 夜雨聆风
夜雨聆风





AI笔记15-LeNet模型之手势图像识别
-
手势图像数据集介绍 -
手势图形识别项目流程 -
小结
通过网盘分享的知识:手势识别
链接: https://pan.baidu.com/s/5IFnxOYrqWSPuV-DVuAtLCg

├── train # 训练集├── G0 # 手势0├── IMG_1118.jpg # 手势0的图片├── ...├── G1 # 手势1├── IMG_1119.jpg├── ...├── ...├── G9 # 手势9├── test # 测试集├── G0├── ...├── G9
二、手势图形识别项目流程
-
数据预处理
如何记录标签数据和图片数据:
import osimport randomimport numpy as npimport cv2def load_img_label(root_dir):"""递归遍历 root_dir 下的所有子文件夹,将每张图片的完整路径和其所属的文件夹名(标签)分别存入两个列表并返回。"""img_paths = [] # 存放所有图片的完整路径labels = [] # 存放每张图片对应的标签(文件夹名)# 遍历 root_dir 下的直接子项(包括文件夹和文件)for item in os.listdir(root_dir):item_path = os.path.join(root_dir, item)# 忽略隐藏文件或文件夹(如 .DS_Store)if item.startswith('.'):continue# 只处理文件夹(因为我们期望子文件夹代表不同类别)if os.path.isdir(item_path):# 遍历该类别文件夹中的每个文件for img_file in os.listdir(item_path):img_full_path = os.path.join(item_path, img_file)# 只把文件(图片)加进去,忽略子文件夹内的子文件夹(如果有)if os.path.isfile(img_full_path):img_paths.append(img_full_path)labels.append(item) # 标签就是文件夹名,如 'G0'return img_paths, labels# 1. 基础路径root = "gestures"# 2. 加载训练集train_root = os.path.join(root, 'train')train_img, train_label = load_img_label(train_root)# 3. 加载测试集test_root = os.path.join(root, 'test')test_img, test_label = load_img_label(test_root)# 4. 从训练集标签中提取所有类别(去重,排序)label_list = list(set(train_label)) # 原代码中变量名为 lable_list,保留拼写label_list.sort() # 按字母/数字顺序排列,保证可重复性# 5. 构建正向和反向的映射字典label2idx = {label: idx for idx, label in enumerate(label_list)}idx2label = {idx: label for idx, label in enumerate(label_list)}# 6. 打印查看映射关系print(label2idx)print(idx2label)
1. 导入必要的库
-
os用于处理文件和目录路径。
-
random、numpy、cv2在后续训练中可能会用到,但当前数据预处理阶段尚未使用,保留以备后续扩展。
2. 定义加载函数 load_img_label(root_dir)
原函数名为 load_img_label,参数名为 train_root,但实际功能通用,因此改为 root_dir 更清晰。
函数内部逻辑:
-
创建两个空列表
img_paths和labels,分别存放图片路径和对应的标签。 -
使用
os.listdir(root_dir)获取根目录下的所有条目(包括文件夹和隐藏文件)。 -
跳过隐藏条目:
if item.startswith('.')排除.DS_Store等系统文件,避免报错。 -
仅处理文件夹:
if os.path.isdir(item_path)确保只进入类别文件夹(如G0、G1……)。 -
遍历该类别文件夹下的所有文件:
for img_file in os.listdir(item_path)。 -
构造完整图片路径:
img_full_path = os.path.join(item_path, img_file)。 -
确保是文件:
if os.path.isfile(img_full_path)忽略可能存在的子文件夹。 -
添加到列表:
