SDD文档审核量大?脑子跟不上AI?我是如何使用一套工作流,大幅减少SDD审核工作量的.
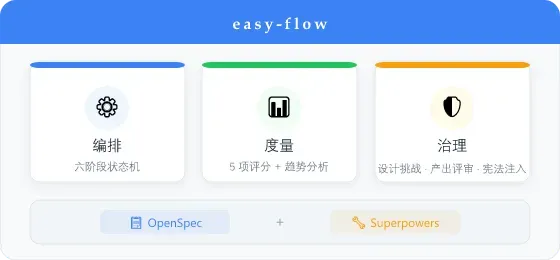
easy-flow 是一套为「AI 编码工程化」开发的工作流系统,它在 OpenSpec 和 Superpowers 之上搭了一层编排+度量+治理框架:6 条命令,5 个阶段,在SDD外侧额外增加 文档审计层 , 把大量文档转换为数个问题 ,助你轻松完成SDD开发
一、起源 最近接手了一个新的项目,给某神秘 Agent 开发 MCP,项目一共就四个文件,每个源文件居然都踏马有 1w 行之多???看着旁边悠哉悠哉喝咖啡的开发同事,本鹅已经准备走上犯罪道路 很难想象这种 Shit 项目竟然能出自大厂工程师之手???经过一番痛苦的重构之后引发了本鹅的思考,为什么最强的一批工程师+最强 AI 的产出的工程却不如古法编程出的工程好维护、质量高呢? 我决定先从问题入手看看现有AI辅助编程都有哪些问题: 1、需求散落口头,AI与人类的共识仅存于当前上下文 团队协作开发缺乏项目级的知识沉淀纯对话式 AI 编码(Cursor agent / Codex CLI / 早期 Claude)的根本缺陷是——用户和模型对「要做什么」的共识只存在于聊天上下文里,session 一关共识蒸发。下一次对话模型不知道上次说过什么,用户也无据可查,半年后看 git log 只看到 commit message 看不到为什么这么做。 2、 长上下文丢失和模型幻觉 当 AI 进行一个复杂功能开发时,起初还能够完成符合工程师描述的任务,但是随着工程的深入和代码量的增加,AI 开始记错甚至忘记之前开发者的约束,导致生产的代码出现逻辑漂移,也没有任何校验机制。 3、 AI 对用户的指令过于急功近利 通常 AI 在接到一个指令或想法后会立即进入实现,即便有 plan 机制也会把完整的设计一股脑的抛出来,这会导致用户瞬间接受大量信息,无法做出深度判断。 这些缺陷导致,开发者一旦完全忽视曾经的编码优秀习惯,让 AI 全自动驾驶跑长任务,那么 AI 就会在你的工程上肆意妄为,随地大小写,让你的工程即便最后能跑起来,也最终沦为一坨 shit。 业界的做法:
为了解决这些问题业界提出了 SDD 的概念并且通过 OpenSpec 以及 Spec-kit 作为 SDD 的工程化实现,但它们需要在已经知道具体要做什么的情况下去推进并且没有强制的测试验证,为此我相信大部分工程师已经在结合 superpower 的 brainstorming(和 explore 的优劣我们可以在评论区讨论)和 TDD 模式先把方案先想清楚,强制 TDD 再结合 openspec 去推进任务,那么我们还缺什么?
