 夜雨聆风
夜雨聆风





为什么很多 AI 视觉测试越做越不稳?根因是 DOM 解析,静态代码分析才更适合测试工程
很多团队不是不会做 AI UI 测试,而是做出来以后不敢放进核心回归
做过 UI 自动化的人,基本都见过这类问题:
-
页面一改,定位器就漂 -
权限一变,脚本就漏场景 -
功能开关一开一关,流程立刻分叉 -
Case 挂了以后,半天分不清是产品 bug,还是测试资产过期
这两年很多 AI UI 测试工具出来后,第一眼看上去确实很惊艳。
它会看页面、读 DOM、识别元素、决定下一步点哪里,像一个“会自己探索页面的测试员”。
但真放进企业项目,问题很快就出来了:
能演示,不代表能稳定回归。
更准确地说,很多方案的问题不是 AI 不够聪明,而是它理解页面的方式,本身就不够稳定。
先说清楚:这里说的“AI 视觉测试”,不是传统截图 diff
这里说的“AI 视觉测试”,不是那种做像素对比的视觉回归。
我这里说的是另一类更常见的 AI UI 测试思路:
-
运行时看截图、DOM、可访问性树 -
现看现判断页面上有什么 -
临场决定该点哪个按钮、填哪个输入框 -
再根据当前页面继续往下走
这类方案适合做探索、演示、快速试跑。
但如果你想把它放进企业里的长期回归链路,问题就来了。
一句话判断:只靠运行时 DOM 解析和页面视觉理解的 AI UI 测试,适合“先跑起来”,不适合直接承担“长期稳定回归”。
一、为什么现在很多主流 AI UI 测试不稳
问题的核心,不在“会不会看页面”,而在“是不是只能看页面”。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
很多团队会以为这只是“模型还不够强”。
其实不是。
这是一个更底层的工程问题。
因为这类方案把测试理解放到了最后一步,也就是页面已经渲染出来以后,才开始问:
-
这里有什么元素? -
这个按钮能不能点? -
这个表单下一步应该怎么走? -
这一次看见的页面,是不是完整真相?
这件事天然就晚了。
页面渲染结果,只是源码逻辑在某个状态下的一次投影。
而测试真正想拿到的,不只是“当前页面”,而是:
-
这个页面由哪些组件组成 -
哪些交互点真正重要 -
哪些内容受权限控制 -
哪些流程受开关影响 -
哪些分支虽然这次没渲染出来,但其实客观存在
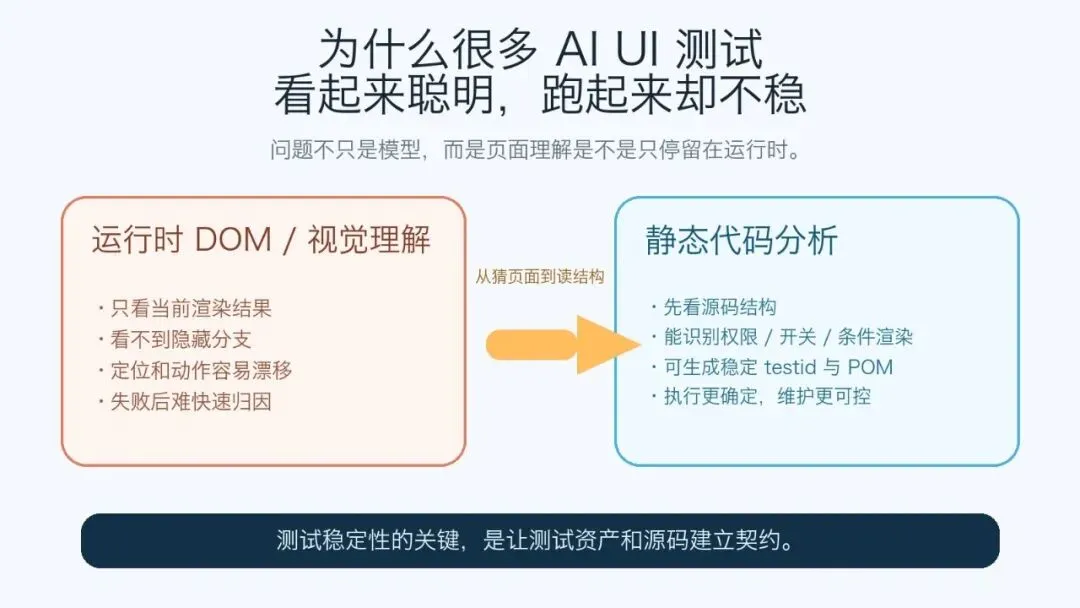 图 1:很多 AI UI 测试不稳,不是因为它不会看页面,而是因为它只能看页面。
图 1:很多 AI UI 测试不稳,不是因为它不会看页面,而是因为它只能看页面。
二、为什么静态代码分析更适合测试工程
静态代码分析更强的地方,不是“更炫”,而是更确定。
它把理解页面这件事,从运行时往前移到了源码阶段。
也就是说,不等页面跑起来再猜,而是先从代码里把这些东西挖出来:
-
组件结构 -
交互事件 -
状态切换 -
权限判断 -
功能开关 -
条件渲染
这样做之后,测试资产就不再是漂在页面外面的,而是和源码绑在一起。
可以把两种思路理解成下面这个差别:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