img_paths.append(img_full_path)和labels.append(item)。注意这里的item就是类别文件夹名(如'G0'),作为标签。 -
最后返回两个列表。
3. 加载训练集和测试集
root = "gestures"train_root = os.path.join(root, 'train')train_img, train_label = load_img_label(train_root)test_root = os.path.join(root, 'test')test_img, test_label = load_img_label(test_root)
-
gestures,然后分别拼接train和test子目录。 -
调用同一个函数,得到训练集的图片路径列表
train_img和标签列表train_label,测试集同理。
4. 构建标签与索引的映射
label_list = list(set(train_label)) # 原码中变量名为 lable_listlabel_list.sort()
-
set(train_label) 去重,得到所有出现过的标签(例如
{'G0','G1',...,'G9'})。
-
转为列表并排序,保证每次运行得到的顺序一致(字典构建的索引顺序固定)。
5. 构建字典映射
label2idx = {label: idx for idx, label in enumerate(lable_list)}idx2label = {idx: label for idx, label in enumerate(lable_list)}
-
enumerate 为每个类别分配一个整数索引(从0开始)。
-
label2idx:标签 → 索引,例如{'G0':0, 'G1':1, ...}。 -
idx2label:索引 → 标签,例如{0:'G0', 1:'G1', ...}。
如何将图片和标签数据打包成适合训练的格式:
import torchfrom torch.utils.data import Datasetimport cv2import numpy as npclass GesturesDataset(Dataset):"""自定义手势数据集,用于加载图片路径和对应标签,并在 __getitem__ 中完成图像预处理和标签映射。"""def __init__(self, X, y):"""初始化数据集Args:X: list of str, 图片的完整路径列表y: list of str, 对应的原始标签(如 'G0')列表"""self.X = Xself.y = ydef __len__(self):"""返回数据集样本总数"""return len(self.X)def __getitem__(self, idx):"""根据索引 idx 返回一个样本 (image_tensor, label_tensor)"""# 获取图片路径和原始标签img_path = self.X[idx]img_label = self.y[idx]# 1. 读取图像 (cv2 默认 BGR 格式)img = cv2.imread(img_path)# 可选:若图像读取失败,可做保护,此处保持原意不添加额外处理# 2. 将图像缩放到 32x32 像素(注意:cv2.resize 默认使用双线性插值)img = cv2.resize(img, (32, 32))# 3. 将图像转为 numpy 数组(原代码此处多余,因为 cv2 读取后已经是 numpy 数组)# 但为了保持原意,保留该操作(np.array(img) 实际不会改变类型)img = np.array(img)# 4. 数据规范化到 [-1, 1] 区间# - 先将像素值 [0, 255] 缩放到 [0, 1]# - 再通过 (x - 0.5)/0.5 映射到 [-1, 1]img = img / 255.0img = (img - 0.5) / 0.5# 5. 转为 PyTorch 张量,数据类型为 float32img = torch.tensor(img, dtype=torch.float32)# 6. 调整维度顺序:PyTorch 模型期望输入通道在前,即 [C, H, W]# 原图像形状为 [H, W, C],所以需交换维度img = img.permute(2, 0, 1) # 原为 [H, W, C] -> [C, H, W]# 7. 标签转换为数字索引:使用外部的 label2idx 字典label = label2idx[img_label] # 例如 'G0' -> 0label = torch.tensor(label, dtype=torch.long)return img, label
1. 导入必要的库
import torchfrom torch.utils.data import Datasetimport cv2import numpy as np
-