维度
OpenSpec
Superpowers
本质定位
纯工件驱动 change 模型
通用 skill 集合
强制力来源
工件结构
skill 内部约束
机器可验证硬门
极少(仅工件齐全检查)
skill 内有,跨 skill 无
强制讨论 / Reframe / Premise
完全无
brainstorming 太轻
独立评审阶段
无
只有 code-review,无 plan-review
跨模型挑战
无
无
Constitution 注入机制
文档存在但不强注入
完全无
多 worktree 并发安全
无(最大短板)
无
per-change 状态隔离
部分(工件目录隔离,但 state 共用)
无
worktree 元数据合回
无
无(git-only)
度量 / Reflect 反馈环
无
无
subagent 派发可控性
N/A
完全黑盒
主代理职责边界
无约束
无约束
跨平台 / 跨宿主验证
中
弱
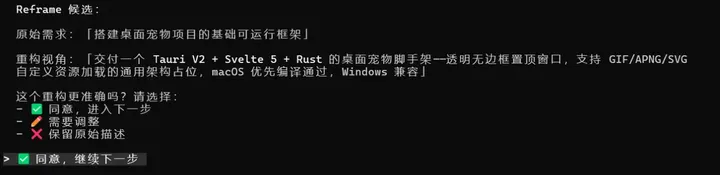
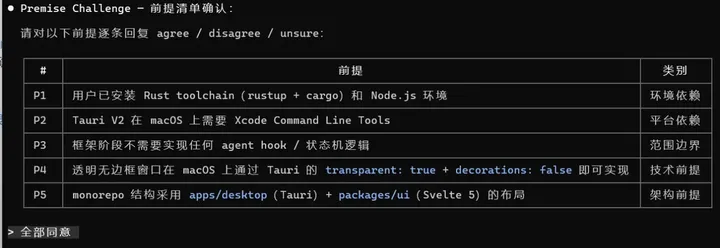
二、痛醒:AI 编码的最后一公里 2.1 代码有自动化审计,文档全靠人肉 代码有 lint、有测试、有 CI 把关。但 OpenSpec 生成的那些文档是从用户描述直接生成的,这会导致把 LLM 的理解错当作既成事实,四件套写得好不好、有没有漏关键设计决策、Constitution 规则有没有对齐,全靠工程师自己翻看。文档质量完全绑在人的认真程度上,没有机制能自动检查「LLM 的实现意图与用户的初始意图是否一致」或者「这份 design 缺了架构说明还是测试用例」。(大量的文档审查对我们程序员来说的注意力也是极大的跳战啊,xdm,我脑子是不够用啊) 2.2 两套工具流程割裂,命令散落在两边 OpenSpec 管需求(/opsx:propose、/opsx:apply),Superpowers 管方法(brainstorming、TDD),各管各的。你想走完「设计→评审→实施→审计」一整条链路,得自己在两套工具之间来回切——记着 OpenSpec 这里用哪个命令、Superpowers 那边调哪个 skill。没有统一的入口,也没有统一的状态追踪,变更走到哪一步全凭脑子。 2.3「LLM 训练偏置」问题仍然存在 LLM 的训练偏置(阿谀奉承 / Framing 锁死 / 未验证前提当事实 / 模糊确认陷阱)是对齐层面的失败,不是规范层面的失败—— ● 你给 LLM 一份 spec,它仍然可能在生成 spec 的过程中顺从用户错前提 ● 你给 LLM 一份 tasks.md,它仍然可能在某个 task 实施时凭「看起来合理」瞎猜 ● 你强制它先 spec 再 code,它仍然可能写一份讨好用户的 spec 2.4 OpenSpec 天然串行,现实是并行的 OpenSpec 的模型是每次开一个 change、走完、归档——单线程。实际开发中,你很可能同时有三个变更在跑:Feature A 在设计阶段,Feature B 在构建,Bugfix C 在审计。OpenSpec 不会告诉你当前有多少变更在并行、各自在哪个阶段。 2.5 没法度量 用了 AI 之后代码质量变好了还是变差了?测试覆盖率在往上走还是往下掉?文档跟没跟上代码改动?