json:"tool"` Args map[string]interface{} `json:"args"`}// 模拟模型输出的工具调用funcparseModelOutput(output string)([]ToolCall, error) {var calls []ToolCall err := json.Unmarshal([]byte(output), &calls)return calls, err}// 执行工具调用funcexecuteTool(call ToolCall)(string, error) {switch call.Tool {case"create_file": path := call.Args["path"].(string) content := call.Args["content"].(string) err := os.WriteFile(path, []byte(content), 0644)if err != nil {return"", fmt.Errorf("创建文件失败: %v", err) }return fmt.Sprintf("文件 %s 创建成功", path), nilcase"run_command": command := call.Args["command"].(string) cmd := exec.Command("sh", "-c", command) output, err := cmd.CombinedOutput()if err != nil {return"", fmt.Errorf("命令执行失败: %v, 输出: %s", err, output) }returnstring(output), nildefault:return"", fmt.Errorf("未知工具: %s", call.Tool) }}funcmain() {// 模拟模型输出的工具调用 JSON modelOutput := `[ { "tool": "create_file", "args": { "path": "hello.go", "content": "package main\n\nfunc main() {\n\tfmt.Println(\"Hello\")\n}" } }, { "tool": "run_command", "args": { "command": "go run hello.go" } } ]`// 解析工具调用 calls, err := parseModelOutput(modelOutput)if err != nil { fmt.Printf("解析失败: %v\n", err)return }// 依次执行for i, call := range calls { fmt.Printf("执行工具 %d: %s\n", i+1, call.Tool) result, err := executeTool(call)if err != nil { fmt.Printf(" 错误: %v\n", err) } else { fmt.Printf(" 结果: %s\n", result) } }}仅供参考,实际上不一定是 go,有可能是 py 或 shell
这个例子虽然简陋,但展示了核心逻辑:
-
模型生成结构化的工具调用指令 -
Runtime 解析 JSON -
根据工具名分发到具体实现 -
返回执行结果
真实的 IDE 会复杂得多——要处理并发、权限控制、沙箱隔离、错误重试等等,但本质就是这套流程。
安全边界:代码执行的风险与防护
让 AI 直接执行代码听起来很酷,但风险也显而易见。万一模型生成了 rm -rf /,或者访问了不该访问的文件,怎么办?
沙箱隔离
成熟的 AI IDE 都会把代码执行限制在沙箱环境里:
-
限制文件系统访问(只能读写特定目录) -
限制网络访问(阻止未授权的外部请求) -
资源限制(CPU、内存、执行时间)
比如 Docker 容器、WebAssembly 运行时,都是常见的沙箱方案。
用户确认机制
对于高危操作(删除文件、修改配置、执行 shell 命令),很多工具会先暂停,展示将要执行的内容,等用户点击”确认”后再执行。
这就是为什么你在用 Cursor 时,有时会看到一个弹窗说”即将执行以下命令,是否继续?”
权限分级
 不是所有工具都能随便调。可以给工具分级:
不是所有工具都能随便调。可以给工具分级:
-
安全级:读取文件、搜索代码(无需确认) -
普通级:创建文件、修改代码(需要确认) -
高危级:删除文件、执行 shell(必须手动授权)
这种分级机制确保了 AI 在自主执行和用户控制之间找到平衡点。
Cursor、Codebuddy 们到底做了啥?
现在咱们把视角拉回到具体的产品。
Cursor
Cursor 基于 VS Code 魔改,核心是在编辑器里集成了一个 Agent 系统:
-
用户在聊天框输入需求 -
背后的模型(通常是 GPT-4 或 Claude)生成工具调用 -
Runtime 在受限的环境里执行(读写项目文件、运行终端命令) -
结果实时回显到编辑器
Cursor 的特色是上下文感知——它能读取你当前打开的文件、光标位置、项目结构,这些都会作为额外信息传给模型,让生成的代码更精准。
Windsurf
Windsurf(Codeium 出品)思路类似,但更强调流式交互。
它的 Agent 不是一次性生成所有代码,而是边生成边执行边调整,有点像”边开车边修路”。
这样的好处是响应快,用户能更早看到进展;但对工具调用的鲁棒性要求更高,因为中间状态可能不完整。
OpenClaw/Trace
这类工具更偏向多轮协作的 Agent。它不只是执行单次任务,还会:
-
记住历史对话 -
主动提问澄清需求 -
在后台运行长时间任务 -
跨文件、跨项目协调
工具调用的复杂度更高,可能涉及几十个工具的组合使用(搜索、分析、重构、测试、部署)。
常见问题
Q1. 模型会不会”乱调”工具?
早期确实会。
模型可能把不该调的工具调了,或者参数填错。解决办法:
-
在提示词里明确工具的使用场景和限制 -
训练时加入更多工具调用的示例 -
Runtime 层做参数校验和安全检查
现在主流模型(GPT-4、Claude 3.5)的工具调用准确率已经挺高了,大部分情况不需要人工干预。
Q2. 工具调用会不会很慢?
相比纯文本生成,确实会慢一些,因为:
-
模型要先输出工具调用(一次推理) -
Runtime 执行工具(I/O 耗时) -
模型再根据结果生成回复(又一次推理)
优化方向:并行执行多个工具、缓存中间结果、预测性加载上下文等。
Q3. 能不能自己给 AI 加工具?
完全可以!
大部分 AI 框架都支持自定义工具。
比如 LangChain、AutoGPT、OpenAI 的 Function Calling API 都提供了注册工具的接口。
你只需要定义工具的名称、描述、参数类型,然后实现具体逻辑,模型就能学会调用它。
Q4. 工具调用和传统 API 调用有啥区别?
传统方式:你写代码显式调用 API(requests.get(...))
工具调用方式:你告诉模型”有这么个 API”,模型自己决定要不要调、怎么调
关键区别是决策权交给了模型。这让交互更自然,但也意味着你要信任模型的判断。
小结
大模型的工具调用,本质上是把”理解”和”执行”两个能力连接起来。模型负责理解意图和生成调用指令,Runtime 负责真正执行,两者配合完成从需求到结果的闭环。
Cursor、CodeBuddy 这类 AI IDE 之所以好用,不是因为模型特别聪明(虽然确实在变聪明),而是因为它们设计了一套合理的工具生态:哪些操作该暴露、哪些该限制、怎么让模型高效调用,这些工程细节决定了最终体验。
说到底,工具调用就是让 AI 从”能说会道”变成”能干实事”。而这,才是 AI 真正有用的开始。
如果大家在实际使用 Cursor、CodeBuddy 或其他 AI IDE 时遇到了工具调用相关的问题(比如执行失败、权限报错、响应慢等),或者对某个具体环节的实现原理感兴趣,欢迎在评论区交流~~~
声明:文中涉及的产品特性和技术细节基于公开资料和实际体验总结,具体实现可能因版本更新有所变化。代码示例仅供演示原理,生产环境需要更完善的错误处理和安全机制。