torch和Dataset:用于构建 PyTorch 自定义数据集。 -
cv2:OpenCV,用于读取图像和调整大小。 -
numpy:用于数组操作(虽然 cv2 已返回 numpy 数组,但原代码显式调用了np.array,所以保留)。
2. 类定义 GesturesDataset(Dataset)
继承 torch.utils.data.Dataset,必须实现 __len__ 和 __getitem__ 方法。
3. 初始化方法 __init__(self, X, y)
self.X = X # 保存图片路径列表self.y = y # 保存原始标签列表(字符串,例如 'G0')
4. __len__(self)
返回 len(self.X),即样本总数。假设 X 和 y 长度相同。
5. __getitem__(self, idx) — 核心数据预处理逻辑
步骤 0:获取原始数据
img_path = self.X[idx]img_label = self.y[idx]
根据索引取出路径和原始标签。
步骤 1:读取图像
img = cv2.imread(img_path)-
cv2.imread会以 BGR 顺序的三维 numpy 数组形式读取图像,形状为[H, W, C],像素值范围 0~255。 -
原代码没有处理读取失败的情况(如路径错误),改写也保持原意(后续 resize 时会报错)。
步骤 2:缩放到 32×32
img = cv2.resize(img, (32, 32))-
cv2.resize默认使用双线性插值,目标尺寸为 (宽度, 高度) = (32, 32),因此输出形状为[32, 32, C](通道数不变)。
步骤 3:转换为 numpy 数组
img = np.array(img)-
实际上
img已经是numpy.ndarray,此操作会创建一个副本。原代码这样写可能是为了强调显式转换,我们保留它。
步骤 4:数据归一化到 [-1, 1]
img = img / 255.0 # 从 [0,255] -> [0,1]img = (img - 0.5) / 0.5 # 从 [0,1] -> [-1,1]
-
除以 255:将像素值缩放到 0~1 之间。
-
(img - 0.5) / 0.5等价于2*img - 1,将 0→-1, 0.5→0, 1→1。这是常见的将输入归一化到对称区间的做法,有利于神经网络训练。
步骤 5:转为 PyTorch 张量
img = torch.tensor(img, dtype=torch.float32)-
将 numpy 数组转换为
torch.Tensor,并指定数据类型为torch.float32(即 float)。原代码未指定 device,默认在 CPU 上。
步骤 6:转换维度顺序
img = img.permute(2, 0, 1) # [H, W, C] -> [C, H, W]-
yTorch 的卷积层通常要求输入张量的形状为
(batch, channels, height, width)。每个样本的形状应为(C, H, W)。 -
原始
img的形状是(32, 32, C),通过permute(2, 0, 1)将通道维(索引 2)移到第一维,高度(索引 0)、宽度(索引 1)依次后移。
步骤 7:标签映射为数字并转为张量
label = label2idx[img_label] # 使用外部字典将 'G0' 映射为整数label = torch.tensor(label, dtype=torch.long)
-
label2idx必须在类外部定义好(例如之前预处理代码生成的字典)。假设label2idx = {'G0':0, 'G1':1, ...}。 -
分类任务中标签通常用
torch.long类型(即整型),因为交叉熵损失要求目标为长整型。
步骤 8:返回样本
return img, label返回一个元组,包含处理后的图像张量和标签张量。
-
模型搭建
在上节课我们已经学习到了LeNet网络结构,代码如下:
import torchfrom torch import nnclass ConvBlock(nn.Module):"""一层卷积块:- 卷积层- 批规范化层- 激活层"""def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):super().__init__()self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,kernel_size=kernel_size, stride=stride, padding=padding)self.bn = nn.BatchNorm2d(num_features=out_channels) # 批规范化层self.relu = nn.ReLU() # ReLU激活函数def forward(self, x):x = self.conv(x) # 卷积操作x = self.bn(x) # 批规范化操作x = self.relu(x) # 激活操作class LeNet(nn.Module):def __init__(self):super().