这些问题的答案全都依赖主观判断——今天感觉还行,下周感觉不太对,但拿不出数据,工程开发的根本问题是 「这套 SDD 流程是不是真的让产出更好」——这需要跨 change 的趋势度量(覆盖率 / 复杂度 / 文档同步度 / 违规率)。 一句话:OpenSpec 管写什么,Superpowers 管怎么写,但编排、度量、治理是空白的。 三、easy-flow到底是个啥东西 在 OpenSpec 和 Superpowers 之上增加编排、度量、治理能力——把六步串成管线统一使用,每次变更有评分,关键节点设置验收标准。 六阶段一条线8条命令,每条对应一个独立skill(design → propose → lock → build → audit → ship → reflect → constitution),不再需要你在 OpenSpec 的 `/opsx:propose` 和 Superpowers 的 brainstorming 之间来回切。变更加到了哪个阶段,`workflow.yaml` 和 `state.yaml` 全程追踪,不用脑子记。 1. /ezfl:design — 谈需求,出方案能力概述: 使用 brainstorming 进行结构化追问(覆盖 ≥3 类问题),走 Reframe Check(「你确定要的是这个?」)和 Premise Challenge(「你的假设成立吗?」),最后沉淀为 9 节标准 pre_design.md。 最大程度避免直接让 AI 开写的冲动。用追问把模糊需求逼出具体方案,用 reframe 对齐人类与 AI 的目标意图,用 premise challenge 在动手前把错误假设排掉。 初始化draft目录 → 加载 Constitution → ≥3 轮 brainstorming 追问 → Reframe Check → Premise Challenge → 写入 pre_design.md → 用户确认 → 敲定 change_id。 产出: .harness/changes//pre_design.md 2. /ezfl:propose — 设计方案转 OpenSpec 四件套 把pre_design.md无损转成OpenSpec 四件套强重读tasks- template.md 将目标任务拆分,TDD 类型任务完全保留 Superpowers 的严格 RED-GREEN-REFACTOR 流程保证格式合规。worktree 创建走确定性 bash,不走 superpower。
为什么不用 using-git-worktrees? 它其实挺好——查已有目录、读 CLAUDE.md、问用户放哪,路径是灵活可控的。easy-flow 放弃它是两个原因:1、它不是确定性的脚本。告诉 AI「按什么规则建 worktree」,最终怎么执行看 AI 心情。 2、 路径一自由,合回阶段脚本找不到目标
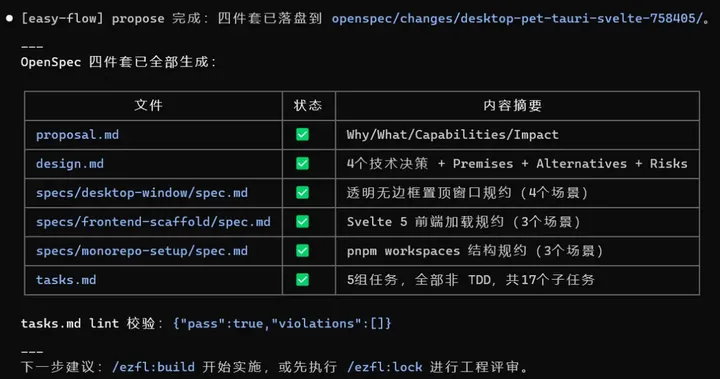
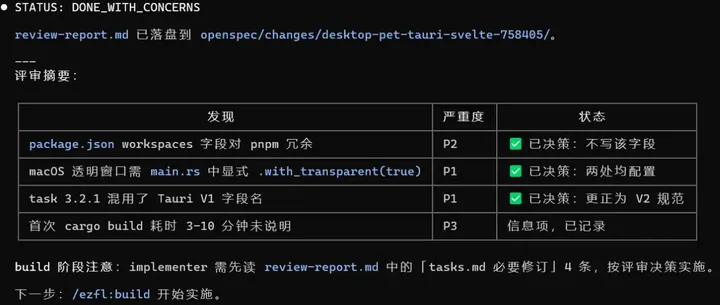
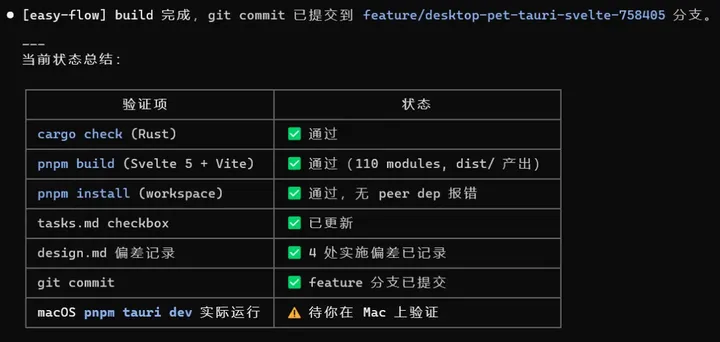
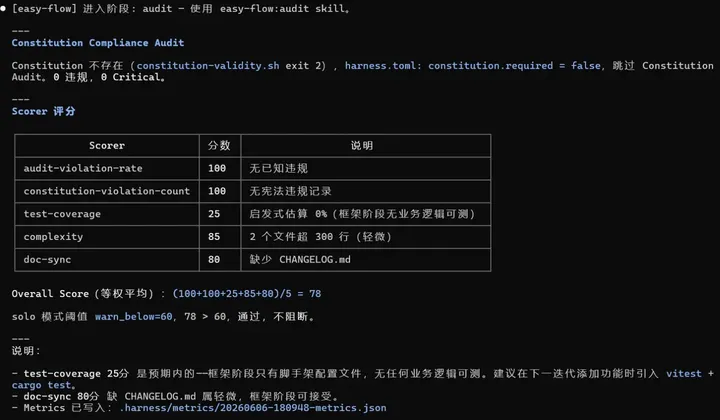
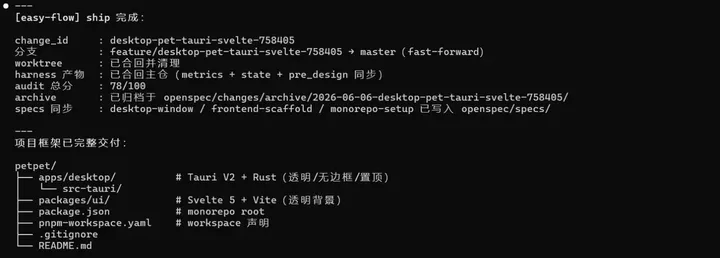