从测试工程角度看,静态代码分析至少有 4 个直接收益。
1. 定位更稳
先识别组件,再补稳定 testid,再生成定位器目录。
这样定位器不是临场猜出来的,而是从源码结构里长出来的。
2. 状态覆盖更全
权限、开关、条件渲染这些东西,很多时候运行时只会露出一部分。
源码扫描后,可以提前知道还有哪些隐藏分支需要覆盖。
3. 页面对象更可维护
POM 不再是测试同学手工硬写的一层壳,而是基于组件结构自动生成或半自动维护。
这样页面改版时,测试不会从 DOM 重新摸一遍。
4. 失败更容易诊断
一旦测试失败,可以往回追:
-
是源码组件变了 -
是 testid 失效了 -
是业务规格变了 -
还是真出了功能 bug
静态代码分析的真正价值,不是帮你少点几下按钮,而是让测试资产重新和源码建立契约。
三、如果测试团队真要做,整体实现应该怎么搭
这个方向不是多加一个 Agent 就结束了。
它本质上是一条“测试资产生产线”。
最实用的做法,是拆成两段:
-
Setup:先建立结构化真相 -
Execution:再执行测试旅程
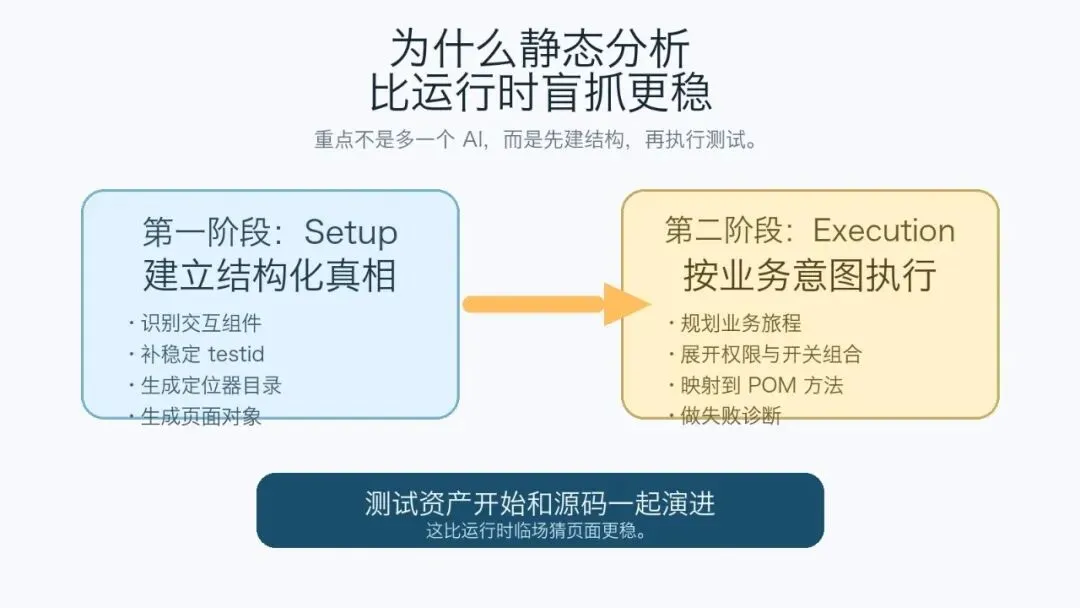 图 2:真正稳定的路径,不是边跑边猜,而是先把源码里的结构和约束抽出来,再执行测试。
图 2:真正稳定的路径,不是边跑边猜,而是先把源码里的结构和约束抽出来,再执行测试。
第一层:源码扫描,建立组件索引
这一层建议直接基于 AST 做。
至少要抽出这些信息:
-
组件名和源码路径 -
可交互元素和事件 -
状态字段 -
条件渲染 -
权限判断 -
功能开关依赖
这份组件索引可以落成 JSON、SQLite,或者团队已有的元数据仓库。
它是后面所有测试资产的上游事实源。
第二层:补稳定契约,生成测试基础设施
有了组件索引以后,第二步不是直接生成 case,而是先把稳定资产补齐:
-
为关键交互点补 data-testid -
生成定位器注册表 -
生成或更新 POM -
建立测试代码到源码组件的映射
这一层最关键,因为它决定后面的测试是在“消费契约”,还是继续“现场猜页面”。
第三层:展开业务场景,不只生成一条正常主流程
这一步才轮到 AI 真正发力。
基于前面的结构化真相,可以去做:
-
权限组合展开 -
功能开关组合展开 -
正常流 / 异常流拆分 -
页面跳转和弹窗分支规划
这时候生成出来的测试,稳定性会比纯运行时探索高很多。
因为它不是凭页面当前长相临场猜测,而是在消费已经建好的结构化资产。
第四层:执行和诊断,把失败分清楚
执行阶段建议只做两件事:
-
按结构化资产执行 -
按错误类型做诊断
也就是说,case 挂了以后,不要只输出“元素没找到”。
最好能继续往下分:
-
是组件改名了 -
是 testid 丢了 -
是流程分支变了 -
还是断言真的揭示了业务 bug
这一步会直接决定团队后续维护成本。
 图 3:别一上来就想着“全自动 Agent 编排”,对测试团队最值钱的,往往是组件索引、稳定定位、POM 和失败诊断。