__init__()# 特征提取部分self.feature_extractor = nn.Sequential(# 第一层卷积块ConvBlock(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0),nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # 最大池化层# 第二层卷积块ConvBlock(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0),nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # 最大池化层)# 分类部分self.classifier = nn.Sequential(nn.Flatten(), # 展平操作nn.Linear(in_features=400, out_features=120), # 第一个全连接层nn.ReLU(), # ReLU激活函数nn.Linear(in_features=120, out_features=84), # 第二个全连接层nn.ReLU(), # ReLU激活函数nn.Linear(in_features=84, out_features=10) # 输出层)def forward(self, x):# 1. 特征提取x = self.feature_extractor(x)# 2. 分类x = self.classifier(x)return x
from models import LeNetmodel = LeNet()
-
筹备训练
代码如下:
import torchimport torch.nn as nn# ----- 设备设置 -----# 检测 CUDA 是否可用,若可用则使用第 0 块 GPU,否则使用 CPUdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 将模型移动到指定设备(内存 → GPU 或 CPU 显存)model = model.to(device)# ----- 超参数配置 -----epochs = 80 # 训练总轮数learning_rate = 1e-3 # 学习率# ----- 损失函数与优化器 -----# 使用交叉熵损失(适用于多分类任务)criterion = nn.CrossEntropyLoss()# 使用随机梯度下降(SGD)优化器,传入模型参数和学习率optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
1. 导入必要模块
import torchimport torch.nn as nn
-
torch:PyTorch 主库,提供设备管理、张量操作等。 -
nn:神经网络模块,包含CrossEntropyLoss等常用层和损失函数。
2. 设备选择(Device)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")-
如果有 CUDA GPU,则使用第一块 GPU(
cuda:0),否则回退到 CPU
3. 将模型移动到指定设备
model = model.to(device)-
调用
model.to(device=device)将模型参数和缓冲区迁移到 GPU 或 CPU 内存
4. 设置训练轮数
epochs = 805. 设置学习率
learning_rate = 1e-36. 定义损失函数
criterion = nn.CrossEntropyLoss()7. 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)-
模型评估
# 准确率计算def get_acc(data_loader):accs = []model.eval()with torch.no_grad():for X, y in data_loader:X = X.to(device=device)y = y.to(device=device)y_pred = model(X)y_pred = y_pred.argmax(dim=-1)acc = (y_pred == y).to(torch.float32).mean().item()accs.append(acc)final_acc = round(number=sum(accs) / len(accs), ndigits=5)return final_acc
-
实现训练过程
代码如下:
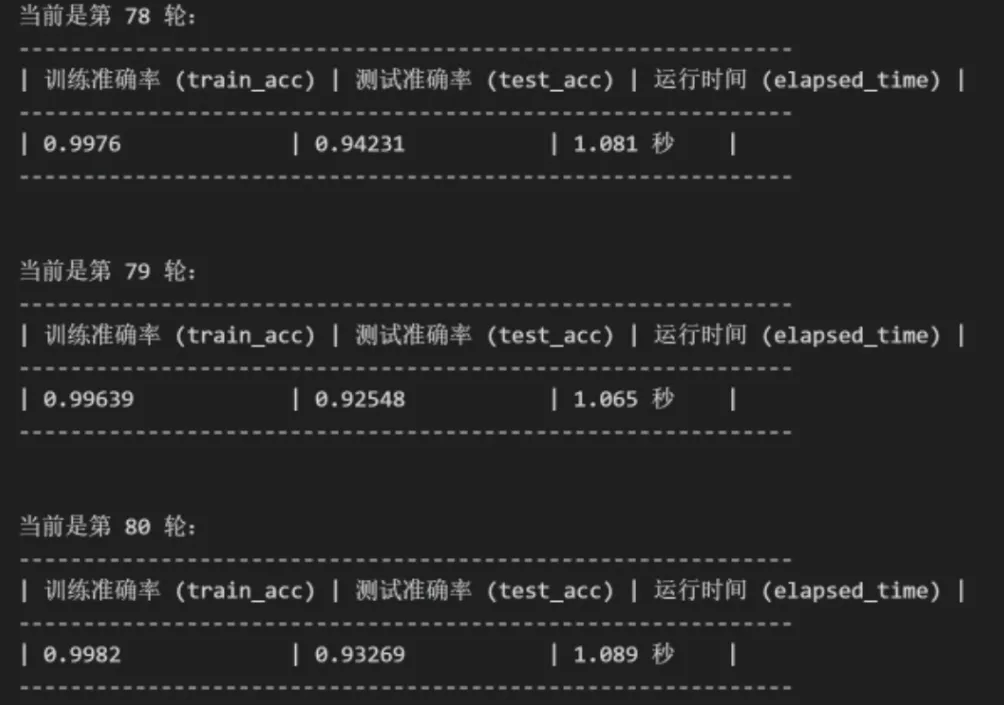