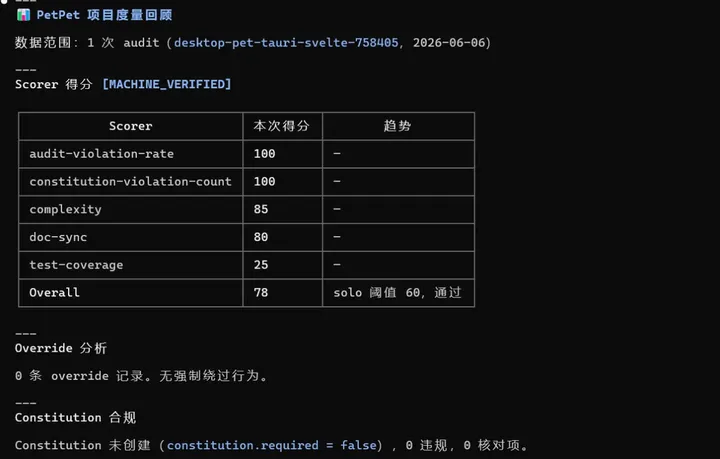
支持多 worktree 并行开发,worktree 要不要建在这里统一决策,并且校验 pre_design.md 完整性,再跑 tasks.md lint 确认格式零偏差,不等到后面再折腾 定位 change_id → 询问是否建 worktree → 定位并校验 pre_design.md → 调/opsx:propose→ 出口校验四件套 + tasks.md lint。 产出:openspec/changes//(proposal + design + specs + tasks) 3. /ezfl:lock — 工程评审,找漏洞 四节对抗式评审(架构/代码质量/测试/性能),一问一议不打包。范围挑战先砍不必要的复杂度。可选换个模型交叉评审。只评不改,结论写入review-report.md。 「设计文档写了但没人真看」,工程师对文档的要求参差不齐。 读 config → 范围挑战 → 四节顺序评审 → 用户逐项决策 → Outside Voice(可选)→ 写入 review-report.md。 4. /ezfl:build — 实施 Agent Selector 让用户选 implementer(项目 agent / 默认子代理 / inline),subagent prompt 强制注入 Constitution 约束。主代理可选全程不写实现代码(但是会更耗费 token,可以根据需求自行选择)。 「谁在干活」不可见 + 实施过程脱离治理。用户显式选择执行者,Constitution 约束跟着 subagent 走,不是主代理说一句「注意遵守」就算了。 定位 change_id → Agent Selector 选 implementer → 三态分支 agent / default-subagent / inline →执行/opsx:apply。 5. /ezfl:audit — 宪法检查 + 五项打分 逐条对 Constitution,跑 5 个 scorer 输出 0-100 分 + 理由。结果写入timestamp-metrics.json,每次不覆写。 代码有 CI,文档没审计。audit 给 proposal/design/tasks 也加上自动化检查,同时量化每次变更的质量——违规率、覆盖率、复杂度、文档同步度全部打分存档。 读取 workflow.yaml 定位 change_id → Constitution 合规检查→ 停等用户处理违规 → 跑 5 个 scorer → 聚合写入 metrics.json → 标记 audit 结果写到 state.yaml。
Scorer
度量维度
audit-violation-rate
审计违规占比
constitution-violation-count
宪法违规次数
test-coverage-scorer
测试覆盖率
complexity-scorer
代码复杂度
doc-sync-scorer
文档同步度
这里只做了最简单的质量检测,其实可以接入更好的检测流程比如CI 流水线等。