图 3:别一上来就想着“全自动 Agent 编排”,对测试团队最值钱的,往往是组件索引、稳定定位、POM 和失败诊断。
四、一个真实场景:退款页为什么最容易暴露问题
退款功能是很典型的一类页面。
它经常同时具备这些复杂度:
-
有权限账号才看得到入口 -
新旧 UI 并行一段时间 -
功能开关开启和关闭走不同流程 -
全额退款和部分退款校验逻辑不同 -
审核弹窗、二次确认、状态回写都可能变
如果只靠运行时 DOM / 视觉理解去做,常见问题是:
-
当前账号看不到退款入口,AI 就不知道还有这条路径 -
新旧 UI 并行时,每次学到的页面结构可能不同 -
弹窗文案或布局一变,动作就容易漂 -
挂了以后,很难第一时间判断是页面改了,还是业务逻辑真的错了
但如果前面已经把源码结构分析过,这个场景就会好很多。
 图 4:退款这类多权限、多开关、多流程场景,最能体现静态代码分析比 DOM 盲抓更适合长期回归。
图 4:退款这类多权限、多开关、多流程场景,最能体现静态代码分析比 DOM 盲抓更适合长期回归。
一个更稳的执行方式通常是这样的:
-
在源码阶段识别退款按钮、退款表单、金额输入框、确认弹窗和状态标签 -
把权限判断、功能开关分支、全额 / 部分退款条件一起抽出来 -
自动生成稳定 POM 和定位器目录 -
再按业务矩阵展开场景,而不是每次运行时重新探索
这样生成出来的测试,不只是“把流程点通”。
它还能更自然地把断言做深,比如:
-
退款按钮在不同权限下是否可见 -
部分退款金额校验是否正确 -
提交后订单状态是否回写成功 -
审核记录和操作日志是否产生 -
新旧 UI 下核心业务结果是否一致
这才是测试团队真正关心的价值。
因为企业里的 UI 测试,从来不只是点点点,而是要验证状态、规则和副作用。
五、测试团队怎么落地,才不会做成一套很重但没人用的系统
最容易踩的坑,就是一上来就想做“全自动 AI 测试大脑”。
更现实的做法是分三步。
第一步:先挑一个最容易碎的模块试点
优先选下面这类页面:
-
权限差异多 -
功能开关多 -
弹窗和子流程多 -
页面改版频繁 -
业务价值高
比如退款、营销配置、优惠券发放、运营后台审批页,都很适合。
第二步:先做 Setup,不要急着追求全自动生成 case
先把这几样东西跑通:
-
组件扫描 -
testid 规范化 -
定位器注册表 -
POM 生成
只要这一步做稳,很多 UI 测试的脆弱问题就已经开始下降了。
第三步:再把 AI 用到场景扩展和失败诊断上
这是更适合测试团队的 AI 用法。
让 AI 去做:
-
场景矩阵展开 -
边界流补充 -
失败归因辅助 -
变更影响分析
而不是把最基础的页面理解,全都交给运行时即时猜测。
六、最后一句话
现在很多 AI UI 测试不稳,不是因为 AI 不够强。
而是因为它太依赖运行时 DOM 和页面视觉结果,理解发生得太晚,测试资产也没有和源码建立稳定契约。
如果测试团队想把 AI 真正用进企业级 UI 回归,重点不该只是“让 AI 会点按钮”,而是“让测试先理解源码结构,再执行页面动作”。
这也是为什么:
DOM 解析适合探索,静态代码分析更适合长期测试工程。