# 训练过程def train():train_accs = []test_accs = []cur_test_acc = 0# 1,训练之前,检测一下准确率train_acc = get_acc(data_loader=train_dataloader)test_acc = get_acc(data_loader=test_dataloader)train_accs.append(train_acc)test_accs.append(test_acc)print(f"训练之前:train_acc: {train_acc},test_acc: {test_acc}")# 每一轮次for epoch in range(epochs):# 模型设置为 train 模式model.train()# 计时start_train = time.time()# 每一批量for X, y in train_dataloader:# 数据搬家X = X.to(device=device)y = y.to(device=device)# 1,正向传播y_pred = model(X)# 2,计算损失loss = loss_fn(y_pred, y)# 3,反向传播loss.backward()# 4,优化一步optimizer.step()# 5,清空梯度optimizer.zero_grad()# 计时结束stop_train = time.time()# 测试准确率train_acc = get_acc(data_loader=train_dataloader)test_acc = get_acc(data_loader=test_dataloader)train_accs.append(train_acc)test_accs.append(test_acc)# 保存模型if cur_test_acc < test_acc:cur_test_acc = test_acc# 保存最好模型torch.save(obj=model.state_dict(), f="lenet_best.pt")# 保存最后模型torch.save(obj=model.state_dict(), f="lenet_last.pt")# 格式化输出日志print(f"""当前是第 {epoch + 1} 轮:------------------------------------------------------------| 训练准确率 (train_acc) | 测试准确率 (test_acc) | 运行时间 (elapsed_time) |------------------------------------------------------------| {train_acc:<18} | {test_acc:<17} | {round(number=stop_train - start_train, ndigits=3)} 秒 |------------------------------------------------------------""")return train_accs, test_accs
-
开始训练
train_accs, test_accs = train()-
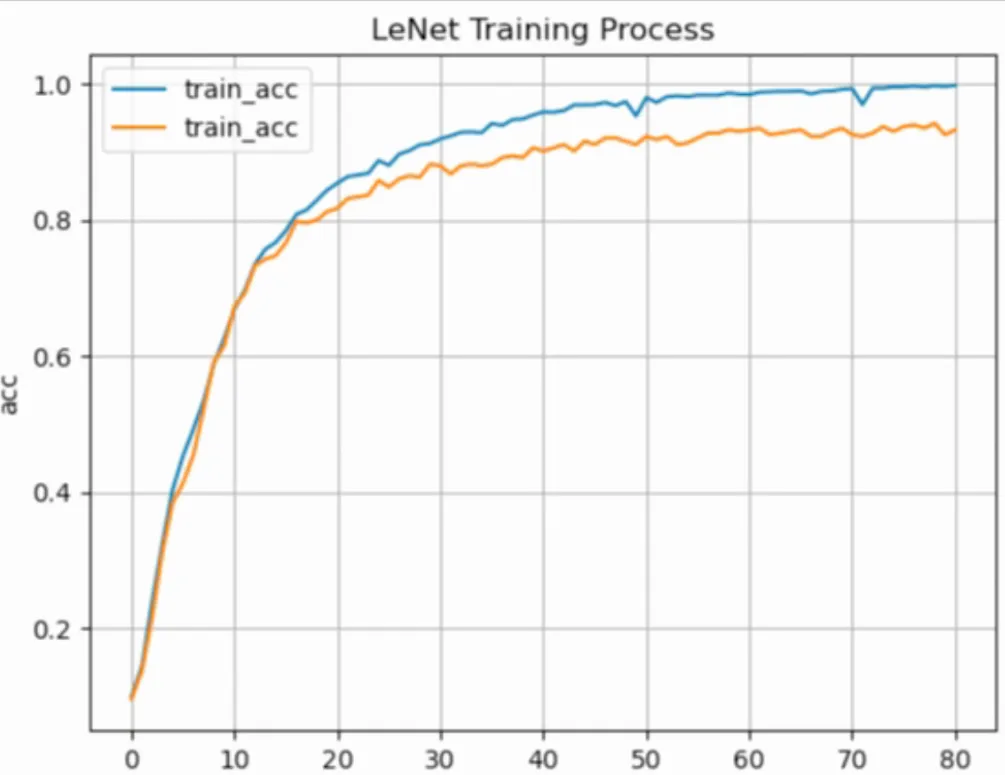
图形化监控数据
plt.plot(train_accs, label="train_acc")plt.plot(test_accs, label="train_acc")plt.legend()plt.grid()plt.xlabel(xlabel='epoch')plt.ylabel(ylabel="acc")plt.title(label="LeNet Training Process")
运行结果:
-
模型预测
import streamlit as stimport torchimport osimport numpy as npfrom PIL import Imagefrom models import LeNet# 标签索引映射字典(与训练时一致)idx2label = {0: 'G0', 1: 'G1', 2: 'G2', 3: 'G3', 4: 'G4',5: 'G5', 6: 'G6', 7: 'G7', 8: 'G8', 9: 'G9'}def infer(img_path, model, device, idx2label):"""对单张图片进行推理,返回预测的类别标签(如 'G3')参数:img_path: str, 图片文件路径model: torch.nn.Module, 已加载权重的模型device: torch.device, 推理设备(cuda/cpu)idx2label: dict, 索引到类别名的映射返回:label: str, 预测的类别名称"""# 1. 