产出:.harness/metrics/-metrics.json 6. /ezfl:ship — 终验、合入、打扫 五步交付管线:拿 ship 锁 → 终验 → 分支决策 → worktree 合回三段式(产物回主仓 → git 合并 → 清 worktree)→ archive 归档。保证数据不随 worktree 蒸发。 合完代码 worktree 一删,审计数据跟着没了。ship 阶段强制在删 worktree 前把 metrics、overrides、state 合回主仓并归档。 获取ship.lock→verification-before-completion 终验 →finishing a development branch分支决策 → harness sync 产物合回 → worktree 清理 →/opsx:archive归档。 7. /ezfl:reflect — 历史度量回头看 聚合.harness/metrics/全量历史数据,按 change_id 归因。输出 scorer 趋势、override 频率、Constitution 违规分布、改进建议。支持/ezfl:reflect monthly月报模式。 「项目质量在变好还是变差」终于有答案了。不再凭感觉判断,历史数据自动聚合出趋势,低分项和频繁 override 一目了然。 glob.harness/metrics/*.json→ 按 scorer 聚合趋势 → override 频率分析 → Constitution 违规统计 → 生成改进建议。 8. /ezfl:constitution — 管宪法 三模式管理openspec、memory、constitution.md:CREATE(带模板引导)、AMEND(版本号 + 影响报告)、SHOW(只读)。宪法通过四个注入点(设计 A / 评审 B / 实施 C / 审计 D)贯穿整条链路。 治理规则不是「贴在墙上」的,而是「卡在流程里」的。Constitution 的每一条 Core Principle 在设计、评审、实施、审计四个环节都会被自动提取校验。
模式
触发条件
效果
CREATE
不存在或有占位符
引导填模板,生成宪法
AMEND
已有有效宪法
修改 + 版本号 + Sync Impact Report
SHOW
传 show
只读展示
对于老项目而言没有宪法在流程中会自动跳过,如果新增了宪法后续只关注delta的遵守情况
分成多条命令目的是为了让用户可以自主选择当前应该做什么,不强制跑完全流程,比如: 明确知道我想要做什么并且不希望走度量,完全可以走 propose -> build -> ship 和 openspec 的流程没有任何区别。 最后看 easy-flow 在一个项目里落盘的文件结构:
.harness/ ├── workflow.yaml # 全局变更注册表,哪些 change 在跑、各在哪个阶段 ├── harness.toml # 项目级配置(宪法开关、scorer 权重等) ├── changes/ │ └── <change_id>/ │ ├── state.yaml # 单变更生命周期档案(design→audit 全阶段产物) │ ├── pre_design.md # 设计方案(design 阶段产出) │ └── draft-* # 未敲定的临时设计目录 ├── metrics/ │ └── <ts>-metrics.json # 每次 audit 