检查图片文件是否存在if not os.path.exists(img_path):raise FileNotFoundError(f"图片文件不存在: {img_path}")# 2. 读取图像(使用 PIL 保持与训练时一致,训练时用了 cv2,但 resize 和归一化逻辑相同)img = Image.open(img_path)# 3. 预处理:缩放到 32x32img = img.resize((32, 32))# 4. 转为 numpy 数组,形状 [H, W, C],像素值 0~255img = np.array(img)# 5. 归一化到 [-1, 1]:先 [0,255] -> [0,1],再 [0,1] -> [-1,1]img = img / 255.0img = (img - 0.5) / 0.5# 6. 转为 PyTorch 张量,float32img = torch.tensor(img, dtype=torch.float32)# 7. 调整维度顺序:PIL 读入为 [H, W, C] -> 转换为 [C, H, W]img = img.permute(2, 0, 1)# 8. 增加 batch 维度: [C, H, W] -> [1, C, H, W]img = img.unsqueeze(0)# 9. 将数据移动到指定设备img = img.to(device)# 10. 设置模型为评估模式(关闭 dropout 等)model.eval()# 11. 不计算梯度,加快推理并节省内存with torch.no_grad():# 12. 正向传播,得到 logitsy_pred = model(img) # 修正:使用传入的 model,而不是全局 m1# 13. 取概率最大的类别索引pred_idx = y_pred.argmax(dim=-1).item()# 14. 通过映射字典得到类别标签label = idx2label.get(pred_idx, "未知")return label# ========== Streamlit UI 部分 ==========def main():# 设置页面标题st.title("手势识别应用 - LeNet")# 1. 检测并显示计算设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")st.write(f"当前推理设备: {device}")# 2. 加载模型(只加载一次,利用 Streamlit 的缓存机制)@st.cache_resourcedef load_model(device):model = LeNet() # 实例化模型model.to(device) # 移动到设备# 加载训练好的权重(文件 lenet_best.pt 应位于当前目录)state_dict = torch.load("lenet_best.pt", map_location=device)model.load_state_dict(state_dict, strict=False)model.eval() # 设为评估模式return modeltry:model = load_model(device)st.success("模型加载成功!")except Exception as e:st.error(f"模型加载失败: {e}")st.stop()# 3. 文件上传组件uploaded_file = st.file_uploader("上传一张手势图片", type=["png", "jpg", "jpeg"])if uploaded_file is not None:# 3.1 将上传的文件保存为临时文件(便于传给 PIL 和 infer 函数)temp_path = "temp_img.jpg"with open(temp_path, "wb") as f:f.write(uploaded_file.getvalue())# 4. 显示上传的图片img = Image.open(temp_path)st.image(img, caption="您上传的图片", use_column_width=True)# 5. 执行推理并显示结果if st.button("开始识别"):with st.spinner("识别中..."):label = infer(temp_path, model, device, idx2label)st.success(f"预测结果: **{label}**")# 可选:推理完成后删除临时文件(此处省略)if __name__ == "__main__":main()
-
小结
1. 手势图像数据集的介绍与下载
2.深度学习的流程:
数据预处理->批量化数据打包->模型搭建->训练模型->模型评估->模型预测
以上就是我们这节课的全部内容了,这节课主要通过实战训练,回顾了一遍深度学习的流程,下节课我们继续通过手势图像来学习Vgg16和ResNet,希望大家和我一起共同学习、一起进步,欢迎点赞、转发,也请关注我的公众号。