的质量评分,不可覆写,横向聚合趋势 ├── overrides.log # 所有 audit overrides 的审计日志 ├── archive/ │ └── <change_id>/ # ship 后归档的完整快照(state + metrics + overrides) ├── .cache/ │ └──.plugin_root # plugin 安装路径探针 └── .locks/ ├── ship.lock # ship 阶段互斥锁(防并发 ship) └── workflow.lock # workflow.yaml 写互斥锁(防并发 RMW)
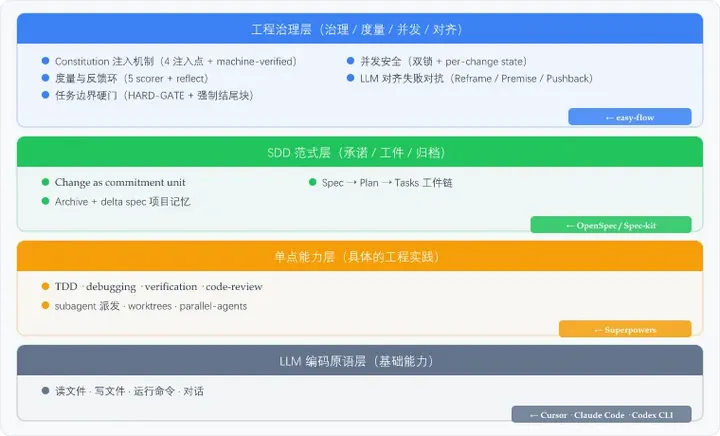
四、esay-flow在Harness工程中到底在哪 easy-flow 不是”另一个 SDD 实现”,而是”SDD 之上的工程治理层”——它不与 OpenSpec/Spec-kit 竞争”如何做 SDD”,而是在 SDD 已经搭好的工件基础上叠加治理机制。真实工程团队要在 AI Coding 上跑稳,需要 SDD(OpenSpec/Spec-kit)+ 单点工程实践(Superpowers)+ 工程治理层(easy-flow 这类)三者叠加。 五、esay-flow 的到底有啥价值 把 spec-driven 从「提示词工程」升级为「机器可验证的状态机」—— 状态行 / Hook 退出码 / 文件锁 / 写后校验,每一步都有可机器验证的门,模型跑偏立刻被拦截。这是 OpenSpec/Superpowers 都做得不够彻底的地方。
把 OpenSpec 从「工件管理器」升级为「工程闭环」——补齐了强制讨论环(pre_design)、宪法注入(4 注入点)、独立评审(lock + Outside Voice)、度量反馈(5 scorer + reflect)、并发安全(双锁 + per-change 隔离)。OpenSpec 的工件还是那套工件,但工件之间的工程纪律完全不一样了。
所有重要设计都是为了解决真实的问题——不是空谈「AI 治理」的概念产品,而是从真实多 worktree 并发、worktree 内数据蒸发、scorer 静默跳过、inline challenger 假评审等真实 coding 场景下存在的问题里反推出的硬规则。这是它和「演示型工作流」最本质的区别。
如果用一句话定位:easy-flow 是把 AI Coding 当软件工程而不是当玩具看的一种工作流——它假设模型会跑偏、假设并发会冲突、假设清理会误删、假设评审会走过场,然后用工程手段把每一种假设都做成不可绕过的硬门。 六、最后哔哔两句 easy-flow 管的事其实挺简单的:AI 编码从偶尔用变成了主力,你怎么保证质量不掉、过程不失控?它不是来替代谁的。OpenSpec 管写什么,Superpowers 管怎么写,easy-flow 管每一步都到位了没有。三块拼一起刚好够用。 从头到尾走一条试试——从 /ezfl:design 到 /ezfl:ship。跟让 AI 随缘写代码比,手感不太一样。 https://github.com/Mikey0212/easyflow.git 里面有安装方法,简单的一批,觉得不错可以点点小星星 使用过程中有任何问题可以通过神秘绿色软件和我交流:Mikey_212
 夜雨聆风
夜雨聆风